
چیتشیت کتابخانه سایکیت لرن در پایتون برای یادگیری ماشین
تیم تحریریه
- ۱۶ اسفند ۱۴۰۰
- زمان مطالعه 11 دقیقه
آیا شما نیز یکی از میلیونها برنامهنویس پایتون هستید که به دنبال کتابخانهای قدرتمند برای یادگیری ماشین میگردند؟ اگر چنین است، باید کتابخانه سایکیت لرن Scikit-Learn را بشناسید. سایکیت لرن در دنیای پایتون نقش مهمی در حوزه یادگیری ماشین دارد و آشنایی با آن برای دریافت مدرک علوم داده ضروری است. این مقاله مناسب کسانی است که پیشتر با پکیچ پایتون آشنایی دارند و تنها به دنبال مرجعی مناسب هستند. اگر تازهکار هستید و با سازوکار سایکیت لرن آشنایی ندارید، باز هم نیازی به نگرانی نیست؛ زیرا در این مقاله اصول و مفاهیم پایهای کتابخانه سایکیت لرن در حوزه یادگیری ماشینی و نحوه کار با آن را خواهید آموخت.
چیتشیت پایتون برای سایکیت لرن

سایکیت لرن یک کتابخانه متن باز پایتون برای یادگیری ماشینی، پیش پردازش، اعتبارسنجی متقاطع Cross-validation و الگوریتمهای مصورسازی Visualization algorithms است. این کتابخانه مجموعه متنوعی از الگوریتمهای یادگیری با نظارت و بدون نظارت را در دسترس ما قرار میدهد.
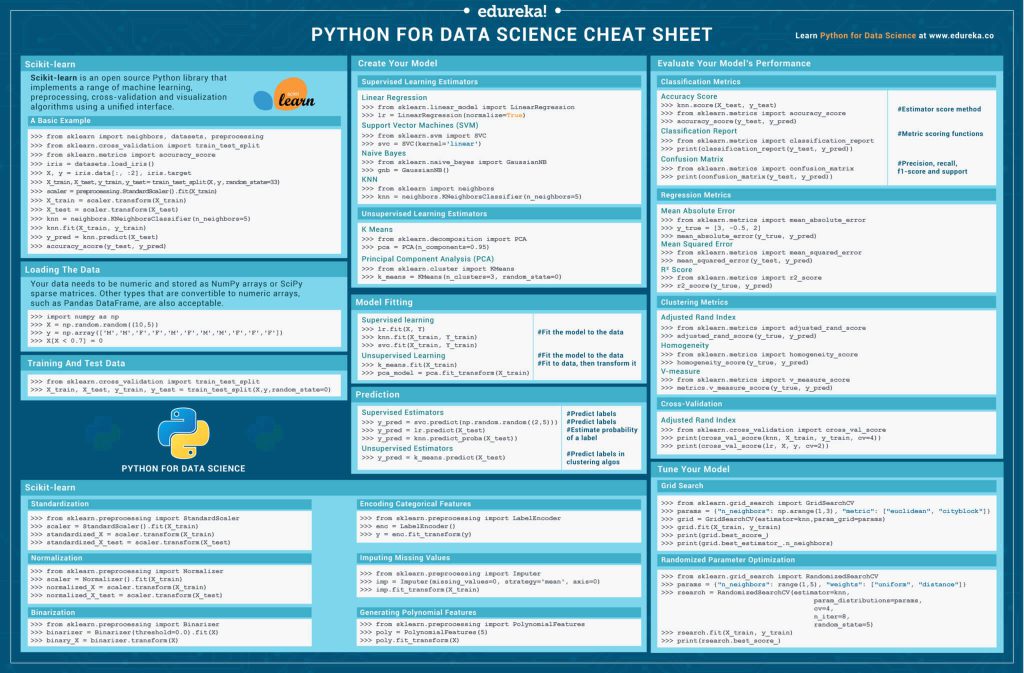
یک مثال ساده
بیایید در یک مثال ساده به کمک کتابخانه اسکیت لرن کدی بنویسیم که:
- دادهها را بارگذاری کند،
- آنها را به دو دسته آموزش و آزمون تقسیم کند،
- دادهها را با استفاده از الگوریتم KNN آموزش دهد،
- نتایج را پیشبینی کند.
>>> from sklearn import neighbors, datasets, preprocessing >>> from sklearn.model_selection import train_test_split >>> from sklearn.metrics import accuracy_score >>> iris = datasets.load_iris() >>> X, y = iris.data[:, :2], iris.target >>> X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=33) >>> scaler = preprocessing.StandardScaler().fit(X_train) >>> X_train = scaler.transform(X_train) >>> X_test = scaler.transform(X_test) >>> knn = neighbors.KNeighborsClassifier(n_neighbors=5) >>> knn.fit(X_train, y_train) >>> y_pred = knn.predict(X_test) >>> accuracy_score(y_test, y_pred)
بارگذاری دادهها
دادههای شما باید در آرایههای NumPy بهصورت دادههای عددی یا درSciPy در قالب ماتریسهای فضایی sparse matrices ذخیره شده باشند. البته میتوانید از سایر آرایههای عددی همچون چارچوب کاری Pandas نیز استفاده کنید.
>>> import numpy as np >>> X = np.random.random((10,5)) >>> y = np.array(['M','M','F','F','M','F','M','M','F','F','F']) >>> X[X < 0.7] = 0
آموزش و آزمون
مر حله بعدی، پس از بارگذاری دادهها، تقسیم دیتاست به دادههای آموزشی و دادهها آزمون است.
>>> from sklearn.model_selection import train_test_split >>> X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
پیش پردازش دادهها
استانداردسازی
استانداردسازی دادهها یکی از مراحل پیش پردازش است که بهمنظور مقیاسدهی مجدد یک یا چند صفت انجام میشود تا مقدار میانگین صفات برابر ۰ یا انحراف از معیار آنها برابر ۱ شود. در استانداردسازی فرض میکنیم که گاوسیتوزیع دادهها گاوسی Gaussian distribution (منحنی زنگولهای Bell curve distribution) است.
>>> from sklearn.preprocessing import StandardScaler >>> scaler = StandardScaler().fit(X_train) >>> standardized_X = scaler.transform(X_train) >>> standardized_X_test = scaler.transform(X_test)
نرمالسازی
نرمالسازی تکنیکی است که عموماً بهمنظور آمادهسازی دادهها برای استفاده در مسئله یادگیری ماشینی به کار گرفته میشود. هدف اصلی از نرمالسازی تغییر مقادیر عددی ستونهای دیتاست است تا بتوان بدون از دست دادن اطلاعات یا بر هم زدن تفاوتهای موجود در گستره مقادیر، به یک مقیاس رایج دست یافت.
>>> from sklearn.preprocessing import Normalizer >>> scaler = Normalizer().fit(X_train) >>> normalized_X = scaler.transform(X_train) >>> normalized_X_test = scaler.transform(X_test)
باینری کردن دادهها
باینری کردن یکی از عملیاتهای رایجی است که روی دیتاستها اجرای میشود. برای مثال در این روش تحلیلگر میتواند بهجای دفعات تکرار یک cheat sheet ویژگی، تنها بود یا نبود آن را درنظر بگیرد.
>>> from sklearn.preprocessing import Binarizer >>> binarizer = Binarizer(threshold=0.0).fit(X) >>> binary_X = binarizer.transform(X)
کد کردن ویژگیهای مقولهای
LabelEncoder یکی دیگر از کلاسهایی است که در مرحله پیش پردازش دادهها برای کد کردن سطوح کلاسها بهکار گرفته میشود. علاوه براین، میتوان از آن برای تبدیل برچسبهای غیر عددی به برچسبهای عددی نیز استفاده کرد.
>>> from sklearn.preprocessing import LabelEncoder >>> enc = LabelEncoder() >>> y = enc.fit_transform(y)
جایگزینی دادههای گمشده
کلاس Imputer در پایتون به شما استراتژیهایی برای پر کردن جای مقادیر گمشده ارائه میدهد. مقادیر گمشده با استفاده از میانگین، مقادیر میانه یا پرتکرارترین مقدار سطر یا ستونی که داده گمشده در آن قرار دارد، جایگزین میشوند. این کلاس همچنین ما را قادر میسازد تا مقادیر گمشده مختلف را به کد تبدیل کنیم.
>>> from sklearn.preprocessing import Imputer >>> imp = Imputer(missing_values=0, strategy='mean', axis=0) >>> imp.fit_transform(X_train)
تولید ویژگیهای چندجملهای
ویژگی چندجملهای یک ماتریس ویژگی جدید تولید میکند که حاوی تمامی ترکیبات چندجملهای ویژگیها با درجه کمتر یا مساوی یک درجه تعیینشده است. برای مثال، اگر یک نمونه ورودی دو بعدی و به صورت (a,b) باشد، ویژگیهای چندجملهای درجه ۲ آن به صورت (۱,a,b,a,ab,b) خواهد بود.
>>> from sklearn.preprocessing import PolynomialFeatures >>> poly = PolynomialFeatures(5) >>> poly.fit_transform(X)
مدل خودتان را بسازید
برآوردگر یادگیری نظارتشده
یادگیری نظارتشده نوعی از مدلهای یادگیری ماشینی است که پس از آموزش دیدن توسط دادهای برچسبدار قادر به پیشبینی نتایج آتی خواهد بود.
# Linear Regression Algorithm >>> from sklearn.linear_model import LinearRegression >>> lr = LinearRegression(normalize=True) # Naive Bayes Algorithm >>> from sklearn.naive_bayes import GaussianNB >>> gnb = GaussianNB() # KNN Algorithm >>> from sklearn import neighbors >>> knn = neighbors.KNeighborsClassifier(n_neighbors=5) # Support Vector Machines (SVM) >>> from sklearn.svm import SVC >>> svc = SVC(kernel='linear’)
برآوردگر یادگیری بدون نظارت
یادگیری بدون نظارت نیز نوع دیگری از مدلهای یادگیری ماشینی است که میتواند بدون آموزش دیدن توسط دادههای برچسبدار، نتایج آتی را پیشبینی کند.
# Principal Component Analysis (PCA) >>> from sklearn.decomposition import PCA >>> pca = PCA(n_components=0.95) # K Means Clustering Algorithm >>> from sklearn.cluster import KMeans >>> k_means = KMeans(n_clusters=3, random_state=0)
برازش مدل
برازش معیاری است برای قابلیت تعمیمیابی یک مدل یادگیری ماشینی برای دادههای مشابه با دادههایی که توسط آنها آموزش دیده است.
# For Supervised learning >>> lr.fit(X, y) #Fits data into the model >>> knn.fit(X_train, y_train) >>> svc.fit(X_train, y_train) # For Unsupervised Learning >>> k_means.fit(X_train)#Fits data into the model >>> pca_model = pca.fit_transform(X_train) #Fit to data, then transform it
پیشبینی
برازش معیاری است برای قابلیت تعمیمیابی یک مدل یادگیری ماشینی برای دادههای مشابه با دادههایی که توسط آنها آموزش دیده است.
# For Supervised learning >>> y_pred=svc.predict(np.random((2,5))) #predict label >>> y_pred=lr.predict(x_test) #predict label >>> y_pred=knn.predict_proba(x_test)#estimate probablity of a label # For Unsupervised Learning >>> y_pred=k_means.predict(x_test) #predict labels in clustering algorithm
ارزیابی عملکرد مدل
معیارهای دستهبندی
ماژول sklearn.metrics بهمنظور سنجش عملکرد دستهبندی، تعداد زیادی تابع زیان، امتیاز و مطلوبیت اجرا میکند.
# Mean Absolute Error >>> from sklearn.metrics import mean_absolute_error >>> y_true = [3, -0.5, 2] >>> mean_absolute_error(y_true, y_pred) # Mean Squared Error >>> from sklearn.metrics import mean_squared_error >>> mean_squared_error(y_test, y_pred) # R² Score >>> from sklearn.metrics import r2_score >>> r2_score(y_true, y_pred)
معیار خوشهبندی
# Adjusted Rand Index >>> from sklearn.metrics import adjusted_rand_score >>> adjusted_rand_score(y_true, y_pred) # Homogeneity >>> from sklearn.metrics import homogeneity_score >>> homogeneity_score(y_true, y_pred) # V-measure >>> from sklearn.metrics import v_measure_score >>> metrics.v_measure_score(y_true, y_pred)
معیارهای رگرسیون
ماژول sklearn.metrics بهمنظور سنجش عملکرد دستهبندی تعداد زیادی تابع زیان، امتیاز و مطلوبیت اجرا میکند.
# Accuracy Score >>> knn.score(X_test, y_test) >>> from sklearn.metrics import accuracy_score >>> accuracy_score(y_test, y_pred) # Classification Report >>> from sklearn.metrics import classification_report >>> print(classification_report(y_test, y_pred)) # Confusion Matrix >>> from sklearn.metrics import confusion_matrix >>> print(confusion_matrix(y_test, y_pred))
اعتبارسنجی متقاطع
>>> from sklearn.cross_validation import cross_val_score >>> print(cross_val_score(knn, X_train, y_train, cv=4)) >>> print(cross_val_score(lr, X, y, cv=2))
هماهنگ کردن مدل
جستوجوی مشبک
تابع GridSearchCV دو متد fit و score را اجرا میکند. همچنین اگر predict، predict_proba، decision_function، transform و inverse_transform در تخمینگر استفاده شده باشند، آنها را نیز اجرا میکند.
>>> from sklearn.grid_search import GridSearchCV
>>> params = {"n_neighbors": np.arange(1,3), "metric": ["euclidean", "cityblock"]}
>>> grid = GridSearchCV(estimator=knn, param_grid=params)
>>> grid.fit(X_train, y_train)
>>> print(grid.best_score_)
>>> print(grid.best_estimator_.n_neighbors)
بهینهسازی پارامتر تصادفی
تابع RandomizedSearchCV یک جستوجوی تصادفی روی ابرپارامترها انجام میدهد. این تابع برخلاف تابع GridSearchCV، تمامی مقادیر پارامترها را بررسی نمیکند، بلکه از هر توزیع معین تعداد ثابتی از پیکربندی پارامترها به عنوان نمونه انتخاب میشوند. تعداد پیکربندی پارامترهایی که تحت بررسی قرار خواهند گرفت توسط متغیر n_iter مشخص شده است.
>>> from sklearn.grid_search import RandomizedSearchCV
>>> params = {"n_neighbours": range(1,5), "weights":["uniform", "distance"]}
>>>rserach = RandomizedSearchCV(estimator=knn,param_distribution=params, cv=4, n_iter=8, random_state=5)
>>> rsearch.fit(X_train, Y_train)
>>> print(rsearch.best_score)
بارگیری چیتشیت پایتون برای کتابخانه سایکیت لرن
اگر به مطالعه مقالات محبوب درخصوص فناوریهای پرطرفدار همچون هوش مصنوعی، دواپس و هک قانونی علاقه دارید، میتوانید به وبسایت Edureka مراجعه نمایید.





















