
تقلید ادراک انسان با کمک هوش مصنوعیِ پیوندِ تصویر متا
تیم تحریریه
- ۲۵ اردیبهشت ۱۴۰۲
- زمان مطالعه 3 دقیقه
«پیوند تصویر» یک مدل هوش مصنوعی «کار مدل چندوجهی» ساخته کمپانی متا است که از یک نوع داده برای تولید انواع دادههای دیگر استفاده میکند؛ برای مثال، ImageBind میتواند از صدا، تصویر تولید کند یا برای تقویت سایر مدلهای چندوجهی استفاده شود.
متا از یک مدل هوش مصنوعی جدید رونمایی کرده است که ادراکی همچون ادراک انسان دارد و همچون انسان از قدرت تخیل برخوردار است؛ همانطور که انسان میتواند چشمهایش را ببندد و با شنیدن صدای گنجشک یا کلاغ تصویر آن را تجسم کند، این مدل از هوش مصنوعی نیز میتواند با گرفتن یک شکل از داده، انواع دیگری از داده را خلق کند. برای مثال این مدل که «پیوند تصویر» یا ImageBind نام دارد میتواند صدای هیاهو در یک خیابان شلوغ را بگیرد و مجموعه تصاویری از این خیابان تجسم کند.

در حقیقت این مدل منبع باز، برای شناخت «چگونگی درک» و «نحوه جذب اطلاعات» پیرامون انسان، توسط انسان ساختهشده است؛ با این مدل میتوان رباتها و ماشینهایی ساخت که همچون انسان فکر میکنند. تصور کنید یک ربات بتواند در یک خیابان شلوغ همچون انسان راه برود و تنها با شنیدن صداهای اطراف بداند که چه موجود یا ماشینی از پشت سر به او نزدیک میشود، بیآنکه به او نگاه کند.
ImageBind با استفاده از رویکرد چند حسی، از منابع اطلاعاتی مختلف بدون نیاز به نظارت صریح یاد میگیرد؛
این منابع دادههای مختلف را در یک «تمثیل یگانه» یا «فضای جایگزین» به هم پیوند میدهند.
پژوهشگران Meta میگویند: «ImageBind ماشینها را به درک جامعی مجهز میکند که اشیاء موجود در یک عکس را با چگونگی صدا، شکل سهبعدی آنها، میزان گرم یا سرد بودن آنها و چگونگی حرکت آنها، پیوند میدهد.»
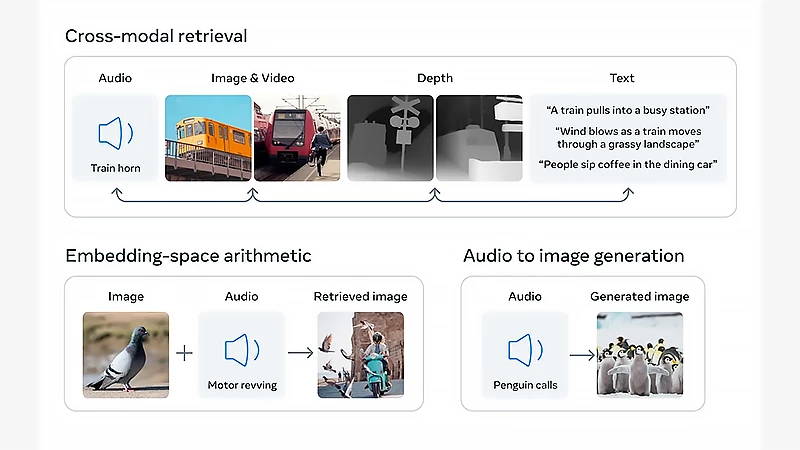
این مدل از هوش مصنوعی را میتوان با مدلهایی مانند DALLE-2 یا Make-a-Scene (زمانی که از پیش آموزشدیده باشند) ترکیب کرد، تا ورودیها را بهتر درک کند. همچنین این مدل میتواند برای بهبود مدلهای هوش مصنوعی موجود، مانند Meta’s Make-A-Scene، (با یک روش هوش مصنوعی مولد چندوجهی) استفاده شود، تا توانایی تولید تصاویر واقعگرایانه از ورودیهای متن را به بهترین شکل بهدست آورد.
همچنین متا استفاده از مدل ImageBind را برای بهکار انداختن مدل Make-A-Scene پیشنهاد میکند، تا در پیوند با یکدیگر بتوانند از صداهای موجود تصویر تولید کنند؛ مانند ایجاد یک تصویر بر اساس صداهای یک جنگل بارانی یا یک بازار شلوغ.
همچنین پژوهشگران متا ادعا میکنند که این مدل جدید هوش مصنوعی، میتواند برای کم کردن و کاستی از محتوا یا بهبود طراحی خلاقانه آن استفاده شود. این پژوهشگران بهطور بالقوه میتوانند از روشهای دیگر نیز بهعنوان پرسوجوهای ورودی در ImageBind، برای دریافت خروجی در قالبهای دیگر این مدل استفاده کنند.






















