
تکنیکهای دادهافزایی در یادگیری عمیق
تیم تحریریه
- ۲۷ بهمن ۱۴۰۰
- زمان مطالعه 7 دقیقه
افرادی که برای انجام پروژههای خود به دادههای تصویری احتیاج دارند، معمولاً اینگونه دادهها را جمعآوری میکنند و برخی مواقع نیز ترجیح میدهند دیتاستهای تصویری را از وبسایتها دانلود کنند. از جمله مشکلاتی که ممکن است در اینگونه دیتاستها وجود داشته باشد میتوان به کنتراست پایین، تفاوت در وضوح و توزیع نامتوازن در کلاسها Class imbalance اشاره کرد.
در معماریهای شبکههای عصبی عمیق، ابتدا با توجه به مسئلهای که قصد داریم به آن بپردازیم، یک معماری عمیق ایجاد میکنیم. برای مثال، برای حل مشکلی در زمینه طبقهبندی تصویر، ممکن است معماریای مبتنی بر شبکههای عصبی پیچشی ایجاد کنیم. پس از اتمام فرایند ایجاد معماری و یا مدل، بخشی از دادههای موجود را (دادههای آموزشی) به مدل تغذیه میکنیم(دادهافزایی). این فرایند، فرایند آموزش نامیده میشود و در طول این فرایند مدل، توزیع دادهها، الگوی دادهها و غیره را یاد میگیرد. پس از تکمیل فرایند آموزش، مدل میتواند بر اساس نکاتی که از تصاویر آموزشی یاد گرفته، تصاویر کاملاً جدید را طبقهبندی کند. البته برای اینکه مدل بتواند فرایند آموزش و یادگیری تصاویر را با موفقیت پشت سر بگذارد، دیتاست باید شرایط و ویژگیهای خاصی داشته باشد، در غیر اینصورت، پیش از تغذیه دادهها به مدل، عملیات پیشپردازش را نیز باید بر روی آنها اجرا کنیم.
مشکلاتی از قبیل کنتراست پایین و وضوح پایین را میتوان با استفاده از تکنیکهای رایج پردازش تصاویر رفع کرد. شبکههای عصبی عمیق در یادگیری تصاویر با کنتراست پایین با محدودیتهایی رو به رو هستند؛ مشکل کنتراست پایین تصاویر را میتوان با استفاده از تکنیکهای ارتقای کیفیت تصاویر از جمله تعدیل هیستوگرام Histogram Equalization، تعدیل هیستوگرام تطبیقی
Adaptive Histogram Equalization (AHE) (AHE) و تکنیکهای پیشرفته از جمله تعدیل هیستوگرام تطبیقی با کنتراست محدودکنتراست محدود Contrast Limited AHE (CLAHE) (CLAHE) رفع کرد. اما جالبترین و در عین حال چالش برانگیزترین آنها، مشکل توزیع نامتوازن در کلاسها است.
توزیع نامتوازن در کلاسها
توزیع نامتوازن در کلاسها که با نام “The Class Skew” نیز شناخته میشود، به توزیع نامتوازن نمونهها در کلاسها گفته میشود. در دیتاستهای طبقهبندی دودویی (دیتاستهایی که از دو کلاس- برای مثال کلاس منفی و مثبت- تشکیل شدهاند)، همچون دیتاست سگ و گربه، زمانی با مشکل توزیع نامتوازن در کلاسها مواجه میشویم که تعداد نمونهها در هر کلاس با هم برابر نباشد و یا تعداد نمونههایی که در دو کلاس قرار دارد، تفاوت زیادی با هم داشته باشد.
تعداد نمونههایی که در دو کلاس وجود دارد تقریباً باید با یکدیگر برابر باشد، در این حالت، مدل میتواند بدون هیچگونه سوگیری فرایند یادگیری را پشت سر بگذارد. اما در واقعیت ممکن است تعداد نمونههای موجود در کلاس اول کمتر و یا بیشتر از تعداد نمونههای موجود در کلاس دوم باشد. در چنین مواقعی مدل، کلاسی که تعداد نمونههای موجود در آن بیشتر از کلاس دیگر است را بهتر یاد میگیرد. و سرانجام مدلی بایاس خواهیم داشت که در کلاسی که نمونههای بیشتری داشته عملکرد بهتری دارد و پیشبینیهای دقیقتری برای آن انجام میدهد.
مشکل توزیع نامتوازان نمونهها در کلاسها در تمامی دیتاستها رخ میدهد. برای نمونه میتوان به دیتاست کلاسیفایر هرزنامههای ایمیل اشاره کرد که از دادههای جدولی تشکیل میشود و نمونههای موجود در آن به دو کلاس هرزنامه/ جعلی و اصلی تقسیم میشوند. چنانچه در کلاس هرزنامه تعداد زیادی نمونه وجود داشته باشد و در کلاس ایمیلهای اصلی تعداد کمی نمونه وجود داشته باشد، میگوییم نمونهها در کلاسهای دیتاست به صورت نامتوازن توزیع شدهاند. هیچیک از الگوریتمهای یادگیری ماشین نمیتوانند با چنین دیتاستی به درستی آموزش ببینند. برای رفع این مشکل میتوان از تکنیکهایی از جمله باز نمونهگیری و SMOTE استفاده کرد.
[irp posts=”۴۸۵۵″]بازنمونهگیری
بهترین و سادهترین تکنیک برای رفع مشکل توزیع نامتوازن نمونهها در دادههای جدولی، بازنمونهگیری است. در تکنیک بازنمونهگیری برای توزیع متوازن نمونهها در کلاسها، عملیات کم نمونهگیری و بیش نمونهگیری برای دستیابی به کلاسهای متوازن انجام میشود.
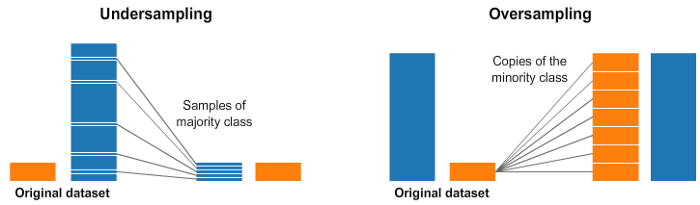
فرض کنید دیتاستی داریم که از دو کلاس تشکیل شده است و ۹۵ درصد از کل نمونهها در کلاس اول و ۵ درصد باقیمانده در کلاس دوم قرار دارند. همانگونه که در تصویر فوق نشان داده شده است برای رفع این مشکل، عملیات کم نمونهگیری را بر روی کلاس با تعداد نمونه بیشتر انجام میدهیم و بدین ترتیب میان این کلاس و کلاسی که نمونههای کمتری در خود جای داده است، توازن برقرار کنیم. به عبارت دیگر، به صورت تصادفی برخی از نمونهها/ مشاهدات را از کلاس بزرگ حذف میکنیم. اما از آنجاییکه در این روش برای برقراری توازن میان کلاسها، برخی از نمونه ار حذف میکنیم، برخی از اطلاعات از بین میروند. چنانچه کلاس غالب Majority class دادههای زیادی را در خود جای داده باشد و برخی از نمونههای اضافی را حذف کنیم، از بین رفتن برخی دادهها مشکل جدی به وجود نمیآورد.
در فرایند بیش نمونهگیری، کلاس اقلیت Minority class را به دفعات نمونهگیری میکنیم تا زمانیکه تعداد نمونههای موجود در آن با تعداد نمونههای موجود در کلاس غالب برابر شود. افزایش نمونهها باعث میشود نمونههای زیادی در کلاس اقلیت جای گیرد!
در ادامه با ذکر یک مثال این تکنیکها را توضیح میدهیم.
ابتدا دیتاستی مصنوعی ایجاد میکنیم که نمونهها در کلاسهای آن به صورت نامتوازن توزیع شدهاند. در این قسمت من با استفاده از ماژول دیتاست کتابخانه Keras یک دیتاست ایجاد میکنم.
from sklearn.datasets import make_classification #Import library
دیتاستی متشکل از ۱۰۰۰ نمونه ایجاد کنید و ۹۵ درصد از نمونهها را در کلاس ۰ و ۵ درصد باقیمانده دادهها را کلاس ۱ قرار دهید.
nb_samples = 1000 #Total number of samples. weights = (0.95, 0.05) #Percentage of split X, y = make_classification(n_samples = nb_samples, n_features = 2, n_redundant = 0, weights = weights, random_state = 1000)
در نهایت دیتاستی حاوی ۱۰۰۰ نمونه خواهیم داشت که دارای دو کلاس و دو ویژگی است و ۹۵ درصد از دادهها در یک کلاس و ۵ درصد باقیمانده در کلاس دیگر قرار دارند.
در مرحله بعد برای برقراری توازن میان نمونههای موجود در دو کلاس، عملیات بازنمونهگیری را بر روی دیتاست انجام میدهیم.
# Re-sampling process import numpy as np from sklearn.utils import resample X_1_resampled = resample(X[y == 1], n_samples = X[y == 0].shape[0], random_state = 1000) #Up-smapling #Conacatenate to get up-sampled Xu and yu. Xu = np.concatenate ((X[y == 0], X_1_resampled)) yu = np.concatenate ((y[y == 0], np.ones(shape = (X[y ==0].shape[0]), dtype = np.int32)))
و در آخر Xu را خواهیم داشت که تعداد نمونههای موجود در کلاس ۰ آن (Xu[y = = 0]) با تعداد نمونههای موجود در کلاس ۱ آن (Xu [y = = 1]) آن برابر است.
[irp posts=”۴۹۷۰″]SMOTE
یکی دیگر از متدهایی که میتواند به ما در حل مشکل توزیع نامتوازن نمونهها در کلاسها کمک کند، SMOTE ( تکنیک بیشنمونهگیری اقلیت مصنوعی Synthetic Minority Over-sampling Technique (SMOTE)) است. در تکنیکهای بازنمونهگیری، دادهها مجددا مورد استفاده قرار میگیرند، اما در این روش، در همسایگی نمونههای موجود در کلاسها، نمونه دادههای مصنوعی جدید تولید میشود.

SOMTE با توجه به روابط حاکم میان نمونهها، نمونههای مصنوعی جدیدی در همسایگی و مجاورت آنها تولید میکند.
نمونههای مصنوعی جدید بر روی خطی قرار میگیرند و به نمونههای کلاس اقلیت که در مجاورت آنها قرار دارند، متصل میشوند. ویژگیهای نمونههایی که در کلاسهای مجاور قرار دارند، تغییر نمیکنند. به همین دلیل SMOTE میتواند نمونههایی تولید کند که به همان توزیع اصلی تعلق داشته باشند. برخلاف روش بازنمونهگیری، در این روش، دیتاست جدید انحراف معیار بالاتری خواهد داشت و یک کلاسیفایر مناسب به آسانی میتواند ابرصفحه جداساز بهتری پیدا کند. بیش از ۸۰ نمونه متفاوت از SMOTE وجود دارد که برای انواع گوناگون دادهها طراحی شدهاند و کتابخانه imblearn متعلق به sci-kit learn تمامی این قابلیتها را دارا میباشد.
میتوانیم با استفاده از دادههای نامتوزن (X, y) به کار رفته در قسمت قبل مشکل توزیع نامتوازن نمونهها را حل کنیم.
#SMOTE from imblearn.over_sampling import SMOTE smote = SMOTE(random_state = 1000) X_resampled, y_resampled = smote.fit_sample(X, y)
توزیع نامتوازن نمونهها در دیتاستهای تصویری
دیتاستی به نام GTSRB (شاخص تشخیص علام راهنمایی و رانندگی آلمان) وجود دارد که شامل ۴۳ کلاس/ نوع مختلف از علائم راهنمایی و رانندگی است.

همانگونه که در تصویر مقابل نشان داده شده است، برخی از کلاسهای این دیتاست بیش از ۲۰۱۰ تصویر را در خود جای دادهاند و برخی دیگر از این کلاسها حاوی ۲۱۰ تصویر هستند.

نکتهای که باید به آن توجه داشته باشید این است که به سادگی نمیتوان مشکل توزیع نامتوازن نمونهها را در دیتاستهای تصویری حل کرد. از این روی، برای رفع مشکل توزیع نامتوازن در اینگونه دادهها باید از تکنیکهای پیشرفتهتری، به غیر از بازنمونهگیری و غیره، استفاده کنیم.
برای حل این مشکل میتوانیم از متد دادهافزایی تصویری Image data augmentation استفاده کنیم.
در متد دادهافزایی تصویری، میتوانیم تصویری را از میان دادهها موجود انتخاب کنیم و با اعمال برخی تکنیکها از جمله چرخش به راست، چرخش به چپ، و بزرگنمایی بر روی آن، تغییراتی در آن ایجاد میکنیم. نسخه تغییریافته تصاویر که در دیتاست آموزشی قرار دارند و به عنوان تصاویر اصلی به همان کلاس تعلق دارند، در این فرایند تولید میشوند.
تکنیکهای اعمال تغییر در تصاویر باید به درستی انتخاب شوند، در غیر اینصورت دیتاست قابل به استفاده نخواهد بود. برای مثال، میتوان تکنیک برگردان افقی را بر روی تصویر یک گربه اعمال کرد. برای اینکه ممکن است این تصویر از سمت چپ و یا از سمت راست گرفته باشد.
در مقابل، از آنجاییکه احتمال دارد مدل هرگز تصویر وارونهای از یک گربه ندیده باشد، اعمال تکنیک برگردان عمودی بر روی عکس یک گربه منطقی نیست. لذا آن دسته از تکنیکهای دادهافزایی که در دیتاست آموزشی مورد استفاده قرار میگیرند باید با دقت انتخاب شوند و مناسب دیتاست آموزشی باشند.
تکنیکهای مورد استفاده در دادهافزایی عبارتند از:
- تغییر عکس ( تغییر طول و تغییر عرض)
- برگردان جانبی عکس (افقی و عمودی)
- چرخش
- تنظیم روشنایی
- بزرگنمایی
- افزودن نویز
فرایند دادهافزایی را میتوان با استفاده از کلاس ImageDataGenerator متعلق به ماژول پیشپردازش تصویر Keras انجام داد.
در این قسمت قصد داریم عملیاتهای متفاوتی بر روی علامت راهنمایی و رانندگی مقابل انجام دهیم و بدین وسیله نمونهها را افزایش دهیم (تصویر مقابل در دیتاست GTSRB وجود ندارد. تصویر مقابل را برای ارائه مثال بهتر از اینترنت دانلود کردهام).

import matplotlib.pyplot as plt #For plotting
from keras.preprocessing.image import ImageDataGenerator #image data
generator.
from numpy import expand_dims
from keras.preprocessing.image import load_img
from keras.preprocessing.image import img_to_array
import cv2
from PIL import Image
%matplotlib inline
image = Image.open('gdrive/My Drive/Colab Notebooks/sign1.jpg')
plt.imshow(image)
plt.show()
در قدم اول، تکنیک “Random horizontal shift” را بر روی تصویر اعمال میکنیم.
datagen = ImageDataGenerator()
#Random horizontal shift
data = img_to_array(image)
samples = expand_dims(data, 0)
datagen = ImageDataGenerator(width_shift_range=[-200,200])
it = datagen.flow(samples, batch_size=1)
for i in range(9):
plt.subplot(330 + 1 + i)
batch = it.next()
image1 = batch[0].astype('uint8')
plt.imshow(image1)
plt.show()
در نتیجه اعمال این تکنیک بر روی عکس، تعداد تصویری خواهیم داشت که تغییراتی به صورت افقی در آنها به وجود آمده است.
[irp posts=”۲۲۹۴۱″]

در مرحله بعد تکنیک “Random Vertical Shift” را بر روی عکس اعمال میکنیم.
#Vertical shiftdata = img_to_array(image)
samples = expand_dims(data, 0)
datagen = ImageDataGenerator(height_shift_range=0.5)
it = datagen.flow(samples, batch_size=1)
for i in range(9):
plt.subplot(330 + 1 + i)
batch = it.next()
image2 = batch[0].astype('uint8')
plt.imshow(image2)
plt.show()
در نتیجه اعمال این تکنیک بر روی عکس، نمونههایی به این شکل خواهیم داشت:


تکنیک بعدی که بر روی عکس اعمال میکنیم “Random Rotation” است.
#Rotation
data = img_to_array(image)
samples = expand_dims(data, 0)
datagen = ImageDataGenerator(rotation_range=90) #Specify angle of rotation
it = datagen.flow(samples, batch_size=1)
for i in range(9):
plt.subplot(330 + 1 + i)
batch = it.next()
image4 = batch[0].astype('uint8')
plt.imshow(image4)
plt.show()
و در نتیجه تصاویر مشابه مقابل خواهیم داشت:

یکی دیگر از تکنیکهایی که میتوانیم بر روی تصویر اعمال کنیم، “Brightness adjustment” است:
#brightness adjustment
data = img_to_array(image)
samples = expand_dims(data, 0)
datagen = ImageDataGenerator(brightness_range=[0.2,1.0])
it = datagen.flow(samples, batch_size=1)
for i in range(9):
plt.subplot(330 + 1 + i)
batch = it.next()
image5 = batch[0].astype('uint8')
plt.imshow(image5)
plt.show()


تکنیک دیگری که میتوانیم بر روی تصاویر اعمال کنیم، Zooming است.
#Zooming
data = img_to_array(image)
samples = expand_dims(data, 0)
datagen = ImageDataGenerator(zoom_range=[0.5,1.0])
it = datagen.flow(samples, batch_size=1)
for i in range(9):
plt.subplot(330 + 1 + i)
batch = it.next()
image6 = batch[0].astype('uint8')
plt.imshow(image6)
plt.show()

پس از تکمیل فرایند دادهافزایی میتوانیم نمونهها را به صورت متوازن در کلاسها توزیع کنیم.
نکته: اعمال تمامی تکنیکها بر روی نمونههای تصویری کار دشواری نیست. چرا که اعمال تعداد تکنیک “random vertical flip” بر روی یکی از علائم راهنمایی و رانندگی، خورجی مناسب و قابل قبولی به ما نخواهد داد. برای مثال، اگر تکنیک برگردان افقی را بر روی یکی از علائم راهنمایی و رانندگی اعمال کنید، مدل یادگیری ماشین نمیتواند چیزی از این تصویر یاد بگیرد. به همین دلیل لازم است تکنیکهایی را انتخاب کنید که مناسب دیتاست شما است.
تکنیکهای دادهافزایی علاوه بر دیتاستهای تصویری، در دادههای جدولی و دادههای متنی نیز مورد استفاده قرار میگیرند. برای نمونه از تکنیکهای دادهافزایی در پردازش زبان طبیعی (NLP) استفاده میشود.





















