
هوش مصنوعی موفق شد گفتار را به زبانهای مختلف از روی حرکات لب تشخیص دهد
تیم تحریریه
- ۹ آذر ۱۴۰۱
- زمان مطالعه 2 دقیقه
در سالهای اخیر، تکنیکهای یادگیری عمیق به نتایج قابلتوجهی در بسیاری از وظایف زبان و پردازش تصویر دست یافتهاند. برای مثال، تشخیص بصری گفتار (VSR) که محتوای گفتار تنها با دقت در حرکات لب گوینده فهمیده شود. در حالی که برخی از الگوریتمهای یادگیری عمیق به نتایج بسیار امیدوارکنندهای در وظایف VSR دست یافتهاند، اما این الگوریتمها بیشتر برای تشخیص گفتههای دیگران به زبان انگلیسی آموزش دیدهاند و البته جای تعجب هم نیست، چون اکثر مجموعههای آموزشی به زبان انگلیسی هستند. در واقع، فقط کاربرانی میتوانند از آن استفاده کنند که به زبان انگلیسی صحبت میکنند.
محققان امپریال کالج لندن بهتازگی مدل جدیدی را توسعه دادهاند که میتواند وظایف VSR را به چندین زبان مختلف انجام دهد. در واقع، این مدل که در مقاله منتشرشده در Nature Machine Intelligence معرفی شد، از برخی مدلهای پیشنهادی قبلی بهتر عمل میکرد.
پینگچوان ما، که دکترای تخصصی تشخیص گفتار بصری (VSR) دارد، در این خصوص گفت: «در طول تحصیل، من بر روی چندین موضوع کار کردم و متوجه شدم که اکثریت قریببهاتفاق ادبیات موجود فقط با گفتار انگلیسی سروکار دارند.»
هدف اصلی مطالعه اخیر پینگچوان و همکارانش آموزش یک مدل یادگیری عمیق برای تشخیص گفتار در زبانهایی غیر از زبان انگلیسی بود، به طوری که از روی حرکات لب گویندگان بتوانند عملکرد آن را با سایر مدلهای آموزشدیده انگلیسی مقایسه کنند. این مدل شبیه مدلهایی است که پیشتر توسط تیمهای دیگر معرفی شده بود، با این تفاوت که برخی از پارامترهای فوقالعاده آن بهینهسازی شدهاند و به مجموعه دادهها افزوده شده بود.
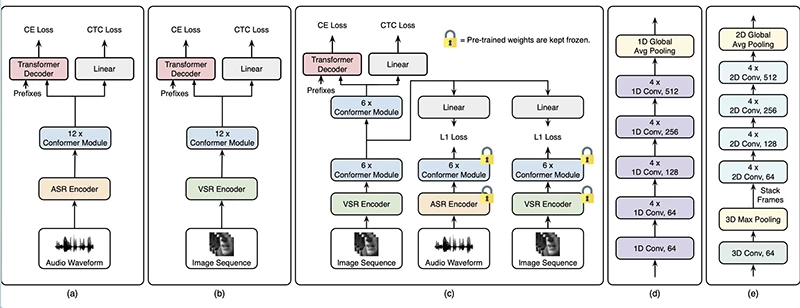
پینگچوان ما در این مورد توضیح داد: «ما نشان دادیم که میتوانیم از مدلهای مشابه برای آموزش مدلهای VSR به زبانهای دیگر استفاده کنیم. در واقع، مدل ما تصاویر خام را به عنوان ورودی میگیرد و سپس به طور خودکار یاد میگیرد که چه ویژگیهای مفیدی را از این تصاویر استخراج کند، تا وظایف VSR را کامل کند. تازگی این کار این است که ما مدلی را برای اجرای VSR آموزش میدهیم و مدلهایی را نیز اضافه میکنیم.»
در ارزیابیهای اولیه، مدل ایجادشده توسط پینگچوان ما و همکارانش عملکرد خوبی داشت و از دیگر مدلهای VSR آموزشدیده بهتر عمل کرد. بااینحال، همانطور که انتظار میرفت، به دلیل مجموعهدادههای کوچکتری که برای آموزش در دسترس بود، بهخوبیِ مدلهای تشخیص گفتار انگلیسی عمل نکرد.
پینگچوان ما در این باره گفت: «ما با طراحی دقیق مدل به جای استفاده از مجموعهدادههای بزرگتر یا مدلهای بزرگتر به نتایج پیشرفتهای در چندین زبان دست یافتیم. به عبارت دیگر، ما نشان دادیم که نحوه طراحی یک مدل برای عملکرد آن به همان اندازه مهم است که افزایش اندازه یا استفاده از دادههای آموزشی بیشتر آن. این به طور بالقوه میتواند منجر به تغییر روشی در تلاش محققان برای بهبود مدلهای VSR شود.»
پینگچوان ما و همکارانش نشان دادند که میتوان با طراحی دقیق مدلهای یادگیری عمیق، بهجای استفاده از نسخههای بزرگتر از همان مدل یا جمعآوری دادههای آموزشی اضافی که هم پرهزینه است و هم زمانبر، به عملکردهای پیشرفتهتری در وظایف VSR دست یافت. در آینده، کار آنها میتواند الهامبخش دیگر تیمهای تحقیقاتی باشد، تا بتوانند مدلهای جایگزین VSR را توسعه دهند. این کار میتواند گفتار را در زبانهایی غیر از زبان انگلیسی از حرکات لب تشخیص دهد.
جدیدترین اخبار هوش مصنوعی ایران و جهان را با هوشیو دنبال کنید





















