
کارکرد شبکههای عصبی در پردازش گفتار چگونه است؟
تیم تحریریه
- ۹ مهر ۱۴۰۱
- زمان مطالعه 2 دقیقه
قبل از آنکه به کاربردهای شبکههای عصبی در پردازش گفتار بپردازیم، باید کارکرد اصلی گفتار را مورد بررسی قرار دهیم. به احتمال بسیار زیاد، گفتار کارآمدترین راه برای برقراری ارتباط میان انسانهاست و انسانها با کمک پردازش گفتار در ذهن، به یکدیگر پیوند میخورند. این همچنین نشانگر آن است که گفتار میتواند میان انسان، ماشین و رایانه نیز پیوند ایجاد کند.
برای زمان درازی در مورد چگونگی بهبود این نوع ارتباطات پژوهشهای فراوانی انجام شده است؛ انسان با شناخت و دریافت چگونگی کارکرد الکترومغناتیس در این راه، در یک قرن گذشته پیشرفت چشمگیری داشته است. پردازش گفتار چنان مهم بود که حتی در قرن هجده و قبل از شناخت کاربردهای شبکههای عصبی، در آن زمان نیز پژوهشگران در حال آزمایش بر روی سنتز گفتار بودند. به عنوان مثال، در اواخر قرن هجدهم، «فون کمپلن» دانشمند آلمانی، ماشینی ساخت که قادر به گفتن کلمات و عبارات بود.
امروزه به لطف تکامل پردازشگرها، نهتنها گسترش، پیشرفت، آزمایش و پیادهسازی سیستمهای پردازش گفتار امکانپذیر شده، بلکه دیگر سیستمهای وابسته به فناوریهای هوش مصنوعی نیز گسترش چشمگیری داشتهاند. با اینهمه، فرآیند پردازش گفتار همچنان با مشکلات زیادی مواجه است و یکی از دلایل آن، میتواند این باشد که گفتار یک پدیده بسیار ذهنی است. درست در همینجاست که اهمیت «کاربردهای شبکههای عصبی» معلوم میشود؛ چرا که اصولاً ذهن و پدیدههای ذهنی در پیچوخم پردازش شبکههای عصبی مغز بهوجود میآیند.
اصلیترین مشکلات در پردازش گفتار
نخستین و مهمترین مشکل در پردازش گفتار، شناخت و تشخیص درست آن است.

به طور کلی برخی از رایجترین دلایلِ اشتباه در تشخیصِ گفتار عبارتند از:
- تنوع گوینده: در این مورد یک واژه میتواند به دلیل سن، جنس، تغییرات تشریحی، سرعت گفتار، شرایط احساسی گوینده و تغییرات گویشی، توسط افراد مختلف به شکلهای متفاوت تلفظ شود.
- نویز در پسزمینه: یک محیط نویز دار میتواند، نویز را نیز همراه با صدای گوینده به سیگنالهای صوتی اضافه کند. حتی خود گوینده نیز میتواند با نحوه صحبت کردنش نویز ایجاد کند.
- جنبه های فرابخشی: تأثیر لحن و تأکید بر هجاها. این جنبهها بر تلفظ یک کلمه تأثیر میگذارند.
- خصلت مداوم گفتار: وقتی صحبت میکنیم به ندرت بین کلمات فاصله میافتد. گفتار عمدتاً یک جریان بیوقفه از صداهاست. این امر تشخیص تکتک کلمات را بسیار سخت میکند.
- سایر عوامل خارجی؛ مانند موقعیت میکروفون نسبت به گوینده، جهت میکروفون و بسیاری موارد دیگر.
کارکرد شبکههای عصبی در پردازش گفتار
شبکههای عصبی از عناصر پردازشگر ساده که به صورت موازی کار میکنند، تشکیل شدهاند و کارکرد این شبکهها تا حد زیادی بر اساس پیوند میان عناصر تعیین میگردد. در همینحال ما میتوانیم یک شبکه عصبی را طوری آموزش دهیم که یک ورودی خاص را به یک خروجی هدفمند خاص منتهی کند. معمولاً از دو نوع گوناگون از شبکههای عصبی مانند «شبکه عصبی انتشار به عقب» و «شبکه عصبی توابع پایه شعاعی» برای تشخیص و پردازش گفتار استفاده میشود.

فرایند پردازش گفتار در هوش مصنوعی و شبکههای عصبی
به طور کلی فرآیند پردازش گفتار را میتوان به اجزای مختلفی تقسیم کرد که در شکل زیر نشان داده شده است.

مرحله نخست که در اینجا با واژه SPEECH نشان داده شده، از محیط صوتی و تجهیزات انتقال صدا مانند میکروفون تشکیل شده است؛ این مرحله، مرحله بازنمایی گفتارِ تولید شده و جمعآوری صداهای محیط است. برای مثال، نویزهای افزودنی یا طنین اتاق میتوانند در این مرحله تأثیر داشته باشند.
مرحله دوم، مرحله پیشپردازش نشانهها یا SIGNAL PREPROCESSING است. این مرحله در ابتدا نشانههای صوتی را استخراج و سپس با نویزهای اضافه مقابله میکند. در اینجا هم دریافت صداهای گفتار باید خوب باشد و هم سرکوب منابع نامربوط.
مرحله سوم، استخراج ویژگیها یا FEATURE EXTRACTION باید قابلیت استخراج ویژگیهای خاص گفتار از مرحله پیشپردازش را داشته باشد. این مرحله را میتوان با تکنیکهای مختلفی مانند آنالیز، سپستروم و طیفنگاری انجام داد.
مرحله چهارم، سعی میکند تا ویژگیهای استخراج شده را طبقهبندی کند و صدای ورودی را به بهترین صدای مناسب در یک مجموعه واژگان شناخته شده مرتب کند؛ این مجموعه واژگان به عنوان یک خروجی نشان داده میشود.
تکنیکهای رایج برای پردازش گفتار
- خم کردنِ زمان پویا: این تکنیک کلمات را با کلمات مرجع مقایسه میکند. در حقیقت هر کلمه مرجع، دارای مجموعهای از طیفهای گوناگون است، اما بین صداهای جداگانه در کلمه تمایزی وجود ندارد. از آنجایی که یک کلمه را میتوان با سرعتهای مختلف تلفظ کرد، باید زمان گفتار واژگان را بر اساس استاندارد معمول، عادی سازی کرد. خم کردن زمان پویا یک تکنیک برنامهنویسی است که در آن بعد زمانی کلمه ناشناخته تغییر میکند، کشیده و کوچک و بزرگ میشود تا زمانی که شباهتی با یک کلمه مرجع پیدا کند.
- مدلسازی پنهانی مارکوف: تاکنون این مدل، موفقترین و پرکاربردترین روش تشخیص الگو برای پردازش گفتار بوده است. این مدل ریاضی، بر اساس مدل مارکوف به دست آمده و بر اساس آن گفتار را پردازش میکند. در این مدل، گفتار و واژگان شفاهی به کوچکترین بخشهای شنیدنی تقسیم میشوند و نهتنها حروف صدادار و صامت، بلکه صداهای مزدوجی مانند ou، ea، eu نیز شناسایی و دستهبندی میشوند. همه این بخشهای کوچک به عنوان یک حالت معنیدار در مدل مارکوف نشان داده میشوند. وقتی یک واژه شفاهی وارد مدل پنهانی مارکوف میشود، با بهترین مدل موجود مقایسه میشود و با توجه به احتمالات موجود از یک حالت به حالت دیگر تغییر میکند.
به عنوان مثال: احتمال شروع کلمه با xq تقریبا صفر است. یک حالت همچنین میتواند یک دگرگونی بدون تغییر داشته باشد و صدا خود را تکرار کند. به نظر میرسد که مدلهای مارکوف در محیطهای پر سر و صدا بسیار خوب عمل میکنند، زیرا هر موجودیت صوتی جداگانه مورد بررسی قرار میگیرد. اگر واژه شفاهی در نویز گم شود، مدل ممکن است بتواند آن موجودیت را بر اساس احتمال رفتن از یک موجود صوتی به موجودیت دیگر حدس بزند.
- شبکههای عصبی: این مدلها شباهت بسیار زیادی به مدل مارکوف دارند و هر دو مدلهای آماری هستند که به صورت نمودار نمایش داده میشوند. در جایی که مدلهای مارکوف از احتمالات برای انتقال حالتهای گوناگون استفاده میکنند، شبکههای عصبی از نقاط قوت و توابع اتصال استفاده میکنند. یک تفاوت اصلی این است که شبکههای عصبی اساساً موازی هستند، در حالی که زنجیرههای مارکوف به صورت سریالی کار میکنند. در شبکههای عصبی، بسامدها در گفتار به صورت موازی اتفاق میافتند، در حالی که مجموعههای هجا و کلمات اساساً سریال هستند. این بدان معنی است که هر دو تکنیک در یک زمینه متفاوت بسیار قدرتمند هستند. در شبکههای عصبی، چالش تعیین وزن واژگان که مناسب اتصال شبکه باشند اهمیت دارد.
در بسیاری از سیستمهای پردازش گفتار، هر دو تکنیک با هم اجرا میشوند و در یک رابطه همزیستی کار میکنند. شبکههای عصبی برای یادگیری واجهای گوناگون از ورودی صوتی، به خاطر پردازش موازی کارکرد بسیار خوبی دارند، در حالی که مدلهای مارکوف میتوانند از احتمالات مشاهده واجهایی که شبکههای عصبی ارائه میکنند برای تولید محتملترین دنباله واجها یا کلمه استفاده کنند. این در هسته یک رویکرد ترکیبی برای درک زبان طبیعی است.
فرایند طبقهبندی نشانههای پردازش گفتار در شبکههای عصبی
ویژگیها و نشانههای گفتار بهطور متوالی در ورودیهای شبکه عصبی ارائه و در خروجی شبکه طبقهبندی میشوند.
این فرآیند در تصویر زیر نشان داده شده است.

پیادهسازی نشانههای پیشپردازشِ گفتار در شبکههای عصبی
پیشپردازشِ نشانهها، تأثیر زیادی بر کارکردِ طبقهبندی گفتار دارد. تغذیه شبکههای عصبی با ورودیهای نرمال مهم است؛ چرا که نمونههای ثبت شده، هرگز الگوهای یکسانی تولید نمیکنند. طول، دامنه، نویز و پسزمینه ممکن است متفاوت باشند. بنابراین ما نیاز به انجام پیشپردازشِ نشانهها داریم تا فقط اطلاعاتِ مربوط به گفتار را استخراج کنیم. این بدان معنی است که استفاده از ویژگیهای مناسب در نشانههای صوتی، برای طبقهبندی موفق بسیار مهم است. ویژگیهای خوب، طراحی یک طبقهبندی را ساده میکنند، در حالی که ویژگیهای ضعیف با قدرت تفکیک کم، بهسختی با هیچ طبقهبندی جور نمیشوند.
ما می توانیم این فرآیند را بر روی چند مرحله متمایز تقسیم کنیم مانند:
الف. ارئه گفتار: گفتار را میتوان با روشهای مختلفی نشان داد. بسته به موقعیت و نوع اطلاعات گفتار، یک حوزه بازنمایی ممکن است مناسب تر از دیگری باشد.
ب. طیفنگار: این دامنه، تغییر در طیف دامنهها را در طول زمان نشان میدهد و دارای سه بعد است:
محور X: زمان ms
محور Y: فرکانس
محور Z: شدت رنگ «نشان دهنده قدرت»
یک نمونه کامل، به بازههای زمانی مختلف تقسیم میشود. برای هر بازه زمانی، طیف فرکانس کوتاه مدت، محاسبه میشود. اگرچه طیفنگار، نمایشِ بصریِ خوبی از گفتار ارائه میکند، اما همچنان بین نمونهها به طور قابل توجهی متفاوت است. نمونهها هرگز دقیقاً در یک لحظه شروع نمیشوند، کلمات ممکن است، سریعتر یا آهستهتر تلفظ شوند و ممکن است در زمانهای مختلف، شدتهای متفاوتی داشته باشند.
ج. فرکانس «سِپِستروم و مِل» یا ضرایب سِپِستروم: گوش انسان برای فرکانسهای کمتر از یک کیلوهرتز، صداها را با مقیاس خطی میشنود و این در حالی است که برای فرکانسهای بالاتر از یک کیلوهرتز از مقیاس لُگاریتمی استفاده میکند. سِپِستروم و مِل، دو دانشمند حوزه پردازش گفتار و شبکههای عصبی، از این ویژگی انسانی برای شناسایی و پیشپردازش نشانههای صوتی و واژآواها استفاده کردهاند. مقیاسی با نام «مِلفرکانس» برای اندازهگیری این نشانهها در نظر گرفتهاند که برگرفته از نام دانشمندانی است که این اصل را طراحی کردهاند. یک فاصله فرکانسِ خطی، زیر ۱۰۰۰ هرتز و یک فاصله لُگاریتمی بالای ۱۰۰۰ هرتز است و سیگنالهای صوتی بیشترین انرژی خود را در فرکانسهای پایین دارند. به همینخاطر نیز از یک بانکِ فیلترِ فاصلهگذار استفاده میشود که نشانهها را بر این اساس مرتب میکند.
از فرمول زیر برای محاسبه «مِلفرکانس» در هر هرتز استفاده میشود:
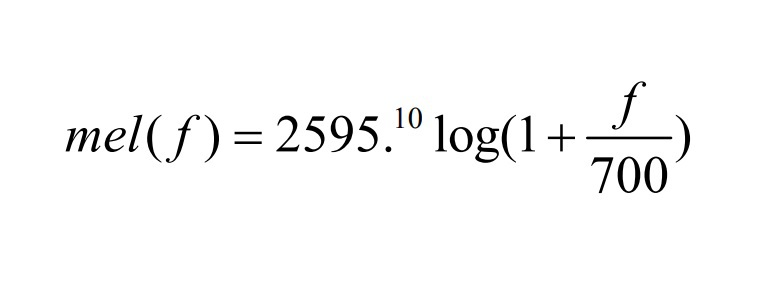
سپستروم، یک طیف را به «تبدیلِ فوریه» رو به جلو میرساند. تبدیل فوریه توابعی را که بر حسب زمان یا فضا هستند، به توابعی بر حسب فرکانس زمانی یا فضایی تجزیه میکند، مانند بیان یک مجموعه صدای هارمونیدار و هماهنگ که در یک کل خود را نشان میدهد، بر اساس حجم صداها و فرکانسهای نتهای تشکیل دهنده آن. اصطلاح «تبدیل فوریه» هم به نمایش دامنه فرکانس و هم به عملیات ریاضی مربوط به آن که نمایش دامنه فرکانس را به تابعی از مکان یا زمان مرتبط میکند، اطلاق میشود.
پس یک طیف، درونِ یک طیفِ دیگر است و این طیفِ درونی، دارای ویژگیهای خاصی است که به آن در آنالیز بسیاری از سیگنالهای گوناگون در شبکههای عصبی کمک میکند.
پیادهسازی شبکههای عصبی برای پردازش گفتار
به طور کلی معمولترین راه برای تشخیص و پردازش گفتار، همانا استفاده از شبکههای عصبی است؛ ولی شبکههای عصبی نیز، مانند هر راهکار دیگری به پیادهسازی نیاز دارند. در اینجا برای پیادهسازی از جعبهابزار شبکههای عصبیِ متلب MATLAB، برای بهوجود آوردن، آموزش و شبیهسازی شبکههای عصبی استفاده میشود.
به طور کلی دو نوع شبکه عصبی در میان شبکههای عصبی، برای پردازش گفتار بیشتر استفاده میشوند:
الف. شبکه چند لایه پیشخور: نخستین نوع از شبکههای عصبی که برای طبقهبندی گفتار در پردازش گفتار استفاده میشود، یک شبکه پیشخورِ چندلایه است که از الگوریتمهای انتشارِ برگشتی، برای آموزش شبکه عصبی استفاده میکند. این نوع شبکه عصبی، محبوبترین در میان شبکههای عصبی است و در سرتاسر جهان، در انواع برنامههای پردازش گفتار استفاده میشود. این شبکه از یک لایه ورودی، یک لایه پنهان و یک لایه خروجی تشکیل شده است.

ب. شبکه تابع پایه شعاعی: رویکرد دیگر برای طبقهبندی نمونههای گفتار در پردازش گفتار با شبکههای عصبی، استفاده از شبکه تابع پایه شعاعی است. این شبکه نیز مانند شبکه نخست از سه لایه تشکیل شده است: یک لایه ورودی، یک لایه پنهان و یک لایه خروجی. تفاوت اصلی این شبکه با شبکه چندلایه پیشخور، در این است که لایه پنهان دارای توابع نگاشت (گاوسی) است. از این شبکه بیشتر برای تخمینزدن تابع استفاده میشود؛ اما این شبکههای عصبی، همچنین میتوانند مشکلات طبقهبندی نشانههای گفتاری در پردازش گفتار را نیز حل کنند. «شعاعی» به این معنی است که آنها در اطراف مرکز خود، در شبکههای عصبی متقارن هستند؛ «توابع پایه» به این معنی است که یک ترکیب خطی از توابع آنها، میتواند تقریباً یک تابع دلخواه برای پردازش گفتار با شبکههای عصبی ایجاد کند.






















