
فرایادگیری با هوش مصنوعی عمومی
تیم تحریریه
- ۱۰ مرداد ۱۴۰۱
- زمان مطالعه 7 دقیقه
فرایادگیری Meta Learning واژه ای است که برای توصیف فرایند کنترل یادگیری و آگاهی از نحوه یادگیری افراد، مورد استفاده واقع شده و هماکنون نیز توسط متخصصان حوزه یادگیری ماشین استفاده میشود.
هوش مصنوعی موفقیتهای بزرگی در حوزههای گوناگون کسب کرده و کاربردهای آن روز به روز در حال گسترش است. اما مسئلهای که باید مورد توجه قرار داد این است که آموزشِ مدلهای شبکه عصبی سنتی به حجم بالایی از داده نیاز دارد. استفاده از این دادهها برای بهروزرسانیهای تکراری در نمونههای برچسبدار نیز مسئله مهمی به شمار میآید.
مثال سگ و گربه
میخواهیم مثال کلاسیکِ «طبقهبندی سگ و گربه» را با هم بررسی کنیم. اگرچه در دو دهه گذشته شاهد ارتقای چشمگیر مدلها و به تبعِ آن افزایش دقت مدلها بودهایم، اما مسائلی که در بالا اشاره شد، کماکان به قوت خود باقی هستند. به همین منظور، هنوز به تعداد بالایی از سگها و گربههای برچسبدار نیاز داریم تا دقت مدل را به میزان قابل توجهی افزایش دهیم.
فرض کنید ناگهان دو حیوان جدید به شما نشان میدهند. به راحتی تشخیص میدهید که کدامیک سگ و کدامیک گربه است. یقین داریم که انسانهای عادی با دقتِ ۱۰۰ درصدی این تفکیک را انجام میدهند. چگونه؟ ما در طی سالیان متمادی به شناخت کامل و دقیقی از ساختار بنیادی حیوانات رسیدهایم و از چگونگی استخراج ویژگیهایی نظیر شکل صورت، مو، دم، ساختار بدن و غیره به خوبی آگاه هستیم.
به طور خلاصه میتوان گفت که انسان موفق شده تواناییِ «یادگیری برای یادگیری» را در خود تقویت کند. فرایادگیری اساساً بر آن است تا یادگیری برای یادگیری را به واقعیت تبدیل و هوش مصنوعی را با کمترین میزان داده به سناریوهای گوناگون تعمیم دهد.
شاید بگویید که یادگیری انتقال هم دقیقاً همین کار را انجام میدهد. این فناوری در جهت درستی گام برداشته است، اما در حال حاضر نمیتواند ما را به مقاصد تهاییمان هدایت کند. پیشتر نیز در مواردی مشاهده شده که اگر اموری که شبکه بر مبنای آن آموزش دیده از هدف اصلی دور شود، مزایا و منافع شبکه از پیش آموزشدیده تا حد زیادی کاهش مییابد.
فرایادگیری این پیشنهاد را داده که مسئله یادگیری در دو سطح بررسی شود. سطح اول به اکتساب سریعِ دانش در هر یک از امور جداگانه مربوط میشود. سطح اول با سطح دوم رابطه تنگاتنگی داشته و به کمک آن به مسیر درست هدایت میشود. استخراج آهسته اطلاعات در سطح دوم انجام میشود.
الگوریتمهای فرایادگیری را میتوان به سه دسته تقسیم کرد:
روشهای مبتنی بر گرادیان کاهشی Gradient Descent کلاسیک
هدفی که این دسته از روشها دنبال میکنند، استفاده از بروزرسانیهای گرادیان کاهشی استاندارد برای ساخت شبکه عصبی و تعمیمِ آن برای انواع گوناگونی از دیتاست است. در این روش از چندین دیتاست که هر کدام مثال خودشان را دارند، استفاده میشود. فرض کنید مجموعۀ مجموعهدادهها با p(T) نشان داده میشود. مدلِ بکارگرفته شده در این مقاله را نیز تابع fₜₕₑₜₐ در نظر بگیرید. اگر کارمان را با پارامترهای θ آغاز کنیم، میدانیم که مدل در تکتکِ دیتاستها با بهروزرسانیِ گرادیان کاهش استاندارد همراه هستند.
میخواهیم مدلمان در طیف وسیعی از دیتاستها قابلیت کاربرد داشته باشد. بنابراین، باید مجموع همه خطاهای دیتاستهای ثبت شده در p(T) با پارامترهای بروزرسانی شده به دست آید. این فرایند به این شکل به زبان ریاضی بیان میشود:
برای هر بسته از پایگاه داده p(T)، ما θ را با توجه به تابع فرا-هدف فوق بوسیله SGD استاندارد بروز رسانی میکنیم
همانطور که ملاحظه میکنید،
پسانتشارِ back propagating meta-loss از طریق گرادیانِ مدل به محاسبۀ مشتقاتِ مشتق نیاز دارد. این کار میتواند با
ضرب بردار Hessian Hessian-vector products و پشتیبانیِ تنسورفلو انجام شود.
روشهای نزدیکترین همسایه
در این مجموعه از روشها، واضح است که الگوریتم نزدیکترین همسایه به هیچ آموزشی نیاز ندارد، اما عملکرد آن به متریک انتخاب شده بستگی دارد. این مراحل متشکل از یک مدل تعبیه و یک یادگیرنده پایه است که به ترتیب دامنۀ ورودی را به فضای ویژگی و فضای ویژگی را به متغیرها هدایت میکند. هدفِ فرایادگیری این است که مدل تعبیه به گونهای یاد گرفته شود که یادگیرنده به خوبی در همه کارها تعمیم داده شود. در این جا، پیشبینیِ فاصلهمحور در تعبیهها نقش اصلی را دارد.
شبکههای تطابق Matching networks برای درک بهتر این سازوکار مثال زده شده است.
شبکه تطابق از یک مجموعه k عنصری از عکس های برچسب زده شده S={(xᵢ ,yᵢ)} که جهت آموزش طبقه بند cₛ(x’) استفاده میشوند پشتیبانی میکنند. این طبقه بند برای داده آزمایش x’ یک تابع توزیع احتمال بر روی مجموعه خروجی y’ تعریف میکند.
طبقه S → cₛ(x’) به صورت P(y’|x’, S′) تعریف میشود که در آن P بوسیله یک شبکه عصبی تعیین میگردد.
بنابراین، با توجه به مجموعه پشتیبانیِ جدید مثالهای S′، که جهت
یادگیری یک باره ای one-shot learning استفاده میشود، میتوان به سادگی از شبکه عصبیِ پارامتریک P برای پیشبینیِ برچسب مناسب y’ در هر مثال آزمایشی x’ : P(y’|x’, S′) استفاده کرد. پس این طور بیان میشود:


روش فوق یادآورِ الگوریتمهای KDE و Knn است. f و g شبکههای عصبی مناسبی برای x و xᵢ هستند.
روشهای مدلمحور با استفاده از فضای کمکی
ما انسانها علاوه بر کارهای پردازشی، نمودارها و سایر ابزارهای نمایشی را برای کاربردهای آتی نگهداری میکنیم. پس این الگوریتمها سعی کردند با استفاده از چند بلوک حافظه کمکی از این کار تقلید کنند. راهبرد اساسی این است که انواع نمایشها برای قرارگیری در حافظه و چگونگی استفاده بعدی از آنها برای پیشبینی یاد گرفته شود. در این روشها، توالی ورودی و برچسبهای خروجی به صورت متوالی ارائه میشوند. در مجموعهدادۀ D ={dₜ}={(xₜ, yₜ)}، t نشاندهندۀ گام زمانی است.
برچسب خروجی yₜ بلافاصله پس از xₜ به دست نمیآید. این انتظار از مدل میرود که از برچسب مناسبی برای xₜ(i.e., yₜ) در گام زمانی مشخص خروجی بگیرد. بنابراین، مدل مجبور است نمونه دادهها را تا زمانی که برچسبهای مناسب یافت شوند، در حافظه ذخیره کند. پس از این اقدام، اطلاعات دسته و نمونه برای کاربردهای آتی ذخیره میشوند.
با توجه به ماژول حافظه در این اجرای خاص، میخواهیم مختصری هم درباره ماشین تورینگ عصبی (NTM) (Neural Turing Machine(NTM صحبت کنیم. NTM اساساً نوعی ماشین تورینگ مجهز به LSTM است. بازیابی و رمزگذاری حافظه در ماژول حافظه اکسترنال NTM به سرعت انجام میشود؛ نمایشهای برداری در هر گام زمانی در حافظه قرار داده شده یا از آن برداشته میشوند. این قابلیت باعث تبدیل شدنِ NTM به گزینهای عالی برای فرایادگیری و پیشبینی low-shot شده است چرا که ذخیرهسازی بلندمدت و کوتاهمدت را امکانپذیر میکند.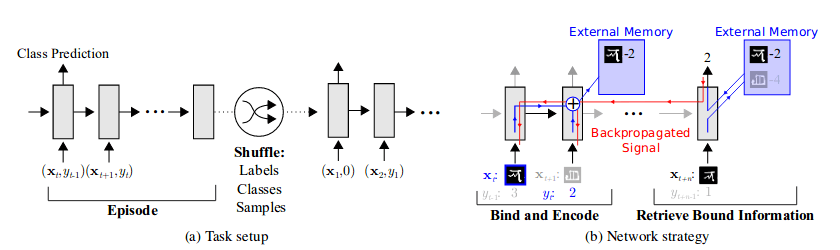
در گام زمانی t، کنترلکنندۀ LSTM کلید kₜ را برای دسترسی به ماتریس حافظه Mₜ فراهم میکند.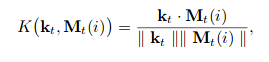
Softmax برای ایجاد بردارهای خواندن-نوشتن مورد استفاده قرار میگیرد.
فرمول زیر برای بدست آوردن حافظه rₜ استفاده میشود.
این فرمول به عنوان ورودی برای حالت کنترلکننده و همچنین دستهکنندههای softmax استفاده میشود.





















