
۹ الگوریتم یادگیری ماشین برتر را بشناسید
تیم تحریریه
- ۲۲ دی ۱۴۰۰
- زمان مطالعه 8 دقیقه
براساس مطالعات اخیر، انتظار میرود که در ده سال آینده انواع الگوریتم یادگیری ماشین جایگزین ۲۵% از مشاغل موجود در سرتاسر دنیا شوند. با رشد سریع کلان داده (Big Data) و آسانترشدن دسترسی به ابزارهای برنامهنویسی همچون پایتون و R، یادگیری ماشین دارد به پرکاربردترین ابزار دانشمندان داده تبدیل میشود. برنامههای کاربردی مبتنی بر یادگیری ماشین تا حد زیادی خودکار و خوداصلاحگرند و به این ترتیب، تقریباً بدون دخالت انسان و تنها با یادگیری به کمک دادهها، در طول زمان تکامل مییابند.
برای مثال الگوریتم پیشنهاددهنده (ریکامندر) نتفلیکس بر اساس ویدئوهایی که هر بیننده تماشا میکند، علایق تماشاگر را شناسایی کرده و نکات بیشتری دراینباره یاد میگیرد. الگوریتمهای تخصصی یادگیری ماشین بهمنظور شناسایی و رفع مشکلات و مسائل موجود در خصوص دادههای دنیای واقعی توسعه پیدا کردهاند. در این مقاله کوتاه، قصد داریم با معرفی برترین الگوریتمهای یادگیری ماشین به تازهکارانی کمک کنیم که با درک اصول اولیه یادگیری ماشین درگیرند.
دستهبندی الگوریتمهای یادگیری ماشین
الگوریتمهای یادگیری ماشین نظارتشده (Supervised Machine Learning Algorithms)
الگوریتمهایی هستند که مسائل را بر اساس دادههایی که به آنها داده شده، پیشبینی میکنند. این الگوریتمها به دنبال الگوهایی میگردند که در نقطه دادههای (data points) برچسبگذاریشده نهان است.
الگوریتمها یادگیری ماشین بدون نظارت (Unsupervised Machine Learning Algorithms)
در زمان استفاده از این الگوریتمها نقطه داده ها هیچگونه برچسبی ندارند. این قبیل الگوریتمهای یادگیری ماشین دادهها را بهنحوی در خوشههای مختلف سازماندهی میکنند که نشاندهندۀ ساختار آن باشد و دادههای پیچیده را سادهسازی میکنند تا بتوان از آنها در کارهای تحلیلی استفاده کرد.
الگوریتمهای یادگیری ماشین تقویتی (Reinforcement Machine Learning Algorithms)
این نوع از الگوریتمها ابتدا در ازای هر نقطه داده اقدامی در پیش میگیرند و سپس درستی تصمیم خود را میسنجند. الگوریتم یادگیری تقویتی میتواند در طول زمان استراتژی خود را تغییر دهد تا روند یادگیریاش تسریع شده و پاداش بیشتری دریافت کند.
۹ الگوریتم یادگیری ماشین که همه مهندسها باید بشناسند
- الگوریتم دستهبند بیز ساده (Naive Bayes Classifier Algorithm)
- الگوریتم خوشهبند k میانگین (K Means Clustering Algorithm)
- الگوریتم ماشین بردار پشتیبان (SVM) (Support Vector Machine Algorithm)
- الگوریتم آپریوری (Apriori Algorithm)
- رگرسیون خطی (Linear Regression)
- رگرسیون لجستیک (Logistic Regression)
- درخت تصمیم (Decision Tree)
- جنگل تصادفی (Random Forest)
- شبکههای عصبی مصنوعی(Artificial Neural Networks)
الگوریتم دستهبند بیز ساده
دستهبندی محتویات درون یک صفحۀ وب، سند ایمیل یا هرگونه متن طولانی دیگری بهصورت دستی سخت و عملاً غیرممکن است. الگوریتم دستهبند بیز ساده در چنین موقعیتی به کمک ما میآید. این دستهبند درواقع تابعی است که به هر داده یک مؤلفۀ جمعیتی از میان دستههای موجود نسبت میدهد. مثلاً میتوان از عمل جداسازی هرزنامهها (spam) نام برد که یکی از پرکاربردترین موارد بهکارگیری الگوریتمهای دستهبند بیز ساده هستند. در این حالت الگوریتم مذکور ایمیلهای ارسالی برای هر کاربر را به دو دستۀ «هرزنامه» و «غیرهرزنامه» تقسیم میکند.
الگوریتم دستهبند بیز ساده جزء محبوبترین الگوریتمهای یادگیری است که دادهها را بر اساس شباهتهایشان گروهبندی میکند. این الگوریتم بر پایۀ نظریۀ معروف بیز در احتمال بنا شده و از آن میتوان بهمنظور آموزش مدلهای یادگیری ماشین برای پیشبینی بیماریها و دستهبندی اسناد استفاده کرد. در تحلیل هدفمند محتوای مربوطه تنها کاری که انجام میشود دستهبندی واژهها به کمک قضیه بیز در احتمال است.
[irp posts=”۱۲۷۳۶″]در چه مواردی میتوانیم از الگوریتم دستهبندیکننده بیز ساده استفاده کنیم؟
- سایز دیتاست متوسط یا بزرگ است؛
- نمونهها خصوصیتهای زیادی دارند؛
- زمانی که پارامتر دستهبندی مشخص باشد، خصوصیتهای معرف نمونهها باید استقلال شرطی داشته باشند.
کاربردهای الگوریتم دستهبند بیز ساده
- تحلیل احساسات: فیسبوک از این الگوریتم برای تحلیل احساسات مثبت و منفی موجود در بهروزرسانیهای کاربران استفاده میکند.
- طبقهبندی اسناد: گوگل از دستهبندی اسناد برای فهرستبندی اسناد و امتیازدهی به میزان مربوطبودن آنها (پیجرنک) استفاده میکند مثلاً، سازوکار پیجرنک صفحاتی را که در پایگاه داده با استفاده از تکنیکهای تجزیه و تحلیل و دستهبندی اسناد نشان «مهم» دارند مدنظر قرار میدهد.
- از الگوریتم دستهبند بیز ساده همچنین برای دستهبندی مقالههای خبری در حوزههای فناوری، سرگرمی، ورزش، سیاست و غیره استفاده میشود.
- جداسازی هرزنامهها: سرویس ایمیل گوگل با استفاده از الگوریتم دستهبند بیز ساده ایمیلها را به دو دستۀ «هرزنامه» و «غیرهرزنامه» تقسیم میکند.

مزایای الگوریتم دستهبند بیز ساده
- در حالتی که دادههای ورودی طبقهبندیشده باشند، الگوریتم دستهبند بیز ساده عملکرد بسیار خوبی خواهد داشت.
- الگوریتم دستهبند بیز ساده بهسرعت همگرا میشود و وقتی فرض استقلال شرطی برقرار باشد، نسبت به مدلهای متمایزگر (رگرسیون لجستیک) به دادههای کمتری برای آموزش نیاز دارد.
- پیشبینی کلاس دیتاست آزمایشی برای الگوریتم دستهبند بیز ساده آسانتر است و میتوان گفت که در پیشبینیهای چندکلاسه نیز خوب عمل میکند.
- اگر چه الگوریتم دستهبند بیز ساده به فرض استقلال شرطی نیاز دارد، اما در برنامههای مختلف عملکرد خوبی داشته است.
الگوریتم خوشهبندی k میانگین
k میانگین در حوزه یادگیری ماشین بدون نظارت و برای تحلیل خوشهای بسیار پرکاربرد است. k میانگین از نوع روشهای غیرقطعی و مکرر است. این الگوریتم روی هر دیتاست دادهشده با توجه به تعداد خوشههای از پیش تعیینشدۀ آن (k) عملیات خاص را انجام میدهد. خروجی الگوریتم k میانگین، k عدد خوشه است که حاوی دادههای ورودی هستند که در k خوشه تقسیم شدهاند.
برای مثال، بیایید الگوریتم خوشهبندی k میانگین را برای نتایج جستوجو در وبسایت ویکیپدیا در نظر بگیریم. با جستوجوی واژۀ «جگوار» در ویکیپدیا، تمام صفحاتی که حاوی این واژه هستند نمایش داده خواهند شد. واژۀ جگوار در این صفحات ممکن است به نام خودرو، نام نسخۀ سیستم عامل Mac و یا نام حیوان اشاره کند. الگوریتم خوشهبندی k میانگین را میتوان به گروهی از صفحات وب که محتویات مشابهی دارند، اعمال کرد. به این ترتیب، این الگوریتم تمامی صفحاتی که حاوی این واژه هستند و منظور از جگوار در آنها یک حیوان است را در یک خوشه قرار میدهد. خوشۀ بعدی حاوی صفحاتی خواهد بود که به خودروی جگوار اشاره کردهاند و به همین ترتیب سایر خوشهها نیز ایجاد میشوند.
مزایای استقاده از الگوریتم یادگیری ماشین خوشهبندی k میانگین
- درخصوص مسئلۀ خوشههای کروی (globular clusters)، الگوریتم k میانگین خوشههای متراکمتری نسبت به روش خوشهبندی سلسلهمراتبی (hierarchical clustering) تولید میکند.
- برای مقادیر کوچک k و متغیرهای زیاد، خوشهبند k میانگین سریعتر از خوشهبندی سلسهمراتبی عمل میکند.
کاربردهای الگوریتم خوشهبندی k میانگین
الگوریتم خوشهبندی k میانگین عمدتاً توسط موتورهای جستوجویی همچون یاهو و گوگل استفاده میشود. این موتورهای جستوجو میخواهند صفحات وب را بر اساس شباهتشان خوشهبندی کنند و «نرخ مرتبطبودن» نتایج جستوجو را شناسایی کنند. این کار به موتورهای جستوجو کمک میکند تا زمان لازم برای محاسبات را کاهش دهند.
کتابخانههای علوم داده که در پایتون برای اجرای الگوریتم خوشهبندی k استفاده میشوند عبارتند از: SciPy، سایکیت لِرن (Sci-Kit Learn) و پوشش پایتون (Python Wrapper).
کتابخانۀ علوم داده که در زبان R برای اجرای الگوریتم خوشهبندی k استفاده میشود SciPy نام دارد.
الگوریتم یادگیری ماشین بردار پشتیبان (SVM)
ماشین بردار پشتیبان یک الگوریتم یادگیری ماشین نظارتشده است که برای دستهبندی و مسائل رگرسیون استفاده میشود. در چنین مسائلی، الگوریتم SVM با استفاده از دیتاست در ارتباط با کلاسها آموزش میبیند تا بتواند هر دادۀ جدید را دستهبندی کند. این الگوریتم دادهها را در دیتاستی که توسط یک خط (ابَرصفحه) به دو کلاس مجزا تقسیم شده، بین این دو کلاس دستهبندی میکند. از آنجا که تعداد زیادی از این ابرصفحههای خطی وجود دارد، الگوریتم SVM در تلاش است تا فاصلۀ میان کلاسهای مختلف را حداکثر کند، به این عمل حداکثرسازی حاشیه (margin maximization) گفته میشود. اگر خطی که حداکثرکنندۀ فاصلۀ میان کلاسهاست شناسایی شود، احتمال تعمیمیافتن الگوریتم و عملکرد خوب آن در مواجهه با دادههای ناشناس افزایش مییابد.
الگوریتمهای SVM به دو دسته تقسیم میشوند:
- الگوریتم SVM خطی: در این الگوریتم دادههای آموزش توسط یک ابرصفحه جدا میشوند.
- الگوریتم SVM غیرخطی: در این الگوریتم امکان جداسازی دادههای آموزش با استفاده از ابرصفحه وجود ندارد. برای مثال، دادههای آموزشی موردنیاز در الگوریتم تشخیص چهره حاوی دو گروه تصویر است؛ یک گروه تصاویر چهرۀ افراد است و گروه دیگر تصویر چهره نیست (به عبارتی هر چیزی هست مگر چهره). تحت چنین شرایطی، دادههای آموزش آنقدر پیچیدهاند که پیداکردن نماینده برای هر بردار ویژگی غیرممکن است. به همین ترتیب، جداسازی خطی دو گروه تصویر مذکور از یکدیگر کار بسیار پیچیدهای خواهد بود.
مزایای استفاده از الگوریتم SVM
- الگوریتم SVM در دستهبندی اشیا بسیار دقیق است و از لحاظ عملکرد بهترین الگوریتم موجود است.
- الگوریتم SVM نسبت به سایر الگوریتمها دقت بیشتری در دستهبندی دادههای آتی دارد.
- بهترین ویژگی الگوریتم SVM این است که هیچگونه فرض قویای برای دادهها تعریف نمیکند.
- این الگوریتم همچنین دادهها را بیشبرازش (over-fit) نمیکند.
کاربردهای الگوریتم ماشین بردار پشتیبان
الگوریتم SVM عموماً برای پیشبینی بازار بورس به کار میرود. برای مثال، از این الگوریتم میتوان برای مقایسۀ عملکرد نسبی سهم یک شرکت در برابر سهام سایر شرکتهای فعال در آن بخش استفاده کرد. مقایسۀ نسبی سهام به مدیران دارایی کمک میکند تا بر اساس دستهبندی انجامشده توسط الگوریتم یادگیری SVM تصمیمگیری کنند.
کتابخانههای علوم داده در پایتون برای الگوریتم ماشین بردار پشتیبان عبارتند از: سایکیت لِرن، PyML ، SVMStruct Python و LIBSVM.
الگوریتم یادگیری ماشین آپریوری
الگوریتم آپریوری یک الگوریتم یادگیری ماشین بدون نظارت است که بر اساس دادههای دیتاست دادهشده قوانین وابستگی (Association rules) تعریف میکند. قانون وابستگی میگوید که اگر A اتفاق بیافتد، B نیز حتماً پس از آن اتفاق خواهد افتاد. بدین ترتیب، اغلب قوانین وابستگی در قالب IF-THEN هستند. مثلاً، اگر مردم آیپَد بخرند، آنگاه باید یک قاب نیز بهعنوان محافظ برای آن بخرند. برای آنکه الگوریتم به چنین نتیجهای برسد، باید چند نفر را ببیند که در هنگام خرید آیپد برای آن قاب میخرند. به این ترتیب، به یک نسبت دست پیدا میکند؛ برای مثال، میگوید از هر ۱۰۰ خریدار آیپد، ۸۵ نفر برای آن قاب نیز میخرند.
اصول و سازوکار الگوریتم یادگیری ماشین آپریوری
- اگر مجموعهای از اتفاقات مکرراً رخ دهند، سپس تمامی زیرمجموعههای این مجموعهها نیز مکرراً اتفاق خواهند افتاد.
- اگر مجموعهای اتفاقات بهندرت رخ دهند، سپس تمامی زیرمجموعههای این مجموعهها نیز بهندرت اتفاق خواهند افتاد.
مزایای الگوریتم آپریوری
- اجرای این الگوریتم آسان است و بهسادگی موازیسازی میشود.
- برای پیادهسازی الگوریتم آپریوری از مجموعۀ بزرگی از ویژگیهای آیتم استفاده میشوند.
کاربردهای الگوریتم آپریوری
- شناسایی واکنش افراد نسبت به عوارض جانبی داروها (Detecting Adverse Drug Reactions): از الگوریتم آپریوری برای تجزیه و تحلیل وابستگی دادههای مراقبتهای بهداشتی استفاده میشود. برای مثال، این الگوریتم داروهای مصرفی بیماران، ویژگیهای هر بیمار، عوارض جانبی منفی که هر بیمار تجربه میکند، تشخیص اولیه و سایر موارد را بررسی میکند. در نتیجۀ این تجزیه و تحلیلها قوانین وابستگی تعریف میشوند که میتوانند به ما در شناسایی ترکیباتی از ویژگیهای بیماران و دارو که منجر به عوارض جانبی منفی میشوند، کمک کنند.
- تحلیل سبد بازار: بسیاری از غولهای دنیای تجارت الکترونیک از جمله آمازون برای آنکه بتوانند محصولاتی که مکمل یکدیگر هستند و معمولاً با هم خریداری میشوند را شناسایی کنند، از الگوریتم آپریوری استفاده میکنند. برای مثال، ممکن است یک خردهفروش از الگوریتم آپریوری استفاده کند تا برایش پیشبینی کند که افرادی که شکر و آرد میخرند، احتمالاً قصد دارند کیک بپزند، بنابراین، تخممرغ نیز خواهند خرید.
نرمافزارهای تکمیل خودکار (Auto-Complete Applications): سرویس تکمیل خودکار گوگل یکی دیگر از کاربردهای معروف الگوریتم آپرویوری است. به این ترتیب، زمانی که کاربر واژهای را مینویسد، موتور جستوجو بهدنبال واژههایی میگردد که سایرین در گذشته عموماً پس از آن واژۀ خاص نوشته و جستوجو کردهاند.


از میان کتابخانههای علوم داده، کتابخانه PyPi الگوریتم یادگیری ماشین آپریوری را با زبان پایتون اجرا میکند.
از کتابخانههای علوم داده در زبان R برای الگوریتم یادگیری ماشین آپریوری میتوان arules را نام برد.
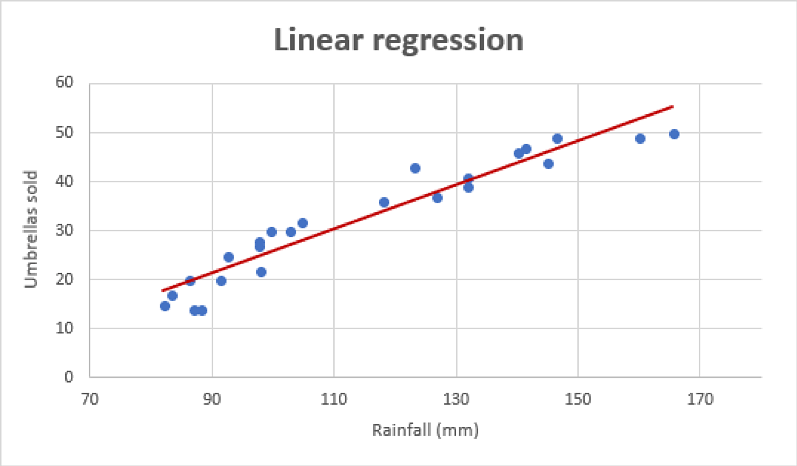
الگوریتم یادگیری ماشین رگرسیون خطی
الگوریتم رگرسیون خطی رابطۀ میان دو متغیر و تأثیری که تغییر یکی بر دیگری خواهد داشت را محاسبه میکند. این الگوریتم بیانگر تأثیری است که تغییر در متغیر مستقل بر متغیر وابسته خواهد گذاشت. متغیرهای مستقل، متغیر توضیحی نیز گفته میشوند، زیرا عوامل مؤثر بر متغیر وابسته را توضیح میدهند. غالباً از متغیر وابسته با نام عامل تحت نظر یا پیشبین نیز یاد میشود.
مزایای الگوریتم یادگیری ماشین رگرسیون خطی
- این الگوریتم یکی از تفسیرپذیرترین الگوریتمهای یادگیری ماشین است و توضیح دادن آن برای سایرین بسیار راحت است.
- استفاده از آن نیز راحت است، زیرا تنظیمات اندکی دارد.
- این الگوریتم در میان الگوریتمهایی که سرعت بالایی دارند، پرکاربردترین است.
کاربردهای الگوریتم یادگیری ماشین رگرسیون خطی
- برآورد فروش: الگوریتم رگرسیون خطی در دنیای کسبوکار و برای پیشبینی میزان فروش بر اساس ترندهای روز کاربردهای زیادی دارد. اگر میزان فروش ماهانۀ یک شرکت با نرخ ثابتی افزایش یابد، استفاده از روش تجزیه و تحلیل رگرسیون خطی روی دادههای فروش ماهانه به این شرکت کمک میکند تا فروش ماههای آتی خود را پیشبینی کند.
- برآورد ریسک: الگوریتم رگرسیون خطی همچنین میتواند به ما در برآورد ریسک فعالیتهای مالی و بیمه کمک کند. یک شرکت فعال در حوزۀ بیمۀ سلامت میتواند تجزیه و تحلیل رگرسیون خطی را روی تعداد ادعای خسارت به ازای هر مشتری در مقابل سن اعمال کند. این تجزیه و تحلیل به شرکت کمک میکند تا متوجه شود که مشتریان مسنتر بیشتر ادعای خسارت میکنند. چنین تحلیلهایی در تصمیمات کسبوکارها نقش اساسی دارد و بهمنظور محاسبۀ عامل ریسک در فرایند تصمیمگیری انجام میشوند.
کتابخانههای علوم دادۀ زبان پایتون برای الگوریتم یادگیری ماشین رگرسیون خطی عبارتند از: statsmodel و سایکیت (SciKit).
کتابخانۀ علوم داده در زبان R برای الگوریتم یادگیری ماشین رگرسیون خطی stats است.
الگوریتم یادگیری ماشین رگرسیون لجستیک
نام این الگوریتم ممکن است اندکی غلطانداز باشد، زیرا الگوریتم یادگیری ماشین رگرسیون لجستیک برای مسائل دستهبندی به کار میرود نه مسائل مربوط به رگرسیون. کلمۀ «رگرسیون» در نام این الگوریتم نشانگر یک مدل خطی است که بر فضای ویژگیها اعمال میشود. این الگوریتم یک تابع لجستیک را به ترکیب خطی ویژگیها اعمال میکند تا خروجیِ متغیر وابستۀ طبقهای (categorical dependent variable) بر اساس متغیر پیشبین پیشبینی شود.
بخت یا احتمالاتی که خروجی یک آزمایش را تعریف میکنند به صورت یک تابع متشکل از متغیرهای توصیفی مدل میشوند. الگوریتمهای رگرسیون لجستیک برای محاسبۀ احتمال قرارگرفتن در سطح مشخصی از متغیر وابستۀ طبقهای برحسب متغیرهای پیشبین دادهشده به ما کمک میکنند.
برای مثال، فرض کنید میخواهید احتمال بارش برف را در شهر نیویورک پیشبینی کنید. در اینجا خروجی پیشبینی عددی پیوسته نیست، زیرا در این حالت تنها دو احتمال وجود دارد: برف ببارد یا نبارد. بنابراین، نمیتوان از الگوریتم رگرسیون خطی استفاده کرد. چون متغیر خروجی در یکی از دستههای مذکور قرار میگیرد، میتوان از الگوریتم رگرسیون لجستیک استفاده کرد.
انواع رگرسیون لجستیک
- رگرسیون لجستیک دودویی یا دوسطحی (Binary Logistic Regression): این رگرسیون رایجترین نوع رگرسیون لجستیک در مسائلی است که با دو خروجی (مثل آره و نه) سروکار دارند. برای مثال، برای پیشبینی قبولی یک دانشآموز در امتحان، برای پیشبینی فشارخون دانشآموزان یا پیشبینی اینکه یک تومور سرطانی است یا نه، میتوان از رگرسیون لجستیک باینری استفاده کرد.
- رگرسیون لجستیک چندسطحی (Multi-nominal Logistic Regression): در این نوع از رگرسیون لجستیک تعداد خروجیهای احتمالی سه عدد یا بیشتر است، اما خروجیها ترتیب خاصی ندارند. برای مثال، پیشبینی موتور جستوجویی (یاهو، بینگ، گوگل یا MSN) که در میان کاربران آمریکایی رایجتر است.
- رگرسیون لجستیک ترتیبی (Ordinal Logistic Regression): در این نوع از رگرسیون لجستیک تعداد خروجیهای احتمالی ۳ عدد یا بیشتر است و خروجیها ذاتاً دارای ترتیب هستند. برای مثال، امتیازی که یک مشتری بین ۱ تا ۱۰ به کیفیت غذا و خدمترسانی یک رستوران میدهد.
بیایید یک مثال ساده را با هم بررسی کنیم. فرض کنید یک تولیدکنندۀ کیک قصد دارد تأثیر درجه حرارت فر در هنگام پخت کیک را بر میزان نرمی یا سفتی کیک برآورد کند. یعنی اگر دمای فر روی ۱۶۰، ۱۸۰ و ۲۰۰ درجۀ سانتیگراد تنظیم شود، کیک «نرم» خواهد بود یا «سفت» (در اینجا فرض این است که این شیرینیفروشی هر دو نوع کیک را میفروشد؛ البته با اسامی و قیمتهای مختلف). مناسبترین تکنیک آماری برای حل این مسئله رگرسیون لجستیک است.
مثلاً، فرض کنید کیکپز دو دسته کیک میپزد که دستۀ اول شامل ۲۰ کیک است (که ۷تای آنها سفت و ۱۳تا نرم هستند) و دستۀ دوم شامل ۸۰ کیک (متشکل از ۴۱ کیک سفت و ۳۹ کیک نرم). در این حالت، اگر از رگرسیون خطی استفاده کنیم، اهمیت هر دو دسته برای آن یکسان خواهد بود و تعداد کیکهای موجود در دستهها در نظر گرفته نمیشود. اما رگرسیون لجستیک این عامل را مدنظر قرار میدهد و به دستۀ دوم وزن بیشتری از دستۀ اول میدهد.
[irp posts=”۱۰۵۴۴″]چه زمانی از الگوریتم یادگیری ماشین رگرسیون لجستیک استفاده کنیم؟
- زمانی از الگوریتمهای رگرسیون لجستیک استفاده میکنیم که بخواهیم احتمالات مربوط به متغیرهای پاسخ را که تابعی از چند متغیر توضیحی هستند مدل کنیم. برای مثال، احتمال خرید کالای X که خود تابعی از جنیست افراد است.
- زمانی از الگوریتمهای رگرسیون لجستیک استفاده میکنیم که بخواهیم احتمالاتی را پیشبینی کنیم که متغیر وابستۀ طبقهای آن در دو دسته یا دو سطح قرار دارد و خود تابعی از تعدادی از متغیرهای توضیحی است. برای مثال، احتمال خرید نوعی عطر توسط یک مشتری درصورتیکه جنسیت وی مونث باشد.
- الگوریتمهای رگرسیون لجستیک برای مسائلی که در آن میخواهیم عناصر را بر اساس متغیر توصیفی در دو گروه دستهبندی کنیم، بسیار مناسباند. برای مثال، دستهبندی زنان در دو گروه «پیر» و «جوان» بر اساس سن آنها.
مزایای استفاده از الگوریتم رگرسیون لجستیک
- کنترل آن آسان است و پیچیدگی ندارد.
- الگوریتم قدرتمندی است، زیرا لازم نیست متغیرهای مستقل آن حتماً واریانس برابر یا توزیع نرمال داشته باشند.
- فرض خطیبودن رابطۀ بین متغیرهای مستقل و وابسته در این الگوریتم مطرح نیست، بنابراین، میتوان اثرات غیرخطی را نیز برآورد کرد.
- این الگوریتم نابهنجاریها را کنترل و تعاملات را آزمون میکند.
معایب استفاده از الگوریتم رگرسیون لجستیک
- اگر دادههای آموزشی پراکنده باشند و ابعاد زیادی داشته باشند، مدل لجستیک ممکن است باعث بیشبرازش دادههای آموزش شود.
- الگوریتمهای رگرسیون لجستیک توانایی پیشبینی خروجیهای پیوسته را ندارند. برای مثال، زمانی که هدف تعیین میزان و شدت بارش باران باشد، نمیتوان از الگوریتم رگرسیون لجستیک استفاده کرد، زیرا مقیاس اندازهگیری میزان بارش پیوسته است. دانشمندان داده میتوانند بارندگیهای شدید و کمشدت را پیشبینی کنند، اما این کار ممکن است به دقت دیتاست لطمه وارد کند.
- در این الگوریتم خروجیها برحسب یک گروه از متغیرهای مستقل پیشبینی میشوند و اگر دانشمند داده یا متخصص یادگیری ماشین در شناسایی متغیرهای مستقل مرتکب خطا شود، ارزش پیشبینی آن مدل کمینه یا صفر میشود.
- این الگوریتم در مواجهه با دادههای پرت و مقادیر گمشده عملکرد ضعیفی دارد.
کاربردهای الگوریتم رگرسیون لجستیک
- الگوریتمهای رگرسیون لجستیک در حوزۀ بیماریهای مسری به کار گرفته میشود تا عوامل ریسک بیماریها را شناسایی کرده و بر اساس آن اقدامات پیشگیرانه را برنامهریزی کند.
- الگوریتمهای رگرسیون لجستیک برای پیشبینی پیروزی یا شکست نامزدهای انتخاباتی استفاده میشوند.
- الگوریتمهای رگرسیون لجستیک بهمنظور دستهبندی واژهها در گروههای اسم، حرف اضافه، فعل و صفت نیز به کار میروند.
- الگوریتمهای رگرسیون لجستیک برای پیشبینی آبوهوا یا پیشبینی احتمال بارش باران استفاده میشوند.
- الگوریتمهای رگرسیون لجستیک در سیتسمهای اعتبارسنجی نیز به کار گرفته میشوند تا ریسکهای موجود را مدیریت کرده و احتمال برگشتخوردن یک حساب را پیشبینی کنند.
کتابخانۀ پایتون استفادهشده در حوزۀ الگوریتم یادگیری ماشین رگرسیون لجستیک سایکیت لِرن است.
کتابخانۀ زبان R استفادهشده در حوزۀ الگوریتم یادگیری ماشین رگرسیون لجستیکstats package (glm ()) است.
الگوریتم یادگیری ماشین درخت تصمیم
فرض کنید درحال برنامهریزی تعطیلات خود هستید و قصد دارید سری به بهترین رستوران شهر بزنید، اما در انتخاب رستوران شک دارید. هر زمان میخواهید به رستوران بروید نظر دوستتان، تایریون، را دراینباره میپرسید. تایریون برای پاسخ به این سؤال ابتدا باید سلیقۀ شما را درخصوص رستورانها بداند. بنابراین، شما فهرستی از رستورانهایی که تابهحال رفتهاید به او میدهید و میگویید کدامیک را دوست داشتهاید و از کدام خوشتان نیامده است (برچسبدارکردن دادههای دیتاست).
به این ترتیب، وقتی از تایریون میپرسید که رستوران R چطور است، او نیز چند سؤال از شما میپرسد: «آیا رستوران R روی پشتبام است؟»، «رستوران R غذای ایتالیایی نیز سرو میکند؟»، «آیا در رستوران R موسیقی زنده اجرا میشود؟»، «آیا رستوران R تا پاسی از شب باز است؟» و غیره. تایریون با پرسیدن این سؤالات حداکثر اطلاعات ممکن را از شما میگیرد و درنهایت، براساس پاسخهای شما به سؤالاتش یک پاسخ «بله» یا «خیر» به شما میدهد. در این مثال تایریون برای تنظیم ترجیحات شما در انتخاب رستوران، نقش درخت تصمیم را بازی کرد.
درخت تصمیم یک بازنمایی گرافیکی از دادههاست که بهمنظور نمایش تمامی عواقب یک تصمیم بر اساس شرایط معین از روش شاخهای استفاده میکند. در یک درخت تصمیم، گره داخلی آزمونی روی صفات انجام میدهد، هر شاخۀ درخت نشانگر نتیجۀ آن آزمون است و برگهای درخت نیز نماد یک کلاس مشخص هستند. تصمیم نهایی پس از محاسبۀ تمامی صفات گرفته میشود. قوانین طبقهبندی نیز در طی مسیر (از ریشه تا گرههای برگی) اعمال میشوند.

انواع درخت تصمیم
درختهای طبقهبند (Classification Trees): برای تقسیمبندی یک دیتاست به کلاسهای مختلف بر اساس متغیر پاسخ، بهصورت پیشفرض از این نوع از درختهای تصمیم استفاده میشود. این الگوریتم زمانی به کار گرفته میشود که متغیر پاسخ ذاتاً طبقهای باشد.
درختهای رگرسیون (Regression Trees): زمانی که متغیر پاسخ یا هدف پیوسته یا اسمی باشد، از درخت رگرسیون استفاده میکنیم. این الگوریتم به جای مسائل طبقهبندی عموماً در مسائل پیشبینی استفاده میشود.
علاوه براین، درخت تصمیم را میتوان از منظر متغیر هدف نیز به دو دسته تقسیم کرد: درخت تصمیم متغیرهای پیوسته و درخت تصمیم متغیرهای دودویی. در این حالت، متغیر هدف است که مشخص میکند کدام نوع درخت تصمیم باید استفاده شود.

چرا باید از الگوریتم یادگیری ماشین درخت تصمیم استفاده کنید؟
- این قبیل الگوریتمهای یادگیری ماشین به ما در تصمیمگیری تحت شرایط نااطمینانی کمک میکنند و همچنین از آنجا که این الگوریتمها یک بازنمایی بصری از وضعیت تصمیم ارائه میدهند،
- به کمک آنها میتوانید بهتر با دیگران ارتباط برقرار کنید.
- الگوریتمهای یادگیری ماشین درخت تصمیم به دانشمندان داده کمک میکنند تا بتوانند پیشبینی کنند که اگر تصمیم دیگری گرفته شود، عملکرد مدل یا وضعیت چه تغییری خواهد کرد.
- الگوریتمهای درخت تصمیم با فراهمکردن امکان حرکت به جلو و عقب در مسیرهای محاسبه به دانشمند داده در گرفتن بهترین و بهینهترین تصمیم کمک میکنند.
چه وقت از الگوریتمهای یادگیری ماشین درخت تصمیم استفاده کنیم؟
- الگوریتمهای درخت تصمیم در برابر خطا مقاوماند و اگر خطایی در دادههای آموزش یک مسئله وجود داشته باشد، الگوریتمهای درخت تصمیم بهترین انتخاب برای حل آن مسئله هستند.
- بهترین الگوریتم برای حل مسائلی که در آنها نمونههایی با مقادیر ویژگی جفتی وجود دارد درخت تصمیم است.
- اگر در دادههای آموزشی مقادیر گمشده وجود داشته باشد، میتوان از درخت تصمیم استفاده کرد، زیرا این الگوریتمها در مواجهه با دادههای گمشده و ستونهای خالی بهراحتی از آن میگذرند و به سراغ ستون بعدی میروند.
- همچنین زمانی که مقادیر خروجی تابع هدف طبقهای باشند نیز بهترین گزینه برای ما درخت تصمیم است.
مزایای الگوریتم یادگیری ماشین درخت تصمیم
- این الگوریتم با غریزۀ انسان همخوانی دارد. همین مسئله توضیحدادن آن را برای دیگران آسان میکند. حتی افرادی که پیشینۀ فنی و مهندسی ندارند نیز میتوانند فرضیههایی را که این الگوریتم ارائه میدهد درک کنند، زیرا بسیار قابلفهم هستند.
- در زمان استفاده از الگوریتم یادگیری ماشین درخت تصمیم نوع دادهها برای شما محدودیت ایجاد نمیکند، زیرا این الگوریتمها هم از دادههای طبقهای و هم عددی پشتیبانی میکنند.
- در الگوریتمهای یادگیری ماشین درخت تصمیم لازم نیست دادهها خطی فرض شوند و بنابراین، میتوان از آنها در شرایط با پارامترهای غیرخطی نیز استفاده کرد. علاوهبراین، این الگوریتم هیچ فرضی برای ساختار دستهبندی و توزیع متصور نیست.
- این الگوریتمها در حوزۀ جستوجو و بررسی دادهها نیز کارآمد هستند. الگوریتمهای درخت تصمیم بهطور غیر مستقیم عمل برگزیدن ویژگی را نیز انجام میدهند که در تحلیلهای پیشبین اهمیت دارد. وقتی الگوریتم درخت تصمیم را روی یک دیتاست آموزش اعمال میکنید، گرههای بالایی که پیش از دوشاخهشدن درخت قرار گرفتهاند، متغیرهای مهم دیتاست را مدنظر قرار میدهند و به این ترتیب، عمل برگزیدن ویژگیها انجام میشود.
- استفاده از الگوریتمهای درخت تصمیم منجر به صرفهجویی در زمان لازم برای آمادهسازی دادهها میشود، زیرا نسبت به دادههای پرت و گمشده حساس نیستند. دادههای گمشده مانع تقسیم دادهها و تشکیل درخت تصمیم نمیشوند و از آنجا که تقسیمات به جای مقادیر مطلق برحسب نمونههای موجود در گستره تقسیم میشوند، دادههای پرت نیز تأثیری بر درخت تصمیم نخواهند داشت.
معایب الگوریتم یادگیری ماشین درخت تصمیم
- هرچه تعداد تصمیمات در یک درخت بیشتر باشد، دقت خروجیهای آن کمتر خواهد شد.
- یکی از مهمترین ضعفهای الگوریتم یادگیری ماشین درخت تصمیم این است که خروجیهای آن ممکن است مطابق با انتظارات نباشند. وقتی تصمیمات بهصورت آنی گرفته میشوند، نتایج نهایی ممکن است مطابق انتظار یا برنامۀ ما نباشند. بنابراین محتمل است که تصمیمات غیرواقعی و درنتیجه بد و غیربهینه توسط درخت تصمیم گرفته شود. هرگونه انتظار غیرمعقول میتواند منجر به خطاهایی بزرگ و درنتیجه ناکارآمدی تحلیلهای درخت تصمیم شود، زیرا در این حالت نمیتوان تمامی عواقب احتمالی یک تصمیم را شناسایی کرد.
- الگوریتمهای درخت تصمیم برای دادههای پیوسته مناسب نیستند و منجر به بیثباتی و مسطحشدن دستهبندی میشوند.
- استفاده از درخت تصمیم در مقایسه با سایر مدلهای تصمیمگیری راحتتر است، اما ایجاد درخت تصمیمی که چندین شاخه داشته باشد، کاری پیچیده و زمانبر است.
- الگوریتمهای یادگیری ماشین درخت تصمیم در هر زمان تنها یک خصوصیت را در نظر میگیرند و ممکن است برای دادههای واقعی موجود در فضای تصمیم چندان مناسب نباشند.
- درختهای تصمیم بزرگ که دارای شاخههای متعدد هستند، تفسیرپذیر نیستند و بازنمایی آنها دشوار است.
کاربردهای الگوریتمهای یادگیری ماشین درخت تصمیم
- درخت تصمیم در میان الگوریتمهای یادگیری ماشین در حوزۀ مالی محبوبترین الگوریتم به شمار میآید.
- سنجش از دور (Remote sensing) یکی از موارد کاربرد الگوریتمهای درخت تصمیم مبتنی بر شناسایی الگوست.
- بانکها نیز میتوانند برای دستهبندی درخواستهای وام بر اساس احتمال نکول وام (برگشتخوردن اقساط از حساب)، از الگوریتمهای یادگیری ماشین درخت تصمیم استفاده کنند.
- شرکت گِربِر که تولیدکنندۀ محصولاتی برای نوزادان است، از الگوریتمهای یادگیری ماشین درخت تصمیم برای تصمیمگیری درخصوص استفاده از پلاستیک PVC در محصولاتش استفاده کرد.
- مرکز پزشکی دانشگاه راش ابزاری به نام Guardian طراحی کرده که با استفاده از یک الگوریتم یادگیری ماشین درخت تصمیم، بیماران در معرض خطر و روندهای بیماری را شناسایی میکند.
کتابخانههای علوم داده در زبان پایتون برای الگوریتم یادگیری ماشین درخت تصمیم عبارتند از: SciPy و سایکیت لِرن.
کتابخانۀ علوم داده در زبان R برای الگوریتم یادگیری ماشین درخت تصمیم caret نام دارد.

الگوریتم یادگیری ماشین جنگل تصادفی
برای توضیح سازوکار الگوریتم جنگل تصادفی نیز با همان مثال قبلی پیش میرویم. تایریون یک درخت تصمیم برای انتخاب بهترین رستوران برای شماست. اما تایریون نمیتواند همواره با دقت کافی عمل کند. برای افزایش دقت پیشنهادات، از تعدادی از دوستان دیگر خود نیز درخصوص رستوران R میپرسید، اگر اکثر آنها بگویند از آن رستوران خوشتان خواهد آمد، به آن رستوران خواهید رفت. بنابراین، بهجای آنکه فقط به نتیجۀ تحلیل تایریون اعتماد کنید، نظر جان اسنو، ساندور، برون و برن را نیز دربارۀ رستوران R میپرسید. به این ترتیب، شما مجموعهای از الگوریتمهای دستهبند درخت تصمیم ساختهاید که به آن جنگل گفته میشود.
شما نمیخواید همه دوستانتان جواب مشابهی به شما بدهند، به همین دلیل، اطلاعاتی که به هرکدام از آنها میدهید، اندکی با دیگری متفاوت است. علاوهبراین، شما از اولویتهای خود درخصوص رستورانها کاملاً مطمئن نیستید و شک دارید. شما به تایریون گفتید که از رستورانهای بالای پشتبام خوشتان میآید، اما شاید دلیل آن فصل تابستان بوده است و در سرمای فصل زمستان ممکن است چندان مشتاق رفتن به چنین رستورانی نباشید. بنابراین، همۀ دوستان شما برای پیشنهاد بهترین رستوران، نباید این نقطه داده (یعنی علاقۀ شما به رستورانهای در پشتبام) را دریافت کنند.
دادن اطلاعات مختلف به دوستانتان باعث میشود آنها نیز سؤالات متفاوتی از شما بپرسند. در این حالت، با ایجاد یک تغییر بسیار کوچک در ترجیحات خود، میتوانید به مدل ویژگی تصادفیبودن بدهید. به این ترتیب، دوستان شما یک الگوریتم جنگل تصادفی برای ترجیحات شما درخصوص رستورانها میسازند.
الگوریتم جنگل تصادفی بهترین الگوریتم یادگیری ماشین است که از روش کیسهگذاری (bagging approach) برای ایجاد چندین درخت تصمیم از زیرمجموعههای تصادفی از دادهها استفاده میکند. با استفاده از این الگوریتم، مدل چندین بار توسط نمونههای تصادفی دیتاست آموزش میبیند تا عملکرد آن در زمینۀ پیشبینی بهبود یابد. در این روش خروجی تمامی درختهای تصمیم در جنگل تصادفی با هم ترکیب میشوند تا نتیجۀ نهایی به دست آید. پیشبینی نهایی الگوریتم جنگل تصادفی گاه برابر مجموع نتایجی است که هر یک از درختهای تصمیم ارائه دادهاند و گاهی نیز همان پیشبینیای است که اکثر درختهای تصمیم به آن رسیدهاند.
برای مثال، اگر در مثال بالا پنج نفر از دوستان شما بگویند که شما از رستوران R خوشتان خواهد آمد و فقط دو نفر از آنها نظر دیگری داشته باشند، نتیجۀ نهایی بهنفع اکثریت خواهد بود و شما هم نتیجه خواهید گرفت که از رستوران R خوشتان خواهد آمد.
[irp posts=”۱۲۰۶۵″]چرا از الگوریتم یادگیری ماشین جنگل تصادفی استفاده میکنیم؟
- در پایتون و زبان R نمونههای اجرایی متنباز و رایگان فراوانی برای این الگوریتم موجود است.
- این الگوریتم در صورت مواجهه با دادههای گمشده کمدقت نیست و در برابر دادههای پرت نیز مقاوم است.
- استفاده از این الگوریتم آسان است و نسخۀ پایهای جنگل تصادفی را میتوان با نوشتن چند خط کد اجرا کرد.
- الگوریتم یادگیری ماشین جنگل تصادفی نیازی به دادههای ورودی ندارد و میتواند با ویژگیهای عددی، دودویی و طبقهای بدون نیاز به هیچگونه مقیاسگذاری، تغییر شکل یا اصلاحی کار کند و به این ترتیب، در صرفهجویی در زمان، به دانشمندان داده کمک میکند.
- این الگوریتم ویژگیها را بهصورت ضمنی برمیگزیند، زیرا اهمیت متغیرها را دستهبند ارزیابی میکند.
مزایای استفاده از الگوریتم یادگیری ماشین جنگل تصادفی
- در الگوریتمهای جنگل تصادفی در مقایسه با درخت تصمیم کمتر پیش میآید که با مشکل بیشبرازش مواجه شویم و نیازی به هرسکردن (pruning) الگوریتم جنگل تصادفی نداریم.
- این الگوریتمها کمابیش سرعت بالایی دارند. وقتی یک الگوریتم جنگل تصادفی را روی دستگاهی با فرکانس ۸۰۰ مگاهرتز، دیتاستی دارای ۱۰۰ متغیر و ۵۰.۰۰۰ نمونه اجرا کنیم، تنها در ۱۱ دقیقه ۱۰۰ درخت تصمیم تولید میشود.
- الگوریتم جنگل تصادفی یکی از کارآمدترین و انطابقپذیرترین الگوریتمهای یادگیری ماشین است که به دلیل مقاومبودن در برابر نویزها، در انواع مسائل از جمله دستهبندی و رگرسیون قابل استفاده است.
- ساختن یک الگوریتم جنگل تصادفی بد کار دشواری است! در زمان اجرای یک الگوریتم یادگیری ماشین جنگل تصادفی، تعیین پارامترهایی که باید استفاده شوند آسان است، زیرا این الگوریتمها نسبت به پارامترهای استفاده شده برای اجرای الگوریتم حساس نیستند. هر کسی میتواند بهراحتی و بدون نیاز به تنظیمات زیاد، یک مدل مناسب بسازد.
- الگوریتمهای یادگیری ماشین جنگل تصادفی را میتوان بهصورت موازی نیز رشد داد.
- این الگوریتم در کار با پایگاه دادۀ بزرگ نیز عملکرد خوبی دارد.
- دقت این الگوریتم در مسائل دستهبندی بسیار بالاست.
معایب الگوریتمهای یادگیری ماشین جنگل تصادفی
- ممکن است استفاده از این الگوریتم آسان باشد، اما تجزیه و تحلیل آن بسیار دشوار است.
- اگر تعداد درختهای تصمیم در جنگل تصادفی زیاد باشد، ممکن است سرعت الگوریتم در زمینۀ ارائۀ پیشبینیهای آنی پایین بیاید.
- اگر دادههای ما حاوی دادههای ظبقهای در سطوح مختلف باشند، الگوریتم نسبت به آن صفاتی که سطوح بیشتری دارند اریبی پیدا میکند. در چنین شرایطی، امتیازبندی متغیرها از لحاظ اهمیت، معتبر نخواهد بود.
- این الگوریتم در مواجهه با مسائل رگرسیون نمیتواند چیزی فراتر از مقادیر پاسخ موجود در دیتاست آموزش را پیشبینی کند.
کاربردهای الگوریتمهای یادگیری ماشین جنگل تصادفی
- بانکها با استفاده از الگوریتمهای یادگیری ماشین جنگل تصادفی میزان مخاطرۀ هر وامگیرنده را میسنجند.
- این الگوریتمها در صنعت بهداشت بهمنظور پیشبینی احتمال بروز بیماریهای مزمن در بیماران استفاده میشوند.
- الگوریتم جنگل تصادفی را همچنین میتوان در مسائل رگرسیون از قبیل پیشبینی میانگین تعداد بهاشتراکگذاری یک مطلب در شبکههای اجتماعی و امتیازدهی به عملکرد استفاده کرد.
- اخیراً از این الگوریتمها برای پیشبینی الگوها در نرمافزار شناسایی گفتار و دستهبندی تصاویر و متون نیز استفاده میشود.
یکی از کتابخانههای پایتون استفادهشده برای اجرای الگوریتمهای یادگیری ماشین جنگل تصادفی سایکیت لِرن است.
یکی از کتابخانههای R مورد استفاده برای اجرای الگوریتمهای یادگیری ماشین جنگل تصادفی randomForest نام دارد.

الگوریتم یادگیری ماشین شبکۀ عصبی مصنوعی
مغز انسان یک رایانۀ موازی فوق پیچیده و غیرخطی دارد که اجزای این سیستم را سازماندهی میکند. نورونهای مغز انسان بهصورت پیچیدهای در هم تنیدهاند و با یکدیگر مرتبطاند. برای مثال، فرایند تشخیص چهره را در نظر بگیرید. هر زمان که ما فرد آشنایی را میبینیم، بهراحتی میتوانیم او را تشخیص داده و بگوییم نامش چیست یا در چه شرکت یا سازمانی کار میکند؛ البته این اطلاعات بستگی به رابطۀ شما با او دارد. ما ممکن است هزاران نفر را بشناسیم. عمل شناسایی چهرۀ افراد نیازمند مغزی مشابه مغز انسان است. حال فرض کنید به جای مغز انسان، از یک رایانه بخواهیم افراد را شناسایی کند.
محاسبات لازم برای انجام این کار محاسبات دشواری هستند. بدین منظور باید به رایانه بیاموزیم که هر تصویر متعلق به فرد متفاوتی است. برای مثال، اگر شما ۱۰,۰۰۰ نفر را بشناسید، باید تصویر هر ۱۰,۰۰۰ نفر را به رایانه بدهید. پس از آن نیز هر بار که فردی را ملاقات میکنید، باید از وی عکس گرفته و به رایانه بدهید. سپس رایانه این تصویر را با ۱۰,۰۰۰ تصویر پیشین که به آن داده شده بود مطابقت میدهد.
پس از به اتمام رسیدن همه محاسبات و بررسیها، رایانه تصویری که بیش از سایرین با عکس دادهشده شاباهت دارد را به عنوان خروجی به شما تحویل خواهد داد. این فرایند ممکن است ساعتها زمان ببرد یا به تعداد تصاویر موجود در پایگاه دادۀ رایانه بستگی داشته باشد. بدین ترتیب، با افزایش شمار تصاویر پایگاه داده، پیچیدگی مسئله نیز افزایش مییابد. اما در مقابل مغز انسان میتواند فوراً هر فرد را شناسایی کند.





















