
یادگیری ماشین چیست؟
در عصری که شاهد دگرگونیهای شتابناک فناوریهای دیجیتال هستیم، درک فناوریهایی که پیشران اصلی نوآوری هستند، از یک مزیت نسبی به یک الزام بدل گشته است. از مهمترین فناوریهای که نقشی اساسی در این دگرگونی دارد، میتوان به یادگیری ماشینی اشاره کرد. در این متن تلاش خواهیم کرد با ارائه یک راهنمای جامع، تصویری روشنتر و کم ابهام تر از این فناوری پیش روی علاقهمندان بگذاریم.
یادگیری ماشین یا ماشین لرنینگ (Machine Learning) زیر مجموعهای از هوش مصنوعی است که طی فرایندی به ماشینها آموزش داده میشود تا چگونه رفتار کنند. به این ترتیب حجم وسیعی از دادهها در اختیار کامپیوتر قرار میگیرد و یادگیری ماشین به طور خودکار از طریق الگوهای خود و بدون دخالت انسان میتواند الگوهایی را کشف کند. الگوریتمها این کار را از طریق تقلید کردن یادگیری انسان انجام میدهند و روزبهروز تجربیات خود را افزایش میدهند و با دقت بالاتری به تجزیه و حل مسائل میپردازند.
فرض کنید تعداد زیادی عکس از غذا و حیوانات داریم، یک انسان میتواند به راحتی این تصاویر را از هم جدا کند. حتی ممکن است بر اساس نوع غذا یا موارد دیگر، تصاویر غذاها را هم در دستهبندیهای جداگانهای قرار دهد. اما کامپیوتر چطور؟
یادگیری ماشین در واقع شامل الگوریتمها و روشهایی هست که به کامپیوتر امکان میدهد که توانایی یادگیری داشته باشد و بتواند؛ مانند یک انسان یا حتی بسیار دقیقتر و حساستر چنین کارهایی را مانند آنچه در مثال تصاویر گفته شد انجام دهد.
برای روشنتر شدن ماجرا به این مثال توجه کنید؛ انسانها به راحتی میتوانند از روی تصویر چهره شخص، جنسیت را تشخیص دهند. یعنی شما بلافاصله و بدون فکر کردن میتواند تشخیص دهید شخص مقابل شما یا تصویری که میبینید مرد است یا زن؛ اما ما چطور این کار را انجام میدهیم؟ آیا میتوانیم روش کارمان را به زبان ریاضی یا چیزی که کامپیوتر متوجه آن شود توضیح دهیم؟ بهعبارتدیگر میتوانیم برنامه کامپیوتری بنویسیم که چنین کاری را انجام دهد؟ جواب منفی است، اگر هم چنین کاری ممکن باشد، خطای زیادی دارد.
با استفاده از تکنیکهای یادگیری ماشین میتوان با سرعت به ماشین یاد داد که چطور باید این کار را انجام دهد و بین جنسیت مرد و زن تمایز قائل شود، بدون نیاز به نوشتن برنامه کامپیوتری پیچیدهای که شاید آنقدر هم دقیق نباشد.

یادگیری ماشین برای شرکتهای بزرگ بسیار حائز اهمیت است و از رفتار مشتریان و الگوهای عملیات تجاری دیدگاه مناسبی ارائه میدهد. مدلهای یادگیری ماشین با دریافت دادهها از محیط بیرونی مطابق با شرایط موجود تصمیمگیری کرده و کار انسان را راحتتر از پیش میکنند.
یادگیری ماشین امروزه در بسیاری از زمینهها از جمله پزشکی، خودروهای خودران، تشخیص گفتار، تجارت الکترونیک و بسیاری دیگر از صنایع کاربرد دارد و همچنان در حال توسعه و پیشرفت است.

از راست به چپ یوشوا بنجیو (Yoshua Bengio)، و جفری هینتون (Geoffrey Hinton)، یان لکون (Yann LeCun)، پیشگامان در توسعه الگوریتمهای یادگیری عمیق
یادگیری ماشین چگونه کار میکند؟
برای درک درست چگونگی کارکرد یک سیستم یادگیری ماشینی نخست میبایست به تفکیک مراحلی را که در طی آن داده خام به یک نتیجه معنیدار تبدیل میشود بشناسیم:
گام ۱
جمع آوری داده
نخستین مرحله در یک فرایند یادگیری ماشینی جمعآوری داده است. داده در حکم خون جاری در رگهای یک سیستم یادگیری ماشینی است تا حدی که کیفیت و کمیت دادهها میتواند تأثیر مستقیمی بر روی عملکرد مدل یادگیری ماشینی داشته باشد. داده میتواند از منابع متنوعی گردآوری شود. از پایگاههای داده تا فایلهای متنی، تصویری، صوتی و حتی با گردآوری دادهها از فضای وب.
زمانی که دادهها گردآوری شد، میبایست تا برای استفاده در یک مدل یادگیری ماشینی آماده شوند. این فرایند شامل ساماندهی دادهها در فرمتهای مناسب – فرمتهایی چون فایلهای csv و یا پایگاههای داده – و اطمینان از آن است که دادهها مناسب مسئلهای باشند که در پی حل آن هستیم.
گام ۱
گام ۲
پیشپردازش داده
پیشپردازش داده یک مرحله حیاتی در یک فرایند یادگیری ماشینی است. پیشپردازش شامل تمیزکردن دادهها است کارهایی مثل؛ حذف موارد تکراری، تصحیح خطاها، مدیریت نمونههای جا افتاده (با حذف آنها و یا با پر کردن آنها) و نرمالایز کردن داده هاست. به منظور مقیاسکردن دادهها به شکلی استاندارد جهت به کارگیری در محاسبات.
پیشپردازش در عمل موجب افزایش کیفیت دادهها شده و این اطمینان را خواهد داد تا مدل یادگیری ماشینی بطور صحیحی دادهها را تفسیر کند. اگر این مرحله به درستی انجام شود میتواند میزان دقت مدل را به میزان قابلتوجهی افزایش دهد.
گام ۲
گام ۳
انتخاب مدل درست
مرحله بعدی پس از آمادهشدن دادهها، انتخاب یک مدل یادگیری ماشینی مناسب است. مدلهای متنوعی از مدلها جهت انتخاب وجود دارد از جمله رگرسیون خطی، درختهای تصمیم، شبکههای عصبی مصنوعی و… . انتخاب مدل بستگی به ذات و طبیعت دادهها و همچنین مسئلهٔ پیش رو دارد. عواملی که میبایست در هنگام انتخاب مدل به آنها توجه داشت، حجم و نوع دادهها و پیچیدگی مسئله و همچنین هزینههای محاسباتی و منابع رایانشی در اختیار است.
گام ۳
گام ۴
آموزش مدل
پس از انتخاب مدل، میبایست به آموزش آن بر اساس دادههای آماده شده بپردازیم. آموزش شامل خوراندن دادهها به مدل به منظور تنظیم پارامترهای درونی است تا در نهایت مدل بتواند در خروجی پیشبینی بهتری ارائه دهد.
در هنگام آموزش، باید توجه داشت تا به دام بیش برازش و کم برازش نیافتیم. بیش برازش زمانی رخ میدهد که مدل عملکرد بسیار خوبی بر روی دادههای آموزش دارد؛ اما در مواجهه با دادههای تاکنون دیده نشده عملکرد بسیار ضعیفی نشان میدهد. در مقابل کم برازش زمانی است که مدل عملکرد ضعیفی هم بر روی دادههای آموزش و هم بر روی دادههای جدید نشان میدهد.
گام ۴
گام ۵
ارزیابی مدل
هنگامی که فرایند آموزش مدل به پایان رسید، پیش از پیادهسازی و به کارگیری مدل، میبایست عملکرد مدل را ارزیابی کنیم. فرایند ارزیابی با مواجه کردن مدل با دادههای جدیدی که تا کنون ندیده است انجام خواهد پذیرفت.
معیارهای مرسومی که برای ارزیابی عملکرد یک مدل به کار گرفته میشود عموماً شامل صحت (در مسائل دستهبندی)، دقت و بازیابی (در مسائل دستهبندی دودویی) و خطای میانگین مربعات (در مسائل رگرسیون) است.
گام ۵
گام ۶
تنظیم و بهینهسازی ابر پارامترها
پس از ارزیابی مدل، شما ممکن است نیاز به تنظیم برخی ابر پارامترهای مدل به منظور بهبود عملکرد آن داشته باشید. این فرایند به تنظیم یا بهینهسازی ابر پارامترها شناخته میشود.
روشهای موجود برای تنظیم ابر پارامترها شامل جستوجوی شبکهای (که در آن ترکیبهای مختلفی از پارامترها را امتحان میکنیم)، یا اعتبارسنجی متقابل (که در آن با تقسیم دادهها به زیرمجموعهها و آموزش مدل بر اساس این زیرمجموعهها از عملکرد مدل بر روی دادههای مختلف اطمینان حاصل میکنیم) خواهد بود.
گام ۶
گام ۷
به کار اندازی و استقرار مدل
وقتی که مدل آموزش دید و ارزیابی شد، زمان آن است تا به پیشبینی نتایج گمارده شود. این فرایند شامل خوراندن نمونه دادههای جدیدی است که تا کنون مدل با آنها مواجه نشده است تا بتواند در خروجی در باره آنها پیشبینی کند.
استقرار یک مدل با واردکردن آن به یک محیط واقعی نرمافزاری محقق خواهد شد؛ جایی که مدل بتواند با پردازش دادههایی از جهان واقعی، نتایجی بلادرنگ و مفید ارائه دهد. به چنین فرایندی عموماً MLOps نیز گفته میشود.
گام ۷
تاریخچه یادگیری ماشین
یادگیری ماشین در واقع یکی از زیرشاخههای مهم هوش مصنوعی است که به کامپیوترها توانایی یادگیری و بهبود عملکرد بر اساس تجربیات گذشته بدون برنامهریزی صریح میدهد. تاریخچه یادگیری ماشین به دههها پیش بازمیگردد و در طول زمان تحولات بسیاری داشته است.
دهه ۵۰ میلادی
گامهای آغازین
آلن تورینگ، ریاضیدان بریتانیایی، با نوشتن مقالهای در سال ۱۹۵۰ تحت عنوان «ماشینهای محاسباتی و هوش»، ایدههای اولیهای در مورد ماشینهایی که میتوانند یاد بگیرند را مطرح کرد.
فرانک روزنبلات (Frank Rosenblatt) در سال ۱۹۵۷ پرسپترون، یک نوع شبکه عصبی ساده، را اختراع کرد که قادر به یادگیری و تصمیمگیری بر اساس ورودیهای داده شده بود.
دهه ۵۰ میلادی
دهه ۱۹۶۰ و ۱۹۷۰
رشد و پیشرفت
در این دوره، الگوریتمهای یادگیری ماشین مانند الگوریتمهای درخت تصمیم و مدلهای خطی توسعه یافتند.
ماروین مینسکی (Marvin Minsky) و سیمور پاپرت (Seymour Papert) نشان دادند که پرسپترونها دارای محدودیتهایی هستند که این موضوع باعث کاهش علاقه به تحقیقات در زمینه شبکههای عصبی شد.
دهه ۱۹۶۰ و ۱۹۷۰
دهه ۱۹۸۰
بازگشت شبکههای عصبی
با پیشرفتهایی که در الگوریتمهای یادگیری عمیق و شبکههای عصبی، انجام شد در این دوره شاهد احیای علاقه به یادگیری ماشین بود. جان هاپفیلد (John Hopfield) و دیوید روملهارت (David Rumelhart) نقش مهمی در این بازگشت داشتند.
دهه ۱۹۸۰
دهه ۱۹۹۰
الگوریتمهای جدید
الگوریتم پشتیبانی ماشین بردار (SVM) توسعه داده شد که برای دستهبندی و رگرسیون در دادههای پیچیده استفاده میشود.
تکنیکهای بیزین (Bayesian)، مانند شبکههای بیزین، برای مدلسازی احتمالاتی و تصمیمگیریهای پیچیده مورد استفاده قرار گرفتند.
دهه ۱۹۹۰
دهه ۲۰۰۰ تا کنون
عصر دادههای بزرگ و یادگیری عمیق
با افزایش حجم دادهها و قدرت محاسباتی، الگوریتمهای یادگیری عمیق مانند شبکههای عصبی پیچشی (CNN) و شبکههای عصبی بازگشتی (RNN) برای پردازش تصویر، زبان طبیعی و سایر دادههای پیچیده استفاده شدند.
یان لکون (Yann LeCun)، یوشوا بنجیو (Yoshua Bengio)، و جفری هینتون (Geoffrey Hinton) به عنوان پیشگامان در توسعه الگوریتمهای یادگیری عمیق شناخته شدند.
دهه ۲۰۰۰ تا کنون
اهمیت یادگیری ماشین
شاید همانگونه که در سده پیشین، مواد خام حکم نیروی پیشران تمام صنایع را داشت، امروزه در قرن بیست و یکم، به جرئت میتوان داده، و به تبع آن، یادگیری ماشینی را نیروی پیشران اکثر صنایع فناور دانست:
یکی از اصلیترین دلائلی که امروزه یادگیری ماشینی دارای چنین جایگاهی است، توانایی آن در به خدمت گرفتن حجمهای بزرگی از داده و استخراج معنی از دل آنهاست. با بهرهگیری از دادههای فراهم آمده از شبکههای اجتماعی، حسگرها، دوربینها و بسیاری دیگر از سرچشمههای داده، امروزه دیگر روشهای سنتی تحلیل داده ناکافی به نظر میرسند. یادگیری ماشینی در مقابل میتواند، ضمن پردازش این حجمهای گسترده از داده، با شناسایی الگوهای پنهان در آنها، دید بسیار خوبی را در اختیار تصمیمگیران قرار دهد. حتماً این ضربالمثل را شنیدهاید که میگوید «آنچه در آینه جوان بیند، پیر در خشت خام آن بیند!»، الگوریتمهای یادگیری هم میتوانند به ماشینها توانایی را بدهند که یک انسان ممکن است پس از سالها تجربه به آن دست پیدا کند.
یادگیری ماشینی موجب ایجاد نوآوریهای شگرفی در بخشهای متنوعی از صنایع شده است:
حوزه بهداشت و درمان: الگوریتمها برای پیشبینی پیش از موعد شیوع بیماریها، طراحی برنامههای درمان شخصیسازیشده و بهبود دقت تصویربرداریهای پزشکی مورد استفاده قرار گرفتهاند.
حوزه مالی و بانکی: یادگیری ماشینی در محاسبه رتبه اعتباری، سیستمهای معاملهگری الگوریتمی، و شناسایی تقلب و جعل کاربرد فراوان دارند.
حوزه خردهفروشی: سیستمهای پیشنهاد گر، زنجیرههای تأمین و خدمات مشتری، همگی از امکاناتی که یادگیری ماشینی میتواند در اختیار آنها بگذارد بهره میبرند.
امروزه دیگر تکنیکهای یادگیری ماشینی در گستره وسیعی از صنایع از کشاورزی، تا آموزش و صنعت سرگرمی دیده میشود.
یادگیری ماشینی یکی از کلیدیترین عناصری است که خودکارسازی امور را ممکن کرده است. الگوریتمهای یادگیری ماشینی، با یادگیری از روی دادهها و بهبود عملکرد خود در طول زمان میتوانند اموری را که تا پیش از این به ناگزیر به صورت دستی انجام میشدند به طور خودکار انجام دهند و اجازه دهند تا نیروی انسانی به امور پیچیدهتر و خلاقانهتر بپردازد و از انجام امور تکراری رها شود. این امر نه تنها موجب افزایش بهرهوری شده بلکه مسیرهای نویی را برای نوآوریهای تازه هموار کرده است.
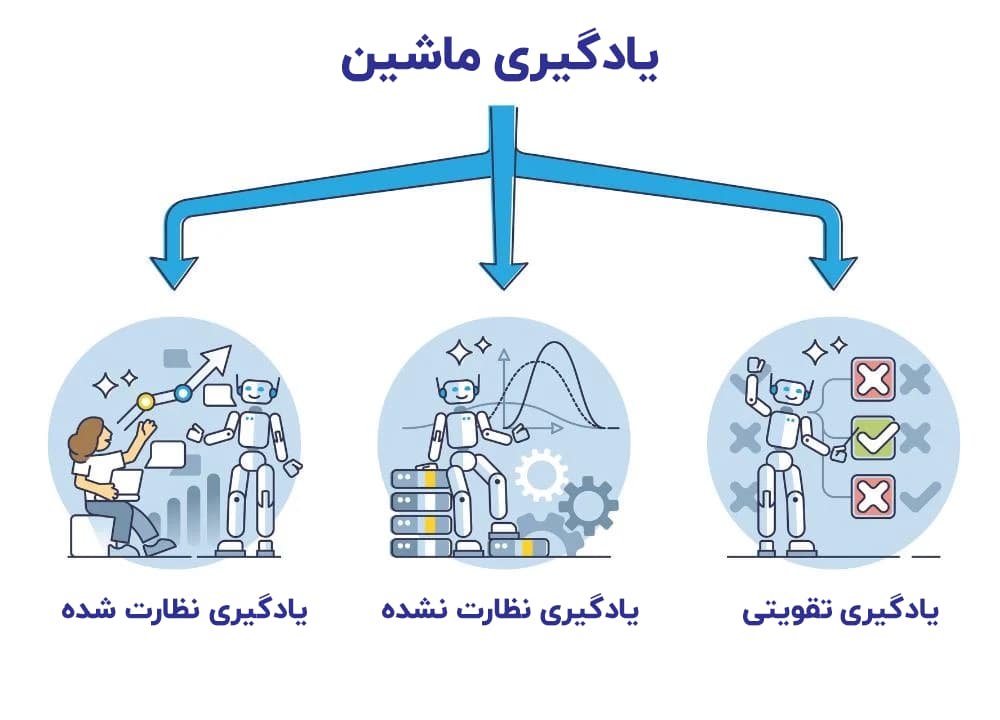
انواع یادگیری ماشین
یادگیری ماشین از روشهای مختلفی انجام میشد که عبارتاند از:
یادگیری تحت نظارت
از مهمترین الگوهای یادگیری ماشین به شمار میرود و برای آموزش ماشین از دادههایی که از قبل برچسبگذاری شده استفاده میشود. در این روش ورودی و خروجی کاملاً مشخص است و ماشین مطابق با این دادهها آموزش میبیند که چگونه به نتایج حاصل شده دست پیدا کند. برای مثال افراد متخصص پیامهای اسپم و واقعی را به طور مجزا در اختیار ماشین قرار میدهند و ماشین میتواند تفاوت آنها را بیابد و به جداسازی آنها بپردازد.
مثلاً میتواند دادهها را به این صورت به ماشین داد، تعدادی مثلاً ۱۰۰ عکس از افراد که جنسیت آنها نیز مشخص شده. ماشین بعد از بررسی این 100 عکس، اگر عکس جدید بگیرد میتواند تشخیص دهد که آن مربوط به کدام دسته میشود. هرچه دادههای آموزشی اولیه بیشتر و با کیفیت تر باشد، یادگیری بهتری انجام میشود.
این روش با نظارت انسان انجام شده و برای درستی آن باید ماشین را مورد آزمایش قرار دهید. یادگیری تحت نظارت به نوبه خود از ۲ روش مختلف تشکیل شده که روش اول از نوع دستهبندی است و از طریق دادههای قبلی تشخیص میدهد که دادههای جدید به کدام دسته تعلق دارند. در روش دیگر یعنی رگرسیون مقادیر پیوسته عددی مانند قیمت خودرو پیشبینی میشوند.
یادگیری بدون نظارت
در این روش برچسب دادهها مشخص نیست و ماشین بدون حضور متخصص ارتباط بین دادهها را به دست میآورد و الگوها را خودش پیدا میکند. در واقع تفاوت یادگیری بدون نظارت با یادگیری نظارت شده نوع اطلاعات ورودی است و در یادگیری بدون نظارت دادهها طبقهبندی و برچسبگذاری شده نیستند. این مدل از یادگیری ماشین دادهها را بررسی میکند و میتواند بدون دستهبندی اولیه، خودش آنها را پیدا کند.
یادگیری نیمه نظارت شده
یکی دیگر از روشهای یادگیری ماشین، یادگیری نیمه نظارتی است که تلفیقی از یادگیری تحت نظارت و یادگیری بدون نظارت به شمار میرود. از این رو در این روش رایانه هم از دادههای برچسبگذاری شده و هم از دادههای بدون برچسب برای آموزش استفاده میکند که در این میان تعداد دادههای بدون برچسب بسیار بیشتر هستند. این مدل از یادگیری توانایی کشف دادهها را به تنهایی دارد و مجموعه دادهها را توضیح میدهد و از مهمترین ویژگیهای آن میتوان به افزایش دقت یادگیری ماشین اشاره کرد.
یادگیری تقویتی
در این روش یادگیری ماشین، اَعمال و کارهایی که انجام میشوند کامپیوتر میتواند بازخوردهای کارها را دریافت کرده و یادگیری تقویتی با آزمونوخطا مسائل مختلف را تجزیه و تفسیر کند. در واقع این روش با محیط اطراف تعامل برقرار میکند و خطاهای آن را به دست میآورد و به این صورت دادههایی را جمعآوری و بهترین تصمیمات را ارائه میدهد. محدودیت روشهای جمعآوری اطلاعات به محیط، ارائه شبیهسازی از محیط و مدل محیط شناخته شده از شرایطی هستند که یادگیری ماشین تقویتی میتواند از آنها برای آموزش مسائل مختلف استفاده کند و بهترین عمل را تشخیص دهد.
کاربردهای ماشین لرنینگ
کاربردهای یادگیری ماشین بسیار فراوان هستند و در رونق تجارت و کسبوکار نقش بسیار مؤثری دارند. به طور کلی در بسیار از موارد که نمیتواند یک قاعده مشخص را برای بررسی دادهها یا تصمیمگیری ماشین تعریف کرد، بهتر است از این روشها استفاده شود. مهمترین کاربردهای ماشین لرنینگ عبارتاند از:
تشخیص گفتار
یکی از مهمترین و کاربردیترین استفادههای یادگیری ماشین ترجمه از گفتار به متن است. در این روش با ارائه فایل صوتی یا ویدئو میتواند گفتار آنها را به متن تبدیل کند. این تکنولوژی امروز در گوشیهای هوشمند وجود دارد و یکی از رایجترین روشها برای اجرای دستورات به صورت است.

تشخیص چهره
یادگیری ماشین از طریق الگوریتمهای مختلف، پیکسلها و سایر ویژگیهای تصاویر را شناسایی میکند و آن را از تصاویر دیگر تشخیص میدهد. در واقع یادگیری ماشین دادههای تصاویر را در کنار یکدیگر قرار میدهد و در نهایت بر اساس الگوهای به دست آمده تصاویر را از یکدیگر تمییز و تشخیص خواهد داد.

دستیارهای مجازی
دستیارهای هوشمند مانند الکسا و سیری با استفاده از مدلهای یادگیری ماشین گفتار انسان را تشخیص میدهند و دستورات آن را اجرا میکنند. به این منظور از مدلهای تحت نظارت و بدون نظارت برای تفسیر گفتار طبیعی استفاده میشود. این دستیارها همچنین بر اساس رفتار کاربر و الگوی زندگی و… او میتوانند پیشنهادهایی را به کاربر بدهند یا بر اساس دادههایی که دارند لیست خرید شما را کامل کنند.
مثلاً این دستیارها در صورت دسترسی به دادههای شما میتوانند الگو خریدها و خوردوخوراک شما را تحلیل کنند و مثلاً متوجه شوند که معمولاً در پایان هر ماه یک مهمانی ترتیب میدهید و یا اینکه شما در آخر هفتهها بیشتر شیر مصرف میکنید و حواسش باشد که چهارشنبهها در لیست خرید شما یک بطری شیر را قرار دهد.

پزشکی
یکی از مهمترین کاربردهای یادگیری ماشین استفاده در حوزه پزشکی است. در این حوزه ماشین با تجزیهوتحلیل دادههای پزشکی پیشنهاداتی مانند مراقبتهای پزشکی حرفهای را ارائه میدهد. یادگیری ماشین اطلاعات وسیعی از سلامتی را در اختیار انسان قرار میدهد و به بهبود سلامت جامعه کمک میکند.
تفسیر عکسهای پزشکی مثل سیتیاسکن، تصاویر ایکس – ری، امآرآی و… توسط این الگوریتمها میتواند بسیاری از مشکلات را پیش از آنکه به راحتی توسط پزشک قابلتشخیص باشند شناسایی کند.

صنعت کشاورزی
ماشین لرنینگ در صنعت کشاورزی کاربردهای زیادی دارد که شامل؛ تشخیص آفات و بیماریها، مدیریت شرایط مزرعه، وجین خودکار، پیشبینی شرایط آب و هوا و… هستند. سیستمهای یادگیری ماشین میتوانند با توجه به آموزشهایی که دیدهاند شرایط گلخانه را برای رشد بهتر محصولات کنترل کنند. با بهکارگیری یادگیری ماشین در پروژههای کشاورزی سلامت و کیفیت محصول افزایش پیدا کرده و در بهبود وضعیت اقتصادی کشاورزان بسیار مؤثر است.

ارتباط با مشتری
بهکارگیری مدلهای یادگیری ماشین در نرمافزار سی آر ام (CRM) باعث تجزیهوتحلیل رفتار و نظرات مشتریان میشود و اعضای تیم فروش از این طریق میتوانند کسبوکار خود را توسعه دهند و محصولات متناسب با نیاز مشتریان ارائه دهند.
بسیاری از الگوها در رفتار مشتری ممکن است حتی از چشم بهترین تحلیلگران هم پنهان بماند یا ارتباط بین مشکلات مشتریان در یک بخش با مورد دیگر چیزی باشد که به راحتی قابل تشخیص نباشد؛ اما سیستمهای یادگیری ماشین میتوانند چنین الگوهایی را شناسایی و درک کنند.

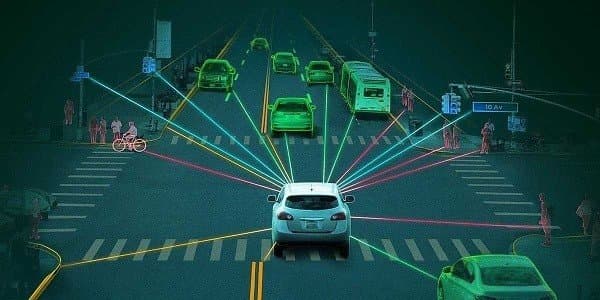
اتومبیلهای خودران
رانندگی خودکار و تشخیص اشیا قابلمشاهده و اعلام آن به راننده توسط الگوریتمهای یادگیری ماشین آن را به یکی از کاربردیترین روشها در صنعت خودروسازی تبدیل کرده است. به این صورت تصادفات جادهای بسیار کاهش پیدا میکنند و ایمنی افراد افزایش پیدا خواهد کرد. کنترل خودرو در محیطهای شهری نیاز به توجه به محیط افراد و رفتار دیگر خودروها و افراد دارد. چنین چیزی را نمیتواند با یک روش یا اجرای یک الگوریتم ممکن کرد. اما میتواند از طریق مدلهای یادگیری ماشین به این نقطه رسید که ماشین در لحظه بتواند بهترین تصمیم را بگیرد.
خدمات مالی
بانکها و مؤسسات مالی با کمک یادگیری ماشین میتوانند تصمیمهای هوشمندانهای بگیرند و با بررسی عملکرد افراد از وقوع ضرر و زیانها جلوگیری کنند. ماشین لرنینگ توانایی تجزیهوتحلیل بازارها را دارد و از بهترین گزینهها برای پیشنهادات سرمایهگذاری است. این سیستمها همچنین میتوانند معاملات مشکوک و تقلب را شناسایی کنند.

کاربردهای امنیتی
از یادگیری ماشین میتواند برای تشخیص رفتار مشکوک در فرودگاهها، ورزشگاهها و اماکن عموم استفاده کرد. این روش میتوانند خلافکاران بالقوه را شناسایی کند. یا مثلاً با بررسی تصویر دوربینهای نظارتی یک ساختمان حساس، رفتار افرادی که از خیابان مقابل یا اطراف این ساختمان میگذرند تحلیل شود و اگر رفتار مشکوک و غیرعادی شناسایی شد، به عامل انسانی هشدار داده شود تا موضوع را بررسی کند.
مزایا و معایب ماشین لرنینگ
یادگیری ماشین مانند هر تکنولوژی دیگر با مزایا و معایبی همراه است که با شناسایی آنها میتوان به درستی از آن استفاده کرد.
مزایای یادگیری ماشین
1
2
3
4
5
شناسایی روندها و الگوها
یادگیری ماشین با بررسی حجم وسیعی از دادهها، روندها و الگوهای ناشناخته برای انسانها را شناسایی میکند. این مزیت برای کسبوکارها بسیار اهمیت دارد و برای فروشگاههای آنلاین میتواند رفتارهای جستجو و تاریخچه خرید کاربران را شناسایی کند و متناسب با آن محصولات مناسبی را ارائه دهد. یا در مثالی دیگر یک پلتفرم پخش فیلم یا موسیقی میتواند بر اساس رفتار کاربر پیشنهادهای بهتری را به او بدهد.
عدم نیاز به دخالت انسان
ماشینها پس از یادگیری و آموزش دیگر نیازی به دخالت انسان ندارند و میتوانند به طور مستقیم کارهای محول شده را انجام دهند. برای مثال؛ تشخیص ایمیلهای اسپم توسط ماشین به طور خودکار انجام میشود و آنها را از پیامهای واقعی تفکیک میکند.
مدیریت دادهها
توانایی بررسی دادههای چندبعدی و چند متغیره از دیگر مزایای یادگیری ماشین است و الگوریتمهای آن میتوانند در محیطهای مبهم این دادهها را بررسی کنند.
بهبود مداوم
الگوریتمهای یادگیری ماشین همچنان در حال کسب تجربه هستند و در این میان ویژگیها و کاراییهای خود را بهبود میبخشند. این ویژگی باعث میشود تصمیمات بهتری توسط رایانه گرفته شود و با دریافت دادههای بیشتر پیشبینیهای دقیقتری انجام شود.
گستردگی کاربرد
کاربردهای یادگیری ماشین بسیار گسترده هستند و در هر جایی که از تکنولوژی و رایانه استفاده میشود میتوان از الگوریتمهای یادگیری استفاده کرد و تجربه بهتری به مشتریان ارائه داد.
معایب یادگیری ماشین
1
2
3
4
5
جمعآوری دادهها
یادگیری ماشین به حجم وسیعی از دادهها نیاز دارد که باید جامع و باکیفیت باشند تا ماشین بتواند به درستی آموزش ببیند و با بالاترین دقت پیشنهادات و تصمیمات را ارائه دهد.
زمان
برای ساخت مدلهای یادگیری ماشین گاهی اوقات زمان زیادی باید صرف شود. در یک بازه مشخص زمانی الگوریتمها باید آموزش ببینند و به اندازه کافی پیشرفت کنند.
منابع
یادگیری ماشین برای جمعآوری حجم زیادی از دادهها و اجرای الگوریتمهای یادگیری به منابع فراوانی نیاز دارد و برای این کار به رایانه و نیروی انسانی نیاز است. البته با پیشرفت کامپیوترها و افزایش قدرت پردازشی این مشکل تا حدودی برطرف شده.
تفسیر نتایج
انتخاب الگوریتمها در تفسیر نتایج نهایی بسیار تأثیرگذار است و باید الگوریتمهای مناسب با نیاز خود را انتخاب کنید تا با دقت بالایی نتایج را تفسیر کنند.
حساسیت به خطای بالا
یادگیری ماشین با توجه به دادههایی که در دسترس انجام میشود و در صورتی که حجم دادهها کم باشد احتمال خطا وجود دارد. در صورت بروز چنین مشکلی خطاها بهصورت زنجیرهوار رخ میدهند و اصلاح آنها به زمان زیادی نیاز دارد.
نمونههایی از یادگیری ماشین
یادگیری ماشین نمونههای بسیار گستردهای دارد که در زندگی واقعی به کار میروند. برخی از این نمونهها عبارتاند از:
تشخیص چهره در تصاویر
از نمونههای روزمره یادگیری ماشین تشخیص چهره در تصاویر است که این روش هوش مصنوعی توانایی تشخیص اعضای بدن و چهره انسان در محیطهای مختلف را دارد. برای مثال از این طریق میتوان چهره افراد خطرناک و تحت تعقیب را شناسایی کرد و به افزایش امنیت جوامع پرداخت.
امنیت عمومی
جلوگیری از وقوع جرایم از دیگر نمونههای یادگیری ماشین است که منجر به افزایش امنیت عمومی میشود. در این روش دانشمند داده بهعنوان یکی از مشاغل یادگیری ماشین از طریق الگوریتمهای موجود نقاط مهمی که جرم در آنها اتفاق افتاده است را شناسایی میکند که این کار در نهایت به سازمانهای دولتی و غیردولتی برای افزایش امنیت عمومی کمک زیادی میکند.
پیشبینی رفت و آمد
الگوریتمهای یادگیری ماشین در نقشهها و اپلیکیشنهای مسیریابی بهترین و سریعترین مسیر را پیشنهاد داده و مواردی مانند جادههای کمترافیک را گزارش میدهند. این کاربرد برای زمانی که عجله دارید یا برای مأموریتهای پلیس، آمبولانس و آتشنشانی بسیار اهمیت دارد.
امنیت سایبری
یادگیری ماشین نقش مؤثری در ردیابی تراکنشها و تشخیص تراکنشهای قانونی از غیرقانونی دارد و به این ترتیب از کلاهبرداریهای مالی آنلاین جلوگیری میکند و باعث افزایش امنیت سایبری میشود. همچنین سیستمهای امنیت سایبری میتوانند از با تشخیص الگوی رفتاری هکرها و برنامههای مخرب آنها را به سرعت شناسایی و دسترسیشان را محدود کنند.
ورزش
یادگیری ماشین با بررسی عملکرد بازیکنان به تیمهای ورزشی این امکان را میدهد تا بهترین تصمیم را بگیرند. دریافت برنامههای آموزشی و رژیم غذایی، تشخیص خودکار الگوهای تاکتیکی پیچیده در رشتههای ورزشی و پیشبینی نتایج مسابقات از کاربردهای یادگیری ماشین در ورزش هستند.
حفاظت از محیطزیست
الگوریتمهای یادگیری ماشین توانایی پیشبینی آلودگی محیط زیستی را دارند و این کار را با جمعآوری آمار و دادهها از دستگاهها و حسگرهای مختلف در زیست محیط انجام میدهند؛ بنابراین یادگیری ماشین باعث کاهش اثرات زیستمحیطی و افزایش پایداری محیط میشود و زندگی سالمی برای انسانها و سایر موجودات به وجود میآورد.
تفاوت یادگیری ماشین با هوش مصنوعی
هوش مصنوعی و یادگیری ماشین از جمله مفاهیم مجزا هستند که تفاوتهایی با یکدیگر دارند. هوش مصنوعی به شبیهسازی هوش انسان توسط سیستمهای کامپیوتری گفته میشود و یک مفهوم کلی است. این تکنولوژی قادر است به روشی مانند ذهن انسان مسائل پیچیده را حل کرده و در ساخت ابزارهای فناوری بسیار مؤثر عمل کند.
از طریق تکنولوژی هوش مصنوعی ماشینهایی تولید میشوند که وظایف انسان را به بهترین شکل ممکن و با کمترین خطا انجام میدهند. همانطور که گفته شد یادگیری ماشین زیر مجموعهای از هوش مصنوعی است و از طریق دادههای موجود آموزش داده میشود. یادگیری ماشین از بسیاری از زمینههای مرتبط با هوش مصنوعی ایده میگیرد و کامپیوترها را قادر میسازد تا بدون دخالت انسان یاد بگیرد.
همچنین الگوریتمهای هوش مصنوعی از تکنیکهای بسیار مختلف تشکیل داده میشوند، در صورتی که الگوریتمهای یادگیری ماشین از روشهای مبتنی بر ریاضیات استفاده میکند. در هوش مصنوعی سیستمها به طور کاملاً مستقل عمل میکنند؛ اما در یادگیری ماشین در برخی از مراحل به دخالت انسان نیاز است و باید توسط کاربر دادههایی در اختیار کامپیوتر قرار بگیرند.
آشنایی با تکنیکهای یادگیری ماشین
تکنیکهای یادگیری ماشین از روشها و الگوریتمهایی تشکیل شده که موجب یادگیری از دادهها میشوند و الگوهای موجود را استخراج میکنند. بهواسطه این تکنیکها به تحلیل و پیشبینی دادهها پرداخته میشود که برخی از آنها عبارتاند از:
این تکنیک ماشین با استفاده از مقادیر پیوسته عددی مدلها را پیشبینی میکند، برای مثال قیمت گوشی همراه را بر اساس عواملی مانند برند، مدل، حافظه و… پیشبینی میکند. رگرسیون از تکنیکهای یادگیری ماشین تحت نظارت به شمار میرود و انواع مختلفی دارد که شامل رگرسیون منطقی، رگرسیون خطی، رگرسیون جنگل تصادفی، رگرسیون درخت تصمیم و رگرسیون چندجملهای هستند.
طی این تکنیک نوع داده یا مشاهده را بر اساس دستههای موجود تعیین میکند، در واقع در سیستم از قبل دادهها و مشاهدات وجود دارند که دستهبندی دادههای جدید با توجه به آنها مشخص میشود و مشاهدات جدید برچسبگذاری میشوند. این تکنیک نیز مربوط به یادگیری ماشین تحت نظارت است و کاربردهای مختلفی در حوزه پزشکی، بانکداری و زمینههای دیگر دارد.
از جمله تکنیکهایی که در یادگیری ماشین بدون نظارت مورداستفاده قرار میگیرد خوشهبندی یا تحلیل خوشهای است. در این روش مشاهدات و دادهها بر اساس شباهتی که با یکدیگر دارند گروهبندی میشوند، از این روش برای تحلیل دادههای آماری استفاده میشود و نقش مؤثری در تشخیص الگو، فشردهسازی دادهها، تجزیهوتحلیل تصاویر و بیوانفورماتیک دارد. این تکنیک توسط الگوریتمهای مختلف به دست میآید و برای شناسایی دادهها از رویکردهای متفاوتی استفاده میکند.
با استفاده از این تکنیک تعداد متغیرها در یک مجموعه داده کاهش پیدا میکند و زمانی رخ میدهد که امکان بررسی دادهها از جهات کمتر وجود دارد. با این حال نتیجه آن با حالت اولیه تفاوت چندانی ندارد و این تکنیک برای حفظ اطلاعات مهم به کار میرود و کاربردهای وسیعی دارد.
برترین مسیرهای شغلی یادگیری ماشین
گسترش کاربردهای یادگیری ماشینی باعث به وجود آمدن فرصتهای شغلی فراوانی شده است. افراد متخصص مجهز به مهارتهای یادگیری ماشینی از مشاغل مرتبط با علوم داده تا مهندسی هوش مصنوعی از جمله مشاغل با بیشترین تقاضا به شمار میآیند. در ادامه به برخی از این مسیرهای شغلی اشاره خواهیم داشت:
دانشمند علوم داده
یک دانشمند علوم داده با بهکارگیری روشها، فرایندها و الگوریتمها از زاویه دیدی علمی به دنبال استخراج دانش و ارائهدادن نگرشهای جدید از دل دادههای ساختارمند و بدون ساختار است. یادگیری ماشینی به عنوان یک ابزار کلیدی در جعبهابزار مهارتهای هر دانشمند علوم داده به او اجازه خواهد داد تا به بهترین شکل این کار را دنبال کند.
مهارتهای کلیدی موردنیاز:
- تحلیل آماری
- برنامهنویسی
- یادگیری ماشینی
- مصورسازی داده
- مهارت حل مسئله
ابزارهای کلیدی موردنیاز:
- زبان برنامهنویسی پایتون
- زبان برنامهنویسی R
- SQL
- Hadoop
- Spark
- Tableau
مهندس یادگیری ماشینی
یک مهندس یادگیری ماشینی متخصصی است که به طراحی و پیادهسازی سیستمهای یادگیری ماشینی میپردازد. از متداولترین کارهایی که یک مهندس یادگیری ماشینی در طی کار خود با آنها درگیر خواهد بود، اجرای آزمایشات یادگیری ماشینی با استفاده از زبانهای برنامهنویسی چون پایتون و R و کار بر روی مجموعه دادهها و به کارگیری الگوریتمهای یادگیری ماشینی و کتابخانههای مرتبط با آنهاست.
مهارتهای کلیدی موردنیاز:
- برنامهنویسی (پایتون، جاوا، R)
- الگوریتمهای یادگیری ماشینی
- آمار
- طراحی سیستم
ابزارهای کلیدی موردنیاز:
- پایتون
- Tensorflow
- Scikit-learn
- PyTorch
- Keras
دانشمند پژوهشی
یک دانشمند پژوهشی در حوزه یادگیری ماشینی به دنبال انجام پژوهش به منظور پیش برد حوزه دانشی یادگیری ماشینی است. آنها هم در فضای دانشگاهی و هم در فضای صنعت حضور پررنگی دارند و در صدد توسعه الگوریتمهای جدید و تکنیکهای نوین هستند.
مهارتهای کلیدی موردنیاز:
- درک عمیق از الگوریتمهای یادگیری ماشینی
- برنامهنویسی (پایتون، R)
- روششناسی پژوهشی
- مهارتهای ریاضیاتی قوی
ابزارهای کلیدی موردنیاز:
- زبان برنامهنویسی پایتون
- زبان برنامهنویسی R
- Tensorflow
- PyTorch
- MATLAB
چگونه در یادگیری ماشین شروع به فعالیت کنیم
در بدو امر ممکن است آغاز یادگیری در فضای یادگیری ماشینی کمی ترسناک به نظر برسد، اما با اتخاذ رویکردی درست و در اختیار داشتن منابع مناسب، هر کسی میتواند در این حوزه پیشرفت کند. در ادامه به برخی گامهای آغازین اشاره خواهیم داشت:
گام ۱
درک و یادگیری مقدمات
پیش از درگیرشدن با مسائل پیچیده در یادگیری ماشین، داشتن یک پیشینه قوی در ریاضیات، مخصوصاً آمار و جبر خطی و همچنین دانستن یک زبان برنامهنویسی، مخصوصاً پایتون میتواند به شدت راهگشا باشد.
منابع خوب بسیاری برای آموختن این مقدمات در دسترس هستند. پلتفرمهای آموزشی آنلاین و کتابهای الکترونیکی فراوانی برای شروع میتوانند بسیار کمککننده باشند.
گام ۱
گام ۲
یادگیری الگوریتمهای یادگیری ماشینی
پس از آشنایی با مقدمات بحث، میبایست به سراغ یادگیری الگوریتمهای یادگیری ماشینی رفت. با درنظرگرفتن الگوریتمهای سادهتری چون رگرسیون خطی و درختهای تصمیم در ابتدا و حرکت به سمت الگوریتمهای پیچیدهتر همانند شبکههای عصبی مصنوعی میتوان یک مسیر آموزشی مناسب را برای خود ترتیب داد.
گام ۲
گام ۳
کار بر روی پروژهها
درگیرشدن با پروژهها یکی از بهترین روشها برای کسب تجربه و تقویت مهارتهای آموخته شده است. با شروع از پروژههای آسانتر چون پیشبینی قیمت خانه یا دستهبندی نوع خاصی از گل (پروژههای آموزشی معروفی که در اینترنت شناخته شدهاند) و بهتدریج حرکت به سوی پروژههای پیچیدهتر میتوان پس از صرف مدتزمان نسبتاً کمی به نتایج قابلقبولی رسید.
گام ۳
گام ۴
به روز کردن اطلاعات و دانش درباره یادگیری ماشینی
یادگیری ماشینی حوزهٔ دانشی است که با سرعت فراوانی در حال تغییر و تحول است، پس به روز نگاهداشتن دانش خود در ارتباط با آخرین پیشرفتها و ابزارها الزامی است. با دنبالکردن بلاگهای مرتبط، شرکتکردن در کنفرانسها و حضوریافتن در جمعهای آنلاین میتوان تا حد زیادی خود را به روز نگاه داشت.
گام ۴
سخن پایانی
از حوزه بهداشت و درمان و حوزه مالی و بانکی تا صنعت حملونقل و سرگرمی، همه امروز با بهکارگیری الگوریتمهای یادگیری ماشینی در حال ایجاد نوآوری و بهرهوری در بخشهای مختلف هستند. همانطور که دیدیم، ورود به حوزه دانشی یادگیری ماشینی نیازمند یک پایه قوی در ریاضیات و برنامهنویسی، درکی عمیق از الگوریتمهای یادگیری ماشینی و تجربه عملی کار با پروژههای واقعی است.
چه علاقهمند به کار به عنوان یک دانشمند علوم داده یا یک مهندس یادگیری ماشینی و یا یک متخصص هوش مصنوعی باشید یا نباشید، امروزه فرصتهای شغلی متعددی در حوزه یادگیری ماشینی ایجاد شده است. با استفاده از ابزارهای مناسب و به خدمت گرفتن منابع آموزشی مفید هر کسی میتواند قدم در راه یادگیری این حوزه دانشی بگذارد.
به یاد داشته باشید، یادگیری در این حوزه دانشی، یک راه طولانی اما شیرین است. حوزهای که دائماً در حال تغییروتحول است و نیازمند به روز بودن با آخرین تحولات مرتبط با آن است.
یادگیری ماشینی صرفاً یک عنوان دهانپرکن علمی و تخصصی نیست و امروزه یک ابزار بسیار قدرتمند است که زندگی و کار همه انسانها را دستخوش تغییرات گستردهای کرده است. با درک درست یادگیری ماشینی گام در مسیری گذاشتهایم تا بتوانیم از توان این حوزه در جهت حل مسائل پیچیده واقعی بهره ببریم.
