

بررسی ویژگیهای سیستم های توصیه گر
 تیم تحریریه
تیم تحریریه- ۲۹ شهریور ۱۴۰۰
به زیرمجموعهای از سیستمهای پالایندۀ اطلاعات، سیستم های توصیه گر Recommendation System گفته میشود. گاهی دقت توصیههای خرید در آمازون، تماشا در سرویس چندرسانهای نتفلیکس یا گوش دادن به موسیقی در اسپاتیفای، ما را شگفتزده میکند. گویی این شرکتها میدانند در ذهنمان چه میگذرد و از تصمیمهایمان آگاهی دارند.
آنها علوم رفتاری را مبنای کارشان قرار دادهاند و ما باید به نحوی به این مفاهیم، رنگِ واقعیت ببخشیم که درکشان آسان باشد و مهمترین مفاهیم نیز پوشش داده شوند. به خاطر داشته باشید که افراد قابل پیشبینی هستند. رفتار نشان از شخصیتِ افراد دارد.

سیستمهای فیلترینگ اطلاعات، دادههای اضافی یا ناخواسته را از پایگاه داده حذف میکنند. نویز را در سطح معنایی کاهش میدهند. تحقیقات زیادی هم در این زمینه انجام شده است؛ از اخترشناسی تا تحلیل ریسک مالی.
به طور کلی سیستم های توصیه گر به دو نوع تقسیم میشوند:
• فیلترینگ مشارکتی Collaborative Filtering
• فیلترینگ مبتنی بر محتوا Content-Based Filtering
در ادامه مزایا و معایب این دو سیستم به همراه چند مثال بررسی خواهند شد. هیچ سیستم کامل و بینقصی وجود ندارد، اما راهحلهایی برای رفع نیازهای خاص و مقابله با سطوح مختلفی از پیچیدگی وجود دارد.
فیلترینگ مشارکتی (Collaborative Filtering)
حلقههای بازخورد کاربران زیربنای این نوع فیلترینگ را تشکیل میدهد. این بازخورد میتواند شامل امتیازدهی کاربران، پسندیدن یا نپسندیدن کاربران یا حتی میزان توجه و استفادۀ کاربران از یک محتوای خاص باشد.
فیلترینگ مشارکتی دارای دو دید محدود و کلی است.
در دید محدود، فیلترینگ مشارکتی به روشی برای پیشبینی خودکارِ علایق کاربران گفته میشود. این روش با گردآوری دادهها از کاربران گوناگون اقدام به تصمیمگیری میکند. روش فیلترینگ مشارکتی بر پایه این فرض استوار است که اگر شخص A دیدگاهی یکسان با شخص B درباره یک موضوع داشته باشد، احتمال آن زیاد است که شخص B دیدگاه شخص A را در خصوص موضوع متفاوتی بداند.
سرویس رسانهایِ نتفلیکس با توجه به فهرستی از سلایق کاربران، از فیلترینگ مشارکتی برای پیشبینی علاقمندیِ کاربران به نمایشهای تلویزیونی استفاده میکند. توجه داشته باشید که این پیشبینیها مختص کاربران است، اما از اطلاعاتِ جمعآوری شده از کاربران گوناگون استفاده میکند.
در فرمول فیلترینگ مشارکتی که اولین نوع سیستم های توصیه گر است، هر کاربر با یک بردار N-بُعدی نشان داده میشود، که N برابر تعداد محصولات مختلف در کاتالوگ است که کاربر امکان انتخاب آنها را دارد؛ هنگامی که کاربر در مورد یک محصول استفاده کرده و در مورد آن نظر مساعدی ارائه دهد، عنصر متناظر با آن محصول در بردار کاربر با مقداری مثبت مقداردهی مییشود، در غیر این صورت با مقداری منفی مقداردهی خواهد شد.

در بدترین حالت پیچیدگی محاسباتی فیلترینگ مشارکتی عبارت است از O(MN) که M تعداد مشتریان و N تعداد محصولات موجود در کاتالوگ است. از آنجا که بردار متوسط مشتری معمولا خیلی باریک است، پیچیدگی زمانی فیلترینگ مشارکتی به سمت O(M+N) میل میکند.
از دید کلی، فیلترینگ مشارکتی به فرایند پالایش اطلاعات یا الگوها با استفاده از روشهای مشارکتمحور در میان عوامل، دیدگاه، منابع داده مختلف و… گفته میشود. فیلترینگ مشارکتی معمولا بر روی مجموعهدادههای خیلی بزرگی اعمال میشود و انواع مختلفی از آن وجود دارد:
• کاربر-کاربر
• آیتم-آیتم
• کاربر-آیتم
کاربر-کاربر:
پرکاربردترین الگوریتم سیستم های توصیهگر از این منطق پیروی میکند: «افرادی مثل شما از فلان چیز خوششان میآید.» این الگوریتم، آیتمها، اقلام یا کالاهایی را پیشنهاد میدهد که قبلاً کاربران مشابه آنها را دوست داشتهاند. وجه تشابه میان دو کاربر با توجه به تعداد آیتم¬های مشترکی که در مجموعهداده برای آنها وجود دارد، محاسبه میشود. این الگوریتم زمانی کارآمد عمل میکند که تعداد کاربران کمتر از تعداد آیتم باشد.
در همین راستا، میتوان یک وبسایت تجارت الکترونیک با میلیونها محصول را مثال زد. عیب اصلی الگوریتم مذکور این است که افزودن کاربران جدید هزینههای زیادی به همراه دارد، زیرا این کار مستلزم بهروزرسانیِ تمامی شباهتهای میان کاربران است.
آیتم-آیتم:
از همان روش قبل استفاده میشود. منطقِ حاکم در آن بدین صورت است که: «اگر این محصول/کالا را دوست داشته باشید. شاید آن یکی را هم دوست داشته باشید.» به عبارت دیگر، آیتمهایی به شما پیشنهاد میشود که به آیتمهایی که پیشتر دوست داشته بودید، شباهت دارد. همان طور که در بخش پیشین ملاحظه کردید، شباهت میان دو آیتم با استفاده از تعداد کاربرانی که در استفاده از آن آیتم ها اشتراک دارند، محاسبه میشود.
این الگوریتم زمانی عملکرد بهتری از خود بر جای میگذارد که تعداد آیتمها بیشتر از تعداد کاربران باشد. یک فروشگاه¬ بزرگ اینترنتی میتواند مثال مناسبی در این مورد باشد به شرطی که مجموعه آیتم ها زیاد تغییر نکند. از جمله معایب عمده این روش این است که باید جداول تشابه آیتم-آیتم از پیش محاسبه شوند. بهروزرسانیِ این جداول در هنگام افزودن آیتمهای جدید کار پیچیده و هزینهبری است.
کاربر-آیتم:
در این رویکرد، دو رویکرد فوق برای ارائه توصیه با هم ادغام میشوند. سادهترین روشها در این رویکرد بر پایه روش تجزیه ماتریس ارائه شده اند. هدف از این کار، ایجاد بردارهایی با ابعاد کمتر برای همه کاربران و همه آیتم هاست. ادغام اینها با یکدیگر میتواند نشان دهد که کاربر، فلان آیتم را دوست دارد یا خیر.
ماتریس کاربر-آیتم یکی از پایههای اساسی روشهای فیلترینگ مشارکتی سنتی برشمرده میشود. این ماتریس با مسئله پراکندگی دادهها مواجه است. تجزیه ماتریس باSVD Singular Value Decomposition امکانپذیر است، اما هزینههای محاسباتی بالایی دارد.
استفاده از ALS در دیتاست هایی که اندازه متوسطی دارند، گزینه مناسبی است. در دیتاستهای بزرگ، فقط الگوریتم SGD Stochastic Gradient Descent قادر به مقیاسبندی است. اما این مورد هم به قدرت محاسباتی قابل توجهی احتیاج دارد.
همانطور که در سناریوی توصیهگر شخصی ملاحظه شد، افزودن کاربران جدید یا آیتمهای جدید میتواند باعث بروز«مشکل آغاز سرد» cold-start problem شود. فیلترینگ مشارکتی به دلیل مواجهه با کمبود داده در این ورودیهای جدید قادر به ارائه عملکرد دقیق نخواهد بود.
برای اینکه سیستم، توصیههای مناسبی برای کاربر جدید ارائه کند، باید در ابتدا امتیازدهی و رایدهیِ گذشتۀ کاربران را مورد تجزیه و تحلیل قرار داده تا علایق آنها را تشخیص دهد. سیستم فیلترینگ مشارکتی به تعداد قابل توجهی از کاربران نیاز دارد تا پیش از توصیۀ یک آیتم جدید به آن رای دهند. دو نوعِ اصلی سیستم فیلترینگ مشارکتی وجود دارد که در زیر به آنها اشاره میکنیم:
مدلمحور:
این سیستم از روشهای مختلفی مثل دادهکاوی و الگوریتمهای یادگیری ماشینی برای پیشبینیِ امتیار کاربران به آیتمهایی که هنوز به آنها رای داده نشده، استفاده میکند. استفاده از الگوریتمهای مبتنی بر خوشهبندیk-نزدیکترین همسایه یا (KNN) K-Nearest Neighbor (KNN)، روشهای فاکتورگیری ماتریس (SVD)، فاکتورگیری احتمالی و یادگیری عمیق (شبکههای عصبی) در دستور کار این سیستم قرار دارد.
حافظهمحور:
این سیستم از دادههای امتیازدهی کاربران برای محاسبه میزان شباهت استفاده میکند. یافتن میزان شباهت با استفاده از همبستگیهای پیرسون Pearson correlation یا کسینوس Cosine similarity انجام میگیرد. این روش به سادگی قابل توصیف است ولی در مقیاسهای بزرگ قابل استفاده نیست.
مبتنی بر محتوا
همه مدلهای پیشین با مشکل آغاز سرد، دستوپنجه نرم میکنند. روشهای فیلترینگ مبتنی بر محتوا بر اساس توضیحات آیتم (جنس یا کالا) و فهرستی از ارجحیات کاربران کار میکنند. این روشها مناسبِ شرایطی هستند که در آنها دادههای معلومی در خصوص آیتمها وجود داشته باشد (مثل نام، موقعیت، توضیحات و…)، در حالیکه داده کافی درباره کاربران در دسترس نیست.
سیستم های توصیه گر مبتنی بر محتوا، توصیه را به عنوان نوعی مسئله طبقهبندی در نظر میگیرند که مختص کاربران است. این سیستم های توصیه گر از طبقه بندیها برای دستهبندی موارد پسندیده شده و پسندیده نشدۀ کاربران استفاده میکنند. توجه به ویژگیهای محصول در دستور کار آن قرار دارد. در این سیستم، از کلیدواژهها برای توصیف آیتمها یا کالاها استفاده میشود و یک پروفایل برای نمایشِ نوع آیتمی که کاربران دوست دارند، ساخته میشود.
الگوریتم سیستم های توصیه گر سعی میکنند آیتمهایی را پیشنهاد دهند که به آیتمهای پسندیده شدۀ قبلی کاربر، شباهت داشته باشند. ریشههای این روش را باید در تحقیقات فیلترینگ و بازیابی اطلاعات جستجو کرد. پیشرفت اخیرِ شناسایی الگو در یادگیری ماشین، منجر به ارتقای قابل توجهِ مدلهای محتوا محور شده است. این روش عملکردی یکسان با الگوریتمهای آیتم-آیتم یا کاربر-کاربر دارد؛ با این تفاوت که وجوه تشابه با استفاده از ویژگیهای محتوا محور محاسبه میشوند.
فیلترینگ مشارکتی و فیلترینگ محتوا محور

مطالعات موردی
در مطالعات موردیِ زیر از پایتون و یک مجموعهداده عمومی استفاده میشود. همچنین، مقاله حاضر به طور اختصاصی از مجموعهداده MovieLens استفاده میکند. فایلِ حاوی «MovieLens 100k dataset» میتواند مجموعهداده مناسبی با 100.000 امتیازدهی باشد. در این مورد، 943 کاربر به 1682 فیلم امتیاز دادهاند به طوریکه هر کاربر، دستکم به 20 فیلم امتیاز داده است. این مجموعهداده متشکل از فایلهای زیادی است و حاویِ اطلاعاتی درباره فیلمها، کاربران و امتیازِ کاربران به فیلمها است. به چند مورد جالب در بخش زیر توجه کنید.
•u.item : فهرست فیلمها
•u.data : فهرست امتیاز کاربران
پنج خط اول فایل به صورت زیر است:

این فایل مربوط به امتیاز کاربران به فیلم است. 100.000 موردِ امتیازدهی مانند جدول فوق در پایگاه داده مذکور ثبت شده است. این اطلاعات برای پیشبینیِ امتیاز فیلمهایی استفاده خواهد شد که کاربران آنها را تماشا نکردهاند.
فیلترینگ مشارکتی حافظهمحور
در این نوع فیلترینگ که در واقع نوع دوم سیستم های توصیه گر است، روشهای آماری در کل مجموعهداده برای محاسبه پیشبینیها به کار برده میشوند. برای اینکه امتیاز R که کاربر U به آیتم I خواهد داد را پیدا کنیم، باید مراحل زیر را طی شود:
• پیدا کردن کاربران شبیه به U که به مورد I رای دادهاند.
• محاسبه امتیاز R بر اساس امتیاز کاربران در مرحله پیشین
با توجه به اینکه هر کاربر به منزلۀ یک بردار است، «scikit» از یک تابع برای محاسبه فاصله کسینوسی در هر بردار استفاده میکند.
>>> from scipy import spatial >>> a = [1, 2] >>> b = [2, 4] >>> c = [2.5, 4] >>> d = [4.5, 5] >>> spatial.distance.cosine(c,a) 0.004504527406047898 >>> spatial.distance.cosine(c,b) 0.004504527406047898 >>> spatial.distance.cosine(c,d) 0.015137225946083022 >>> spatial.distance.cosine(a,b) 0.0
زاویه کم میان بردارهای A و C منجر به تولید فاصله کوسینوسی کم میان این بردارها خواهد شد.
توجه داشته باشید که کاربران A و B علیرغم اینکه امتیاز متفاوتی دادهاند، اما در متریک شباهت کسینوس کاملاً مشابهاند. این اتفاق در دنیای واقعی عادی است هنگامیکه کاربرانی مانند A سختگیرانه امتیاز میدهند.
برای مثال، یک منتقد فیلم را در نظر بگیرید که همیشه پایینتر از مقدار میانگین رای میدهد، اما امتیاز مواردی که در فهرستشان است به امتیازدهندگان متوسطی مثل B شباهت دارد. در همین راستا، باید امتیازها را نرمال¬سازی کنیم تا سوگیریها از بین بروند. مراحل نرمالسازی به صورت زیر است:
- در خصوص کاربر A، بردار امتیازدهی [2, 1] دارای میانگینِ 1.5 است. کسرِ 1.5 از عناصر این بردار، بردار [0.5, 0.5-] را حاصل میکند.
- در خصوص کاربر B، بردار امتیازدهی [4, 2] دارای میانگین3 است. کسرِ 3 از هر امتیاز این بردار، به بردار[1, 1-] ختم میشود.
با پیادهسازیِ همین روش برای کاربران C و D میبینیم که امتیازها تنظیم شدهاند تا میانگینِ «صفر» برای همه کاربران منظور شود. بنابراین، همه آنها به سطح یکسانی میرسند و سوگیریها حذف میشود. کسینوس زاویه میان بردارهای تنظیم شده «کسینوس مرکزی» نامیده میشود. این روش معمولاً زمانی مورد استفاده قرار میگیرد که تعداد مقادیر گمشده در بردارها زیاد باشد و باید مقدار متداولی را برای پر کردن مقادیر گمشده (ناموجود) به کار برد.
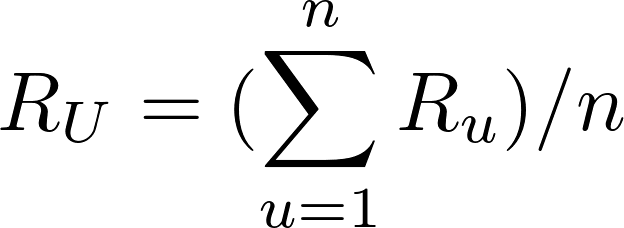
یکی از گزینههای مناسب برای پر کردن جای خالیِ مقادیر گمشده، امتیاز متوسط هر کاربر است. اما میانگین اصلی کاربر A و B به ترتیب 1.5 و 3 است. اگر مقادیر خالیِ A را با 1.5 و B را با 3 پر کنیم، وجه تشابه آن کاربران از بین میرود. عادیسازی Normalization میتواند این مسئله را حل کند، زیرا میانگین مرکزیِ هر دو کاربر برابر با 0 است؛ پس میتوان نتیجه گرفت که مقادیر گمشده، 0 هستند.
پس از اینکه فهرستی از کاربران شبیه به کاربر U تهیه شد، میتوان مقدار امتیاز R را که U به مورد I خواهد داد را محاسبه نمود. این کار میتواند به چندین روش انجام شود. میتوان پیشبینی کرد که امتیاز R یک کاربر به مورد I به میانگینِ امتیازِ داده شده به I نزدیک خواهد بود. فرمول ریاضیِ میانگین امتیاز n کاربر به صورت زیر محاسبه میشود:
این فرمول نشان میدهد که امتیاز متوسط n کاربر، برابر است با مجموع امتیازات داده شده توسط آنان، تقسیم بر n. در برخی از شرایط، مجموعه n کاربر مشابه، به طور مساوی شبیهِ کاربر هدف U نیستند. ممکن است 3 عدد از کاربران شباهت زیادی با کاربر U داشته باشند ولی سایر کاربران از مجموعه nتایی چنین شباهتی را با کاربر U نداشته باشند. بنابراین، میتوانید روشی را در نظر بگیرید که در آن، امتیاز مشابهترین کاربران اهمیتی بیشتر از امتیاز کاربری با سطح مشابهت کمتر دارد.
میانگین وزنی weighted average میتواند نقش موثری در حصول این هدف داشته باشد. در روش میانگین وزنی، هر امتیاز به ضریب تشابه ضرب میشود سپس با یکدیگر جمع میشوند. هر چقدر وزن سنگینتر باشد، امتیازدهی اهمیت بیشتری پیدا میکند. ضریب تشابه که به عنوان وزن عمل میکند، باید معکوس فاصلهای باشد که در فوق به آن اشاره شد زیرا فاصله کمتر به معنای تشابه بیشتر است.
برای مثال، میتوان فاصله کسینوسی را از 1 کم کرد تا شباهت کسینوسی به دست آید. با داشتنِ ضریب تشابه S برای هر کاربر، میتوان میانگین وزنی را با استفاده از فرمول زیر محاسبه کرد:

بر اساس فرمول فوق، هر امتیازبندی به ضریب تشابه کاربری که امتیازبندی کرده ضرب میشود. امتیاز نهاییِ پیشبینیشده توسط کاربر U برابر با مجموع امتیاز وزنی، تقسیم بر مجموع وزنها است. با داشتنِ میانگین وزنی، امتیازبندیِ کاربران مشابه بیشتر مورد توجه قرار میگیرد. این روش مثالی از فیلترینگ مشارکتی کاربر-کاربر است.
اگر بر اساس امتیازبندیِ کاربران از ماتریس امتیازبندی برای یافتن موارد مشابه استفاده کنیم. روشِ مورد استفاده نوعی فیلترینگ مشارکتی آیتم-آیتم به حساب میآید. باید به این نکته توجه داشت که روش آیتم-آیتم (Item-Item) عملکرد ضعیفی در مجموعهدادههایی با موارد مرتبط با سرگرمی مثل MovieLens دارد. چنین مجموعهدادههایی نتایج بهتری را با روشهای فاکتورگیری ماتریس به دست میآورند.
فیلترینگ مشارکتی مدلمحور
در ماتریس کاربر-آیتم (User-Item)، دو بعد تحت عنوان «تعداد کاربران» و «تعداد آیتمها یا موارد» وجود دارد. اگر ماتریس عمدتاً خالی (پراکنده) باشد، کاهش ابعاد میتواند عملکرد الگوریتم را به لحاظ فضا و زمان ارتقاء ببخشد. یکی از متداولترین روشها برای انجام این کار، فاکتورگیری ماتریس است.
فاکتورگیری ماتریس Matrix factorization میتواند ماتریس بزرگی را به ماتریسهای کوچکتر تجزیه کند. این کار به فاکتورگیری از اعداد صحیح شباهت دارد؛ یعنی میتوان 12 را به صورت 6×2 یا 4×3 نوشت. ماتریس A با ابعاد m×n میتواند به دو ماتریس X و Y به ترتیب با ابعاد m×p و p×n تقسیم شود. بسته به الگوریتمی که برای کاهش ابعاد استفاده میشود، تعداد ماتریسهای کاهشیافته میتواند بیشتر از دو مورد باشد. m ردیف ماتریس اول، نشان دهنده m کاربر است. ستونهای p اطلاعاتی درباره ویژگیها یا خصوصیات کاربران به دست میدهد. همین مورد برای ماتریسی با n آیتم و p خصوصیات صِدق میکند.

بیایید نمونهای از فاکتورگیری ماتریس را بررسی کنیم:
در عکس فوق، ماتریس به دو ماتریس دیگر تقسیم شده است. ماتریس سمت چپ، ماتریس کاربر با m کاربر است. ماتریس بالا هم n آیتم دارد. امتیاز4 کاهش داده شده یا به صورت زیر فاکتورگیری میشود:
• بردار کاربر (1-، 2)
• بردار آیتم (1، 2.5)
دو ستون در ماتریس کاربر و دو ردیف در ماتریس آیتم «فاکتور پنهان» نام دارند. نشاندهندۀ خصوصیات پنهانِ کاربران یا آیتمها هستند. فاکتورگیری به صورت زیر تفسیر میشود:
• فرض کنید در یک بردار کاربر (u, v) و u نشان میدهد که کاربر چقدر ژانر وحشت را دوست دارد و v نشاندهنده این است که کاربر تا چه حد به ژانر عاشقانه علاقه دارد.
بردار کاربر (1- و 2 ) کاربری را نشان میدهد که فیلمهای ترسناک را دوست دارد و به آنها امتیاز مثبت میدهد؛ او علاقهای به فیلمهای عاشقانه ندارد و به آنها امتیاز منفی میدهد.
• فرض کنید در یک بردار آیتم (i, j) و i نشاندهنده این است که فیلم تا چه اندازه به ژانر وحشت تعلق دارد و j نشان میدهد که آن فیلم تا چه اندازه در ژانر عاشقانه جای میگیرد.
• فیلم (1 و 2.5) دارای امتیاز وحشت2.5 و امتیاز عاشقانه1 است. ضربِ آن به بردار کاربر با استفاده از قواعد ضرب ماتریس ختم میشود به: 4= (1- * 1) + (2 * 2.5)
• بنابراین، آن فیلم به ژانر وحشت تعلق دارد و کاربر میتوانست امتیاز5 را به آن بدهد، اما دخالت اندکِ ژانر عاشقانه باعث شد امتیاز پایانی به 4 کاهش پیدا کند.
این نوع ماتریسها میتواند بینش خوبی در خصوص کاربران و آیتمها فراهم کنند، اما در واقعیت بسیار پیچیده هستند. تعداد این فاکتورها میتواند از یک تا صد یا هزار مورد متغیر باشد. این تعداد یکی از مواردی است که باید در حین آموزشِ مدل، بهینهسازی شود. در مثال فوق، دو فاکتور پنهان برای ژانر فیلم وجود داشت. اما در سناریوهای واقعی، نیازی نیست این فاکتورهای پنهان را بیش از حد تجزیه و تحلیل کرد.
الگوهایی در داده وجود دارند که نقش خود را به صورت خودکار بازی میکنند. فرقی هم نمیکند معنای ضمنی آنها را استخراج کنید یا نه. تعداد فاکتورهای پنهان بر توصیه اثر میگذارد. یعنی هر چه تعداد فاکتورها بیشتر باشد، توصیهها شخصیتر میشوند. تعداد زیادِ فاکتورها میتواند باعث بروز بیشبرازش در مدل شود.
# load_data.py
import pandas as pd
from surprise import Dataset
from surprise import Reader
# This is the same data that was plotted for similarity earlier
# with one new user "E" who has rated only movie 1
ratings_dict = {
"item": [1, 2, 1, 2, 1, 2, 1, 2, 1],
"user": ['A', 'A', 'B', 'B', 'C', 'C', 'D', 'D', 'E'],
"rating": [1, 2, 2, 4, 2.5, 4, 4.5, 5, 3],
}
df = pd.DataFrame(ratings_dict)
reader = Reader(rating_scale=(1, 5))
# Loads Pandas dataframe
data = Dataset.load_from_df(df[["user", "item", "rating"]], reader)
# Loads the builtin Movielens-100k data
movielens = Dataset.load_builtin('ml-100k')
k-نزدیکترین همسایه (k-NN) و فاکتورگیری ماتریس
کتابخانه Surprise، الگوریتم های بسیاری دارند که به سادگی قابل استفاده هستند، مانند k-NN.
# recommender.py
from surprise import KNNWithMeans
# To use item-based cosine similarity
sim_options = {
"name": "cosine",
"user_based": False, # Compute similarities between items
}
algo = KNNWithMeans(sim_options=sim_options)
اکنون میتوان با استفاده از k-NN به آموزش و پیشبینی پرداخت:
>>> from load_data import data
>>> from recommender import algo
>>> trainingSet = data.build_full_trainset()
>>> algo.fit(trainingSet)
Computing the cosine similarity matrix...
Done computing similarity matrix.
<surprise.prediction_algorithms.knns.KNNWithMeans object at 0x7f04fec56898>
>>> prediction = algo.predict('E', 2)
>>> prediction.est
4.15
در نهایت، پارامترها و خطای مجذر میانگین مربعات به طور دقیق تنظیم و محاسبه میشوند:
from surprise import KNNWithMeans
from surprise import Dataset
from surprise.model_selection import GridSearchCV
data = Dataset.load_builtin("ml-100k")
sim_options = {
"name": ["msd", "cosine"],
"min_support": [3, 4, 5],
"user_based": [False, True],
}
param_grid = {"sim_options": sim_options}
gs = GridSearchCV(KNNWithMeans, param_grid, measures=["rmse", "mae"], cv=3)
gs.fit(data)
print(gs.best_score["rmse"])
print(gs.best_params["rmse"])
توصیهگر SVD
به جای استفاده از k-NN، امکان اجرای الگوریتم سیستم های توصیه گر با استفاده از SVD نیز وجود دارد.
from surprise import SVD
from surprise import Dataset
from surprise.model_selection import GridSearchCV
data = Dataset.load_builtin("ml-100k")
param_grid = {
"n_epochs": [5, 10],
"lr_all": [0.002, 0.005],
"reg_all": [0.4, 0.6]
}
gs = GridSearchCV(SVD, param_grid, measures=["rmse", "mae"], cv=3)
gs.fit(data)
print(gs.best_score["rmse"])
print(gs.best_params["rmse"])
خروجیِ برنامه فوق به شرح زیر است:
0.9642278631521038
{'n_epochs': 10, 'lr_all': 0.005, 'reg_all': 0.4}



















