

شبکه های عصبی برآورد حالت انسان : HRNet ،HigherHRNet، معماریها و FAQ
 تیم تحریریه
تیم تحریریه- ۱ تیر ۱۴۰۰
شبکه وضوح بالا (HRNet) در بین شبکه های عصبی برآورد حالت انسان یک اثر هنری به شمار میرود. تخمین حالت انسان یک روند پردازش تصویر است که میتواند ساختاربندی مفاصل و اعضای بدن یک سوژه (فرد) را در یک تصویر پیدا کند. تازگی این شبکه در این است که بازنمایی دیتای ورودی را با وضوح بالا حفظ کرده و آن را به طور موازی با زیرشبکههایی که وضوحشان از زیاد تا کم است، ترکیب میکند و به صورت همزمان پیچیدگی محاسبات و شمار پارامترها را در حد کارآمد نگه میدارد.
ویدئوی دمو
در این مطلب به این مباحث از شبکه های عصبی برآورد حالت انسان خواهیم پرداخت:
- چرا HRNet؟
- HRNet و معماری
- HigherHRNet: یادگیری بازنمایی مقیاس محور برای تخمین حالت انسان از روش پایین به بالا
- ویدئو دمو
- سوالات رایج در کدنویسی
چرا HRNet؟
- منابعی از بهترینهای حوزه شبکه های عصبی برآورد حالت انسان فراهم میآورد که هم به خوبی ثبت و تدوین شده اند و هم در دسترس هستند (2490 ستاره در پلتفورم github به دست آورده است – لینک).
- محور اصلی معماریهای اخیر در حوزههای مشابه محسوب میشود. (نمونه در یک پروژه)
- در بسیاری از چالشهای برآورد حالت، رقیب اصلی به شمار میرود. (مرجع)
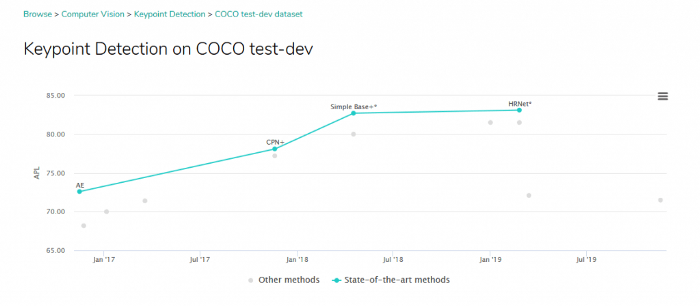
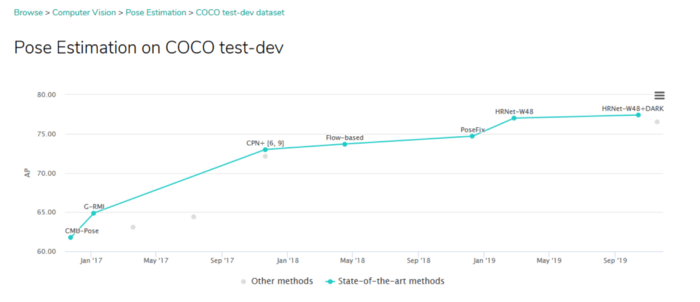
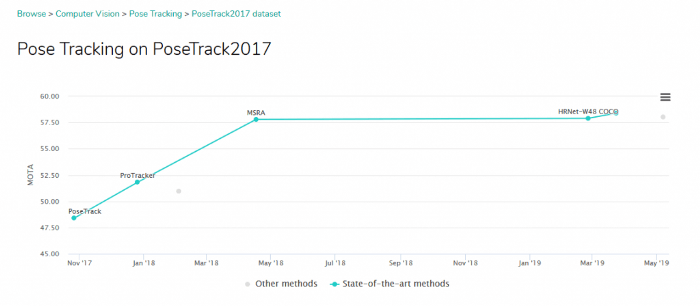

معرفی HRNet
وقتی صحبت از شبکه های عصبی برآورد حالت انسان میشود، منظورمان این است که بتوانیم یک فرد را در یک تصویر تشخیص دهیم و ساختاربندی مفاصل (یا نقاط اصلی) وی را تخمین بزنیم. دو روش برای برآورد حالت وجود دارند:
برآورد حالت از بالا به پایین و از پایین به بالا
در رویکرد از پایین به بالا ابتدا نقاط کلیدی پیدا شده و سپس به افراد متفاوت حاضر در تصویر مرتبط میشوند؛ ولی در روش از بالا به پایین ابتدا از مکانیزمی استفاده میشود تا افراد در تصویر مشخص گردند، یک کادر محصور کننده اطراف هر فرد تعریف میشود و سپس ساختار و جایگیری نقاط کلیدی درون این کادرها تخمین زده میشود.
متودهای از بالا به پایین برای تشخیص فرد به شبکههای دیگر اتکا دارند و نیاز دارند نقاط کلیدی را برای هر فرد به طور جداگانه تخمین بزنند. بنابراین معمولا از نظر محاسباتی قوی بوده و نمیتوان گفت سیستمهای نقطه به نقطهای end-to-end هستند. در سوی دیگر متودهای از پایین به بالا وجود دارند که با تشخیص محل نقاط کلیدی بدون تعیین هویت همه افراد حاضر در تصویر ورودی شروع میکنند. بدین منظور نقشههای حرارتی نقاط کلیدی بدنی را پیشبینی کرده و سپس آنها را در قالبها (نمونهها)ی فردی گروهبندی میکنند. این فرآیند باعث افزایش سرعت در این متود میشود.
از آنجایی که رویکرد از بالا به پایین دو وظیفه را از هم جدا میکند تا از شبکه های عصبی برآورد حالت انسان تربیت شده خاص هرکدام استفاده کند، هم رواج بیشتری دارد و هم در حال حاضر قابلیت پیشبینی آن صحیحتر است. یک دلیل دیگر این برتری این است که در متود دیگر (از پایین به بالا) مشکلاتی در مورد پیشبینی نقاط کلیدی وجود دارد که دلیل آن تفاوت اندازه افراد در یک تصویر است (برای رفع این مشکل HigherHRNet به وجود آمده که جلوتر به توضیح آن خواهیم پرداخت). این تنوع در اندازهها در روشهای بالا به پایین دیده نمیشود، زیرا همه نمونهها (افراد) در یک مقیاس مشابه هنجار شدهاند. با اینکه سرعت روش پایین به بالا بیشتر به نظر میرسد، اما از آنجایی که HRNet از روش بالا به پایین استفاده میکند، شبکه به نحوی ساخته شده که نقاط کلیدی را بر اساس کادرهای محصورکننده افراد برآورد میکند. این کادرها خود طی فرآیند استنتاج/ آزمون توسط شبکه دیگری (FasterRCNN) تعیین میشوند. در طول آموزش، HRNet از کادرهای مشخص شده در دادههای dataset ارائه شده استفاده میکند.
دو دسته دیتا برای آموزش و ارزیابی شبکه استفاده میشوند.
- COCO: بیشتر از 200 هزار تصویر و 250 هزار نمونه فردی را شامل میشود که 17 نقطه کلیدی دارند. ارزیابی دیتاهای COCO dataset نیازمند ارزیابی کادرهای محصورکننده هر فرد است که از طریق شبکه FasterRCNN انجام میشود. مقیاس اندازهگیری در این ارزیابی شباهت نقاط کلیدی شیء Object Keypoint Similarity (OKS) است که یک سیستم اندازهگیری استاندارد برای ارزیابی صحت تشخیص نقاط کلیدی است.
- حالت انسانی MPII: حدود 25 هزار تصویر با 40 هزار سابجکت (فرد) را در بردارد. ارزیابی MPII با کادرهای حاشیهنویسی شده از دیتاهای dataset انجام میشود.
معماری
در ادامه نمودار شبکه های عصبی را میبینید که بر اساس کد ارائه شده در پروژه git به دست آمده و به دنبال آن نیز نمودار شبکه را آنطور که در مقاله پژوهشی شرح داده شده، مشاهده خواهید کرد.
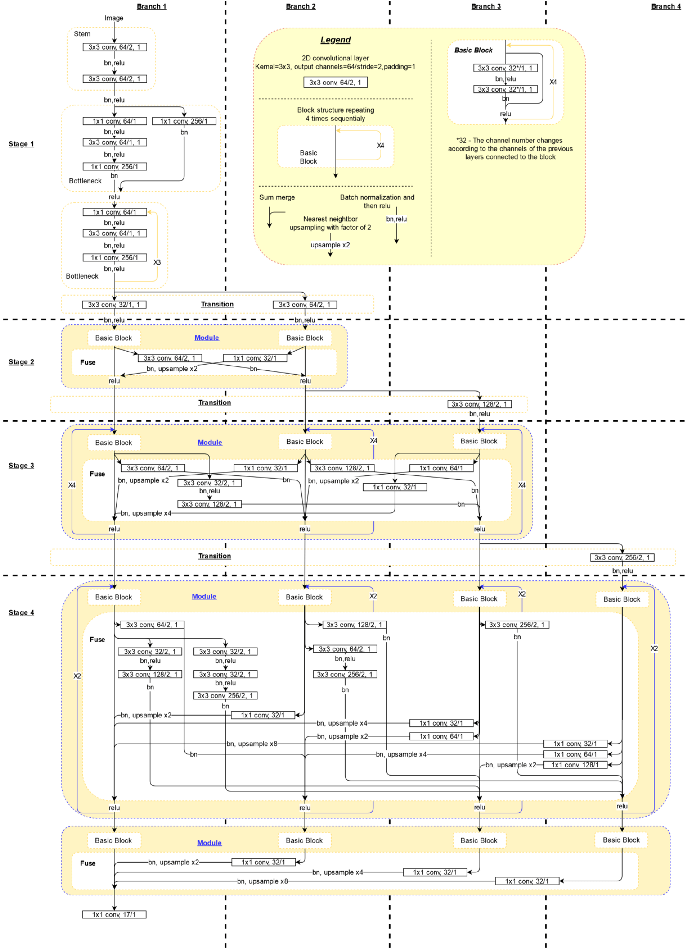

ساختار مهمی که باید به آن توجه داشت این است که شبکه، زیرشبکه وضوح بالا (یعنی شاخه اول) را به طور موازی با زیرشبکههایی که وضوح پایینتری دارند (شاخه 2-4) محاسبه میکند. زیرشبکهها از طریق لایههای پیوندی به یکدیگر متصل میشوند؛ به صورتی که هر کدام از بازنماییها با وضوح بالا تا پایین، متوالیا اطلاعاتی را از بازنمایی¬های موازی دیگر دریافت میکنند و این به بازنماییهایی با وضوح بالا منتهی میشود.
تصویر ورودی یا 256×192 است و یا 384×288 و اندازه نقشه حرارتی خروجی مربوطه نیز یا 64×48 می-باشد و یا 96×72 . دو لایه پیچش اول Convolution layer، اندازه تصویر ورودی را بر اساس اندازه نقشه حرارتی مورد انتظار کاهش میدهد. شبکه نیز اندازه نقشههای حرارتی و 17 کانال را بیرون میدهد (کانال: ارزش هر پیکسل در نقشه¬ی حرارتی به ازای هر نقطه کلیدی).
معماری متنبازی که نمایش داده شده برای یک ساختار 32 کانالی است. برای حالت 48 کانالی، کانالها لایه به لایه تغییر میکنند، بدین صورت که از اولین لایه¬ی تبدیلی شروع شده و تا لایه 48 ادامه مییابد (ضرایب متفاوت از عدد 2).
بلوک تبادلی در این مقاله یک واحد در متن باز است و واحد تبادلی نیز لایه پیوندی در متنباز میباشد. در نمودار مقاله، لایه تبدیلی همچون یک پیوند مستقل بین زیرشبکههاست، در حالیکه در کدنویسی زمانی که شبکهای با وضوح پایینتر (کانال بالاتر) ایجاد میکنیم، تبدیلی که منجر به آن میشود، خود بر اساس پیوندی است که باعث ایجاد زیرشبکه قبلی که پایینترین وضوح را داشته با یک لایه انحنایی دیگر شده است. همچنین در متنباز، پیوند آخرین لایه تنها برای شاخه با وضوح بالا (شاخه¬ی 1) محسوب میشود، نه برای همه شاخههایی که در نمودار این مقاله نشان داده شدهاند.
کاهش نمونهگیری که پیچشهایی است با خصوصیت stride=2، نتیجه تبدیل شاخههای با وضوح بالا به شاخههای با کیفیت پایین در بخش اتصال (یا واحد تبادلی) هستند. کاهش نمونهگیری دو یا سه گانه تعداد کانالها را تنها در آخرین نمونه کاهش یافته بزرگ میکند. این موضوع یا یک مشکل در کدنویسی است و یا در مقاله به روشنی توضیح داده نشده است. از آنجایی که برای اولین نمونههای کاهش یافته، اطلاعات از دقت بالاتر در کانالهای عمیقتر نقشه برداری نشدهاند، احتمال اینکه مسئله بیان شده یک اشتباه در کدنویسی باشد بیشتر است. برای آشنایی بیشتر با این مسئله در نرمافزار git اینجا کلیک کنید.
آموزش شبکه
- نویسندگان به منظور مقداردهی به وزنها شبکه مشابهی را با یک لایه خروجی متفاوت بر روی ردهبندی دادههای دیتاست ImageNet آموزش داده و از مقادیر وزنها به عنوان مقادیر اولیه برای آموزش برآورد حالت استفاده کردند.
- آموزش 210 دوره از HRNet-W32 بر روی مجموعه دیتای COCO dataset با استفاده از 4P100 GPU تقریبا حدود 50 تا 60 ساعت زمان میبرد. منبع
HigherHRNet: بازنمایی مقیاس محور از آموزش برآورد حالت انسانی از پایین به بالا
این مفهوم در واقع شبکه های عصبی برآورد حالت انسان جدید همان تیم تحقیقاتی است، با این ویژگی که برای یافتن حالت به روش از پایین به بالا به طور اصلی از HRNet استفاده میکنند. نویسندگان به مشکل تغییرپذیری اندازه در روش برآورد حالت از پایین به بالا (همان مشکلی که پیشتر ذکر شد) پرداختند و دریافتند که میتوانند با خروج نقشههای حرارتی چند وضوحی و استفاده از بازنماییهای وضوح بالا که HRNet امکانش را فراهم میکند، این مشکل را حل کنند.
HigherHRNet از سایر روشهای پایین به بالا که در دیتاهای دیتاست COCO اجرا میشوند قویتر است و این مسئله به خصوص در مورد افراد میانه فواید زیادی دارد. HigherHRNet در مورد دادههای دیتاست CrowdPose نیز به نتایج چشمگیری دست یافته است. نویسندگان معتقدند که این بدین معنی است که روشهای از پایین به بالا در صحنههای پرجمعیت (شلوغ) نسبت به روشهای بالا به پایین قابل اتکاتر هستند. با این وجود در دیتاهای دیتاستهای مشابه، بین این مسئله با نتایج منظم HRNet در روش بالا به پایین مقایسهای صورت نگرفته است.
در صورتی که یک بخش دیگر برای نقشههای حرارتی با وضوح بالاتر به انتهای HRNet منظم اضافه شود، میتواند در این شبکه نقش محوری داشته باشد.
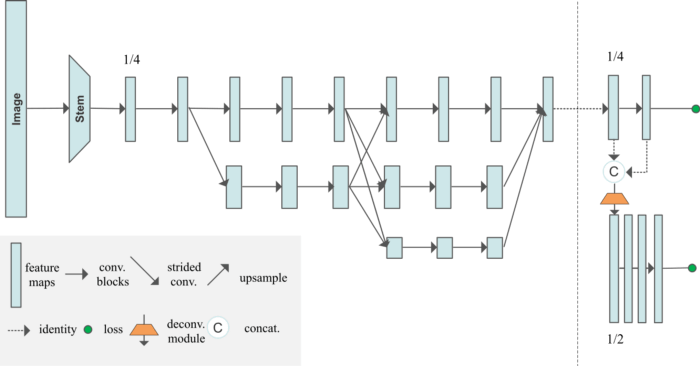
سمت راست این معماری دو نقشه حرارتی را بیرون میدهد که یکی برای وضوح بالا و یکی برای وضوح پایین است (رزولوشنها: 128×128 و 256×256). در طی استنتاج، نقشههای حرارتی به طور میانگین برای رسیدن به وضوح بالاتر تجمیع شده و بالاترین نقاط ارزش داده شده برای تشخیص نقاط کلیدی انتخاب میشوند. ذوزنقه (در تصویر) نشاندهنده یک لایه انحلالی است که خروجی آن وضوح دوبرابری به همراه 4 لایه residual دارد. همچنین برای هر نقطه کلیدی، یک تگ عددی خروجی محاسبه میشود، ارزش تگهای پایانی یک گروه از نقاط کلیدی را تشکیل میدهند که متعلق به یک فرد خاص هستند و ارزش تگهای دیستنت ، نقاط کلیدی را نشان میدهند که مربوط به گروههایی از افراد متفاوت میباشند. تگها بر اساس روش “تعبیه وابسته” که در این مقاله توضیح داده شده محاسبه میگردند. ارزش تگها فقط برای نقشه حرارتی که پایینترین وضوح را دارد آموزش داده شده و پیشبینی میشوند، زیرا نویسندگان به این نتیجه رسیدند که ارزش تگهای نقشههای حرارتی که وضوح تجربی بالاتری دارند نمیتوانند پیشبینی را خوب بیاموزند و حتی همگرایی هم ندارند.
تابع زیان میانگین ضریبدار اتلاف پیشبینی نقشه حرارتی و اتلاف ارزش تگهاست (بر اساس روش تعبیه وابسته، فاصله اندک بین تگهایی که به یک گروه تعلق دارند و همچنین فاصله بیشتر بین تگهایی که از گروههای متفاوت هستند، منجر به اتلاف کمتر میشود). تابع زیان وضوح هر نقشه حرارتی بر اساس دادههای پایه و به صورت جداگانه و مستقل اندازهگیری شده و سپس به صورت تراکمی جمع میشوند.
با بررسی کد متنباز HigherHRNet متوجه میشویم که هنوز هیچ کد استنتاجی وجود ندارد که بتوان از آن برای ایجاد ویدئوهای دموی برآورد حالت بر اساس شبکه آموزش داده شده استفاده کرد.
ویدئوی دمو
ویدئوی دمو بر اساس متن استنتاجی از HRNet تهیه شده است (این نسخه تغییر یافتهای است که در آن بین مفاصل تمایز قائل شده و در حین اجرا، تصاویر ناگهانی را باز نمیکند – لینک نسخه – اعتبار متعلق به: Ross Smith’s Youtube channel)
مشخصات ویدئو
- 1920×1080 پیکسل، 25 فربم بر ثانیه، 56 ثانیه (1400 فریم).
- در بر داشتن نمونه¬های خوبی از صحنههای چندنفره و چالش برانگیز (با پیشزمینههای همگون و ناهمگون، پیش-زمینههای متغیر، زوایای مختلف دوربین که شامل زوم کردن و زوم اوت شدن هم میشود، و حتی کوتولهای که در اول ویدئو در حالتی غیرعادی دیده میشود).
اطلاعات زمان اجرا
- FasterRCNN با شبکه عصبی Resnet50 برای شناسایی فرد استفاده شد.
- HRNet با تصویر ورودی 48 کانال و وضوح 384×288 مورد استفاده قرار گرفت.
- از لپتاب Dell، Core i5-7200، 32GB RAM، GeForce 940MX، Ubuntu 18.04 استفاده شد. GPU در طی فرآیند استنتاج به استفاده 100% رسید.
- میانگین زمانی که صرف یافتن همه کادرهای موجود در یک فریم شد: 1.14 ثانیه.
- میانگین زمانی که صرف برآورد همه حالات در یک فریم شد: 0.43 ثانیه.
- میانگین زمان کل که صرف تجزیه¬ی یک فریم شد: 1.62 ثانیه.
- کل زمان لازم برای اینکه کد بتواند از کل ویدئو استنتاج انجام دهد: 2586.09 ثانیه.
مسائلی که در دمو پیش آمد
زمانی که نتایج یک الگوریتم پردازش تصویر را ارزیابی میکنیم، باید به این نکته توجه کنیم که الگوریتم کجا به خوبی عمل نکرده است. این به ما کمک میکند بتوانیم مشکلاتی که باعث این عملکرد ضعیف شدهاند را دنبال کنیم که در این مورد عبارت بودند از:
- وقتی افرادی که در قسمت بالاتنه پوشیده نبودند جلوی یک پیشزمینه چوبی قرار میگیرند، در FasterRCNN به خوبی تشخیص داده نمیشوند. این مسئله میتواند چندین علت داشته باشد: به خاطر مشکل درآموزش دادهها در شبکه FasterRCNN باشد، به خاطر کمبود نمونههای بدون پیراهن و یا کمبود نمونههایی که رنگ پیشزمینه در آنها با رنگ فرد نمونه در آنها مشابه و نزدیک است.
- ترمپولین زردرنگ بزرگی که به عنوان یک انسان تشخیص داده شد (در دقیقه¬ی 00.11 از ویدئو). این مشکل میتواند حاکی از یک مسئله اساسی باشد که FasterRCNN با صحنههای همگون دارد.
- حتی وقتی در کادرهای محصورکننده فردی وجود نداشت و یا همه مفاصل مشهود نبودند، 17 نقطه کلیدی در آنها تشخیص داده میشد. HRNet به نحوی ساخته شده که هر 17 مفصل باید پیشبینی شوند، حتی اگر دیده نمیشوند.

- به اینکه در ابتدای ویدئو، حتی با وجود تخریب در تصویر، تخمین حالت خوبی صورت میگیرد ارزش چندانی داده نمیشود. توانایی کار کردن با وجود اطلاعاتی که به خاطر تخریب در تصویر از دست رفتهاند، مسئله مهمی است که HRNet به خوبی از پس آن بر میآید.
- این مسئله نیز حائز اهمیت است که (همانطور که در تصویر مشخص شده) آن شاخهای که کوتوله در دست گرفته به عنوان یکی از پاها در نظر گرفته نشده است و این خود یک نقطه قوت به شمار میرود.
سوالات رایج در مورد کدنویسی
1. جستجوی حالت در RGB صورت گرفته (https://github.com/leoxiaobin/deep-high-resolution-net.pytorch/issues/41) در حالیکه شبکهای که برای تشخیص فرد آموزش داده شده در BGR انجام گرفته است (https://github.com/leoxiaobin/deep-high-resolution-net.pytorch/issues/15).
2. کار با pycocotoolهای رابط برنامه کاربردی دیتاست COCO با پایتون 3 امکانپذیر نیست (https://github.com/cocodataset/cocoapi/issues/49). HRNet اغلب جواب میدهد اما اگر pycocotool ها را هم درگیر کنید ممکن است اینطور نماند.
3. باید از numpy 1.17 استفاده شود (https://github.com/leoxiaobin/deep-high-resolution-net.pytorch/issues/177)
4. چطور از دادههای دیتاست خود برای آموزش شبکه استفاده کنید (https://github.com/leoxiaobin/deep-high-resolution-net.pytorch/issues/68).
5. در فرآیند استنتاج برای افزایش سرعت عملکرد و کاهش استفاده از mem ، استفاده از model.no_grad را هم در نظر داشته باشید (من این روش را امتحان نکردهام).
6. به نظر میرسد سومین پارامتر مفصل همیشه صفر میشود و برای شیء joints_3d_vis دو پارامتر اول همیشه فلگ تغییرپذیری یکسانی دارند، در حالیکه سومین پارامتر همیشه صفر است؛ برگرفته از from coco.py ->_load_coco_keypoint_annotation_kernal() . در JoinsDataset->getitem()->affine_transform، به منظور آمادگی برای تغییر affine در JoinsDataset -> getitem() -> affine_transform، مفاصل سایز 3 هستند، اما سومین پارامتر هیچگاه استفاده نمیشود (شاید وراثتی باشد و شاید برای استفادههای بعدی در HigherHRNet در محل قرار گرفته است). به نظر میرسد همین مسئله برای دیتاهای دیتاست MPII هم رخ میدهد.
7. در طول اعتباریابی/آزمون از مفاصل حاشیهای استفاده نمیشود (حتی اگر در خط پایه … ذخیره شده باشند) و در نتیجه نتایج صحتیابی/ اعتباریابی که طی اجرای آزمایشی چاپ شدهاند صحیح نخواهند بود. تمامی خط پایه محاسبه صحت و اعتبار که در اجرای آزمایشی به دست میآید دیگر مفید نخواهند بود. در انتهای اجرا (ران گرفتن) از coco api به منظور محاسبه اندازههای درست اعتبار استفاده میشوند.
8. استنتاج با 384×288 تنظیم می¬شود (در حالیکه readme میگوید از 256×192 استفاده کنید).
تصویر و تبدیل مفاصل
- دمو/ استنتاج — box_to_center_scale() تصویر را بر اساس کادرها اندازهگیری میکند، اما اینکه pixel_std=200 چه کاری انجام میدهد معلوم نیست. چندین مسئله در این مورد وجود دارد:
https://github.com/microsoft/human-pose-estimation.pytorch/issues/26
https://github.com/leoxiaobin/deep-high-resolution-net.pytorch/issues/23
https://github.com/leoxiaobin/deep-high-resolution-net.pytorch/issues/9
https://github.com/microsoft/human-pose-estimation.pytorch/issues/94 - مرکز و مقیاس مطابق با موقعیت کادرهای حاشیه نویسی شده تشخیص داده شده درون تصویر اصلی میباشند. مرکز، مرکز کادر را در تصویر اصلی نشان میأدهد و مقیاس هم اندازه نسبی کادر به تصویر اصلی است — from coco.py->_load_coco_person_detection_results().. وقتی مقیاس را اندازهگیری میکنیم، نسبت جنبهها و هنجارسازی بر اساس pixel_std از قبل تنظیم شده و مقیاس 1.25 انجام میگیرد.
- استنتاج -> get_pose_estimation_prediction coordهای تصویر اصلی را باز میگرداند (هیچ چرخشی وجود ندارد، فقط مرکز و مقیاس هر کادر محصورکننده وجود دارند).
- JointsDataset->getitem->get_affine_transform تبدیلی را به وجود میآورد که اندازه تصویر اصلی را متناسب با اینکه از کادر محصورکننده چقدر بزرگتر است، افزایش داده و سپس تصویر را در مرکز این کادر قرار میدهد.
- سپس warpAffine تصویر اصلی را تغییر میدهد تا هم در مرکز باشد و هم در اندازهای که مشخص شده است؛ در نتیجه ما باید محیط کادر را در تصویر خروجی ببینیم. نقطه 0,0 (مرکز) تصویر خروجی کراپ شده با آن نقطهای روی تصویر اصلی منطبق میشود که بعد از تغییر (تبدیل) روی 0,0 قرار میگیرد، سپس کراپینگ دیگر به سمت راست و پایین حرکت نمیکند.
- در طول آموزش، اندازهگیری چرخش و رده چرخشی برای تغییر affine رندوم میباشد. JointsDataset → __getitem__()
- آبجکت¬هایی که در JointsDataset به صورت self.db هستند بر اساس منبع تغییر می¬کنند. Self.db در خط 246م از رده جمع¬آوری شده است. COCODataset -> _load_coco_person_detection_results().
- محاسبه¬ی تغییر به این صورت است: x_new(of x_old),y_new(of y_old),z = T*(x_old,y_old,1). برای مشاهده¬ی یک مثال میتوانید به این لینک مراجعه کنید:
- موقعیت مفاصل بعد از تغییرممکن است منفی باشد. زیرا با همان ماتریکس تغییر تصویر منتقل میشوند و از آنجایی که تغییر به سمت مرکز و بزرگنمایی مقیاس مطابق با کادر است، برخی از مفاصل ممکن است خارج از کادر قرار بگیرند.
- حاشیهنویسیهایی که برای مرکز و مقیاس در MPII انجام شده کاملاً واضح نیستند. https://github.com/leoxiaobin/deep-high-resolution-net.pytorch/issues/51



















