
کتابخانه Pandas در پایتون: چگونه دیتاستهای بزرگ را بارگذاری کنیم
 تیم تحریریه
تیم تحریریه- ۱۶ آبان ۱۴۰۰
کتابخانه Pandas در پایتون یکی از ارکان حیاتی علوم داده به شمار میآید. یکی از انتقاداتی که به این کتابخانه وارد میشود این است که نمیتواند دیتاستهای بزرگتر از حافظه را تحلیل کند و به همین دلیل در هنگام تحلیل و کار کردن با کلان داده به مشکل میخورد. تصور کنید میخواهیم یک دیتاست بزرگ را تنها با استفاده از کتابخانه Pandas در پایتون تحلیل کنیم. در این حالت ممکن است با چه چالشهایی مواجه شویم؟ برای مثال، فرض کنید فایلی شامل 3 گیگابایت داده در اختیار داریم؛ این دادهها چکیدهای از اطلاعات مربوط به سفرهایی است که در ماه مارس سال 2016 با تاکسیهای شهری (زرد) انجام شده است. برای اینکه بتوانیم این دیتاست را تحلیل کنیم، باید ابتدا آن را در حافظه بارگذاری کنیم. برای خواندن این دیتاست، از تابع ()read_csv متعلق به کتابخانه Pandas در پایتون استفاده میکنیم:
import کتابخانه Pandas در پایتون as pd
df = pd.read_csv('yellow_tripdata_2016-03.csv')
زمانی که سلول/ فایل را اجرا میکنم، سیستم Memory Error (خطای حافظه) را نشان میدهد ( خطای حافظه بستگی به ظرفیت سیستمی دارد که از آن استفاده میکنید).

آیا میتوان از کتابخانههای دیگر استفاده کرد؟
نکتهای که باید به آن توجه داشته باشید این است که کتابخانه Pandas در پایتون ابزار مناسبی برای انجام و اجرای تمامی مسائل نیست. کتابخانه Pandas در پایتون از پردازش چندگانه Multiprocessing پشتیبانی نمیکند و کتابخانههای دیگر در هنگام کار با کلاندادهها عملکرد بهتری دارند. یکی از این کتابخانهها Dask نام دارد؛ این کتابخانه API مشابه کتابخانه Pandas در پایتون دارد که میتواند با دیتاستهایی بزرگتر از حافظه کار کند. حتی در سند کتابخانه Pandas در پایتون نیز صریحاً به عدم توانایی این کتابخانه در تحلیل کلاندادهها اشاره شده است:
بهتر است در چنین مواقعی از کتابخانه Pandas استفاده نشود. Pandas ابزار مناسبی برای انجام و اجرای تمامی مسائل نیست.
در این نوشتار به معرفی روش تقسیمبندی Chunking خواهیم پرداخت؛ با استفاده از این روش میتوانید دیتاستهای موجود در حافظه را در کتابخانه Pandas در پایتون بارگذاری کنید. برخی اوقات این روش در کتابخانه Pandas در پایتون میتواند راهکاری مناسب برای مدیریت و حل مشکلات خارج از حیطه حافظه پیش روی ما بگذارد، اما همیشه هم کارایی لازم را ندارد و در ادامه این نوشتار به آن خواهیم پرداخت. در این نوشتار به بررسی دو روش بارگذاری دیتاستهای بزرگ در پایتون خواهیم پرداخت:
- استفاده از ()read_csv به همراه پارامتر اندازه بخش Chunksize
- استفاده از SQL و کتابخانه Pandas در پایتون
تقسیمبندی: تقسیم کردن دیتاستها به بخشهای کوچکتر
پیش از ذکر هرگونه مثالی در این زمینه، مفهوم تقسیمبندی را توضیح خواهیم داد.
تقسیمبندی به استراتراتژیهایی گفته میشود که با استفاده از دانش و تخصص موقعیتی خاص درخواستهای مرتبط با تخصصی حافظه را جمعآوری میکنند و بدین وسیله با ارتقای عملکرد کمک میکنند.
به بیانی دیگر، به جای اینکه تمامی دادهها را به صورت همزمان در حافظه بخوانیم، میتوانیم آنها را به قسمتها و بخشهای کوچکتر تقسیم کنیم. در مواردی هم که دادهها در فایلهای CSV قرار دارند، در زمانی مشخص چندین خط از دادهها را در حافظه بارگذاری میکنیم.
تابع ()read_csv متعلق به کتابخانه Pandas در پایتون یک پارامتر اندازه بخش دارد که اندازه قسمتها/بخشها را کنترل میکند. برای اینکه نحوه عملکرد این تابع را با یکدیگر بررسی کنیم، از دیتاستی که در ابتدای این نوشتار به آن اشاره شد، استفاده میکنیم، اما به جای اینکه این دیتاست را به طور کامل بارگذاری کنیم، آن را به بخشهای کوچکتر تقسیمبندی میکنیم و سپس آن را بارگذاری میکنیم.
استفاده از تابع ()read_csv به همراه اندازه بخش
برای آنکه بتوانیم دیتاست را تقسیم بندی کنیم، ابتدا باید اندازه بخشها/ قسمتها را مشخص کنیم. استفاده از تایع به همراه پارمتر اندازه بخش، یک شیء به عنوان خروجی به ما میدهد که میتوانیم چندین بار آن را تکرار کنیم.
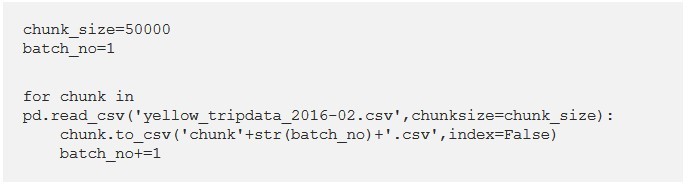
سپس عدد 50.0000 را به عنوان سایز بخش انتخاب میکنیم، به این معنا که هر بار، فقط 50.000 ردیف از دادهها بارگذاری خواهد شد.
بارگذاری فایل تک بخشی به عنوان دیتافریم کتابخانه Pandas در پایتون
حالا چندین بخش داریم و میتوانیم هر بخش را به عنوان یک دیتافریم کتابخانه Pandas در پایتون بارگذاری کنیم.
df1 = pd.read_csv('chunk1.csv')
df1.head()
df1 = pd.read_csv('chunk1.csv')
df1.head()
VendorID tpep_pickup_datetime tpep_dropoff_datetime passenger_count trip_distance pickup_longitude
pickup_latitude RatecodeID store_and_fwd_flag dropoff_longitude dropoff_latitude payment_type
fare_amount extra mta_tax tip_amount tolls_amount improvement_surcharge total_amount
0 2 2016-02-25 17:24:20 2016-02-25 17:27:20 2 0.70 -73.947250 40.763771 1 N -73.992012 40.735390 2 5.0 0.0 0.5 0.0 0.0 0.3 5.8
1 2 2016-02-25 23:10:50 2016-02-25 23:31:50 2 5.52 -73.983017 40.750992 1 N -73.988586 40.758839 2 20.0 0.5 0.5 0.0 0.0 0.3 21.3
2 2 2016-02-01 00:00:01 2016-02-01 00:10:52 6 1.99 -73.992340 40.758202 1 N -73.964355 40.757977 1 9.5 0.5 0.5 0.7 0.0 0.3 11.5
3 1 2016-02-01 00:00:04 2016-02-01 00:05:16 1 1.50 -73.981453 40.749722 1 N -73.982323 40.763985 2 6.5 0.5 0.5 0.0 0.0 0.3 7.8
4 2 2016-02-01 00:00:05 2016-02-01 00:20:59 1 5.60 -74.000603 40.729755 1 N -73.951324 40.669834 1 20.0 0.5 0.5 4.0 0.0 0.3 25.3
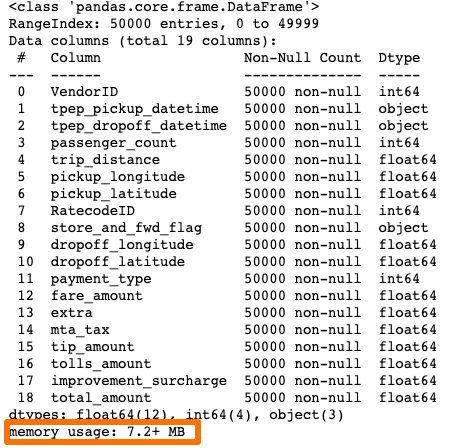
نتیجه عالی است! سیستم خطای حافظه را نشان نمیدهد. حالا میخواهیم ببینیم این بخش چه مقدار از حافظه را اشغال کرده است:
()df1.info
- هشدار
تقسیمبندی دیتاست منجر به شکلگیری چندین بخش کوچکتر از دادهها میشود. به همین دلیل، در عملیاتهایی که هماهنگی میان بخشها اهمیت چندانی ندارد، این روش میتواند عملکرد فوقالعادهای داشته باشد. توجه به این نکته ضروری و لازم است. یکی دیگر از نقاط ضعف استفاده از روش تقسیمبندی این است که برای برخی عملیاتها همچون groupby استفاده از بخشها دشوارتر است. در چنین مواقعی بهتر است از کتابخانههای دیگر استفاده کنید.
استفاده از SQL و Pandas برای خواندن فایلهای داده بزرگ

یکی دیگر از روشهایی که میتوانیم به کار ببندیم این است که با استفاده از بخشها یک دیتابیس SQLite بسازیم و سپس دادههای مورد نیاز را با استفاده از پرسمانهای SQL استخراج کنیم. SQLite سیستم مدیریت دیتابیس مبتنی بر زبان SQL است که برای محیطهای کوچکتر طراحی و بهینهسازی شده است. این سیستم را میتوان با استفاده از یکی از ماژولهای پایتون به نام sqlite3 در پایتون وارد کرد.
[irp posts=”3144″]SQLAlchemy جعبهابزار SQL پایتون است و توسعهدهندگان نرمافزارهای کاربردی میتوانند با استفاده از تکنیک Object Relational Mapper از تمامی توان و انعطافپذیری SQL استفاده کنند. از این جعبهابزار برای ساخت موتوری استفاده میشود که با استفاده از دادههای اصلی یک دیتابیس ایجاد میکند. در پروژه پیشرو، این دیتابیس، یک فایل CSV بزرگ است.
برای انجام پروژه حاضر، باید مراحل زیر را دنبال کنیم:
بارگذاری کتابخانههای مورد نیاز
import sqlite3 from sqlalchemy import create_engine
ایجاد رابطی به دیتابیس
دیتابس را نامگذاری میکنیم:
csv_database = create_engine('sqlite:///csv_database.db')
در اینجا، دیتابیس را با هدف ایجاد csv_database نامگذاری میکنیم.
ایجاد یک دیتابیس از فایل CSV با استفاده از روش تقسیمبندی
مشابه این فرایند را در ابتدای این نوشتار نیز انجام دادیم. حلقه دیتاستها را که به بخشهای کوچکتر تقسیم شدهاند و به وسیله پارامتر اندازه بخش مشخصشدهاند را میخواند.
chunk_size=50000
batch_no=1
for chunk in pd.read_csv('yellow_tripdata_2016-02.csv',chunksize=chunk_size,iterator=True):
chunk.to_sql('chunk_sql',csv_database, if_exists='append')
batch_no+=1
print('index: {}'.format(batch_no))
به دلیل اینکه دادهها را در دیتابیس csv_database مینویسیم، از تابع chunk.to_sql instead of chunk.to_csv استفاده میکنیم. علاوه بر این، chunk_sql نامی است که به دلخواه برای بخش انتخاب شده است.
ساخت دیتافریم کتابخانه Pandas در پایتون با query ارسال شده به دیتابیس SQL
دیتابیس ایجاد شده است. اکنون میتوانیم دیتابیس را پرسوجو کنیم و ستونهای مورد نیاز را استخراج کنیم؛ برای مثال، میتوانیم ردیفهایی که تعداد مسافران (passenger count) آنها کمتر از 5 و مسافت سفر آنها بیشتر از 10 است را استخراج کنیم. Pandas .read_sql_query ، query ارسال شده به SQL را در قالب یک دیتافریم میخواند.
df_new = pd.read_sql_query('SELECT * FROM chunk_sql WHERE passenger_count <5 AND trip_distance > 10',csv_database)
df_new.head()
index VendorID tpep_pickup_datetime tpep_dropoff_datetime passenger_count trip_distance pickup_longitude pickup_latitude RatecodeID store_and_fwd_flag dropoff_longitude dropoff_latitude payment_type fare_amount extra mta_tax tip_amount tolls_amount improvement_surcharge total_amount
0 18 2 2016-02-01 00:00:38 2016-02-01 00:18:27 1 10.67 -73.875008 40.773972 1 N -73.975113 40.758751 2 29.5 0.5 0.5 0.00 5.54 0.3 36.34
1 40 2 2016-02-01 00:02:08 2016-02-01 00:21:39 2 10.70 -73.788902 40.646389 1 N -73.709320 40.725712 1 30.0 0.5 0.5 9.39 0.00 0.3 40.69
2 50 2 2016-02-01 00:03:40 2016-02-01 00:33:11 1 18.81 -73.777023 40.645000 2 N -73.988579 40.725780 1 52.0 0.0 0.5 11.67 5.54 0.3 70.01
3 56 2 2016-02-01 00:21:01 2016-02-01 00:21:01 1 16.40 -73.791527 40.645340 2 N -73.969627 40.753689 2 52.0 0.0 0.5 0.00 5.54 0.3 58.34
4 71 1 2016-02-01 00:00:11 2016-02-01 00:35:10 1 10.40 -74.000549 40.729809 1 N -73.939407 40.826813 1 33.5 0.5 0.5 5.00 0.00 0.3 39.80
حالا دیتافریمی داریم که به خوبی در حافظه جای میگیرد و برای تحلیلهای آتی میتوان از آن استفاده کرد.
نتیجهگیری
کتابخانه Pandas در پایتون کتابخانهای سریع و سودمند برای تحلیل دادهها است. با این وجود ابزار مناسبی برای کار کردن و تحلیل کلاندادهها نیست. در این نوشتار نشان دادیم تقسیمبندی و SQL چگونه میتوانند در تحلیل دیتاستهای بزرگتر از حافظه سیستم به کمک ما بیایند. اما باید توجه داشته باشید که این روشهای همیشه مؤثر و کارآمد نیستند و بهتر است از کتابخانههایی استفاده کنید که با هدف کار کردن و تحلیل کلاندادهها ایجاد شدهاند.



















