

آموزش توزیع شده مدل های یادگیری عمیق با پای تورچ
 تیم تحریریه
تیم تحریریه- ۶ مرداد ۱۴۰۰
هدف از نگارش مقاله پیشرو مطالعه و بررسی نحوه استفاده از رایانش توزیع شده Distributed Computing در آموزش مدل های مقیاس بزرگ یادگیری عمیق با پای تورچ است. در ابتدا تعریفی از مفاهیم پایه رایانش توزیعشده ارائه میدهیم و سپس نحوه استفاده از آن در حوزه یادگیری عمیق را توضیح میدهیم. در بخش دیگری از این مقاله فهرستی از حداقلهای استاندارد (سختافزاری و نرمافزاری) ارائه میدهیم که برای ایجاد محیطی با قابلیت مدیریت برنامههای توزیعشده به آنها نیاز داریم. و در آخر مباحث نظری و همچنین شیوه پیادهسازی و اجرای یک الگوریتم توزیعشده منحصر بفرد ( موسوم به گرادیان کاهش نزولی همزمانی Asynchronous Stochastic Gradient descent) را توضیح میدهیم که میتوان از آن در آموزش مدلهای یادگیری عمیق استفاده کرد.
منظور از رایانش توزیعشده چیست؟
رایانش توزیعشده به فرایند نوشتن یک برنامه کامپیوتری گفته میشود که اجزای آن در شبکه با یکدیگر در ارتباط هستند. به طور معمول با استفاده از کامپیوترهایی که به صورت موازی قادر به انجام محاسبات عددی با حجم بالا هستند میتوان محاسبات مقیاس بزرگ را انجام داد. در حوزه رایانش توزیعشده معمولاً به این کامپیوترها گره Node گفته میشود و مجموعهای از این کامپیوترها در شبکه یک خوشه Cluster را تشکیل میدهند. این گرهها اغلب به وسیله Ethernet به یکدیگر متصل میشوند اما از سایر شبکهها با پهنای باند زیاد نیز استفاده میشود تا از مزایای معماری توزیعشده بهرهمند شوند.
یادگیری عمیق با پای تورچ و رایانش توزیعشده
هرچند شبکههای عصبی که اصلیترین مؤلفه در یادگیری عمیق هستند از مدتها پیش در این حوزه مورد استفاده قرار میگرفتند اما تا چندی پیش کسی نمیتوانست به صورت کامل از مزایای آنها بهرهمند شود. یکی از دلایلی که موجب افزایش ناگهانی محبوبیت شبکههای عصبی شد توان محاسباتی بالای این شبکهها بود که در این مقاله قصد داریم به آن بپردازیم. در حوزه یادگیری عمیق شبکههای عصبی عمیق Deep Neural Network باید با حجم بالایی از دادهها که پارامترهای بیشماری دارند، آموزش داده شوند. رایانش توزیعشده ابزاری مناسب برای بهرهمندی کامل از مزایای این شبکهها است. ایده اصلی مقاله آموزش توزیع شده مدل های یادگیری عمیق با پای تورچ این است:
الگوریتم توزیعشدهای که به درستی طراحی شده باشد میتواند:
- به منظور پردازش منسجم، رایانش (فرایند جلوگذر Forward Pass و فرایند عقبگذر Backward Pass
مدل یادگیری عمیق) و همچنین دادهها را در چندین گره «توزیع کند». - به منظور حفظ انسجام، میان گرهها «همگاهی Synchronization» ایجاد کند.
رابط انتقال پیام: سیستم استاندارد رایانش توزیعشده
یکی دیگر از اصطلاحاتی که باید با آشنا شوید زابط انتقال پیام Message Passing Interface است. MPI تقریباً در تمامی محاسبات توزیعشده کاربرد دارد. MPI یک استاندارد باز است و مجموع قوانینی تعریف میکند که مشخص میکنند گرهها چگونه باید در شبکه با یکدیگر ارتباط داشته باشند. علاوه بر این MPI یک مدل/ API برنامهنویسی است. MPI یک ابزار یا نرمافزار نیست، MPI یک ویژگی و خصوصیت است. در تابستان سال 1991 گروهی از افراد و سازمانها گرد هم آمدند و MPI Forum را راهاندازی کردند. به اتفاق آرا MPI Forum یک دستورالعمل معنایی و نحوی Syntactic and semantic specification برای کتابخانه طراحی کرد که ارائهدهندگان سختافزارها میتوانند از آن به عنوان یک راهنما استفاده کنند و بر مبنای آن پیادهسازیهای قابلحمل/ انعطافپذیر/ بهینه portable/ flexible/optimized implementations داشته باشند. چندین شرکت ارائهدهنده سخت افزاری پیادهسازی MPI مخصوص به خود را دارند، برای نمونه میتوان به OpenMPI، MPICH، MVAPICH، Intel MPI و غیره اشاره کرد.
با توجه به اینکه Intel MPI کاربردیتر است و برای پلتفرمهای Intel بهینهسازی شده در این مقاله آموزشی از این پیادهسازی MPI استفاده میکنیم. Intel MPI اصلی یک کتابخانه C و سطح پایین است.
راهاندازی
راهاندازی صحیح یک سیستم اهمیت زیادی دارد. حتی اگر فردی شناخت کافی نسبت به مدل برنامهنویسی سیستم داشته باشد اما تنظیمات سختافزاری و شبکهای مناسب صورت نگیرد، سیستم کارایی لازم را نخواهد داشت. تنظیمات اساسی که باید بر روی سیستم صورت بگیرد به شرح زیر است:
- ابتدا به مجموعهای از گرهها که در شبکه با یکدیگر در ارتباط هستند و یک خوشه را تشکیل میدهند نیاز داریم. بهتر است از سرورهای پیشرفته High-end server به عنوان گره و شبکههایی با پهنای باند زیاد همچون InfiniBand استفاده شود.
- بر روی تمامی گرههای خوشه به سیستمهای لینوکس با حسابهای کاربری دقیقا به همان نام نیاز است.
- سطح اتصال گرههای شبکه باید دسترسی SSH بدون رمز password-less SSH باشد.
- یک پیادهسازی MPI باید نصب شود. در این مقاله آموزشی فقط از Intel MPI استفاده میشود.
- به یک مدیریت فایل Filesystem نیاز داریم که از تمامی گرهها قابل مشاهده باشد و برنامههای توزیعشده در آن قرار بگیرند. برای مثال میتوانید از سیستم سیستم پرونده شبکه ای Network FileSystem استفاده کنید.
انواع استراتژیهای موازیسازی
به دو روش میتوان مدلهای یادگیری عمیق را موازیسازی کرد:
- موازیسازی مدل Model Parallelism
- موازیسازی داده Data Parallelism
موازیسازی مدل
منظور از موازیسازی مدل این است که یک مدل به چندین بخش تقسیم شود ( برای مثال تعدادی از لایهها در یک بخش و لایههای دیگر در بخش دیگر قرار بگیرند)، سپس آنها را در سختافزارها و دستگاههای متفاوت قرار دهیم. اگرچه قرار دادن هر بخش در دستگاهی متفاوت، باعث بهبود زمان اجرا Execution time می شود، اما بیشتر به منظور رفع مشکل محدودیت فضای حافظه Memory constraints از آن استفاده می شود. استراتژی موازیسازی مدل مناسب مدلهایی است که پارامترهای بیشماری دارند و به دلیل اینکه فضای زیادی از حافظه را اشغال میکنند اجرای آنها در یک سیستم دشوار است.
[irp posts=”7552″]موازیسازی داده
موازیسازی داده به فرایند پردازش قسمت هایی از داده ( به لحاظ فنی همان بستهها) بر روی همتاهایی از همان شبکهای گفته میشود که در سختافزارها یا دستگاههای مختلف قرار گرفته است. برخلاف روش موازیسازی مدل، در این روش ممکن است هر نمونه یک شبکه کامل ، نه فقط بخشی از آن، باشد. مقیاس استراتژی موازیسازی داده میتواند همزمان با افزایش دادهها، افزایش یابد. اما از آنجاییکه در موازیسازی داده کل شبکه باید بر روی یک دستگاه قرار بگیرد، این استراتژی مناسب مدلهایی که فضای زیادی از حافظه را اشغال میکنند نیست. در تصویر مقابل تفاوت میان این دو استراتژی نشان داده شده است.

موازیسازی داده نسبت به موازیسازی مدل محبوبیت بیشتری دارد و سازمانهای بزرگ اغلب جهت اطمینان از صحت الگوریتمهای آموزشی یادگیری عمیق با پای تورچ از آن استفاده میکنند. از این روی در این مقاله آموزشی از استراتژی موازیسازی داده استفاده میکنیم.
رابط برنامهنویسی کاربردی “torch.distributed”
پای تورچ یک رابط برنامهنویسی کاربردی عرضه کرده که به زبان C نوشته شده و استفاده از آن آسان است و رابطی برای کتابخانه MPI است. پای تورچ باید از منبع compile شود و به Intel MPI که بر روی سیستم نصب شده متصل و همگام شود. در ادامه کاربرد پایه torch.distributed و شیوه اجرای آن را بررسی میکنیم.
# filename 'ptdist.py'
import torch
import torch.distributed as dist
def main(rank, world):
if rank == 0:
x = torch.tensor([1., -1.]) # Tensor of interest
dist.send(x, dst=1)
print('Rank-0 has sent the following tensor to Rank-1')
print(x)
else:
z = torch.tensor([0., 0.]) # A holder for recieving the tensor
dist.recv(z, src=0)
print('Rank-1 has recieved the following tensor from Rank-0')
print(z)
if __name__ == '__main__':
dist.init_process_group(backend='mpi')
main(dist.get_rank(), dist.get_world_size())
ارتباطات همتا به همتا
در صورتیکه کد بالا را با استفاده از mpiexec، که یک زمانبند توزیعشده فرایند است و در تمامی پیادهسازیهای استاندارد MPI وجود دارد، اجرا کنید به نتیجه مقابل دست خواهید یافت:
cluster@miriad2a:~/nfs$ mpiexec -n 2 -ppn 1 -hosts miriad2a,miriad2b python ptdist.py Rank-0 has sent the following tensor to Rank-1 tensor([ 1., -1.]) Rank-1 has recieved the following tensor from Rank-0 tensor([ 1., -1.])
1- اولین خطی که باید اجرا شود dist.init_process_group (backend) است که کانال ارتباطات داخلی را میان گرهها راهاندازی میکند. تصمیمگیری راجع به اینکه از کدام backend باید استفاده کرد، دشوار است. به دلیل اینکه در این مقاله از MPI استفاده میکنیم، از backend=’mpi’ استفاده میکنیم. Backendهای دیگر از جمله TCP، Gloo و NCCL نیز وجود دارد.
2- دو پارامتر world size و شناسه پردازش را باید بازیابی کرد. world به مجموع تمامی گرههایی گفته میشود که در بافت خاصی از احضار mpiexec مشخص شده است ( به نشانه –hosts در mpiexec مراجعه کنید).
پارامتر شناسه پردازش یک عدد صحیحمنحصر بفرد است که توسط Runtime MPI به هریک از فرایندها اعمال میشود. شناسه پردازش از 0 شروع میشود. از ترتیبی که شناسه پردازشها در پارامتر –hosts مشخص شدهاند برای اعمال اعداد استفاده میشود. از این روی در این مورد فرایند گره “miriad2a” به Rank 0 و “miriad2b” به Rank 1 اعمال میشود.
3 – x آرایه چند بعدی Tensor است که Rank 0 تصمیم دارد به Rank 1 ارسال کند. x این کار را از طریق dist.send (x, dst=1) انجام میدهد.
4- z چیزی است که Rank 1 پیش از دریافت آرایه چند بعدی ایجاد کرده است. در این حالت به آرایه چند بعدی که از قبل با شکل یکسان ایجاد شده نیاز داریم که آرایه چند بعدی آتی را دریافت کند. در نهایت مقادیر z جایگزین مقدار x میشوند.
5 – یک دریافتکنند دیگر مشابه dis.send ( . . )، به نام dist.recv (z, src=0) وجود دارد که آرایه چند بعدی z را دریافت میکند.
ارتباطات جمعی Communication collectives
چیزی که در بخش قبل مشاهده کردیم ارتباط همتا به همتا Peer-to-Peer communication نامیده میشود که در آن شناسه پردازش (ها) دادهها را در یک بافت مشخص به شناسه پردازش (ها) خاصی ارسال میکنند. یکی از مزیتهای ارتباط همتا به همتا برای کاربران این است که امکان کنترل granular را بر روی ارتباطات فراهم میکند. علاوه بر ارتباط همتا به همتا، الگوی ارتباطی دیگری موسوم به تجمعی وجود دارد. در ادامه تعریفی از یک تجمع خاص (موسوم به all-reduce) ارائه شده است که در مبحث الگوریتم گرادیان کاهش نزولی همزمانی مورد توجه ما قرار گرفته است.
تجمع “All-reduce”
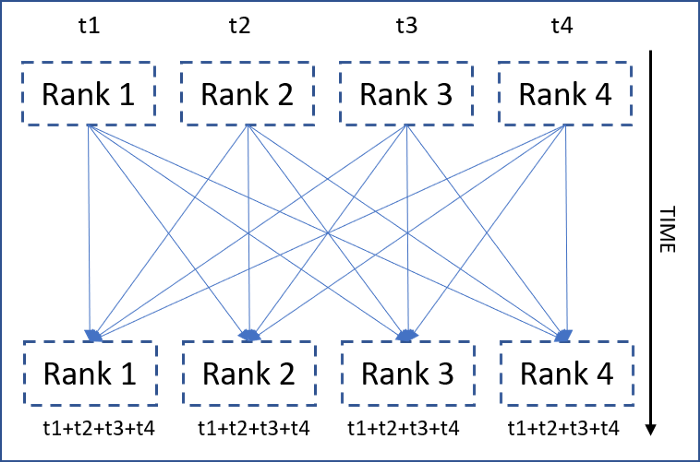
All-reduce روشی برای ارتباطات همگاهی است که در آن یک عملیات کاهشی Map reduce operation بر روی تمامی شناسه پردازشها اجرا میشود و نتیجه کاهش یافته (فیلترشده) در دسترسی تمامی آنها قرار میگیرد. تصویر مقابل نشاندهنده تجمع all-reduce است ( از جمع Summation به عنوان عملیات کاهشی استفاده شده)
1 def main(rank, world):
2 if rank == 0:
3 x = torch.tensor([1.])
4 elif rank == 1:
5 x = torch.tensor([2.])
6 elif rank == 2:
7 x = torch.tensor([-3.])
8
9 dist.all_reduce(x, op=dist.reduce_op.SUM)
10 print('Rank {} has {}'.format(rank, x))
11
12 if __name__ == '__main__':
13 dist.init_process_group(backend='mpi')
14 main(dist.get_rank(), dist.get_world_size())
کاربرد پایه تجمع all-reduce در پای تورچ
نتیجه اجرا در world of 3 به شرح زیر است:
cluster@miriad2a:~/nfs$ mpiexec -n 3 -ppn 1 -hosts miriad2a,miriad2b,miriad2c python ptdist.py Rank 1 has tensor([0.]) Rank 0 has tensor([0.]) Rank 2 has tensor([0.])
1 – if rank == <some rank> … elif الگویی است که در رایانش توزیعشده بارها و بارها با آن مواجه میشویم. در این مقاله، از آن برای ایجاد تنسورهای مختلف بر روی شناسه پردازشهای مختلف استفاده میشود.
2 – تمامی آنها all-reduce را ( همانگونه که مشاهده میکنید dist.all_reduce ( . . ) خارج از بلوک if … elif قرار دارد) به همراه جمع ( dist.reduce_op.SUM) به عنوان عملیات کاهشی اجرا میکنند.
3 – x تمامی شناسه پردازشها جمع بسته میشود و مجموع آن در x تک تک شناسه پردازشها جایگزین میشود.
[irp posts=”22941″]پیش به سوی یادگیری عمیق با پای تورچ
فرض ما بر این است که خوانندگان مقاله آموزش توزیع شده مدل های یادگیری عمیق با پای تورچ با الگوریتم استاندارد گرادیان کاهش نزولی Standard Stochastic Gradient Descent (SGD) algorithm که اغلب از آن برای آموزش مدلهای یادگیری عمیق استفاده میشود، آشنایی دارند. در این مقاله به معرفی نوع دیگری از این الگوریتم (موسوم به گرادیان کاهش نزولی همزمانی) میپردازیم که برای مقیاسگذاری عمودی Scale up از تجمع All-reduce استفاده میکند. فرمول ریاضی الگوریتم SDG عبارت است از:

چنانچه D را مجموعهای از (بسته کوچکی Mini-batch) از نمونهها در نظر بگیریم، θ مجموعهای از تمامی پارامترها است، λ نرخ یادگیری است و Loss (X, y) میانگین تابع زیان Mini-batch تمامی نمونههای D است.
الگوریتم SGD همگام مجموع را بر حسب قانون بهروز رسانی به زیر مجموعههای کوچکتر (مینی) بسته تقسیم میکند. D به R تعداد از زیرمجموعههای D1 و D2 تقسیم میشود (ترجیحاً تعداد نمونههای هر کدام یکسان است)، مشابه معادل مقابل:

در نتیجه تقسیم مجموع SDG استاندارد به معادله مقابل دست پیدا میکنیم:

حالا عملگر گرادیان Gradient Operator بر عملگر جمع Summation Operator توزیع میشود و به معادله روبهرو دست پیدا میکنیم:

حاصل این بحث چیست؟
به جملات مرتبط با گرادیان (اصطلاحات درون کروشه) در معادله فوق نگاه کنید. هر کدام از آنها را میتوان به صورت جداگانه محاسبه کرد و سپس آنها را با هم جمع کرد و بدون هیچگونه زیان Loss/ تقریب Approximation گرادیان اصلی را به دست آورد.
در این حالت است که موازیسازی داده به کمک ما میآید. برای انجام این کار باید:
1- کل دیتاست را به R قسمت مساوی تقسیم کنید. از حرف R برای اشاره به Replica (کپی) استفاده میشود.
2 – با استفاده از MPI فرایندها/ شناسه های پردازش R را آغاز کنید و هر فرایند را به یک قسمت از دیتاست مرتبط کنید.
3 – اجازه دهید هر شناسه پردازش با استفاده از یک بسته کوچک (dr) با اندازه B از دادههای متعلق به خود، گرادیان را محاسبه کند، به عبارت دیگر شناسه پردازش r گرادیان مقابل را محاسبه میکند:

4 – گرادیان تمامی شناسه پردازشها را با هم جمع کنید و گرادیان به دست آمده را به تمامی شناسه پردازشها تخصیص میدهیم.
آخرین نقطه الگوریتم all-reduce است. در این حالت، هر بار که تمامی شناسه های پردازش یک گرادیان را (بر روی یک بسته کوچک با اندازه B) بر روی بخش دادههای متعلق به خود محاسبه کردند، all-reduce باید اجرا شود. نکته جالبی که باید به آن توجه داشته باشید این است که با جمع کردن گرادیانهای (بر بستههای کوچک با اندازه B) تمامی شناسه پردازشهای R به اندازه بسته مقابل دست پیدا میکنید:
![]()
کدهای مقابل بخش حیاتی و مهم فرایند پیادهسازی هستند ( کدهای boilerplate نشان داده نشده است)
model = LeNet()
# first synchronization of initial weights
sync_initial_weights(model, rank, world_size)
optimizer = optim.SGD(model.parameters(), lr=1e-3, momentum=0.85)
model.train()
for epoch in range(1, epochs + 1):
for data, target in train_loader:
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
# The all-reduce on gradients
sync_gradients(model, rank, world_size)
optimizer.step()
def sync_initial_weights(model, rank, world_size):
for param in model.parameters():
if rank == 0:
# Rank 0 is sending it's own weight
# to all it's siblings (1 to world_size)
for sibling in range(1, world_size):
dist.send(param.data, dst=sibling)
else:
# Siblings must recieve the parameters
dist.recv(param.data, src=0)
def sync_gradients(model, rank, world_size):
for param in model.parameters():
dist.all_reduce(param.grad.data, op=dist.reduce_op.SUM)
1- تمامی شناسه پردازشهای R نمونه/ کپی مخصوص به خود را از مدل با وزن تصادفی ایجاد میکنند.
2- هر کپی با وزن تصادفی ممکن است منجر به ناهمگامی De-synchronization شود. بهتر است وزنهای اولیه را میان تمامی کپیها به صورت همگام کنید. Sync_initial_weights ( . . ) این کار را انجام میدهد. اجازه دهید هر یک از شناسه پردازشهای r وزن خود را به گره مجاورگره مجاور Siblings ارسال کنند و برای راهاندازی اولیه آنها را دریافت کنند.
3 – یک بسته کوچک (با اندازه B) را از بخش مربوط به یک شناسه پردازش بگیرید و (گرادیان) جلوگذر و عقب گذر ار محاسبه کنید. نکته مهمی که به عنوان بخشی از فرایند راهاندازی باید به آن توجه داشته باشید این است که بخش دادههای مربوط به تمامی فرایندها/ شناسه پردازشها باید برای آنها نمایان باشد ( معمولاً بر روی هارد دیسک یا سیستم پرونده مشترک Shared filesystem خود).
4 – تجمع all-reduce را به همراه جمع به عنوان عملیات کاهش Reduction operation بر روی گرادیانهای هر یک از کپیها اجرا کنید. Sync_gradients ( . .) عمل همگامسازی گرادیان را انجام میدهد.
5 – پس از همگامسازی گرادیانها، هر کپی میتواند به صورت مستقل بهروزرسانی SGD استاندارد را بر روی وزن خود اجرا کند. optimizer . step () همین کار را انجام میدهد.
اکنون ممکن است این سؤال پیش بیاید که « چگونه مطمئن شویم که بهرزورسانیهای مستقل همگام باقی خواهند ماند؟»
اگر به معادله بهروزرسانی اولین بهروزرسانی نگاهی بیندازیم

نقطه 2 و 4 در معادله فوق اطمینان حاصل میکنند که وزنهای اولیه و گرادیانها به صورت مجزا همگام خواهند بود. به دلایل مشخص، ترکیب خطی آنها هم همگام خواهد بود ( λ ثابت است).
[irp posts=”18831″]مقایسه عملکرد:
اصلیترین چالشی که تمامی الگوریتمهای توزیعشده با آن روبهرو هستند همگامسازی است. الگوریتمهای توزیعشده در صورتی میتوانند کارآمد و سودمند باشند که زمان همگامسازی کمتر از زمان محاسبه باشد. در این بخش، SGD همگام و SGD استاندارد را با هم مقایسه میکنیم تا ببینیم SGD همگام در چه مواردی میتواند سودمند باشد.
تعریف: فرض کنید اندازه کل دیتاست N است. بستههای کوچک با اندازه B را شبکه پردازش میکند که Tcomp زمان میبرد. در موارد توزیعشده، زمان صرف شده برای همگامسازی all-reduce، Tsync خواهد بود. در صورت وجود کپیهای R، زمان صرف شده برای هر دوره برای SGD توزیعنشده (استاندارد):

برای SGD همگام:

بنابراین، برای اینکه محیط توزیعشده کارآمدتر و سودمندتر از محیط توزیعنشده باشد، باید:

یا:

با اعمال برخی تغییرات در سه عاملی که در نابرابری معادلات بالا مؤثر هستند میتوان بیشتر از مزایای الگوریتم توزیعشده بهرهمند شد:
1- با اتصال گرهها در یک شبکه با پهنای باند بالا (سریع) میتوان Tsync را کاهش داد.
2- Tcomp را میتوان با افزایش اندازه بسته B افزایش داد.
3- R را میتوان با اتصال گرهها بیشتر بر روی شبکه و در اختیار داشتن کپیهای بیشتر، افزایش داد.





