
استفاده از PyText در فیسبوک برای آزمایش سریع NLP
 تیم تحریریه
تیم تحریریه- ۲۴ آبان ۱۴۰۰
هدف اصلی از ساخت «PyText»، ارائه تجربهای سادهتر برای کاربران است تا گردش کاری NLP را به صورت پیوسته (end-to-end) اجرا کنند. استفاده از PyText برای حصول این هدف باید به حل برخی از اشکالات در گردش کاری NLP بپردازد. از میان همه این اشکالات، ناهمخوانی میان آزمایش و چرخه حیات کاربرد NLP به عنوان آزاردهندهترین اشکال شناخته میشود.
بررسی مبادلات میان آزمایش پردازش زبان طبیعی (NLP) و تولید
اجرای راهحل پردازش زبان طبیعی (NLP) مراحل آزمایش پیچیدهای دارد. دانشمندان در این مراحل سریعاً ایدهها و مدلهای جدید را آزمایش میکنند تا سطح مشخصی از عملکرد حاصل آید.
بسیاری از این ایدهها از پیشینه تحقیق مقالههای مختلف استخراج میشوند. متخصصان داده در طول آزمایش، آن دسته از چارچوبهایی را مد نظر قرار میدهند که رابطهای آسانی را ارائه میکنند. این رابطها میتوانند نوشتن مدلهای پویا و پیشرفته را آسانتر کنند.
چارچوبهایی از قبیل PyTorch یا TensorFlow Eager نمونههای بارزی از این دسته هستند. وقتی زمانِ بهکارگیری چارچوبها از راه میرسد، محدودیت مدلهای نمودار پویا به امری چالشبرانگیز تبدیل میشود. متخصصان یادگیری عمیق، به استفاده از چارچوبهایی که دارای نمودارهای محاسباتی استاتیک هستند روی میآورند.
TensorFlow، Caffe2 یا MxNet از اعضای مشهور این نوع از چارچوبها به شمار میروند. نتیجه پایانی این است که تیمهای بزرگ علوم دادهای غالباً از دستههای متفاوتی برای آزمایش استفاده میکنند.
PyTorch یکی از نخستین چارچوبهای یادگیری عمیق بود که به بررسی شکاف میان آزمایش سریع و serving پرداخت. PyText با تکیه بر PyTorch برخی از اصول فضای پردازش زبان طبیعی را بهینهسازی میکند.
[irp posts=”23350″]درک PyText
از دید مفهومی، PyText با 4 هدف طراحی شده که عبارتند از
1. انجام هرچه سریع و آسانترِ آزمایش با ایدههای مدلسازی جدید
2. آسانتر کردنِ استفاده از مدلهای از پیشساخته با کمترین کار اضافی
3. تعریف کردن یک گردش کار واضح برای محققان و مهندسان تا مدلهای خود را بسازند، ارزیابی کنند و سرانجام آنها را با هزینه حداقل به تولید انبوه برسانند.
4. تضمین عملکرد عالی و خروجی زیاد در مدلهای بهکار گرفته شده
قابلیتهای PyText باعث ایجاد نوعی چارچوب مدلسازی میشود که به محققان و مهندسان کمک میکند خطوط لوله بههمپیوستهای را برای آموزش یا استنباط بسازند. در اجرای فعلیِ PyText، مراحل اصلی چرخه حیاتِ گردش کاری NLP مورد بررسی قرار میگیرند.
هدف از این کار، ارائه رابطهایی برای آزمایش سریع، پردازش دادههای خام، گزارش متریک، آموزش و serving مدلهای آموزشیافته است. چشمانداز سطحبالایِ PyText به وضوح نشان میدهد که مولفههای بومی چارچوب بر این مراحل احاطه دارند.
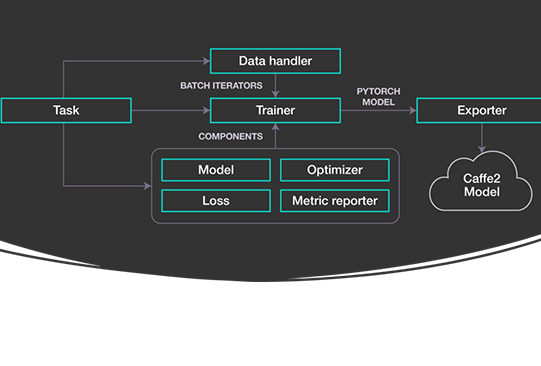
معماری PyText شامل اجزای زیر است
- کار: ادغام مولفههای گوناگون با یکدیگر برای آموزش یا استنباط در یک خط لوله
- مدیریت داده Data Handler : پردازش دادههای خام و آمادهسازی دستههای tensor برای اینکه در اختیار مدل قرار گیرد.
- مدل: تعریف کردنِ معماری شبکه عصبی
- بهینهساز: بهینهسازی پارامتر مدل با استفاده از loss
- گزارشگر متریک: اجرای محاسبات متریک و ارائه گزارش به مدلها
- آموزشدهنده: استفاده از مدیریت داده، مدل، loss و بهینهساز برای آموزشِ یک مدل و انتخاب مدل با روش اعتبارسنجی
- پیشبینیکننده: استفاده از ابزار مدیریت داده و مدل برای استنباط در یک مجموعهدادۀ آموزشی
- صادرکننده: صادر کردن مدل PyTorch آموزشیافته به نمودار Caffe2 با استفاده از ONNX8
همانطور که ملاحظه میکنید، PyText از فرمت تبادل شبکه عصبی بازOpen Neural Network Exchange Format(ONNX) (ONNX) برای انتقال مدلها از PyTorch به Caffe2 استفاده میکند. PyText در انجام طیف وسیعی از کارهای پردازش زبان طبیعی ایفای نقش میکند.
از جمله این کارها میتوان به دستهبندی متن، برچسب زدن واژه، تجزیه معنایی و مدلسازی زبانی اشاره کرد. بهطور مشابه، PyText با استفاده از مدلهای محتوایی contextual models از قبیل مدل SeqNN و مدل Contextual Intent Slot در حوزه درک زبان نیز به کار گرفته میشود. از دیدگاه گردش کاری NLP، روش پردازش PyText باعث میشود فرایند انتقال ایده از مرحله آزمایش به تولید، به آسانی انجام شود.
گردش کار PyText معمولاً شامل مراحل زیر است
1. اجرای مدل در PyText و اطمینان از عملکرد مناسبِ متریکهای آفلاین در مجموعه آزمایشی
2. استفاده از سرویس استنباطِ مبتنی بر PyTorch و ارزیابی در مقیاس کوچک
3. صدور خودکارِ آن به Caffe2. در برخی موارد (مثلاً زمانی که از منطق کنترل گردش پیچیده و ساختارهای دادهای شخصی استفاده میشود)، شاید PyTorch 1.0 از این کار پشتیبانی نکند.
4. اگر راهکار ذکر شده در شماره 3 مورد پشتیبانی قرار نگیرد، از Py-Torch C++ API9 برای نوشتن مجدد مدل و قرار دادن آن در عملگر Caffe2 استفاده کنید.
5. مدل را در سرویس پیشبینی Caffe2 قرار دهید.
[irp posts=”4477″]استفاده از PyText
فرایند آغاز کار با PyText نسبتاً آسان است. این چارچوب را میتوان به عنوان بسته معمولی پایتون راهاندازی کرد.
$ pip install pytext-nlp
پس از آن، میتوان مدل NLP را به شرح زیر آموزش داد.
(pytext) $ cat demo/configs/docnn.json
{
"task": {
"DocClassificationTask": {
"data_handler": {
"train_path": "tests/data/train_data_tiny.tsv",
"eval_path": "tests/data/test_data_tiny.tsv",
"test_path": "tests/data/test_data_tiny.tsv"
}
}
}
}$ pytext train < demo/configs/docnn.json
هر یک از کارها رابطه میان اجزای مختلف را تعریف میکند. جزئیات آن در کد زیر نشان داده شده است.
from word_tagging import ModelInputConfig, TargetConfigclass WordTaggingTask(Task): class Config(Task.Config): features: ModelInputConfig = ModelInputConfig() targets: TargetConfig = TargetConfig() data_handler: WordTaggingDataHandler.Config = WordTaggingDataHandler.Config() model: WordTaggingModel.Config = WordTaggingModel.Config() trainer: Trainer.Config = Trainer.Config() optimizer: OptimizerParams = OptimizerParams() scheduler: Optional[SchedulerParams] = SchedulerParams() metric_reporter: WordTaggingMetricReporter.Config = WordTaggingMetricReporter.Config() exporter: Optional[TextModelExporter.Config] = TextModelExporter.Config()
پس از اینکه مدل آموزش داده شد، میتوان آن را ارزیابی کرد و به Caffe2 فرستاد.
(pytext) $ pytext test < "$CONFIG"(pytext) $ pytext export --output-path exported_model.c2 < "$CONFIG"
باید به این نکته توجه کرد که PyText یک معماری توسعهپذیر را فراهم میکند و امکان شخصیسازیِ هر کدام از اجزای کلیدی آن وجود دارد.
PyText نقطه عطفی در توسعه پردازش زبان طبیعی به شمار میآید. این نرمافزار یکی از نخستین چارچوبهایی است که مبادله میان آزمایش و تولید را بررسی میکند. PyText با حمایت فیسبوک و جامعه PyTorch این فرصت را دارد تا به یکی از مهمترین دستههای پردازش زبان طبیعی در فضای یادگیری عمیق تبدیل شود.





