افزایش سرعت pandas با استفاده از Modin حتی برای لپتاپها!
 تیم تحریریه
تیم تحریریه- ۳۰ مرداد ۱۴۰۰
pandas یکی از کتابخانههای بسیار مشهور در دنیای علوم داده است. این کتابخانه عملکرد بسیار خوبی دارد، قالبها و ساختارهای دادهای آن به نحویست که استفاده از آنها آسان است. این کتابخانه همچنین ابزارهایی برای تجزیه و تحلیل دادهها ارائه میدهد. اما وقتی باید با حجم بسیار زیادی از داده کار کنیم، اجرای pandas روی دستگاههای تک هستهای ناکارآمد خواهد بود و مجبور میشویم برای بهبود عملکرد به سیستمها توزیعشده روی بیاوریم. اما این کار درواقع نوعی موازنه میان بهبود عملکرد و شیب منحنی یادگیری است. گاه کاربران تنها میخواهند سرعت اجرای Pandas بالا برود و قصد ندارند جریان کاری را برای تنظیمات سختافزار خود بهینه سازند. افراد میخواهند کدی که برای دیتاست 10 کیلوبایتی خود استفاده میکنند را برای دیتاست 10 ترابایتی نیز به کار بگیرند. قاب داده DataFrame Modin با بهینهسازی Pandas این مشکل را حل میکند تا دانشمندان داده به جای وقت گذاشتن روی ابزارهایی که دادهها را استخراج میکنند بر روی استخراج ارزش دادهها متمرکز شوند.
قاب داده Modin

Modin یکی از جدیدترین پروژههای دانشگاه برکلی کالیفرنیا است که با هدف تسهیل کار دانشمندان داده در زمینه استفاده از سیستمهای توزیعشده آغاز شد. این پروژه یک کتابخانه و قاب داده چندفرایندی دارای یک رابط برنامهنویسی کاربردی منطبق با pandas است که امکان افزایش سرعت جریانهای کاری Pandas را برای کاربران فراهم میکند.
Modin سرعت کوئریهای (query) Pandas را روی یک دستگاه 8 هستهای تا 4 برابر افزایش میدهد و بدین منظور تنها لازم است که کاربر یک خط از کد نوتبوکهای (notebook) خود را تغییر دهد. این سیستم برای کاربرانی طراحی شده که میخواهند برنامههایشان بدون نیاز به تغییرات عمده در کد اصلی قابل تعمیم باشند و سرعت اجرای آنها افزایش یابد. هدف نهایی در این عملیات این است که بتوان Pandas را در فضای ابری cloud نیز به کار گرفت.
نصب
Modin کاملاً رایگان و متنباز است و میتوان آن را از سایت GitHub بارگیری کرد:
https://github.com/modin-project/modin
pip install modin
Modin را میتوان از PyPI نیز نصب کرد:
برای نصب در سیستمعامل ویندوز برنامه Ray نیز باید نصب شود. البته ویندوز بهصورت پیشفرض از این برنامه پشتیبانی نمیکند. بنابراین، برای نصب آن باید از WSL Windows Subsystem for Linux استفاده کنید.
Modin چگونه سرعت اجرای برنامهها را افزایش میدهد؟
استفاده در لپتاپ
یک لپتاپ جدید و 4 هستهای و قاب دادهای که به راحتی با آن هماهنگ میشود را درنظر بگیرید. pandas تنها از یکی از هستههای این رایانه استفاده میکند، اما Modin میتواند تمامی هستههای CPU را به کار بگیرد.

در واقع کاری که Modin انجام میدهد این است که استفاده از هستههای CPU را افزایش میدهد و بدین صورت عملکرد بهتری را رقم میزند.
استفاده در دستگاههای بزرگتر
وقتی با دستگاههای بزرگتر سروکار داشته باشیم، کارآیی Modin حتی قابلتوجهتر نیز خواهد بود. بیاید فرض کنیم یک سرور یا دستگاه بسیار قدرتمند داریم. pandas در این سیستم نیز تنها از یک هسته استفاده خواهد کرد، درحالیکه modin تمامی هستهها را به کار خواهد گرفت. در تصویر زیر عملکرد pandas و modin در اجرای read_csv روی یک دستگاه 144 هستهای مقایسه شده است.

نمودارهای مربوط به pandas به صورت مشخص و خطی افزایش پیدا کردهاند که دلیل آن نیز استفاده از یک هسته از دستگاه است. شاید نمودارهای میلهای سبزرنگ که مربوط به زمان اجرای read_csv توسط modin هستند در ابتدا به چشم نیایند، زیرا بسیار کوچک هستند.
اجرای CSV با سایز 2 گیگابایت برای modin حدوداً 2 ثانیه و با سایز 18 گیگابایت کمتر از 18 ثانیه به طول میانجامد.
معماری
در این بخش قصد داریم به بررسی معماری Modin بپردازیم.
بخشبندی قاب داده
تفاوت عملیات بخشبندی در Modin با pandas در این است که Modin بخشبندی را در دو سطح سطری و ستونی انجام میدهد که باعث انعطافپذیری و مقیاسپذیری Modin در زمینه تعداد سطرها و ستونها میشود.
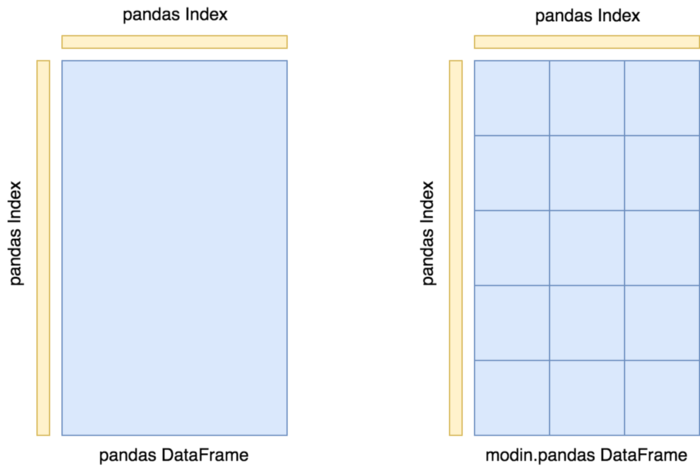
معماری سیستم
Modin به چند لایه جداگانه تقسیم میشود:
- بالاترین لایه رابط برنامهنویسی نرم افزار pandas است.
- لایه بعدی کوئری کامپایلر Query Compiler را در خود جای میدهد که کوئریها را از لایه رابط برنامهنویسی کاربردی pandas دریافت کرده و عملیات بهینهسازی را روی آنها اجرا میکند.
لایه آخر که مدیر بخشبندی نام دارد، مسئولیت طرحبندی دادهها و مخلوط کردن، بخشبندی و سریسازی مسائلی که به هر بخش ارسال میشود را بر عهده دارد.
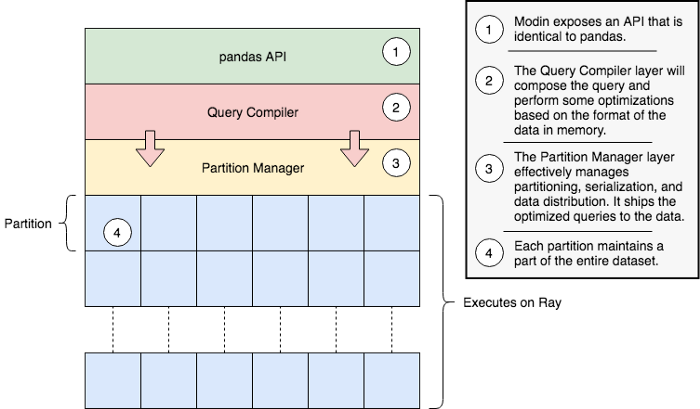
بهکارگیری رابط برنامهنویسی کاربردی pandas در Modin
رابط برنامهنویسی کاربردی pandas بسیار پیشرفته است و همین موضوع علت گستردگی موارد کاربرد آن میباشد.

با توجه به این گستردگی، modin یک روش مبتنی بر داده را دنبال میکند. یعنی سازندگان modin به دنبال این بودند که مردم بیشتر از کدوم قابلیتهای pandas استفاده میکنند. آنها
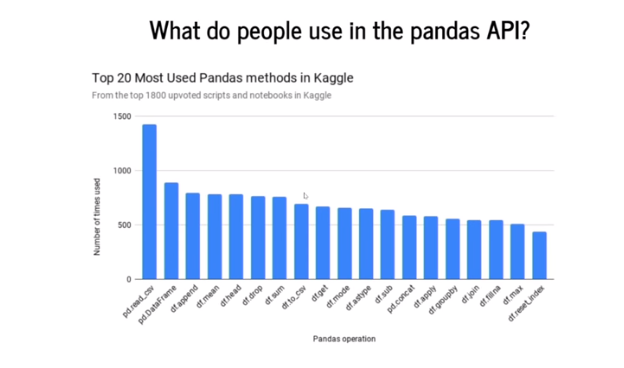
به سراغ Kaggle رفتند و تمامی نوتبوکها و کدهای حاضر در آن را بررسی کردند و درنهایت، دریافتند که محبوبترین متدهای pandas به شرح زیر هستند:
pd.read_CSV با اختلاف زیاد، محبوبترین متدی است که در pandas استفاده میشود. دومین متد محبوب نیز pd.Dataframe میباشد. بنابراین، سازندگان modin ابزارها را براساس محبوبیتشان در میان کاربران تعبیه و بهینهسازی کردند و بدین ترتیب، modin هماکنون از حدود 71% از رابط برنامهنویسی کاربردی pandas پشتیبانی میکند و طبق مطالعات انجام شده، این مقدار برابر است با 93% از کل موارد استفاده از pandas.
چارچوب کاری Ray
Modin برای آنکه بتواند به راحتی سرعت نوتبوکها، کدها و کتابخانههای pandas را افزایش دهد، از Ray استفاده میکند.Ray یک چارچوب اجرایی توزیعشده و کارآمد است که رنج گستردهای از برنامههای کاربردی یادگیری ماشینی و یادگیری تقویتی را هدف قرار میدهد. با استفاده از Ray ، کدی که باید روی یک مجموعه از دستگاهها اجرا شود با کدی که روی یک دستگاه اجرا میشود مشابه خواهد بود.Ray را میتوانید در این آدرس روی سایت GitHub پیدا کنید.
استفاده از Modin
فراخوانی Importing
Modin تمام pandas را فرامیگیرد و دادهها و محاسبات را تماماً توزیع میکند و بهاین ترتیب، سرعت جریانهای کاری در pandas تنها با تغییر یک خط کد، بهطرز چشمگیری افزایش خواهد یافت. در این حالت، کاربران میتوانند از همان نوتبوکهای همیشگی pandas استفاده کنند، درحالیکه حتی روی یک دستگاه واحد نیز به لطفModin سرعت بسیار بالاتری را تجربه خواهند کرد. به این منظور تنها کافی است در زمان وارد (import) کردن pandas به جای فایل ساده pandas، modin.pandas را وارد کنیم.
import numpy as np import modin.pandas as pd

حال بیایید با استفاده از Numpy یک دیتاست آزمایشی حاوی اعداد صحیح تصادفی بسازیم. در اینجا نیازی نیست بخشبندی انجام دهیم.
ata = np.random.randint(0,100,size = (2**16, 2**4))
df = pd.DataFrame(data)
df = df.add_prefix("Col:")
اگر بخواهیم 5 خط اول دیتاست را با استفاده از دستور head چاپ کنیم، درنهایت، درست مثل pandas یک جدول در فرمت HTML خواهیم داشت.
type(df) modin.pandas.dataframe.DataFrame

مقایسه
Modin عملیات افراز و مخلوطکردن دادهها را انجام میدهد، بنابراین کاربران میتوانند بر روی استخراج ارزش دادهها متمرکز شوند. کد زیر روی یک سیستم iMac چهار هستهای نسخه سال 2013 با رم 32 گیگابایتی اجرا شده است.
pd.read_csv
عملیات read_csv در مقایسه با سایر عملیاتها، کاربردهای بیشتری در pandas دارد. در ادامه عملکرد read_csv را در modin و pandas با هم مقایسه میکنیم.
- Pandas
%%time
import pandas
pandas_csv_data = pandas.read_csv("../800MB.csv")
-----------------------------------------------------------------
CPU times: user 26.3 s, sys: 3.14 s, total: 29.4s
- Modin
%%time
modin_csv_data = pd.read_csv("../800MB.csv")
-----------------------------------------------------------------
CPU times: user 76.7 ms, sys: 5.08 ms, total: 81.8 ms
Wall time: 7.6 s
همانطور که ملاحظه میفرمایید، سرعت عمل read_csv روی یک دستگاه چهار هستهای تنها با تغییر گزاره import تا چهار برابر افزایش مییابد.
df.groupby
عملیات groupby در pandas بهخوبی نوشته شده و سرعت بسیار بالایی دارد. اما modin در این حوزه نیز به راحتی pandas را شکست میدهد.
- Pandas
%%time import pandas _ = pandas_csv_data.groupby(by=pandas_csv_data.col_1).sum() ----------------------------------------------------------------- CPU times: user 5.98 s, sys: 1.77 s, total: 7.75 s
- Modin
%%time results = modin_csv_data.groupby(by=modin_csv_data.col_1).sum() ----------------------------------------------------------------- CPU times: user 3.18 s, sys: 42.2 ms, total: 3.23 s Wall time: 7.3 s
تنظیمات پیشفرض pandas
وقتی یک کاربر بخواهد بدون تعبیه یا بهینهسازی رابط برنامهنویسی کاربری pandas از آن استفاده کند، میتواند از پیشفرضهای پانداس بهره ببرد. به این ترتیب، کاربر میتواند در سیستم خود از نوتبوکهایی استفاده کند که حاوی عملیاتهایی هستند که در Modin تعبیه نشده اند، اما این کار موجب میشود تا عملکرد سیستم کاهش یابد. وقتی از تنظیمات پیشفرض pandas استفاده میکنید با این هشدار مواجه خواهید شد:
dot_df = df.dot(df.T)
کد زیر پس از اتمام محاسبات یک Modin DataFrame توزیعشده به شما تحویل میدهد.
نتیجهگیری
علیرغم آنکه Modin هنوز در مراحل ابتدایی پیشرفت خود است، اما توانسته به عنوان یک افزونه در pandas نتایج خوبی به دست بیاورد. Modin میتواند عملیات بخشبندی و مخلوطکردن دادهها را به طور کامل انجام دهد تا کاربر بتواند بر روی جریانهای کاری متمرکز شود. هدف اصلی Modin این است که امکان بهکارگیری ابزارهایی که برای دادههای کمحجم استفاده میشوند را دادههای حجیم نیز فراهم آورد تا کاربران برای تحلیل دادهها در سایزهای مختلف نیازی به تغییر رابط برنامهنویسی کاربردی خود نداشته باشند.
type(dot_df) ----------------- modin.pandas.dataframe.DataFrame