

برچسب های نویزدار و تاثیر آن بر مسائل ردهبندی
 تیم تحریریه
تیم تحریریه- ۳ شهریور ۱۴۰۰
عملکرد همه رده بندها، یا بهتر است بگوییم همه مدلهای یادگیری ماشین، به کیفیت دادههای آنها بستگی دارد. کیفیت دادهها نیز خود به عواملی از قبیل دقت اندازهگیری (وجود نویز noise)، ثبت اطلاعات مهم، عدم وجود اطلاعات زائد، شیوه نمونهگیری و معرف بودن نمونه، بستگی دارد. در این نوشتار بر مسئله نویز، یا به بیان دقیقتر برچسب های نویزدار، تمرکز میکنیم؛ یعنی زمانی که هر نمونه فقط میتواند یک برچسب (یا کلاس) داشته باشد و یک زیرمجموعه از نمونههای موجود در دیتاست به اشتباه برچسبگذاری شدهاند. علاوه بر این، عملکرد رده بندها در صورت وجود نویز، تأثیر نویز روی فرآیند یادگیری رده بندها، و راهحلهای موجود برای این مشکلات را نیز مرور خواهیم کرد.
در این پست، صرفاً به دیتاستهایی میپردازیم که شکل ماتریسی دارند. البته بسیاری از نکاتی که اینجا مطرح میشوند در یادگیری عمیق نیز صدق میکنند؛ با این حال، تفاوتهای عملی بین این دو باعث میشود که مقالهی دیگری را به آن حوزه اختصاص دهیم. کد پایتون آزمایشات انجامشده و تصاویر مربوطه را میتوانید در این لینک مشاهده کنید.
ضرورت مسئله

توجه به برچسب های نویزدار از دو جنبه حائز اهمیت است:
1. برچسب های نویزدار میتوانند به میزان چشمگیری به عملکرد آسیب برسانند: نویز موجود در دیتاست را میتوان در دو دسته گروهبندی کرد: نویز در ویژگیها و نویز در برچسبها. چندین مقالهی پژوهشی اشاره کردهاند که نویز در برچسبها آسیبزاتر از نویز در ویژگیهاست. تصویر بالا تأثیر 30% نویز تصادفی در برچسبها را روی مرز ردهبندیClassification boundary مدل LinearSVC نشان میدهد (مدل روی یک دیتاست ردهبندی دودوییBinary classification ساده، خطی و تفکیکپذیر اجرا شده است). در مورد تأثیرات برچسب های نویزدار در قسمتهای بعدی مقاله به تفصیل صحبت خواهیم کرد.
2. برچسب های نویزدار فراوانی بالایی دارند: نویز میتواند به طرق مختلف به برچسبهای دیتاست نفوذ کند. یکی از این منابع برچسبگذاری خودکارAutomatic labeling ابراطلاعات Meta information است. در برچسبگذاری خودکار، اغلب از (یعنی اطلاعاتی که مستقیماً از بردارهای ویژگیFeature vector به دست نمیآیند) برای تولید برچسب استفاده میشود؛ به عنوان مثال میتوان به برچسبگذاری تصاویر بر اساس هشتگها یا استفاده از گزارشات کامیتCommit logs برای تشخیص ماژولهای ناقص یک منبعدادهی نرمافزاری اشاره کرد. در مقایسه با برچسبگذاری توسط متخصصان حوزههای مربوطه، برچسبگذاری خودکار به زمان و هزینهی کمتری نیاز دارد، به خصوص زمانی که دیتاست بزرگ باشد؛ البته این صرفهجویی به قیمت کاهش کیفیت تمام میشود. برای مثال، در حوزهی مهندسی نرمافزار، یک الگوریتم مشهور و برجسته به نام SZZ وجود داشت که سالها برای شناسایی کامیتهای تولیدکنندهی باگ به کار میرفت. در نهایت دریافتند این الگوریتم نرخ نویز خیلی بالایی دارد و بدین ترتیب همهی پژوهشهایی که برای تولید دیتاستهای ردهبندی نواقصDefect classification از SZZ استفاده کرده بودند، زیر سؤال رفتند.
این رابطهی تبادلی بین کیفیت و هزینه در زمینههای گوناگون به چشم میخورد. به عنوان مثال میتوان به ساخت دیتاستی اشاره کرد که هدفش پیشبینی ابتلا به کووید-19 بر اساس ویژگیهای دموگرافیک است. برای جمعآوری برچسبها (ابتلا یا عدم ابتلا به کووید-19) تنها دو گزینه داریم: یا از آزمونهای گرانقمیت، آهسته اما دقیق RT-PCR استفاده کنیم یا اینکه کیتهای تشخیصی سریع و ارزانقیمت را به کار ببریم که احتمال خطا در آنها بالاست.
البته به این نکته نیز باید توجه داشت که افراد یا حتی متخصصانی که وظیفهی برچسبگذاری را بر عهده دارند هم جایزالخطا هستند. به عنوان مثال در حوزهی پزشکی، نرخ خطای ردهبندی تصاویر MRI بین رادیولوژیستهایی با 10 سال تجربه به 1/16% میرسد. Amazon Mechanical Turk ابزاری محبوب برای برچسبگذاری دادههاست؛ گفته میشود باتهایی غیرقانونی (و گاهی افرادی کمدقت) در این ابزار حضور دارند که برچسبگذاری را به صورت تصادفی (و نادرست) انجام میدهند. به طور کلی، به سختی میتوان دیتاستی با اندازه مناسب پیدا کرد که دست کم مقداری نویز نداشته باشد. بنابراین با قطعیت میتوان گفت آگاهی در مورد برچسب های نویزدار برای همهی متخصصان علوم داده که با دیتاستهای دنیای واقعی سروکار دارند، الزامی است.
رده بندها چطور به برچسب های نویزدار واکنش نشان میدهند؟
هر رده بندی که برچسب نویزدار داشته باشد، با افت عملکرد روبرو میشود؛ سؤال اینجاست که میزان این افت عملکرد چقدر است؟ پاسخ این سؤال به قدرت به رده بندی بستگی دارد که برای استخراج دیتاست به کار میرود. برای درک بهتر این نکته، یک آزمایش اجرا میکنیم. در این آزمایشات از هفت دیتاست (iris، Breast Cancer، Vowel، Segment، Digits، Wine و Spambase) استفاده میکنیم تا احتمال سوگیری را کاهش دهیم. به منظور محاسبهی دقت هر جفت رده بند-دیتاست، تکنیک اعتبارسنجی متقاطع 5 لایهای را سه بار اجرا (تکرار) میکنیم. در هر بار اجرا، 20% از برچسبهای آموزشی را به صورت تصادفی انتخاب و نویزدار میکنیم (از طریق معکوس کردنflipping ). به این نکته توجه داشته باشید که نویز فقط به دیتاست آموزشی وارد میشود و برای آزمایش مدل، از برچسبهای اصلی که سالم هستند استفاده میکنیم.

همانطور که پیشتر توضیح دادیم و در تصویر بالا هم مشاهده میکنید، عملکرد همه رده بندها در اثر ورود نویز افت کرده است؛ اما میزان افت عملکرد در هرکدام از رده بندها با دیگری متفاوت است. برای مثال، درخت تصمیمDecision tree (DT) آسیبپذیری بسیار زیادی در برابر نویز دارد. 4 الگوریتم گروهی که اینجا مورد بررسی قرار گرفتهاند (جنگل تصادفیRandom forest یا RF، extra trees یا Extra، XGBoost یا XGB و LightGBM یا LGB) روی دادههای اصلی، عملکرد تقریباً مشابهی از خود نشان دادهاند. اما عملکرد XGBoost بعد از افزودن نویز بیشتر از بقیه دچار آسیب میشود؛ از سوی دیگر، RF نسبت به نویز مقاوم به نظر میرسد.
برچسب های نویزدار چطور به عملکرد آسیب میزنند؟

دلیل واضح و بدیهی این است که دادههای بیکیفیت منجر به ساخت مدلهای بیکیفیت میشوند. اما تعریف کیفیت کار چندان سرراست و سادهای نیست. شاید فکر کنیم هرچه نویز دیتاست بیشتر باشد، کیفیت آن پایینتر است و از نظر منطقی هم درست به نظر برسد. اگر به تصویر 1 و 3 توجه کنید (تصویر 3 به جای 400 نمونه، 4000 نمونه دارد) میبینید که هر دو دیتاست 30% نویز دارند؛ پس طبق آنچه گفتیم باید فرض کنیم سطح کیفیت آنها هم برابر است. اما مشاهده میکنید که در تصویر 3، مرز تصمیمی که بر اساس دادههای نویزدار آموخته شده با مرز تصمیم مبتنی بر دادههای تمیز، تفاوت چندانی ندارد. هدف از این مثال، رد پیشفرض مذکور نبود؛ بلکه تأکید بر این مهم بود که هنگام توجیه زیان عملکرد، علاوه بر میزان نویز دیتاست، باید به جنبههای دیگری (مثل اندازه دیتاست) هم توجه داشت.
علاوه بر این، رویکرد دادهمحور به تنهایی نمیتواند این را توجیه کند که چرا رده بندها در برابر برچسب های نویزدار واکنش متفاوتی نشان میدهند. به همین دلیل، در قسمت بعدی از منظر رده بندها به قضیه نگاه میکنیم. بدین منظور، آسیبپذیرترین رده بند یعنی درخت تصمیم را انتخاب کرده و آن را روی برچسبهای سالم و نویزدار دیتاست iris آموزش دادیم. سپس ساختار نهایی درخت تولیدشده را به تصویر درآوردیم:
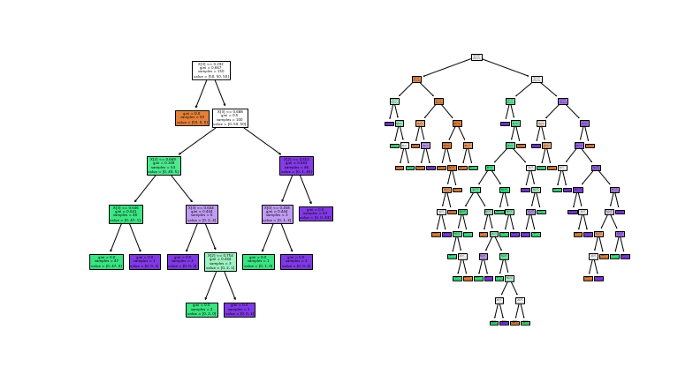
در این مثال تنها 20% نویز به برچسبها وارد کردیم. اما حتی با این مقدار نویز هم میتوان عملکرد درخت تصمیم (سمت چپ) را به شدت کاهش داد (سمت راست). این مثال ساختگی و اغراقشده است؛ با این حال، نکتهای را نشان میدهد که تقریباً در مورد همه رده بندها صدق میکند: نویز در برچسبها منجر به افزایش پیچیدگی مدل شده و بدین طریق باعث میشود رده بندها روی نمونههای نویزدار، بیشبرازش کنند.

الگوریتم دیگری که به خوبی میتواند تأثیر نویز را نشان دهد Adaboost است، مدلی که رده بندهای نوین XGBoost و LightGBM بر پایهی آن ساخته شدهاند. این مدل در اوایل دههی 2000 در شمار پیشرفتهترین و جدیدترین دستاوردها قرار داشت؛ با این حال، در برابر برچسب های نویزدار آسیبپذیری بالایی دارد. Adaboost در ابتدا به همهی نمونهها، وزن برابر اختصاص میدهد. سپس در هر دور آموزشی، وزن نمونههایی که به اشتباه ردهبندی کرده است را افزایش و وزن سایر نمونهها را کاهش میدهد؛ بدین ترتیب، به تدریج روی نمونههای سختتر تمرکز بیشتری میگذارد. بدیهی است ردهبندی نمونههایی که برچسب اشتباه دارند کار دشوارتری است. به همین دلیل Adaboost در انتها مجبور میشود به نمونههایی که برچسب اشتباه دارند وزن بیشتری اختصاص دهد؛ به عبارتی سعی دارد نمونههایی را به درستی ردهبندی کند که در اصل باید از آنها چشمپوشی کند. در تصویر 5، توزیع وزنهایی که Adaboost به نمونههای نویزدار و سالم دیتاست breast cancer (شامل 20% نویز) اختصاص میدهد را مشاهده میکنید. با اینکه نسبت نمونههای نویزدار به نمونههای سالم 1 به چهار است، بعد از 20 دور، وزن آنها جمعاً به دو برابر وزن نمونههای سالم میرسد.
برای تکمیل این بحث، به رده بندهایی میپردازیم که در سر دیگر طیف قرار دارند، یعنی آنهایی که مقاومت بیشتری در مقابل نویز دارند. با توجه به تصویر 2 یک نکتهی جالب میتوان دریافت: دو رده بندی که بیشترین مقاومت را دارند (جنگل تصادفی و Extra Tree) مجموعهای متشکل از همان الگوریتمی هستند که بیشترین آسیبپذیری را داشت (درخت تصمیم). علت در این نهفته است که این الگوریتمها مثل Adaboost (یا SVM) بیش از حد روی نمونههای نویزدار تمرکز نمیکنند، بلکه از طریق ادغام bootstrap (یا روش bagging) با همهی نمونهها به صورت یکسان رفتار میکنند؛ این خصیصیهی اصلی جنگلهای تصادفی است.
شاید از خود بپرسید چطور میتوان یک دسته درخت تصمیم ضعیف را با هم جمع کرد و چنین جنگل قدرتمندی تشکیل داد؟ پاسخ در مفهومی به نام تبادل سوگیری-واریانسBias-variance decomposition خطای ردهبندی خلاصه میشود. تصور کنید تعداد زیادی درخت تصمیم دارید که همگی روی یک دیتاست ردهبندی دودویی، دقت 60 درصدی دارند. با فرض اینکه هیچ همبستگی بین پیشبینیهای آنها وجود ندارد، با ورود یک نمونهی جدید میتوانیم انتظار داشته باشیم که (حدوداً) 60% درختها به درستی پیشبینی میکنند. پس اگر نتایج آنها را از طریق رأیگیری اکثریتی جمع کنیم، بیشتر درختها یعنی 60% آنها نمونهی جدید را به درستی پیشبینی کرده و به دقت کامل یعنی 100% میرسند. البته از آنجایی که پیشفرض مذکور (مبنی بر همبستگی صفر) در عمل غیرممکن است، نمیتوان به دقت 100% دست یافت؛ هرچند در شرایط مناسب میتوان به آن نزدیک شد.
مدیریت برچسب های نویزدار
قبل از اینکه در مورد کاهش آسیبهای ناشی از وجود نویز صحبت کنیم، یک نکته را به خاطر داشته باشید: هیچ کدام از روشهایی که قرار است توضیح دهیم نوشدارو و علاج قطعی نیستند، گاهی اوقات جواب میدهند و گاهی هم نه. حتی اگر به نتیجه برسند، برخی اوقات ممکن است خروجی آنها در مقایسه با هزینههای محاسباتی که تحمیل میکنند قابل توجیه نباشد. پس بهتر است روال پردازشی یادگیری ماشینی خود را همیشه با یک خط پایهی ساده (که از هیچکدام این مکانیزمهای کنترلی استفاده نمیکند) مقایسه کنید.

به طور کلی میتوان از دو زاویه به حل مشکل برچسب های نویزدار نگاه کرد: استفاده از الگوریتمهایی که نسبت به نویز مقاوم هستند و یا پاکسازی دادهها. در رویکرد اول، تنها کافیست الگوریتمهایی را انتخاب کنیم که ذاتاً مقاومت بالاتری دارند؛ برای مثال مدلهای گروهی مبتنی بر روش bagging نسبت به مدلهای boosting اولویت دارند. الگوریتمها و توابع زیان فراوانی (همچون SVM نامتوازن) نیز وجود دارند که اساساً برای مقاومت علیه نویز ساخته شدهاند. راه دیگر این است که با تکیه بر این نکته که برچسب های نویزدار منجر به بیشبرازش میشوند، الگوریتمهای آسیبپذیر را مقاومتر کنیم؛ بدین منظور، تنها کافی است تکنیکهای منظمسازیRegularization قویتری را برای آنها تعریف کنیم (تصویر 6).
پیشتر مشاهده کردیم ردهبندی نمونههایی که برچسب اشتباه دارند، کار دشواری است؛ برای پاکسازی دادهها میتوانیم از همین نکته استفاده کنیم. شماری از مقالات یادگیری ماشینی با تکیه بر همین نکته، فرآیندهای جدیدی برای پاکسازی دادهها طراحی کردهاند. گامهای مقدماتی این فرآیندها شامل این موارد میشوند: آموزش مجوعهای از رده بندها روی یک دیتاست آموزشی، استفاده از این رده بندها برای پیشبینی برچسب یک دیتاست دیگر، محاسبهی درصدی از رده بندها که قادر به پیشبینی برچسب درست برای نمونهها نبودهاند. این درصد، نشاندهندهی احتمال برچسبگذاری اشتباه یک نمونه را نشان میدهد. لینک مربوط به کد کامل را پیشتر در دسترس خوانندگان قرار دادیم؛ در این قسمت، نمونهای ساده از پیادهسازی گروهی از درختهای تصمیم را نیز به نمایش میگذاریم:
def detect_noisy_samples(X,y,thres=.5): #Returns noisy indexes
rf = RandomForestClassifier(oob_score=True).fit(X,y)
noise_prob = 1 - rf.oob_decision_function_[range(len(y)),y]
return noise_prob>thres
با استفاده از این روش، مدل توانست روی دیتاست Spambase با 25% نویز در برچسبها، 85% از نمونههایی که برچسب اشتباه خوردهاند را تشخیص دهد (در حالیکه نرخ مثبت کاذب یا نمونههای سالمی که به عنوان نویزدار تشخیص داده شدند تنها 13% بود). برای دیتاست Breast Cancer این ارقام به 90% و 10% رسیدند.
اما اینکه صرفاً برای انجام پیشپردازش، چندین رده بند را آموزش دهیم، در دیتاستهای بزرگ چندان عملی به نظر نمیرسد. یک راهکار جایگزین وجود دارد: 1) پیدا کردن K همسایهی نزدیک نمونه، 2) محاسبهی درصدی از این همسایهها که برچسب مشابهی دارند، 3) استفاده از این درصد به عنوان نمایندهی قابلیت اطمینان برچسب. عملکرد رده بندها به کمک این راهکار به طرز چشمگیری بهبود مییابد؛ به نحوی که دو سوم نمونههای نویزدار در دیتاست Spambase تشخیص داده میشوند (با نرخ مثبت کاذب 10% درصدی). پیادهسازی این روش هم بسیار ساده است:
def detect_noisy_samples(X,y,thres=.5): #Returns noisy indexes
knn = KNeighborsClassifier().fit(X,y)
noise_prob = 1 - knn.predict_proba(X)[range(len(X)),y]
return np.argwhere(noise_prob>thres).reshape(-1)
به یاد داشته باشید پاکسازی دادهها لزوماً به معنی دور انداختن نمونههایی که برچسب اشتباه دارند نیست. خروجی هر دو راهکار مذکور، یک مقدار احتمال پیوسته برای هر نمونه است که نشان میدهد چقدر احتمال دارد برچسب اشتباهی به آن نمونه اختصاص داده شده باشد. با معکوس کردن این مقدار احتمال میتوانیم میزان پایاییReliability یا سطح اطمینانConfidence score مدل را محاسبه کنیم. سپس در یادگیری حساس به هزینهCost-sensitive ، این اطلاعات را به کار ببریم. بدین طریق میتوان همهی نمونهها را در دیتاست نگه داشت؛ امری که وقتی میزان نویز بالا یا اندازهی دیتاست کوچک باشد، بسیار مهم خواهد بود. به علاوه، این راهکار از روش<span class=”custom-tooltip”>فیلترینگ<span class=”tooltiptext”>filtering</span> </span> عمومیتر است؛ فیلترینگ، یک مورد خاص از رویکردهای حساس به هزینه است که در آن مقدار تابع هزینه فقط میتواند بین 0 و 1 باشد.
جمعبندی
از توجه شما سپاسگزاریم. فراموش نکنید آنچه در این نوشتار گفته شد صرفاً مطالب مقدماتی بود و ممکن است از مسائلی مهمتر و جامعتر صرف نظر کرده باشد.
برای مثال، در این مقاله در مورد مدلهای نویزدار صحبت نکردیم؛ بلکه تنها روی نمونههایی که اشتباه برچسبگذاری شدهاند تمرکز کردیم و فرض را بر این گذاشتیم که احتمال اختصاص برچسب اشتباه و درست به یک نمونه با هم برابر است. اما این حالت (که به عنوان مدل نویزدار متقارنUniform noise model نیز شناخته میشود) غیرواقعبینانه است و برای مثال، زمانی رخ میدهد که ربات آمازون برچسبگذاری را به صورت تصادفی انجام دهد. فردی که وظیفهی حاشیهنویسی Annotator را برعهده دارد به احتمال بیشتری 9 و 7 را با هم اشتباه میگیرد تا 9 و 8 را، یا احتمال اینکه بین عواطف مثبت و خنثی اشتباه کند بیشتر است تا اینکه عواطف مثبت و منفی را به جای هم تشخیص دهد؛ این در حالی است که مدل نویزدار متقارن قادر به درک این نوع تعاملات نابرابر بین برچسبها نیست.
نکتهی جالب دیگری که در این نوشتار پوشش ندادیم مربوط به پرسشی است که قبل از شروع به جمعآوری برچسبها باید مطرح کرد: آیا بهتر است حجم زیادی دادهی بیکیفیت جمع کنیم یا یک مجوعهی کوچک از دادههای باکیفیت؟





