چرخی در محلههای توکیو: به کارگیری علم داده در دنیای واقعی
تیم تحریریه
- ۱۸ مرداد ۱۴۰۰
دادهکاوی تحت وِب Web-Scraping، واسط برنامه نویسی کاربردی Foursquare، نقشههای فولیوم و غیره
بخشی از پروژه IBM Capstone به این امر اختصاص داشت که دانشمندان علم داده در دنیای واقعی با چه مسائلی مواجه هستند. اهداف آخرین دوره بدین ترتیب تعریف شد: تعریف مسئلهی کسبوکار، جستجوی اطلاعات در وب، و استفاده از پایگاه دادههای مکانی Foursquare جهت مقایسه مناطق مختلف حوزههای (شهریِ) شهر مورد نظر (در این مقاله شهر توکیو) به منظور شناسایی محل مناسبِ راهاندازی کسبوکار مورد انتخاب دانشجو (در این مقاله رستوران). مطابق دستور کار پروژه، سه مرحله فوق را گام به گام توضیح میدهم. جزئیاتِ کدها و تصاویر در Github و لینک آن در پایین همین پست قرار گرفته است.
1. زمینه و مباحث مسئله کسبوکار
بیان مسئله: آیندهی رستورانهایِ سرو ناهار در مناطق اداری توکیو
توکیو پرجمعیتترین کلان شهر دنیا است و در حال حاضر سومین قدرت اقتصادی جهان محسوب می شود لذا مکان مناسبی جهت شروع یک کسبوکار جدید است.
در طی روز به ویژه صبح و وقت ناهار مناطق اداری شهر فرصتهای شغلی مناسبی برای رستورانها فراهم می کنند. رستورانهایی با قیمتهای مناسب (مثلاً 8 دلار بابت یک پرس غذا) اغلب در این ساعاتِ روز ( یعنی 11 صبح تا 2 بعد از ظهر) پُر از مشتری هستند. با توجه به این موضوع به بررسی فواید و مضرات تاسیس رستورانهای سرو کنندهی صبحانه و ناهار در مناطق متراکم اداری پرداختیم. اغلب حاشیه سود یک رستوران معمولی بین 15 تا 20 درصد است امّا ممکن است به 35 درصد هم برسد. مرکز شهر توکیو شامل 23 حوزه (شهری) است در این مقاله تنها پنج مورد از آنها را که شلوغترین حوزههای اداری توکیو هستند بررسی می کنیم _ چیود (千代田区)، چو (中央区)، شینجوکو (新宿区)، شیبوی (渋谷区) و شیناگاوا (品川区).
هر مرحله را جداگانه توضیح می دهم. ابتدا تصویر کلی جمعآوری اولیه دادهها را بیان می کنم و سپس گامهای آتی شروع رقابت محلههای توکیو را مطرح خواهم کرد.
جمعیّت هدف
مشتریان یا افراد علاقمند به این پروژه کدامند؟
- پرسنلی که در حال حاضر در یک کسبوکار مشغول به کار و در عین حال به دنبال سرمایهگذاری در رستوران هستند. تحلیل پیش رو راهنمای جامعی خواهد بود جهت افتتاح یا توسعه رستورانهایی که در ساعات ناهار پذیرای تعداد زیادی از کارمندانِ شهرِ توکیو است.
- صاحبانِ کسبوکارهای آزاد که دوست دارند در کنار شغل خود رستوران هم داشته باشند. تحلیل پیش رو ضمن ارائه ایدههایی به این افراد، به آنها نشان میدهد که میزان سود رستوران چقدر است و فواید و مضرات آن چیست.
- افراد تازه فارغ التحصیل شده؛ این پژوهش به آنها کمک می کند تا به راحتی در نزدیکی محل کار خود رستورانی پیدا کنند که با قیمتی مناسب صبحانه و ناهار سرو می کند.
- دانشمندان تازهکارِ علم اطلاعات دانشمندان تازهکارِ علم اطلاعات Budding Data Scientists، یعنی افرادی که میخواهند پرکاربردترین راهبردهای اکتشافی تحلیل دادهها را به کار گیرند تا دادههای مورد نیاز خود را بدست آورند، آنها را تحلیل کنند و نهایتاً یافتههای خود را دراختیار دیگران قرار دهند.
2. آمادهسازی دادهها
2-1. جدول دادهکاوی حوزههای توکیو برگرفته از ویکیپدیا
در مرحله اول برای ایجاد چارچوب کلی دادهها از صفحه جدول دادهکاوی مناطق ویژه توکیو در ویکیپدیا استفاده نمودم. بدین منظور از درخواستها و کتابخانه Beautifulsoup4 برای ایجاد چارچوب دادههایی استفاده نمودم که شامل نامِ حوزههای 23 گانهی توکیو، وسعت، جمعیّت و بخشِ تراز اول آنها است. با دستور زیر شروع کردم:

پس از کمی دستکاری، چارچوبِ دادهها به شکل زیر درآمد:

2-2. دریافت مختصات بخشهای اصلی: Geopy Client
هدف بعدی دریافت مختصات بخشهای اصلی این حوزههای 23 گانه با استفاده از کلاس geocoder در Geopy client است. تکه-کدهای the code snippet زیرمورد استفاده قرار گرفتند:

همانطور که مشاهده میکنید مختصات چهار مورد (بونکیو، کوتو، اوتا، ادوگاوا)، به دلیل املای متفاوت نامِ منطقه در چارچوب دادهها، کاملاً اشتباه است (مثلاً Hongō — Hongo). لذا، بایستی این مختصات را با مقادیر بدست آمده در گوگل جایگزین می کردم. پس از دستکاری بیشتر دادهها با ابزارهای Panda، چارچوبِ دادهای منسجم زیر بدست آمد:

2-3. متوسطِ قیمت زمین در حوزههای اصلی توکیو: دادهکاوی تحت وِب
متوسط قیمت زمین در حوزههای 23 گانه فاکتوری دیگر است که به ما در انتخاب بهترین منطقه جهت افتتاح رستوران کمک میکند. این اطلاعات را از طریق دادهکاوی صفحه وبِ قیمت زمین در نواحی مختلف توکیو، در همان صفحه قبلی ویکیپدیا بدست آوردم. هدف این مقاله بررسی پنج مورد از شلوغترین نواحی شهری توکیو است که در بخش اول نام بردیم، لذا دادهها به صورت زیر مرتب شد:

2-4. دادههای موقعیتیاب Foursquare
دادههای Foursquare بسیار جامع است و موقعیت یاب اَپل، آبر، و غیره را تقویت میکند. در مسئله مورد بررسی این مقاله، به منظور بازیابی اطلاعاتِ مربوط به مکانهای مورد توجه مردم در پنج ناحیه اصلی توکیو، واسط برنامه نویسی کاربردی Foursquare را مورد استفاده قرار دادم. نقطههای بازگشتی متداول popular spots returned به بالاترین میزان تردد پیاده و در نتیجه به زمان فراخوانی بستگی دارند. لذا، در ازای ساعات مختلف روز، مناطق پرتردد متفاوتی خواهیم داشت. بازگشت فراخوان، یک فایل JSON را در اختیار ما قرار میدهد که باید آن را به چارچوب دادهها تبدیل کنیم. در این پژوهش برای هر یک از مناطق اصلی، 100 نقطه پرتردد با بُرد یک کیلومتر انتخاب نمودم. دادههای بدست آمده از فایل JSON که توسط Foursquare ارسال شده است را در زیر مشاهده میکنید:

3. تصویر سازی و اکتشاف دادهها
3-1. کتابخانه فولیوم و Leaflet Map
فولیوم نوعی کتابخانه پایتون است که می تواند با استفاده از دادههای مختصات، یک Leaflet Map تعاملی ایجاد کند. به دلیل اینکه مکان پرتردد مورد نظر من در پژوهش حاضر رستوران است، ابتدا چارچوب دادهها را به نحوی ایجاد نمودم که ستون ‘Venue_Category’ دادههای قبلی شامل واژه «رستوران» باشد. تکه-کد زیر را استفاده کردم:

گام بعدی به کارگیری این دادهها در ایجاد Leaflet Map تعاملی با فولیوم است تا از طریق آن توزیع پرترددترین رستورانهای این نواحی پنج گانه را مشاهده کنیم.

در تکه-کد دستوری بالا Leaflet Map تعاملی به صورت زیر است:

3-2. تحلیل اکتشافی دادهها:
همانطور که در تصویر زیر مشاهده می کنید، در صدر فهرست، 134 نوع جایگاه منحصربه فرد و رستورانِ سروِ رامنرستورانِ سروِ رامن Ramen Restaurant قرار دارد:

وقتِ ناهار رستورانهای رامن از جملهی پر بازدیدترین مکانهای پنج منطقهی اصلی توکیو محسوب میشوند.

پس از صرف ناهار خوشمزه، حالا وقت آن رسیدهاست تا بیشتر به اکتشاف دادهها بپردازیم. برای کسب اطلاعات بیشتر درباره مکانهای برتر هر کدام از این پنج منطقه انتخابی، مراحل زیر انجام شد:
- ایجاد چارچوب دادهها از طریق کدگذاری بردار تک بعدی pandas برای مقوله بندی مکانها.
- استفاده از دسته بندی Panda بر اساس ستون مناطق و محاسبه میانگین بردار تک بعدی کدگذاری شدهی رستهی مکانها.
- انتقال دادهها از گام دوم و مرتب سازی آنها به صورت نزولی.
تکه-کدهای زیر را در نظر بگیرید:

خروجی این کدها پنج مکان پرتردد درهریک از مناطق را نشان می دهد.

از میان چندین چارچوب دادهای که می بایستی برای تحلیل اکتشافی دادهها ایجاد می کردم، یک مورد را انتخاب نمودم تا نشان دهم کدام مناطق دارای پربازدیدترین رستورانها هستند و ناگاتاچو در حوزه چیودا با 56 رستوران پرتردد در صدر فهرست قرار گرفت.

همچنین میتوانیم به نمودارهای ویولنی رجوع کنیم که مبین دادههای رستهای هستند. برای نمایش توزیعِ چهار نوع رستوران اصلی در مناطق مختلف از کتابخانه seaborn استفاده نمودم.

پس از دریافت دیدگاهی نسبتاً کلی درباره انواع مختلف مکانها به ویژه رستورانها در پنج حوزه اصلی توکیو، زمان آن فرا میرسد که مناطق را با کمک K-Mean خوشه بندی کنیم.
- خوشهبندی منطقه
در آخر این پنج حوزه را بر اساس رستههای مکانها و با استفاده از خوشهبندی K-Mean خوشهبندی میکنیم. لذا، پیشبینیهای ما مبتنی بر آن دسته از شباهتهایِ بین رستههای مکان است که این مناطق بر اساس آنها خوشه بندی شده اند. برای این منظور تکه-کد زیر را مورد استفاده قرار دادم:

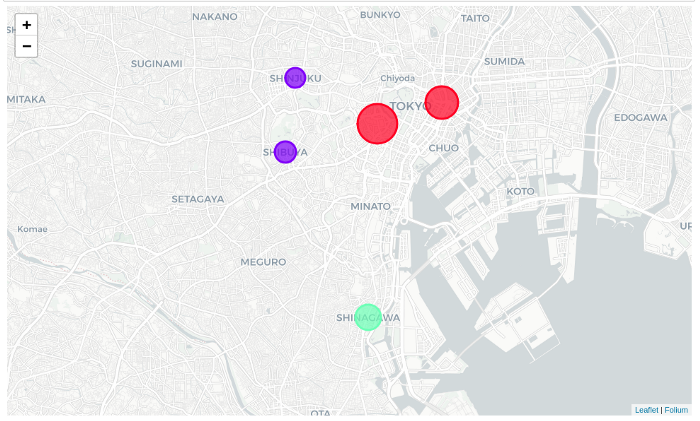
پنج حوزه اصلی توکیو بر اساس مکانهای پرتردد بدست آمده از دادههای Foursquare به سه خوشه تقسیم شدند.
همانند زیر میتوانیم با کمک کتابخانه Folium این سه خوشه اصلی را در یک leaflet map نمایش دهیم:
4. بحث و نتیجه گیری
به پایان تحلیل رسیدیم و اکنون باید نگاهی به پنج حوزهی اصلی توکیو بیاندازیم. به دلیل اینکه مسئله کسبوکار این پژوهش دربارهی فواید و مضرات افتتاح رستورانِ سرو ناهار در یکی از پُر رفت و آمدترین مناطق شهر بود، تحلیل اکتشافی دادهها عمدتاً مبتنی بر رستورانها صورت گرفت. برای تبیین واقع گرایانهی تحلیل دادهها، اطلاعات منابع مختلف از جمله ویکیپدیا، کتابخانههای پایتون مثل Geopy، و واسط برنامه نویسی کاربردی Foursquare را مورد استفاده قرار دادیم. در نتیجهی پژوهش حاضر نتایج زیر حاصل شد:
- رستورانهای رامن در صدر فهرست مکانهای پرتردد پنج منطقه انتخابی قرار داشتند.
- منطقه ناگاتاچو در حوزهی چیودا و منطقه نیهومباشی در حوزهی چو، مناطقی هستند که مکان پرتردد آنها رستوران است درحالی که در نواحی شیبویا وشینجوکو میکدهها، میخانهها، و کافی شاپها مکانهای پرتردد محسوب میشوند.
- بیشترین تعداد رستورانها و پرترددترین مکانها در منطقه ناگاتاچو واقع شده است در حالی که کمترین تعداد رستورانها در منطقه شیبویا هستند.
- به دلیل اینکه خوشهبندی مبتنی بر پرترددترین مکانهای هر منطقه صورت گرفتهاست، دو منطقهی شینجوکو و شیبویا در یک خوشه و دو منطقهی ناگاتاچو و نیهومباشی در یک خوشه قرار گرفتند. و به دلیل اینکه در منطقهی شیناگاوا خواربارفروشیها پرترددترین مکانها بودند، این منطقه از دو خوشه دیگر مجزا ماند.
بنابراین تحلیل، خواربارفروشیها پرترددترین مکانها در ناحیهی شیناگاوا هستند و فراوانی رستورانهای پرتردد در این ناحیه در مقایسه با دو خوشه دیگر بسیار کم است، لذا رستورانِ تازه تاسیسِ سِرو ناهار در ناحیهی شیناگاوا با کمترین رقابت مواجه خواهد شد. به علاوه، همانطور که در دادههای دادهکاوی شدهی تحت وب مشاهده نمودیم، میانگین قیمت زمین در منطقه شیناگاوا و نواحی اطراف آن در مقایسه با بخشهای نزدیکِ مرکزِ توکیو بسیار کمتر است. بنابراین، به طور قطع منطقهی شیناگاوا مکان بسیار مناسبی برای تاسیس رستورانی باکیفیت خواهد بود. ایراد تحلیل حاضر این است که خوشهبندی صرفاً مبتنی بر اطلاعات بدست آمده از دادههای Foursquare دربارهی پرترددترین مکانها صورت گرفته است. البته با در نظر گرفتن قیمت زمین، فاصله مکانها از نزدیکترین ایستگاه، تعداد مشتریان احتمالی، مزایا و معایب منطقه بندری شیناگاوا و نقش و تاثیرگذاری همه این موارد در کسبوکارهای این منطقه، مسلماً تحلیل پیش رو، تحلیل قطعی و متقن نیست. با این وجود، این تحلیل اطلاعات اولیه بسیار مهمی دربارهی امکان تاسیس رستوران در مناطق اصلی توکیو در اختیار ما قرار میدهد. به علاوه، لحاظ کردنِ تنها یک منطقهی اصلی در هر کدام از حوزههای توکیو، ایراد دیگر این تحلیل به شمار میرود. با در نظر گرفتنِ تمام نواحی تحت پوشش هر یک از این حوزههای پنج گانه میتوان تحلیلی واقع گرایانهتر بدست آورد. به علاوه، در صورت اتخاذ تکنیک خوشهبندی متفاوتی مثل DBSCAN به احتمال زیاد نتایج متفاوت نیز متفاوت خواهند شد.
5. نتیجه
در مجموع این پژوهش برداشتی کلی دربارهی پروژههای علم اطلاعات در دنیای واقعی در اختیار ما قرار داد. در این پروژه برای دادهکاوی دادهای تحت وب از برخی از کتابخانههای متداول پایتون استفاده نمودم، برای شناسایی مناطق اصلی توکیو واسط برنامه نویسی کاربردی Foursquare را به کار گرفتم و نتایج تقسیم بندی مناطق را با leaflet map فولیوم به نمایش گذاشتم. دربارهی قابلیت به کارگیری این گونه تحلیلها در مسئلههای کسبوکار دنیای واقعی نیز به تفضیل بحث کردیم. همچنین برخی از ایرادها و فرصتهای بهبود و اصلاح آنها را به منظور ارائه تصویری واقع گرایانهتر مطرح نمودیم. نهایتاً، به دلیل اینکه تحلیل این پژوهش بر امکانِ تاسیس رستوران در مناطقی متمرکز بود که بیشتر کارمندان رفتوآمد میکردند، برخی از نتایج با انتظارات من به عنوان فردی که 5 سال در توکیو زندگی کرده است منطبق است. من به ویژه به چشم خودم شاهد این هستم که در اطراف شینجوکو و شیبویا کافیشاپها، میکده و میخانهها و در اطرافِ نیهومباشی و ناگاتانچو رستورانهای ژاپنی مکانهایی پرتردد هستند. امیدواریم این گونه تحلیلها راهنمای اولیهای باشند برای افرادی که میخواهند با کمک علم اطلاعات چالشهای حقیقی بیشتری را مورد بررسی قرار دهند.
لینک کدها در Github