
راهنمای تصویری و توضیح گام به گام ترنسفرمرها
 تیم تحریریه
تیم تحریریه- ۲۴ تیر ۱۴۰۰
ترنسفرمرها بر دنیای پردازش زبان طبیعی غلبه کردهاند. این مدلهای خارقالعاده رکورد حل جدیدترین و بیشترین مسائل حوزهی NLP را در دست دارند. علاوه بر این در موارد گوناگون دیگری، همچون ترجمهی زبان ماشینی ، رباتهای سخنگوی مکالمهای ، و حتی موتورهای جستجو ی قویتر نیز کاربرد دارند. ترنسفرمرها در صدر مدلهای یادگیری عمیق قرار دارند و در این نوشتار میخواهیم با نحوهی کار آنها آشنا شویم و ببینیم چرا در مسائل توالی، عملکرد بهتری از سایر مدلها (همچون شبکههای عصبی بازگشتی Recurrent Neural Networks (RNN)، واحدهای بازگشتی دروازهای Gated Recurrent Network (GRU) یا حافظهی کوتاهمدت Long Short-Term Memory (LSTM)) دارند. احتمالاً تا کنون در مورد ترنسفرمرها ی معروف مثل BERT، GPT و GPT2 شنیدهاید. بحث خود را از مرور مقالهای شروع میکنیم که سرمنشأ این مسیر بوده است: «توجه: همهی آنچه نیاز دارید».
مکانیزم توجه
برای درک بهتر ترنسفرمرها ، ابتدا باید با مکانیزم توجه آشنا شویم. مکانیزم توجه امکان داشتن حافظهای طولانی را به ترنسفرمرها ارائه میدهد. یک مدل ترنسفرمر میتواند روی همهی توکن token هایی که از پیش تولید شدهاند «تمرکز» کند یا به عبارت دیگر، به آنها «توجه» کند.
برای مثال، فرض کنید میخواهیم با استفاده از یک ترنسفرمر مولد یک داستان علمی-تخیلی کوتاه بنویسیم. با استفاده از برنامهی Write with Transformer از کتابخانهی Hugging Face میتوان به راحتی این کار را انجام داد. مدل را با ورودی مدنظر راهاندازی میکنیم و مدل باقی کار را انجام میدهد.
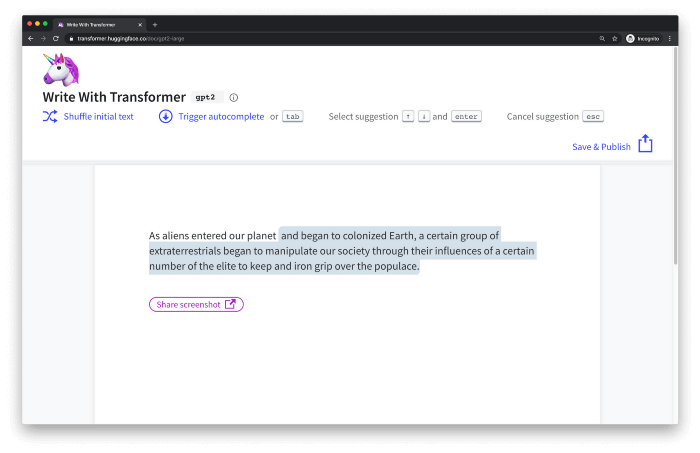
ورودی: وقتی آدمفضاییها وارد سیارهی ما شدند،
خروجی ترنسفرمر: و در آن ساکن شدند، گروهی از این موجودات فرازمینی با استفاده از نفوذ رهبران خود، شروع به کنترل جامعهی ما کردند تا انسانها را تحت سلطهی خود قرار دهند.
تولید چنین داستانی توسط یک مدل جالب است. هنگام تولید داستان، مدل میتواند روی کلمات مربوط به ورودی یعنی کلمهی تولیدشده تمرکز کند (یا به آن توجه کند). اینکه مدل باید روی چه کلماتی تمرکز کند، طی مرحلهی آموزش با فرآیند پسانتشار آموخته میشود.

شبکه های عصبی بازگشتی (RNN) نیز میتوانند به ورودیهای قبلی نگاه کنند. اما مزیت و قدرت مکانیزم توجه در این است که مثل RNNها مشکل حافظهی کوتاهمدت ندارد. RNNها پنجرهی مرجع کوتاهتری دارند، به همین دلیل اگر داستان (در مثال قبلی) طولانیتر شود، RNNها نمیتوانند به کلماتی که اوایل متن تولید شدهاند دسترسی داشته باشند. شبکههای GRU و LSTM گنجایش بیشتر و حافظهی بلندمدتتری نسبت به RNNها دارند، با این حال مشکلی که گفته شد همچنان در آنها به چشم میخورد. از نظر تئوری زمانی که منابع محاسباتی کافی را در اختیار داشته باشیم، مکانیزم توجه، پنجرهی مرجع بینهایتی خواهد داشت. بدین معنی که مدل میتواند هنگام تولید متن، از کل متن داستان استفاده کند.

مروری بر مقالهی «توجه: همهی آنچه نیاز دارید»
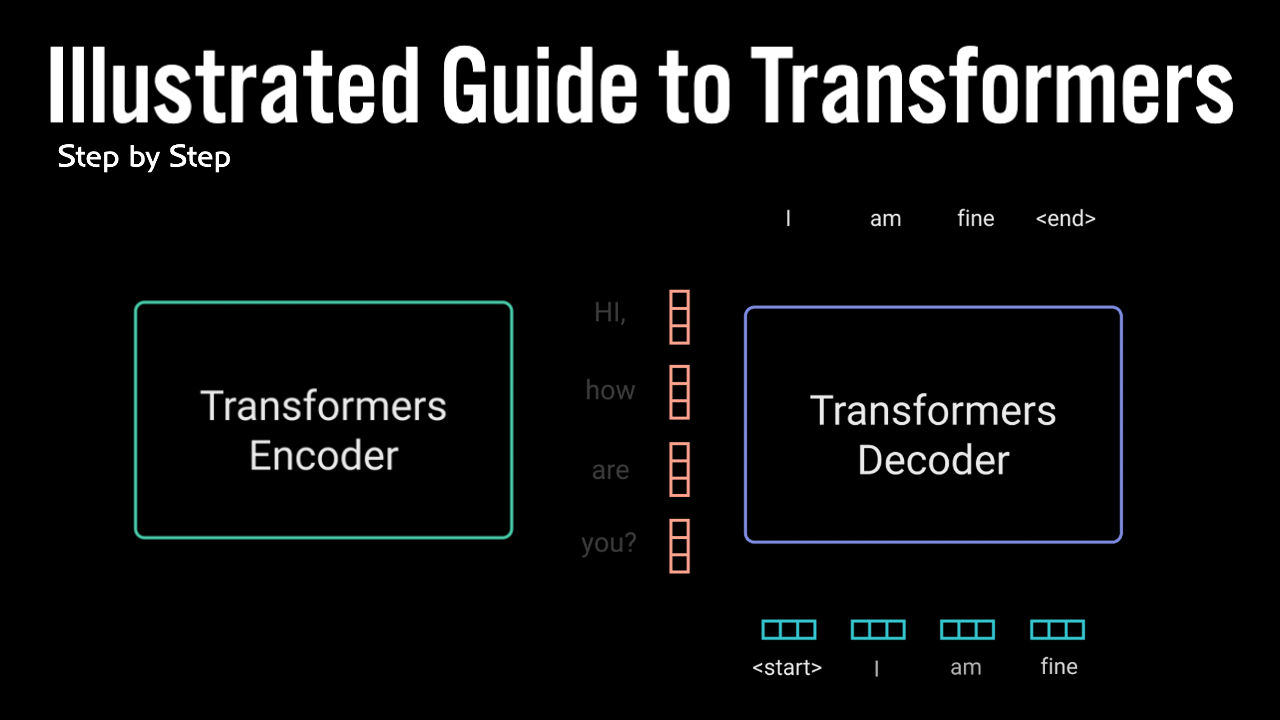
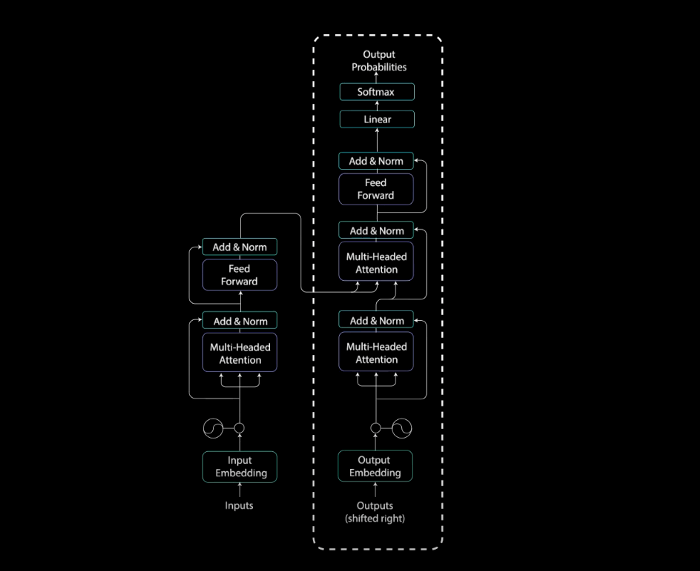
قدرت مکانیزم توجه در مقالهی «توجه: همهی آنچه نیاز دارید» نشان داده شد. نویسندگان این مقاله یک شبکهی عصبی نوین به نام ترنسفرمرها معرفی کردند که معماری آن مبتنی بر مکانیزم توجه و به شکل رمزگذار-رمزگشا است.
رمزگذار در سطح پیشرفته، توالی ورودی را به شکل یک بازنمایی انتزاعی پیوسته در میآورد؛ این بازنمایی همهی اطلاعاتی که از ورودی آموخته شده را در بردارد. سپس رمزگشا این بازنمایی پیوسته را میگیرد و در هرگام، همزمان با دریافت خروجیهای قبلی، یک خروجی واحد تولید میکند.
مقالهی مذکور مدل ترنسفرمر را روی یک مسئلهی ترجمهی ماشینی اجرا کرد. در این نوشتار قصد داریم نحوهی کار مدل را در یک ربات سخنگوی مکالمهای نشان دهیم.
ورودی: Hi, How are you?
خروجی ترنسفرمر: I am fine
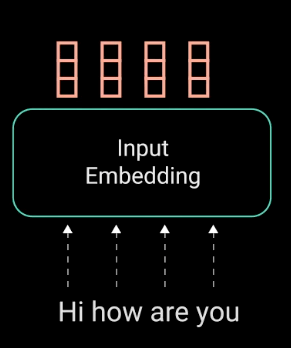
تعبیههای ورودی
گام اول، تغذیهی ورودیها به یک لایهی تعبیهی کلمه است. لایهی تعبیهی کلمه را میتوان یک جدول مرجع در نظر گرفت که میتوان در ازای هر کلمه، یک بازنمایی بردار آموخته شده از آن دریافت کرد. شبکههای عصبی از روی اعداد یاد میگیرند؛ به همین دلیل برای هر کلمه، یک بردار با مقادیر پیوسته ایجاد میشود؛ به عبارتی، این بردار نمایندهی آن کلمه است.
رمزگذاری موقعیتی
گام بعدی ورود اطلاعات موقعیتی به تعبیههاست. از آنجایی که رمزگذار ترنسفرمر مثل RNNها بازگشتی نیست، باید مقداری اطلاعات در مورد موقعیتها را به تعبیههای ورودی اضافه کنیم. این کار را میتوان از طریق رمزگذاری موقعیتی Positional encoding انجام داد. نویسندگان با استفاده از توابع سینوسی و کسینوسی یک راهکار هوشمندانه برای انجام این کار پیدا کردهاند:
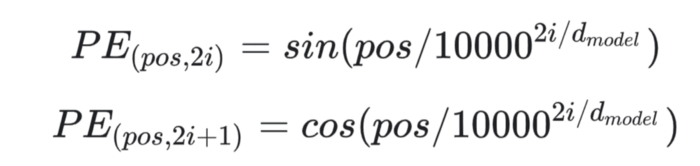
در این نوشتار وارد جزئیات ریاضیاتی رمزگذاری موقعیتی نخواهیم شد و تنها به مقدمات و مطالب پایه میپردازیم. برای شاخصهای فرد روی بردار ورودی، با استفاده از تابع کسینوسی یک بردار ایجاد میکنیم. برای شاخصهای زوج هم با استفاده از تابع سینوسی یک بردار ایجاد میکنیم. سپس این بردارها را به تعبیههای ورودی مربوط به آنها اضافه میکنیم. بدین ترتیب شبکه اطلاعاتی در مورد موقعیت هر بردار به دست میآورد. تابع کسینوسی و سینوسی کنار یکدیگر به کار میروند؛ زیرا خواص خطی دارند که مدل به آسانی میتواند روی آنها تمرکز کند.
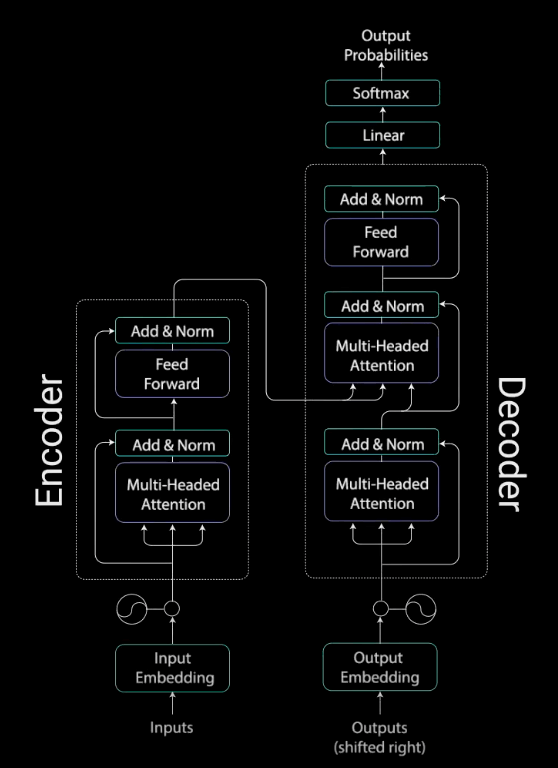
لایهی رمزگذار
کار لایههای رمزگذار، تبدیل همهی توالیهای ورودی به یک بازنمایی انتزاعی پیوسته است که اطلاعات آموختهشده در مورد کل آن توالی را در برمیگیرد. این لایه دو ماژول فرعی دارد: توجه چندشاخه Multi-headed attention، و شبکهی کاملاً متصل Fully connected network (که بعد از توجه چندشاخه قرار دارد). علاوه بر این، اطراف هر کدام از لایههای فرعی، اتصالات residual و بعد از آنها، یک یک نرمالسازی لایه Layer normalization وجود دارد.
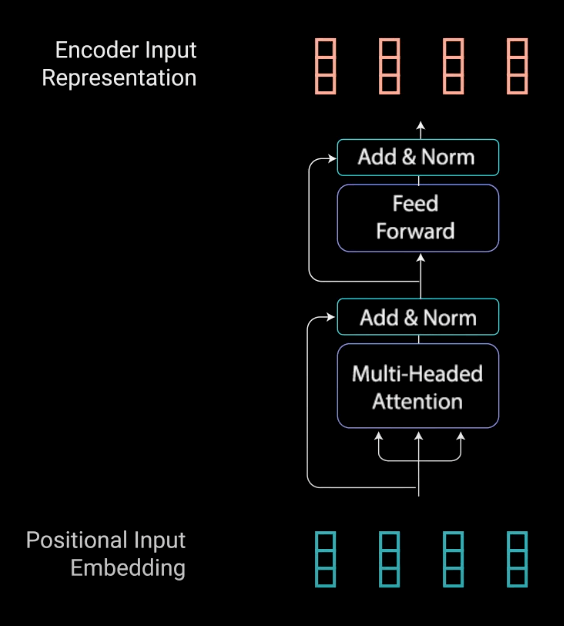
برای درک بهتر آنچه گفته شد بهتر است ابتدا نگاهی به ماژول توجه چندشاخه بیاندازیم.
توجه چندشاخه
توجه چندشاخه در رمزگذار یک مکانیزم توجه خاص به نام خودتوجه را اجرا میکند. خودتوجه، مدلها را قادر میسازد هر کلمه از ورودی را به کلمات دیگر مرتبط کنند. در مثالی که پیشتر استفاده کردیم، ممکن است مدل ما کلمهی you را با How و are مرتبط کند. شاید هم مدل بیاموزد کلماتی که در این ساختار قرار گرفتهاند، یک سؤال را تشکیل میدهند و بنابراین پاسخ مناسبی ارائه دهد.
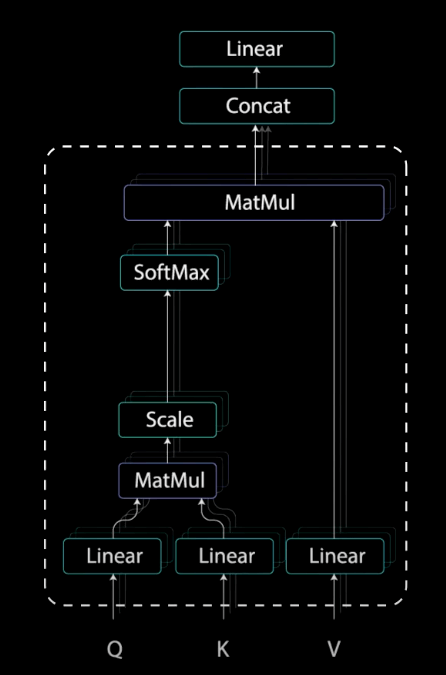
بردارهای کوئری، کلید، و مقدار
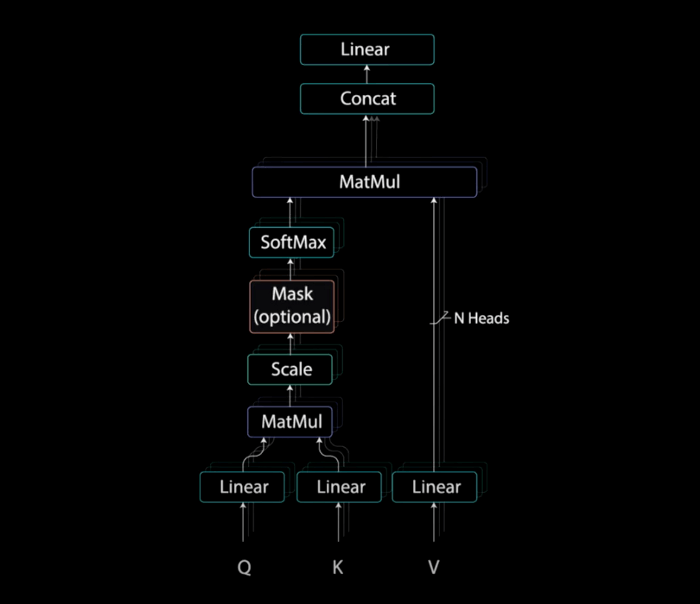
برای اجرای خودتوجهی، ورودی را به سه لایهی مجزا اما کاملاً متصل تغذیه میکنیم تا بردارهای کوئری ، کلید و مقدار را به دست آوریم.
برای اینکه با این مفاهیم بیشتر آشنا شویم، از توضیحات وبسایت Stack Exchange استفاده میکنم:
«مفاهیم کوئری، کلید و مقدار از سیستمهای بازیابی اطلاعات Retrieval systems نشأت گرفتهاند. برای مثال، وقتی میخواهید یک ویدئو در یوتیوب جستجو کنید، یک کوئری مینویسید، موتور جستجو کوئری شما را با یک مجموعه از کلیدها (عناوین ویدئو، توضیح ویدئو و مواردی از این دست) مرتبط میکند؛ این کلیدها با ویدئوهای خاصی (داوطلب) از دیتابیس مرتبط هستند. بدین ترتیب مرتبطترین ویدئوها (مقادیر) به شما ارائه میشوند.»
ضرب ماتریسی کوئری و کلید
بعد از اینکه بردارهای کوئری، کلید و مقدار به یک لایهی خطی تغذیه شدند، بین کوئریها و کلیدها ضرب ماتریسی نقطهای انجام میشود تا ماتریس نمرات به دست آید.
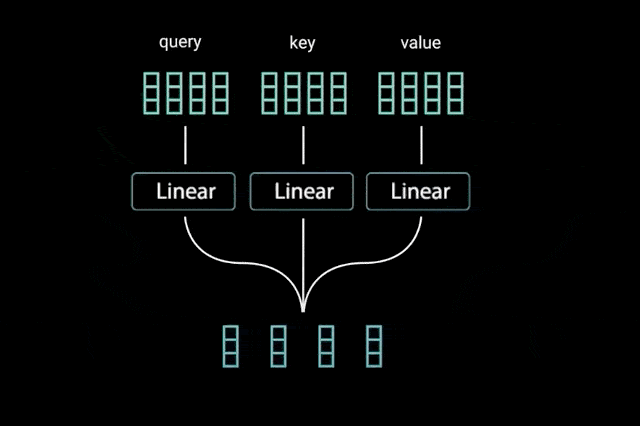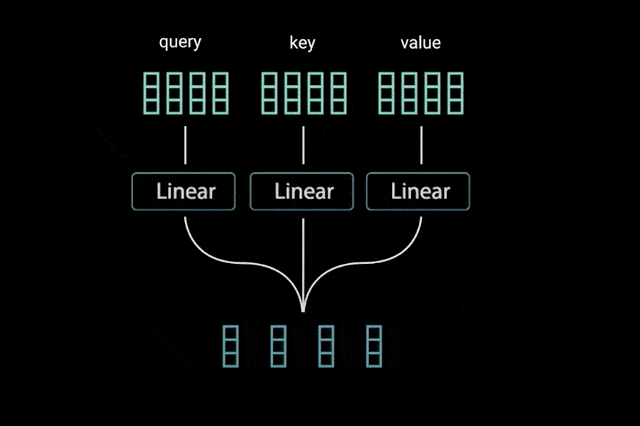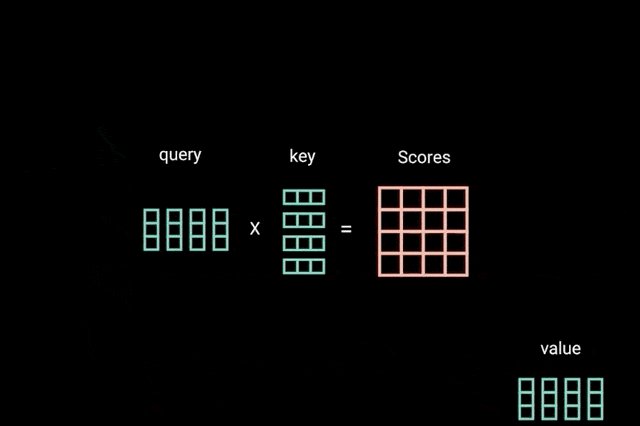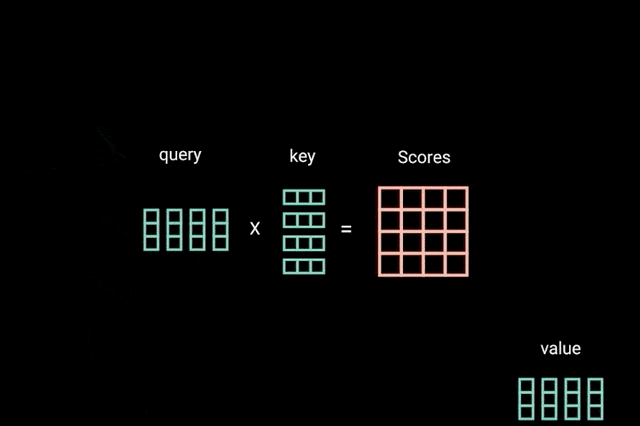
ماتریس نمرات تعیین میکند به یک کلمه، نسبت به کلمات دیگر، چقدر توجه شود. بدین ترتیب هر کلمه یک نمره خواهد داشت که به سایر کلمات آن گام زمانی مرتبط میشود. هرچه این نمره بالاتر باشد، میزان توجه بیشتر خواهد بود. کوئریها بدین شیوه به کلیدها متصل (مرتبط) میشوند.

کوچک کردن نمرات توجه
نمرات بر جذر بُعد کوئری و کلید تقسیم شده و بدین طریق کوچک میشوند. این کار باعث میشود گرادیانها ثبات بیشتری داشته باشند، زیرا ضرب مقادیر (مقادیر بالا) میتواند منجر به بزرگ شدن بیش از حد نمرات شود.
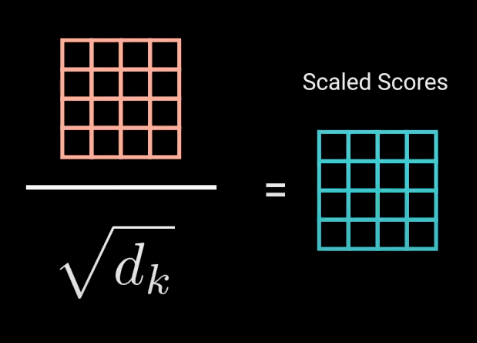
محاسبهی تابع Softmax مقادیر کوچک شده
در گام بعد، تابع softmax نمرات کوچک شده محاسبه میشود تا وزنهای توجه به دست آید. این وزنها، به شکل مقادیر احتمال و بین 0 تا 1 هستند. با محاسبهی Softmax، نمرات بالا، افزایش یافته و نمرات پایین کاهش مییابند. در نتیجهی این امر، مدل با اطمینان بیشتری میداند روی چه کلماتی تمرکز کند.

ضرب خروجی softmax در بردار مقدار
ضرایب توجه را در بردار مقدار ضرب میکنیم تا یک بردار خروجی به دست آوریم. مقادیر بالای softmax نشاندهندهی کلماتی هستند که مدل باید آنها را بیاموزد. نمرات پایین کلمات نامرتبط را حذف میکنند. سپس خروجی این گام، برای پردازش وارد یک لایهی خطی میشود.
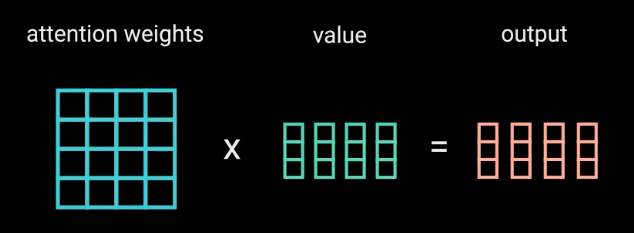
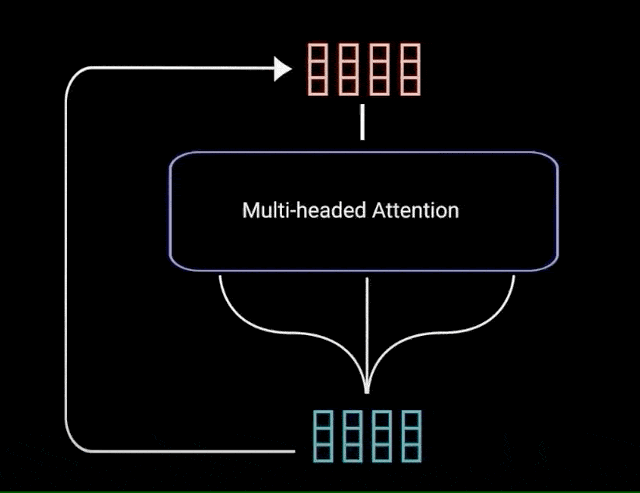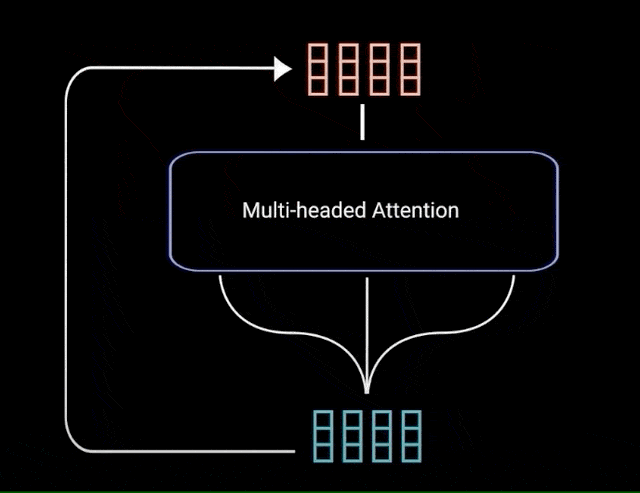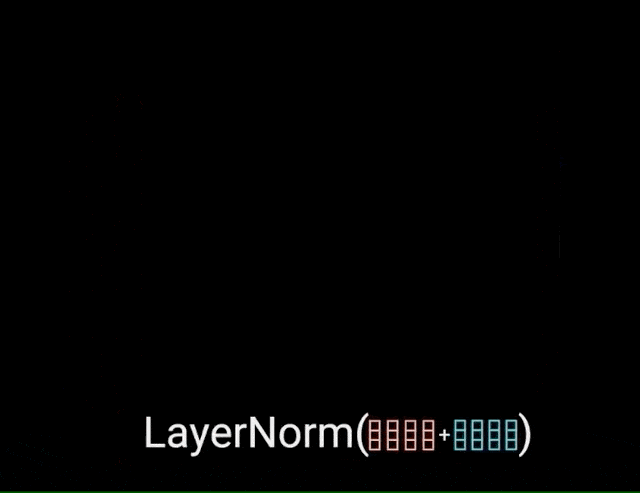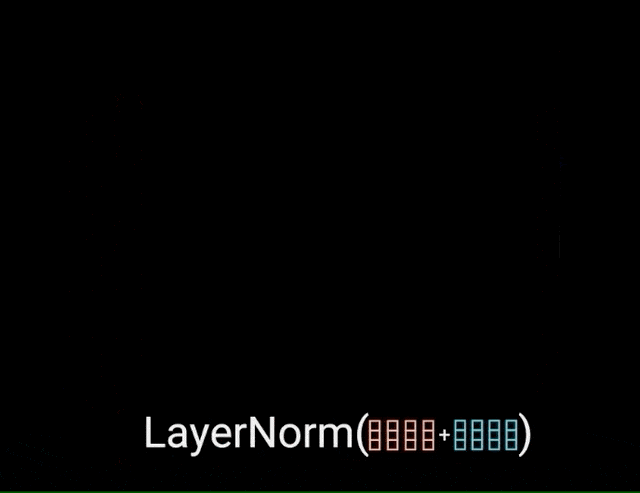
محاسبهی توجه چندشاخه
برای اینکه مسئله را به محاسبهی توجه چندشاخه تبدیل کنیم، باید قبل اجرای توجه چندشاخه، کوئری، کلید و مقدار را به N بردار تقسیم (تجزیه) کنیم. بردارهای حاصل به صورت مجزا وارد فرآیند خودتوجه میشوند. هر فرآیند خودتوجه یک شاخه خوانده میشود. هر شاخه یک بردار خروجی تولید میکند. بردارها قبل از ورود به لایهی خطی آخر، در یک بردار ادغام میشوند. به صورت نظری گفته میشود هر شاخه یک چیز متفاوت را میآموزد و بدین ترتیب مدل رمزگذار توان بیشتری در بازنمایی خواهد داشت.

پس تا اینجا دریافتیم توجه چندشاخه یک ماژول در شبکهی ترنسفرمرها است که وزنهای توجه را برای ورودی محاسبه میکند، و یک بردار خروجی با اطلاعات رمزگذاریشده (در مورد اینکه هر کلمه نسبت به کلمات دیگر چقدر باید مورد توجه قرار گیرد) تولید میکند.
اتصالات residual، نرمالسازی لایه و شبکهی پیشخور
بردار خروجی توجه چندشاخه به تعبیهی ورودی موقعیتی اصلی اضافه میشود؛ به این اتصال residual گفته میشود. خروجی اتصال residual تحت نرمالسازی لایه قرار میگیرد.
خروجی نرمالسازیشدهی residual وارد یک شبکهی پیشخور نقطهای میشود تا پردازشهای بعدی روی آن انجام گیرد. شبکهی پیشخور نقطهای متشکل از چند لایهی خطی است که بین آنها تابع فعالسازی ReLU وجود دارد. خروجی این لایهها به ورودی شبکهی پیشخور نقطهای اضافه و سپس نرمالسازی میشود.
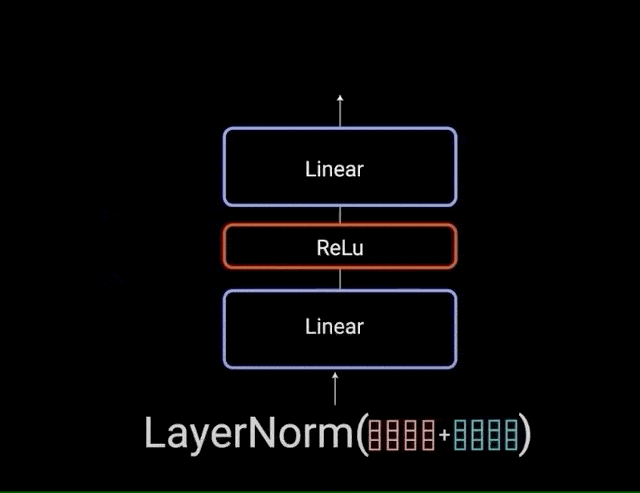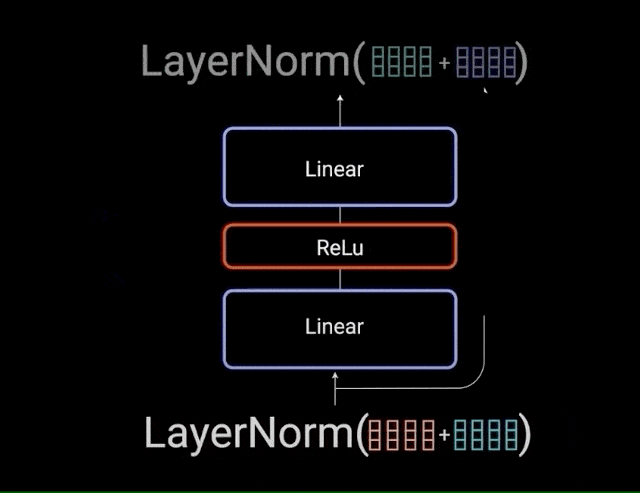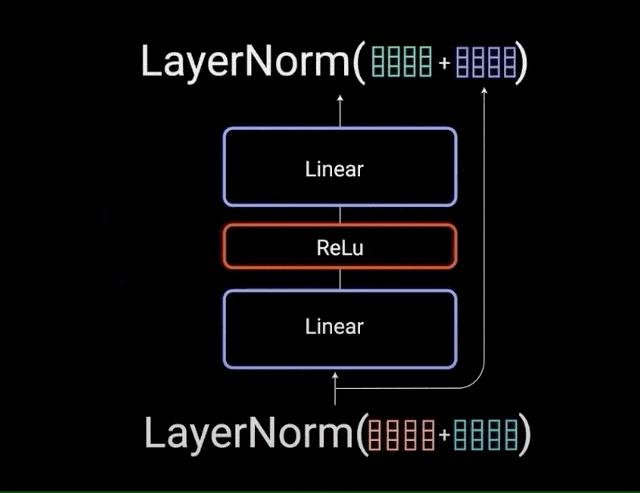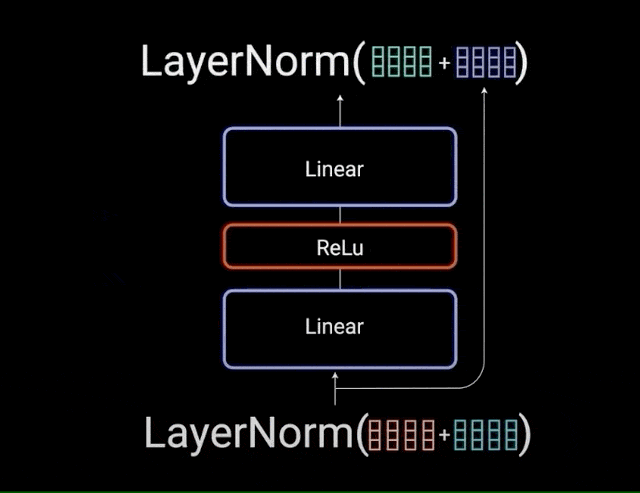
پس به طور خلاصه، اتصالات residual به آموزش شبکه کمک میکنند، زیرا باعث میشوند گرادیانها مستقیماً در شبکهها جریان داشته باشند. نرمالسازی لایهها برای به ثبات رساندن شبکه به کار میروند و منجر به کاهش چشمگیر زمان آموزش میشوند. لایهی پیشخور نقطهای برای مصورسازی خروجیهای توجه استفاده میشود و یک بازنمایی غنیتر ایجاد میکند.
خلاصهی قسمت رمزگذار
تا اینجا لایهی رمزگذار را توضیح دادیم. همهی این عملیاتها برای رمزگذاری ورودی و ایجاد یک بازنمایی پیوسته از اطلاعات توجه انجام میشوند. این فرآیند به رمزگشا کمک میکند هنگام فرآیند رمزگشایی روی کلمات مناسب ورودی تمرکز کند. رمزگشا را میتوان N بار انباشته (Stack) کرد تا اطلاعات قابل رمزگشایی شوند. طی رمزگشایی، هر لایه فرصت یادگیری بازنماییهای مختلف توجه را دارد و بدین ترتیب قدرت پیشبینی شبکهی ترنسفرمرها افزایش مییابد.
لایهی رمزگشا
کار رمزگشا تولید توالیهای متنی است. رمزگشا نیز مانند رمزگذار یک لایهی فرعی و دو لایهی توجه چندشاخه، یک لایهی پیشخور نقطهای، اتصالات Residual و نرمالسازی لایه (بعد از هر لایهی فرعی) دارد. این لایههای فرعی رفتاری مشابه با لایههای موجود در رمزگذار دارند. اما لایههای توجه چندشاخه کارکرد متفاوتی دارند. در رمزگشا یک لایهی خطی وجود دارد که به عنوان کلسیفایر عمل میکند و یک Softmax که احتمالات مربوط به کلمات را محاسبه میکند.
رمزگشا اتو رگرسیو است. با یک توکن ابتدایی شروع میکند و لیستی از خروجیهای قبلی را به عنوان ورودی میگیرد. خروجی رمزگشا، همچون خروجی رمزگذار شامل اطلاعات توجه حاصل از ورودی است. وقتی یک توکن به عنوان خروجی تولید شود، رمزگشا فرآیند خود را متوقف میکند.
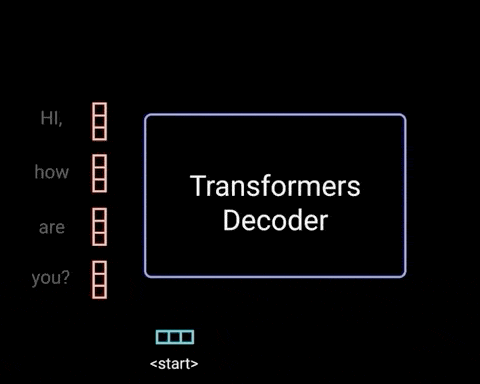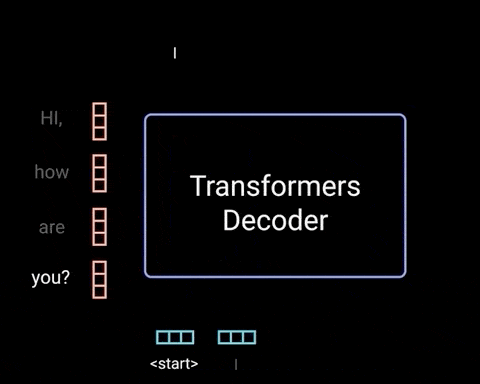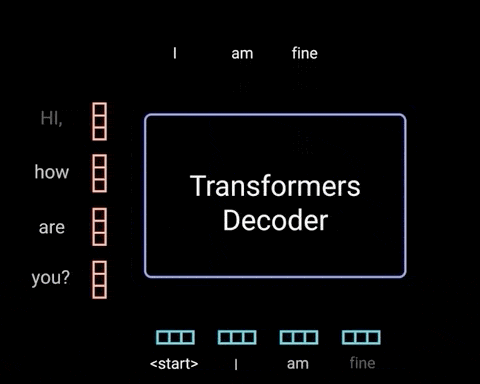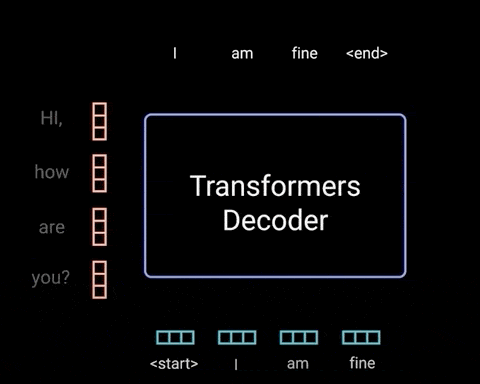
حال گامهای رمزگشایی را با هم مرور میکنیم.
تعبیههای ورودی و رمزگذاری موقعیتی در رمزگشا
آغاز کار رمزگشا تا حد زیادی شبیه به رمزگذار است. ورودی، وارد لایهی تعبیه و رمزگذاری موقعیتی میشود تا تعبیههای موقعیتی تولید شوند. تعبیههای موقعیتی به اولین لایهی توجه چندشاخه تغذیه میشوند؛ این لایه نمرات توجه را برای ورودی رمزگشا محاسبه میکند.
اولین لایهی توجه چندشاخه در رمزگشا
لایهی توجه چندشاخه در رمزگشا کمی متفاوتتر عمل میکند. از آنجایی که رمزگشا خودبازگشتی (Auto-regressive) است و توالی را کلمه به کلمه تولید میکند، باید از توجه آن به توکنهای آینده جلوگیری کرد. برای مثال، هنگام محاسبهی نمرات توجه برای کلمهی am، مدل نباید به کلمهی fine دسترسی داشته باشد، چون این کلمه در قسمت بعدی توالی تولید میشود. کلمهی am تنها باید به خودش و کلمات قبلش دسترسی داشته باشد. این نکته برای کلمات دیگر هم صدق میکند، یعنی هر کلمه فقط میتواند به کلمات قبل خودش توجه کند.

برای جلوگیری از محاسبهی نمرات توجه کلمات بعدی به یک راهکار نیاز داریم. به این راهکار، ماسکگذاری گفته میشود. برای اینکه رمزگشا نتواند به توکنهای آینده نگاه کند، مکانیزمی به نام Look ahead mask اجرا میکنیم. این ماسک قبل از محاسبهی softmax و بعد از مقیاسبندی نمرات اجرا میشود.
Look Ahead Mask
این ماسک، ماتریسی هماندازه با نمرات توجه است که با مقادیر 0 و -inf (منفی بینهایت) پر شده است. وقتی ماسک را به نمرات توجه مقیاسدهیشده اضافه میکنیم، ماتریسی از نمرات به دست میآوریم که مثلث بالا-سمت راست آن از مقادیر -inf (منفی بینهایت) پر شده است.

در نتیجهی این ماسکگذاری، هنگام محاسبهی تابع softmax برای نمرات ماسکشده، مقادیر -inf برابر صفر قرار داده می شود و نمرات توجه را برای توکنهای بعدی صفر میکنند. همانطور که در تصویر پایین میبینید، ماتریس نمرات توجه برای کلمهی am و همهی کلمات قبلش عددی را نشان میدهد، اما برای کلمهی بعدی یعنی fine صفر است. در نتیجهی این امر، مدل میداند که نباید به آن کلمه توجهی کند.
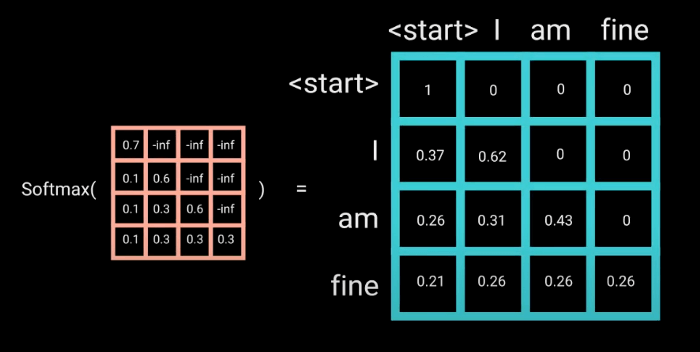
این ماسکگذاری تنها تفاوت بین محاسبهی نمرات توجه در اولین و دومین لایهی توجه چندشاخه است. این لایه چندین شاخه دارد؛ قبل از اینکه این شاخهها ادغام شده و برای پردازش وارد یک لایهی خطی دیگر شوند، ماسک روی آنها اجرا میشود. بنابراین خروجی اولین لایهی توجه چندشاخه، یک بردار ماسکشده از اطلاعات است؛ اطلاعاتی که به مدل میگوید چطور باید ورودی رمزگشا را مورد «توجه» قرار دهد.
دومین لایهی توجه چندشاخه و لایهی پیشخور نقطهای در رمزگشا
خروجی لایه ی اول توجه چندشاخه مقادیر و خروجی لایهی دوم توجه چندشاخه، کوئریها و کلیدها هستند. این فرآیند ورودی رمزگذار را با ورودی رمزگشا تطبیق میدهد و بدین طریق رمزگشا را قادر میسازد تصمیم بگیرد کدام ورودی رمزگذار مرتبط است و باید مورد توجه قرار گیرد. خروجی لایهی دوم توجه چندشاخه وارد یک لایهی پیشخور نقطهای میشود تا پردازش بیشتری روی آن انجام شود.
رده بندی خطی و softmax نهایی برای احتمالات خروجی
خروجی آخرین لایهی پیشخور نقطهای، وارد آخرین لایهی خطی (که به عنوان یک کلسیفایر عمل میکند) میشود. اندازهی خروجی برای رده بند مطابق با تعداد کلاسها است؛ اگر 10000 کلاس برای 10000 کلمه داشته باشید، اندازهی خروجی کلسیفایر نیز 10000 خواهد بود. بعد از آن، خروجی کلسیفایر وارد لایهی softmax میشود که مقادیر احتمال (بین 0 تا 1) تولید میکند. شاخص بالاترین نمرهی احتمال نشاندهندهی کلمهی پیشبینی شده خواهد بود.
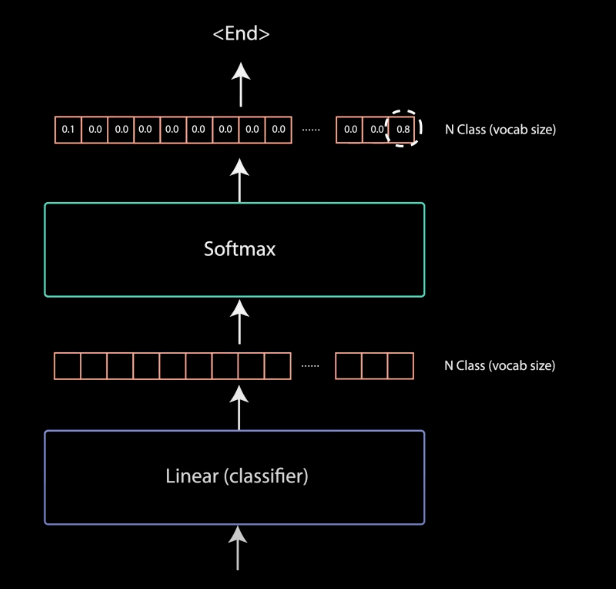
رمزگشا خروجی را میگیرد، به لیست ورودیهای رمزگشا اضافه میکند و به رمزگشایی ادامه میدهد تا زمانی که یک توکن پیشبینی شود. بالاترین احتمال پیشبینی شده نشاندهندهی کلاسی است که نهایتاً توکن به آن اختصاص مییابد.
رمزگشا را میتوان تا N لایه انباشت (Stack)؛ به صورتی که ورودی هر لایه، خروجی رمزگذار و لایههای قبلش باشد. با انباشت این لایهها، مدل میآموزد ترکیبهای مختلفی از توجه را از شاخهها استخراج کرده و روی آنها تمرکز کند و بدین طریق قدرت پیشبینی خود را افزایش دهد.
سخن پایانی
سازوکارهای ترنسفرمرها را در این مقاله مرور کردیم. ترنسفرمرها از مکانیزم توجه استفاده میکنند تا پیشبینیهای بهتری تولید کنند. شبکههای عصبی بازگشتی (RNN) نیز سعی دارند همین کار را انجام دهند، اما مشکل حافظهی کوتاهمدت دارند. ترنسفرمرها در این مسئله، به خصوص در تولید یا رمزگذاری توالیهای طولانی، عملکرد بهتری از خود نشان میدهند. حوزهی NLP با تکیه بر معماری ترنسفرمرها، توانسته است به نتایج خوب و بیسابقهای دست یابد.




