

تغییر مدل مو به وسیله فضای پنهان شبکه عصبی مولد برای انجام ویرایشهای معنایی
 تیم تحریریه
تیم تحریریه- ۱۰ اسفند ۱۴۰۱
پیشرفتهایی که اخیراً در انواع شبکه عصبی مولد حاصل شده، تأثیرات شگرفی بر کیفیت و وضوح تصاویر، به ویژه در حوزه تغییر و انتقال سبک Style transfer، داشته است. مشوق اصلی ما برای نگارش مقاله پیشرو، موفقیتهای اخیر StyleGAN بوده است. در مدل StyleGAN، تغییرات تصادفی در تصاویر ایجاد شده که تشخیص آنها از تصاویر اصلی دشوار است، ترکیب میشود. مقاله پیشرو، حول موضوع مدل مو است.
مدل مو نقش بسیار تعیین کنندهای در ظاهر افراد دارد و به نوعی میتواند معرف شخصیت و سبک شخصی افراد باشد. یکی از اصلیترین روشهای انتخاب مدل موی مناسب، امتحان کردن مدلهای مختلف مو است. بنابراین، امتحان کردن یک مدل موی جدید، به صورت مجازی، در سیستمهای بینایی ماشین، میتواند کمکهای زیادی به افراد در انتخاب مدل موی مناسب بکند.
شرح مسئله
- ورودی: تصویری از چهر ه افراد
- خروجی: تصاویری از همان چهره با مدل موهای مختلف
- متد اصلی: فضای پنهان Latent space کشف و بررسی GAN
کشف و بررسی فضای پنهان GAN
هدف GAN این است که از طریق آموزش تخاصمی Adversarial training، نگاشت غیرخطی از توزیع پنهان به دادههای واقعی را یاد بگیرد.
اغلب ارتباط میان فضای پنهان و ویژگیهای معنایی Semantic attributes ناشناخته است. برای مثال، کد پنهان چگونه راجع به ویژگیهای مدل موی ایجاد شده– موی چتری، رنگ مو و غیره- تصمیم گیری میکند؟ علاوه بر این، تشخیص اینکه این ویژگیها بر هم تأثیر دارند یا خیر دشوار است.
هدف از انجام پروژه پیشرو این است که مشخص کنیم چگونه یک و یا چندین ویژگی مدل مو، در فضای پنهانِ مدلهای آموزش دیده GAN، از جمله PG GAN و StyleGAN، رمزگذاری میشوند.
نویسندگان مقاله InterfaceGAN معتقدند «در فضای پنهان برای تمامی واحدهای معنایی باینری ( برای مثال آقایان و بانوان)، ابرصفحه hyperplaneهایی وجود دارد که در نقش مرزهای جداکننده separation boundary را ایفا میکنند. در این مقاله ما تصمیم داریم با اتکا به همین بینش و با اعمال تبدیل خطی، ویژگیها را تفکیک کنیم.
پیشزمینه
PG GAN
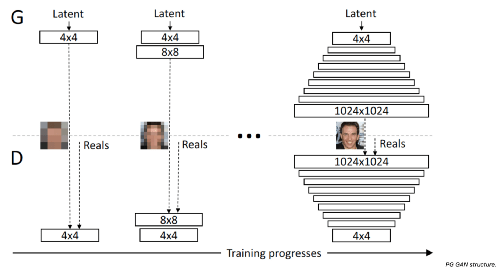
اولین مدلی که در این مقاله به بررسی آن خواهیم پرداخت، PG GAN است. این مدل از سلسله مراتبی از مولدها generators و متمایزکنندهها discriminators تشکیل شده که وضوح لایههای آنها رو به افزایش است. انواع شبکه عصبی مولد و متمایزکنندههای این مدل، تصاویر مقیاس بزرگ با وضوح پایین را میگیرند و تصاویری با وضوح بالا به عنوان خروجی ارائه میدهند.
در این مدل میتوان در طول فرایند آموزش، تمامی مولدها و متمایزکنندهها را آموزش داد و همزمان با پیشروی فرایند آموزش، لایههایی را به صورت تدریجی اضافه کرد. از اتصالات عبوری میان ورودیها و خروجیهای یک لایه نیز میتوان برای آموزش مجدد خروجیهای لایه قبلی استفاده کرد.
PG GAN موفق به حل برخی مشکلاتی شده که مدلهای قدیمیتر GAN قادر به حل آنها نبودهاند.
هرچه وضوح تصویر بالاتر باشد، تشخیص تصویر ایجادشده از تصویر واقعی آسانتر است و به همین دلیل ایجاد تصاویری با وضوح بالا برای مدلهای قدیمیتر GAN دشوار است. در این حالت ممکن است مقدار گرادیانها gradients افزایش یابد و شبکه های عصبی را وادار کنند با سرعت کمتری همگرا شود. علاوه بر این، تصاویر بزرگتر به بستههایی با اندازه کوچکتر نیاز دارند و همین امر موجب ناپایداری فرایند آموزش میشود.
این ساختار سلسله مراتبی تلاش میکند از طریق آموزش کلی به جزئی Coarse to fine training، برخی مشکلات GAN را حل کند.
- لایههایی که وضوح پایینتری دارند کلاسهای اطلاعاتی و حالتهای کمتری در خود جای میدهند و به همین دلیل آموزش آنها آسانتر است.
- به منظور افزایش سرعت آموزش، اکثر تکرارها در وضوح پایینتر انجام میشود. در این حالت، در مدت زمان کمتری میتوان به نتایج مشابهی دست پیدا کرد.
StyleGAN
مدل دیگری که برای انجام این پژوهش از آن استفاده میکنیم، StyleGAN است.
StyleGAN ابتدا به روشی غیرخطی، z یا همان کد پنهان ورودی، را به w، کد پنهان میانی، تبدیل میکند.
منظور از z، فضای کد پنهان اصلی است و نشاندهنده چگالی احتمال probability density دادههای آموزشی است که گاهی باعث پیچیدگی غیرقابل اجتناب می شود. w فضای پنهان میانی است و توسط نگاشت پیوسته بخش محور
piecewise continuous mapping از z آموزش میبیند.
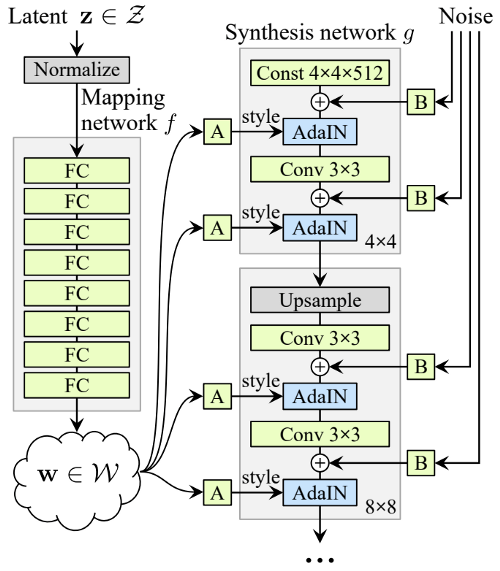
در شبکه سنتز
- تبدیلهای هندسی آفین Affine transformation که w یا همان کد پنهان میانی را به سبکهای y (که به لحاظ مکانی ثابت میباشند spatially invariant) تبدیل میکنند، به A آموزش داده میشود.
- B به ازای هر یک از فاکتورهای مقیاسبندی کانال، به ورودی نویز آموزش داده میشود.
- منظور از AdaIN، نرمالسازی تطبیقی نمونه Adaptive instance normalization است و ابتدا ویژگیهای x را به وسیله سبکهای y مقیاسبندی و بایاس میکند و سپس این ویژگیها را نرمالسازی میکند.
شبکه سنتز synthesis نیز از ساختاری سلسله مراتبی پیروی میکند و هر لایه پیچشی convolution آن، سبک تصاویر را با وضوح متفاوتی تنظیم میکند. این ویژگی شبکه سنتز، میزان تأثیرگذاری ویژگیهای تصویر در مقیاسهای مختلف را کنترل میکند.
در ادامه، نحوه ویرایش معنایی تصاویر را با یکدیگر بررسی خواهیم کرد.
مراحل مختلف ویرایش معنایی تصویر
مطابق مراحل زیر میتوانید تصویری انتخاب کنید، کد پنهان آن را تخمین بزنید، ویرایشهای معنایی را بر روی آن انجام دهید و مدل موی مورد نظر خود را بر روی آن بگذارید.

مرحله اول – برآورد کد پنهان
برای انجام ویرایش معنایی ابتدا باید تصویر مورد نظر را در فضای پنهان StyleGAN پیدا کنیم. سؤالی که ممکن است برای شما پیش بیاید این است که در یک تصویر ورودی، اگر z را به وسیله مولد ارسال کنیم، چگونه میتوانیم بردار پنهان z را پیدا کنیم و آیا میتوانیم همان تصویر ورودی را به عنوان خروجی داشته باشیم؟
برای انجام این کار میتوانیم بردار ویژگی را بهینه کنیم؛ بردار ویژگی، ویژگیهای بسیاری از آنچه درون تصویر است را در خود جای داده است.
برای برآورد اولیه کد پنهان در StyleGAN، ابتدا تصویر ورودی را به یک Residual Network از پیش آموزش داده شده ارسال میکنیم. سپس این برآورد را به شبکه عصبی مولد ارسال میکنیم. ارسال این برآورد به شبکه عصبی مولد نمونه اولیهای از تصویر ورودی اصلی به ما میدهد. برای استخراج ویژگیها نیز میتوانیم یک کلاسیفایر تصویر که از قبل آموزش دیده را بر روی این تصویر اعمال کنیم. در ضمن میتوانیم عملیات استخراج ویژگی را بر روی تصویر ورودی نیز انجام دهیم.
در مرحله بعد، در فضای ویژگی، گرادیان کاهشی gradient descent را اعمال میکنیم و تابع هزینه L2 بردارهای ویژگی را به حداقل میرسانیم و برآورد کد پنهان را به روز رسانی میکنیم (پیکان قرمز). این شیوه اعمال گردایان کاهشی بر روی بردارهای معنایی ویژگی تا حدودی بهتر از اعمال گرادیان کاهش بر روی تابع هزینه پیکسل است، چراکه استفاده مستقیم از بهینهسازی سطح دوم در فضای پیکسل موجب میشود در بهنیه محلی Local optima بدی قرار بگیریم.

اکنون با استفاده از این رویکرد میتوانیم هرگونه تصویری را در فضای پنهان StyleGAN پیدا کنیم. در مقابل نمونههایی از تصاویر ورودی و نمایشهای کد پنهان آنها نشان داده شده است، به نظر شما هم این تصاویر شباهت زیادی به هم دارند؟

مرحله دوم – ویرایش معنایی به همراه مرز
منظور از «ویرایش معنایی»، ویرایش یک تصویر و اعمال ویژگی هدف بر روی آن است، به نحوی که در سایر اطلاعات و ویژگیها تا جایی که ممکن است، تغییری ایجاد نشود؛ در مقاله Interface GAN نیز اینچنین تعریفی از ویرایش معنایی ارائه شده است.
پیش از اینکه فرایند ویرایش را آغاز کنیم، باید مرزهای خاصی که میتوانند ویژگیهای باینری را در فضای پنهان جدا کنند، مشخص کنیم. هر یک از مرزها با یک مدل موی مشخص مطابقت دارند.
در پژوهش مقابل این دسته از ویژگیهای مربوط به مو را بررسی خواهیم کرد:
- مدل موی مجعد/ لخت، چتری
- رنگ مشکلی/ بلوند/ قهوهای/ خاکستری
- رستنگاه مو پسروی رستنگاه مو
- موی صورت سبیل، خط ریش
چگونه میتوانیم مرزها را پیدا کنیم؟ ابتدا باید عملیات جداسازی فضای پنهان را انجام دهیم. نویسندگان مقاله InterFaceGAN روشی عالی برای انجام این کار معرفی کردهاند.
با فرض اینکه در فضای پنهان برای هر ویژگی باینری، یک ابرصفحه وجود دارد، به نحوی که تمامی نمونههایی که در یک بخش وجود دارند، ویژگیهای یکسانی داشته باشند، میتوانیم SVM خطی را که مسئول هر یک از ویژگیها است، آموزش دهیم. هدف ما از انجام این کار این است که این ابرصفحهها را در فضای پنهان 512 بعدی StyleGAN پیدا کنیم.

برای پیدا کردن ابرصفحه به دادههای جفتی این ویژگی نیاز داریم؛ داده جفتی شامل کد پنهان و امتیاز است. یکی از روشهای پیدا کردن ابرصفحه این است که تصاویری از چهرهها پیدا کنیم که این ویژگی در آنها واضحتر است و به صورت دستی آنها را با امتیازات 0 و 1 برچسبگذاری کنیم. ما به صورت آزمایشی این روش را به کار بستیم و 50 تصویر را برچسبگذاری کردیم تا مطمئن شویم که میتوان مرزها را پیدا کرد. کمی بعد تصمیم گرفتیم از کلاسیفایرهایی که از قبل با دیتاست بزرگی (CelebA) از ویژگیهای مو آموزش دیدهاند و به همراه StyleGAN ارائه میشوند، استفاده کنیم.

ما برای ایجاد 20000 جفتداده از کد پنهان و امتیاز، از 10 کلاسیفایر منطبق با ده ویژگی، استفاده کردیم. ما با استفاده از جفتدادههای کد پنهان و امتیازات، ویژگیهای مو را به SVMهای خطی و مستقل آموزش دادیم و سپس آنها را بر مبنای مجموعه اعتبارسنجی محک زدیم و در نهایت نرخ دقت آنها به حدود 80 درصد رسید.

در قدم بعد موقعیت هر یک از تصاویر ورودی را در فضای پنهان StyleGAN پیدا میکنیم و سپس برای انجام ویرایش معنایی آن را در همان جهت حرکت میدهیم.

پس از پیدا کردن ابرصفحه متعلق به هر یک از ویژگیها، از بردار قائم آن به عنوان جهت استفاده میکنیم. همراستا با این بردار به طور مداوم تغییراتی مطابق با ویژگی مقصد در چهرههای خروجی ایجاد میشود. در تصویر فوق، کد پنهان تصویر جوانی لئوناردو دیکاپریو را در فضای StyleGAN پیدا کردیم. بعد یک بردار قائم به سوی ابرصفحه موی چتری کشیدیم و موقعیت کد پنهان را در همان جهت حرکت دادیم. در نتیجه سکانسی شبیهسازیشده از دیکاپریو بدون موی چتری، با موی چتری کم و با موی چتری زیاد ایجاد شد.

و در آخر به معرفی مرز شرطی Conditional Boundary خواهیم پرداخت که در مقاله InterfaceGAN نیز معرفی شده است. معمولاً بسیاری از ویژگیها میتوانند با هم همبستگی داشته باشند. برای مثل یکی از دلایل پسروی رستنگاه مو افزایش سن است و موی مجعد بیشتر در چهره بانوان مشاهده میشود و موی صورت از جمله سبیل و خط ریش فقط در چهره آقایان مشاهده میشود. به همین دلیل ضروری است ویژگی مقصد را از ویژگیهایی که با آنها همبستگی دارد، جدا کنیم.

همانگونه که در تصویر فوق نشان داده شده است، اگر دو ابرصفحه با بردارهای قائم n1 و n2 داشته باشیم و همراستا با جهت ترسیم n1 حرکت کند (جابهجا کردن (n1) n2)، n2 میتواند ویژگی 1 را بدون اینکه بر ویژگی 2 تأثیر بگذارد، تغییر دهد. همانگونه که در مقاله InterfaceGAN به آن اشاره شده است، این روش دستکاری شرطی conditional manipulation نامیده میشود.
نتایج حاصل از آزمایشات ما نشان میدهد که ویژگی پسروی رستنگاه مو با ویژگی لبخند زدن همبستگی دارند: به بیانی دیگر، چهره خروجی پسروی رستنگاه مو اغلب کمی دهان خود را باز میکرد و لبخند میزد. تصور ما این است که پسروی رستنگاه مو و ویژگی لبخند زدن به این دلیل با هم همبستگی دارند که در دیتاست، افرادی که رستنگاه موی آنها در حال پسروی است، مهربانتر به نظر میرسند و لبخند به لب دارند. لذا اگر بخواهیم چهرهای خروجی ایجاد کنیم که رستنگاه موی وی در حال پسروی باشد اما لبخند به لب نداشته باشد، میتوانیم در صفحهای که به وسیله جهت شرطیشده (لبخند) ساخته شده است، ویژگی لبخند را از جهت اولیه (پسروی رستنگاه مو) حذف کنیم. در تصویر مقابل چهره جورج کلونی با و بدون مرز شرطی نشان داده شده است.

یافتهها
نتایج حاصل از آزمایشات ما نشان میدهد که بسیاری از ویژگیها در فضای پنهان با یکدیگر همبستگی دارند. برای مثال، در هنگام ویرایش موها، چهره فرد با توجه به میزان موی سر، پیرتر یا جوانتر میشود.

البته تمامی نتایج حاصل از آزمایشات ما عالی نیست. چنانچه نتوانیم مطابق مراحل ذکر شده، خروجی قابل قبولی ایجاد کنیم، میتوانیم مطابق با شرایط، مرز را بهینه کنیم. اگر اعوجاج distortion در تصویر ورودی چشمگیر باشد، میتوانیم ویژگیای که بیشترین شباهت را به این اعوجاج دارد، پیدا کنیم و آن را به عنوان ویژگی شرطی به ویژگی اولیه اعمال کنیم. در هنگام ویرایش موهای صورت، میتوانیم آن را به طور شرطی با ویژگی لبخند زدن مرتبط کنیم. در نتیجه دهان چهرهای که به عنوان خروجی دریافت میکنیم، باز نخواهد بود.

اما برخی مواقع تغییرات فاحشی در چهرهها ایجاد میشود و در نتیجه خروجی دریافت میکنیم که طبیعی نیست. اعوجاج در برخی چهرههای خروجی بیش از اندازه است، یا چهره خروجی، ظاهر خون آشامها را به خود میگیرد و یا ویژگی مورد نظر ما بر روی چهره خروجی اعمال نمیشود.

علاوه بر این متوجه شدیم این شبکه عصبی مولد بایاس است. از آنجاییکه دیتاست مورد استفاده برای آموزش شبکه عصبی مولد حاوی تصاویری از چهره افراد واقعی است، ویژگیهای مختص به هر جنسیت (مرد و زن) فقط در چهرههای مربوط به همان جنسیت ظاهر میشود. برای مثال افزودن سبیل به چهره یک خانم موجب میشود که فرد ظاهری مردانه داشته باشد، اما باز هم ممکن است چهره خروجی کمی سبیل داشته باشد و یا اصلاً هیچ سبیلی نداشته باشد.

نتیجهگیری
یافتن مرز ابرصفحه در فضای پنهان امکان ویرایش ویژگیهای چهره افراد را برای ما فراهم میکند. همانگونه که در مقاله InterfaceGAN نیز توضیح داده شده است، میتوانیم یکی از ویژگیها را به همراه ویژگی اولیه به عنوان ویژگی شرطی انتخاب کنیم. علاوه بر این، از آنجاییکه برخی ویژگیها بر یکدیگر تأثیر متقابل دارند، ممکن است همزمان با ویرایش یکی از ویژگیهای چهره، ویژگیهای دیگر نیز تغییر کنند. به عقیده ما، با استفاده از کلاسیفایرهای پیشرفتهتر میتوان به صورت همزمان دو ویژگی را کنترل کرد و مرز ابرصفحه را مشخص کرد. البته توجه داشته باشید که این مدل نمیتواند چهره یک خانم را با ویژگیهای مردانه ایجاد کند و بالعکس. به عقیده ما اگر از یک دیتاست به خصوص برای آموزش شبکه عصبی مولد استفاده کنیم، میتوانیم این مشکل را حل کنیم.





