

تفاوت استانداردسازی و نرمالسازی در چیست؟
 تیم تحریریه
تیم تحریریه- ۱۷ فروردین ۱۴۰۱
این مطلب با هدف توضیح دو مفهوم بسیار گیج کننده در مهندسی ویژگی، یعنی استانداردسازی Standardization و نرمالسازی Normalization نوشتهشده است. این دو مفهوم بسیار شبیه به هم هستند و در اکثر مواقع بسیاری از افراد قادر به تشخیص تفاوت و موارد استفادهی آنها نیستند. ولی جای نگرانی نیست توضیحات این وبنوشت به تشخیص تفاوتهای میان این دو و شناخت موارد استفادهی آنها کمک میکند.
|| مسابقه هوش مصنوعی (مهلت ثبتنام تا 16 آذر 1401)
عدم تشخیص دو مفهوم استانداردسازی و نرمالسازی کاملاً طبیعی است. تا چند ماه قبل من هم به خوبی تفاوت این دو مفهوم را نمی دانستم به همین دلیل به خوبی درک میکنم که چطور ممکن است دچار سردرگمی و استیصال شوید زیرا منابع مناسب و کافی برای توضیح این دو مفهوم در دسترس نیست.
پیش از توضیح تفاوتهای «استانداردسازی» و «نرمالسازی» اجازه بدهید کمی درباره مسائل زیربنایی توضیح دهم.
هر دو مفهوم استانداردسازی و نرمالسازی بخشی از مهندسی ویژگی هستند که خود زیر مجموعه علم داده است.
مسیر پردازشی علم داده چیست؟
شکی نیست که در دنیای امروزه «علم داده» بر سر زبانها است.همه درباره علم داده صحبت می کنند، اما …
مهندسی ویژگی به معنای به کارگیری دانش و تخصص در جهت بهینهسازی ویژگیها است به نحوی که پس از آن این ویژگیها به راحتی و به بهترین نحو به مدل آموزش داده شوند.
هر دو مفهوم استاندارسازی و نرمالسازی در مقیاسبندی مورد استفاده قرار میگیرند، لیکن در نحوهی کارکرد و موارد استفاده با هم تفاوت دارند (منظور از مقیاسبندی قرار دادنِ ویژگی در دامنهای خاص به جای قرار داشتن در دامنهای وسیع است. قرار داشتن در دامنهی بزرگ فهمیدن دادهها را برای مدل دشوار میسازد). همین اطلاعات برای شناخت بافت مهندسی ویژگی کافی است. اکنون مستقیماً به شرح موضوعات اصلی میپردازم.
[irp posts=”8191″]استانداردسازی
منظور از استانداردسازی نرمال نمودن توزیع دادهها است. استانداردسازی میانگین دادهها را به صفر و واریانس را به 1 تبدیل میکند. هر چه مقادیر داده به سمت بینهایت کشیده شود، واریانس دادهها به 1 نزدیکتر میشود.
برای مثال، دادههای زیر را در نظر بگیرید:

پس از اجرای عملیات استانداردسازی بر روی دادهها، به صورت زیر تغییر خواهند نمود:

فرمول استانداردسازی!

در تصویر بالا، x برابر است با مقدار داده، μ برابر است با میانگین دادهها، و σ برابراست با واریانس دادهها.
اجرای دستور استانداردسازی بر روی دادهها!
برای اجرای دستور استانداردسازی، کدنویسی را انجام دهید.
نرمالسازی
منظور از نرمال سازی تبدیل دادهها به دامنهی [0 و1] است. هر کدام از دادههای ثبت شده در دیتاست به بازهای بین صفر و یک تغییر خواهد نمود. این امر باعث میشود دادهها تحت دامنهی کوتاهتری قرار گیرد و مدل بهتر آموزش ببیند.
برای مثال، دادههای زیر را در نظر بگیرید:

پس از اجرای نرمالسازی، دادهها به شرح زیر تغییر میکنند:

فرمول نرمالسازی!
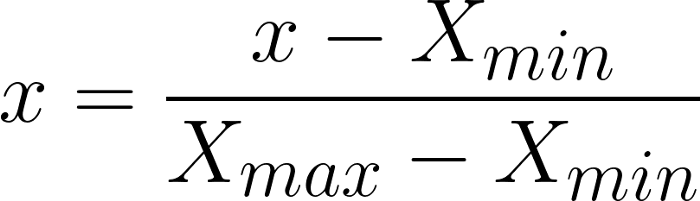
در این فرمول Xmin و Xmax به ترتیب برابر با مقادیر بیشینه و کمینه دادهها در دیتاست هستند و معادل دادهی خاص در دیتاست است.
اجرای دستور نرمالسازی بر روی دادهها!
به منظور اجرای دستور نرمالسازی، کدنویسی را انجام دهید. توجه داشته باشید که به دلیل لحاظ کردن هر نقطه داده در محاسبه مقادیر مطرح شده برای کتابخانههای «مقیاس بندیاستاندارد» و «مقیاسبندی بیشینه-کمینه»، هردو مفهوم به شدت به دادههای پرتِ موجود در دیتاست حساس هستند. مقادیر محاسبه شده در استانداردسازی و نرمال سازی داده ها مورد استفاده قرا می گیرد.
[irp posts=”11015″]موارد کاربرد استانداردسازی
- استانداردسازی در اکثر مدلهای یادگیری ماشین مورد استفاده قرار میگیرد و طبق تجربیات دیگران و خودم، نسبت به نرمالسازی عملکرد بهتری دارد.
- در هر شرایطی که نیازی به مقیاس بندی ویژگیها در دامنهی صفر و یک نیست.
- به دلیل اینکه توزیع دادهها را به توزیع نرمال تبدیل میکند، در اکثر مواقع بهترین شیوه در یادگیری ماشین است. توزیع نرمال توزیع مطلوب است.
موارد استفاده نرمالسازی
- در هر شرایطی که باید دامنهی ویژگیها ببین صفر و یک باشد. برای مثال، در دادههای تصویری به دلیل اینکه دامنه پیکسلهای رنگی بین صفر تا 255 (در مجموع 256 رنگ) است، نرمالسازی بهتر از استانداردسازی است.
- موارد مختلفی به چشم میخورد که دامنهی صفر و یک مد نظر باشند، در این شرایط شیوهی دلخواه/بهتر مقیاس بندی بیشینه-کمینه است.
امیدوارم مقاله حاضر تمام مسائل و توضیحات مرتبط با این موضوع را به تفصیل بیان کرده باشد و جای هیچگونه ابهامی نباشد.





