تفاوت یادگیری بانظارت و بدون نظارت
 مریم کاملان
مریم کاملان- ۱۹ مهر ۱۴۰۴
در دنیای وسیع هوش مصنوعی، دو مسیر اصلی برای «یادگیری» ماشینها وجود دارد: یادگیری با نظارت (Supervised Learning) و یادگیری بدون نظارت.(Unsupervised Learning) این دو رویکرد، پایهایترین مفاهیمی هستند که اساس بسیاری از شگفتیهای تکنولوژی امروزی را تشکیل میدهند.
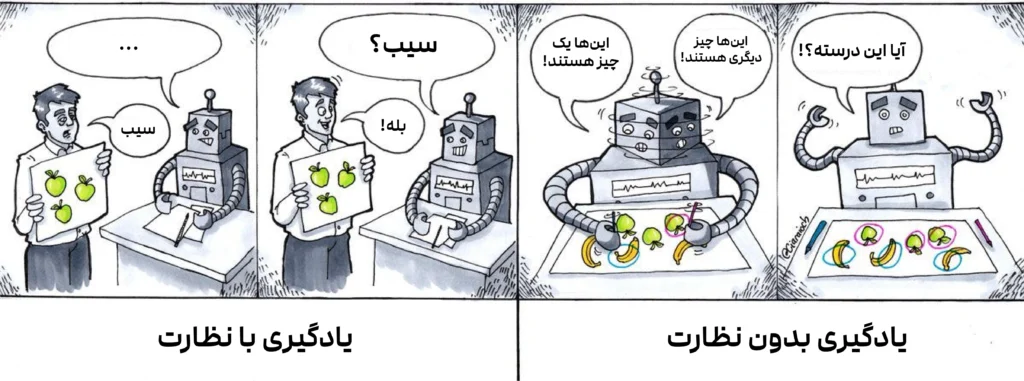
تصور کنید میخواهید به یک ربات، تفاوت بین سیب و پرتقال را آموزش دهید.
- در یادگیری با نظارت، شما مانند یک معلم عمل میکنید. صدها عکس از سیب و پرتقال به ربات نشان میدهید و روی هر کدام برچسب میزنید: «این سیب است»، «این پرتقال است». ربات با دیدن این دادههای برچسبدار، الگوها را یاد میگیرد تا در آینده بتواند بهتنهایی سیب را از پرتقال تشخیص دهد.
- اما در یادگیری بدون نظارت، شما هیچ برچسبی ارائه نمیدهید. فقط یک سبد بزرگ و مخلوط از سیب و پرتقال را جلوی ربات میگذارید و از او میخواهید که خودش میوهها را بر اساس شباهتهایشان (مانند رنگ، شکل یا اندازه) دستهبندی کند. ربات بدون هیچ راهنمایی قبلی، الگوهای پنهان را کشف کرده و دو گروه مجزا ایجاد میکند.
این مثال ساده، تفاوت اصلی این دو رویکرد را نشان میدهد: یادگیری با نظارت بر اساس دادههای برچسبدار و با هدف پیشبینی عمل میکند، در حالی که یادگیری بدون نظارت با دادههای بدون برچسب سر و کار دارد و هدفش کشف ساختارها و الگوهای پنهان است.
چرا دانستن این تفاوت اهمیت دارد؟
شاید در نگاه اول، این دستهبندی یک بحث فنی و آکادمیک به نظر برسد، اما در حقیقت درک این تفاوت برای هر علاقهمند به علم و فناوری یک ضرورت است. چرا؟
- رمزگشایی از جادوی هوش مصنوعی: وقتیمیشنوید که هوش مصنوعی قادر به تشخیص سرطان از روی تصاویر پزشکی است (یادگیری با نظارت) یا یک فروشگاه آنلاین محصولاتی را دقیقاً مطابق سلیقه شما پیشنهاد میدهد (یادگیری بدون نظارت)، دانستن این مفاهیم به شما کمک میکند تا بفهمید پشت پرده این جادو چه منطقی نهفته است.
- فهم محدودیتها و تواناییها: این دو رویکرد، قابلیتها و محدودیتهای خاص خود را دارند. برای مثال، یادگیری با نظارت به حجم عظیمی از دادههای برچسبدار نیاز دارد که تهیه آنها اغلب پرهزینه و زمانبر است. درک این موضوع به شما دیدی واقعبینانه نسبت به چالشهای پیش روی پروژههای هوش مصنوعی میدهد.
- اساس نوآوریهای آینده: بسیاری از پیشرفتهای بزرگ آینده در هوش مصنوعی، مانند توسعه مدلهای زبانی پیچیدهتر یا سیستمهای تحلیلی هوشمند، بر پایه ترکیبی از این دو رویکرد و روشهای نوینتری مانند یادگیری خودنظارتی (Self Supervised Learning) یا پیشروتری مانند یادگیری تقویتی (Reinforcement Learning) بنا خواهد شد. دانستن این اصول، کلید درک تحولات آینده این حوزه است.

پس یادگیری با نظارت و بدون نظارت فقط دو اصطلاح فنی نیستند؛ آنها دو فلسفه متفاوت برای آموزش ماشینها هستند که درکشان دید شما را نسبت به دنیای هوش مصنوعی عمیقتر و دقیقتر میکند. در ادامه این مقاله، با جزئیات بیشتری به مقایسه این دو غول دنیای یادگیری ماشین خواهیم پرداخت.
یادگیری با نظارت: آموزش به ماشین با یک «معلم» دیجیتال
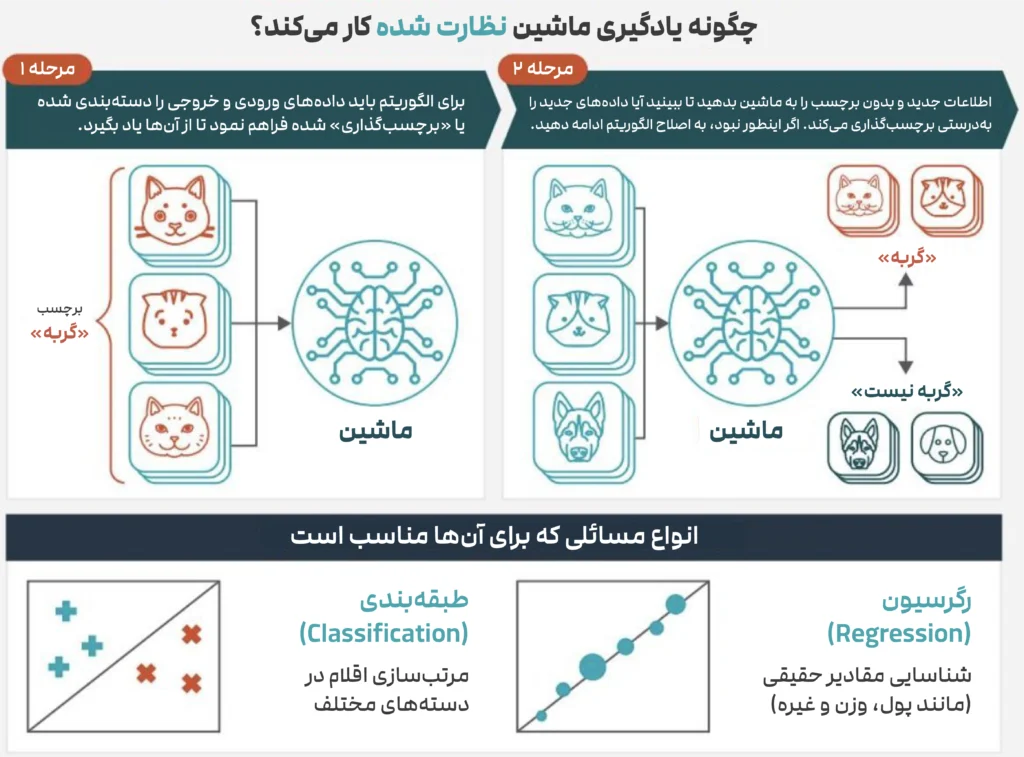
یادگیری با نظارت، همانطور که از نامش پیداست، روشی است که در آن یک الگوریتم هوش مصنوعی تحت «نظارت» انسان آموزش میبیند. در این رویکرد ما مجموعهای از دادههای ورودی را به همراه پاسخهای صحیح آنها به ماشین میدهیم و از او میخواهیم که رابطه بین ورودی و خروجی را یاد بگیرد.
هدف نهایی این است که مدل آنقدر هوشمند شود که بتواند برای دادههای جدیدی که تا به حال ندیده، خروجی صحیح را پیشبینی کند. این دقیقاً مانند دانشآموزی است که با حل صدها مسئله ریاضی (دادههای ورودی) به همراه پاسخهایشان (برچسبها)، یاد میگیرد که چگونه مسائل جدید را حل کند.
ما هر روز در حال استفاده از نتایج این نوع یادگیری هستیم؛
- تشخیص بیماری قبل از بروز علائم: الگوریتمهای هوش مصنوعی امروزه میتوانند با مشاهده تصاویر شبکیه چشم، بیماری دیابت را با دقتی بالاتر از برخی متخصصان تشخیص دهند، حتی قبل از آنکه بیمار علائم جدی را تجربه کند. در اینجا، هزاران تصویر چشم (ورودی) به همراه برچسب «سالم» یا «بیمار» (خروجی) به مدل داده شده تا الگوهای میکروسکوپی بیماری را یاد بگیرد.
- نجات حساب بانکی در نیمهشب: آیا تا به حال برایتان پیش آمده که بانکتان یک تراکنش مشکوک را مسدود کرده و به شما پیامک دهد؟ این سیستمهای تشخیص تقلب از یادگیری با نظارت استفاده میکنند. آنها با تحلیل میلیونها تراکنش (ورودی) که به عنوان «قانونی» یا «کلاهبرداری» (برچسب) مشخص شدهاند، یاد میگیرند که الگوهای مشکوک را در لحظه شناسایی کرده و از پول شما محافظت کنند.
- پیشبینی قیمت سفر: چرا قیمت یک بلیت هواپیما یا درخواست یک تاکسی اینترنتی در ساعات مختلف روز تغییر میکند؟ این قیمتگذاری پویا توسط مدلهای یادگیری با نظارت انجام میشود. این مدلها با تحلیل دادههای تاریخی مانند زمان، آبوهوا، ترافیک و تقاضا (ورودیها) و قیمتهای نهایی (برچسبها)، یاد میگیرند که بهترین قیمت را در هر لحظه پیشبینی کنند.
مهمترین الگوریتمهای یادگیری با نظارت
الگوریتمهای زیادی در این حوزه وجود دارند، اما در اینجا با چند مورد از معروفترین آنها آشنا میشویم:
- رگرسیون خطی:(Linear Regression) یکی از سادهترین و قدیمیترین الگوریتمهاست. کار آن پیدا کردن یک خط مستقیم برای پیشبینی مقادیر پیوسته است. مثلاً پیشبینی قیمت یک خانه بر اساس متراژ آن.
- رگرسیون لجستیک :(Logistic Regression) برخلاف اسمش، این الگوریتم برای طبقهبندی (Classification)استفاده میشود؛ یعنی پیشبینی یک خروجی دو حالته (بله/خیر، سالم/بیمار). فیلتر اسپم ایمیل شما یک مثال کلاسیک است که یاد میگیرد یک ایمیل را در دسته «اسپم» یا «غیراسپم» قرار دهد.
- ماشین بردار پشتیبان :(Support Vector Machine – SVM) این الگوریتم یک طبقهبند بسیار قدرتمند است. تصور کنید دادههای شما مانند دو گروه سرباز در یک دشت هستند. این الگوریتم هوشمندانهترین خط مرزی را بین این دو گروه پیدا میکند، به طوری که بیشترین فاصله ممکن را از نزدیکترین سربازان هر دو گروه داشته باشد. این ویژگی آن را در کاربردهایی مانند تشخیص چهره بسیار کارآمد میکند.
- درخت تصمیم و جنگل تصادفی :(Decision Tree & Random Forest) درخت تصمیم مانند یک فلوچارت از سوالات «بله/خیر» عمل میکند تا به یک نتیجه برسد. اما قدرت واقعی زمانی آشکار میشود که صدها درخت تصمیم را در یک «جنگل» ترکیب کنیم )جنگل تصادفی. (هر درخت نظر خود را میدهد و در نهایت، تصمیمی که بیشترین رأی را بیاورد، به عنوان پاسخ نهایی انتخاب میشود. این خرد جمعی، دقت پیشبینی را به شدت بالا میبرد و در بسیاری از مسابقات علم داده برنده بوده است.
- شبکههای عصبی و یادگیری عمیق :(Neural Networks & Deep Learning) این الگوریتمها که از ساختار مغز انسان الهام گرفتهاند، ستون فقرات انقلاب هوش مصنوعی مدرن هستند. شبکههای عصبی با داشتن لایههای متعدد از «نورونهای» مصنوعی، میتوانند پیچیدهترین الگوها را در دادهها یاد بگیرند. از ترجمه ماشینی گرفته تا خودروهای خودران، تقریباً تمام دستاوردهای بزرگ اخیر هوش مصنوعی مدیون قدرت شبکههای عصبی عمیق هستند.
یادگیری بدون نظارت: وقتی ماشین خودش «کشف» میکند
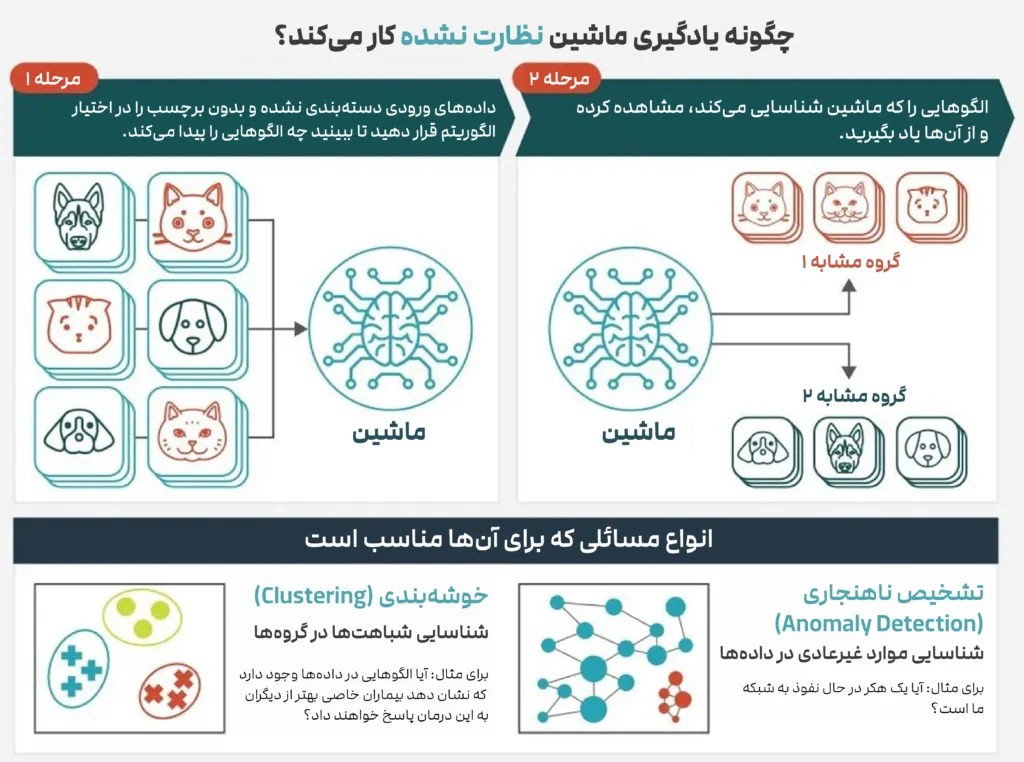
در مقابل یادگیری با نظارت، یادگیری بدون نظارت دنیایی است که در آن هیچ معلمی وجود ندارد. دادهها بدون برچسب هستند و الگوریتم باید خودش ساختار پنهان و الگوهای درون دادهها را کشف کند.
اگر در یادگیری با نظارت، هدف پیشبینی خروجی مشخص است، در یادگیری بدون نظارت هدف، درک و کشف روابط درونی دادهها است.
ماشین در این حالت مانند یک دانشمند کنجکاو عمل میکند که سعی دارد در میان انبوهی از دادههای خام، معنا و نظم پیدا کند.
برای مثال، تصور کنید مدیر یک فروشگاه آنلاین هستید و هزاران مشتری دارید، اما هیچ اطلاعاتی از سلیقه یا الگوی خریدشان ندارید. با استفاده از یادگیری بدون نظارت، میتوانید مشتریان را بر اساس رفتار خریدشان گروهبندی کنید (خوشهبندی)، بدون آنکه از قبل بدانید چه گروههایی وجود دارند.
یا در یک مثال دیگر، فرض کنید میخواهید از بین میلیونها عکس تصاویری را پیدا کنید که از نظر ویژگیهای بصری (رنگ، بافت، شکل) به هم شبیهاند. الگوریتمهای بدون نظارت میتوانند این شباهتها را به طور خودکار کشف کنند، بدون اینکه نیازی به دخالت انسان باشد.
مهمترین الگوریتمهای یادگیری بدون نظارت
- خوشهبندی K-Means
یکی از معروفترین روشها برای گروهبندی دادههاست. الگوریتم به دنبال آن است که دادهها را به تعدادی خوشه (Cluster) تقسیم کند، به طوری که نقاط هر خوشه بیشترین شباهت را به یکدیگر و کمترین شباهت را با نقاط سایر خوشهها داشته باشند.
برای مثال، میتوان از K-Means برای تقسیم مشتریان به چند گروه رفتاری یا حتی بخشبندی بازار استفاده کرد. - الگوریتم سلسلهمراتبی (Hierarchical Clustering)
این روش دادهها را به شکل یک درخت از گروهها سازماندهی میکند. در هر مرحله نزدیکترین گروهها با هم ترکیب میشوند تا ساختاری شبیه به درخت خانوادگی از دادهها به وجود بیاید.
این روش برای تحلیل روابط میان دادهها و کشف ساختارهای تو در تو (مثل روابط ژنتیکی یا خوشهبندی متون مشابه) بسیار کاربرد دارد. - کاهش ابعاد باPCA (Principal Component Analysis)
در دنیای واقعی دادهها معمولاً بسیار پیچیده و چندبعدی هستند. PCA با فشردهسازی هوشمندانه دادهها به ابعاد کمتر باعث میشود تحلیل و تجسم آنها سادهتر شود؛ بدون آنکه اطلاعات مهم از بین برود. این روش در بینایی ماشین، فشردهسازی تصویر و حذف نویز دادهها بسیار پر کاربرد است. - خوشهبندی DBSCAN (Density-Based Spatial Clustering)
این الگوریتم برخلاف K-Means نیازی به تعیین تعداد خوشهها ندارد.
DBSCAN دادهها را بر اساس «تراکم نقاط» گروهبندی میکند و میتواند دادههای نویزی یا نقاط پرت را نیز تشخیص دهد.
همین ویژگی آن را برای تحلیل دادههای دنیای واقعی (که همیشه تمیز و منظم نیستند) بسیار قدرتمند میسازد. - مدلهای مولد (Generative Models) از Autoencoder تا GAN
در سالهای اخیر یادگیری بدون نظارت وارد فاز جدیدی شده است. مدلهایی مانند Autoencoder یاGAN (Generative Adversarial Network) قادرند دادههای جدید و واقعنما تولید کنند.
از تولید تصاویر چهرههای غیرواقعی گرفته تا خلق آثار هنری دیجیتال، این مدلها نشان دادهاند که ماشین میتواند نه تنها تحلیل کند، بلکه خلاق هم باشد.
کاربردهای واقعی یادگیری با نظارت و بدون نظارت
برای درک بهتر تفاوت این دو نوع یادگیری، بیایید نگاهی بیندازیم به چند کاربرد واقعی که در آنها هر دو رویکرد نقش خاص خود را ایفا میکنند؛ یکی با دادههای برچسبدار برای پیشبینی دقیق و دیگری با دادههای خام برای کشف الگوهای پنهان.
دنیای پزشکی: از تشخیص تا کشف
در پزشکی مدرن، یادگیری با نظارت به پزشکان کمک میکند تا بیماریها را از روی دادههای برچسبدار تشخیص دهند. برای مثال، مدلی که با هزاران تصویر «سالم» و «سرطانی» آموزش دیده، میتواند تومورهای احتمالی را با دقت بالا شناسایی کند.
اما یادگیری بدون نظارت هم میتواند وارد عمل میشود تا الگوهای ناشناخته در دادههای بیماران را کشف کند؛ مثلاً تشخیص دهد که برخی بیماران بدون برچسب مشخص، ویژگیهای مشترکی دارند که میتواند نشانهی یک نوع جدید از بیماری یا واکنش دارویی خاص باشد.
به زبان ساده: یادگیری با نظارت تشخیص میدهد چه کسی بیمار است و یادگیری بدون نظارت کشف میکند چرا یا چطور گروهی از بیماران مشابهاند.
تجارت الکترونیک: از پیشنهاد تا تحلیل رفتار
در فروشگاههای آنلاین، مدلهای با نظارت مسئول پیشنهاد محصولاتی هستند که احتمال خریدشان زیاد است. آنها از دادههای برچسبدار مثلاً «کاربر این کالا را خریده / نخریده» یاد میگیرند چه چیزی برای هر فرد مناسبتر است.
در سوی دیگر، مدلهای بدون نظارت مشتریان را بر اساس شباهت در الگوهای خرید یا مرور، خوشهبندی میکنند. یادگیری بدون نظارت میتواند فقط با تکیه بر الگوهای پنهان در رفتار خرید، مشتریان را به گروههایی مثل «خریداران هیجانی»، «مشتریان وفادار» یا «شکارچیان تخفیف» تقسیم کند .یعنی یکی (نظارتی) پیشنهاد میدهد چه بخریو دیگری (بدون نظارت) میفهمد تو شبیه چه کسانی خرید میکنی.
امنیت و تشخیص تقلب: از پیشبینی تا کشف
بانکها و شرکتهای مالی از یادگیری با نظارت برای شناسایی تراکنشهای تقلبی استفاده میکنند. سیستم با دیدن نمونههای برچسبدار از «تراکنش سالم» و «تراکنش مشکوک» یاد میگیرد که کدام عملیات میتواند خطرناک باشد.
در کنار آن، الگوریتمهای بدون نظارت الگوهای رفتاری جدید را بررسی میکنند تا موارد غیرعادی را بدون نمونه قبلی از تقلب تشخیص دهند. این روش بهویژه در مواجهه با کلاهبرداریهای نوظهور بسیار مؤثر است.
به بیان دیگر: یادگیری با نظارت میگوید این تراکنش مشکوک است و بدون نظارت میگوید چیزی در این رفتار درست به نظر نمیرسد.
خودروهای هوشمند: از دیدن تا فهمیدن
در خودروهای خودران، بخشِ با نظارت سیستم را برای تشخیص عابران، تابلوها و خودروهای دیگر آموزش میدهد؛ در مقابل، بخش بدون نظارت به خودرو کمک میکند محیط را بهتر درک کند؛ مثلاً مسیرهای پرترافیک را بر اساس الگوهای مشاهده شده تشخیص دهد یا موقعیتهای غیرمنتظره را شناسایی کند.
بهطور خلاصه یادگیری با نظارت به ماشین کمک میکند ببیند و بدون نظارت کمک میکند بفهمد.
دنیای محتوا و خلاقیت: از تشخیص تا تولید
در حوزهی تولید محتوا، یادگیری با نظارت برای تشخیص اشیاء، افراد یا صحنهها در تصاویر به کار میرود؛ مثل زمانی که سیستم بهطور خودکار چهرهها را در عکسها شناسایی میکند.
اما یادگیری بدون نظارت پا را فراتر میگذارد و میتواند دادههای جدید بسازد. مدلهای مولدی مثل GAN با تحلیل میلیونها تصویر، میتوانند چهرههای جدیدی خلق کنند که وجود خارجی ندارند.
یعنی یکی میگوید این چیست و دیگری میگوید اگر بخواهم چیزی شبیه این بسازم، چطور باید باشد؟

چالشهای پنهان در هر دو رویکرد
در عمل، هر رویکرد یادگیری ماشینی مجموعهای از چالشهای خاص خود را دارند و بسیاری از خطاهای جدی نه از ساختار الگوریتم، که از کیفیت و سازگاری دادهها و نیز پیچیدگیهای مهندسی سیستم ناشی میشوند.
1. کیفیت برچسبها و نویز در دادههای آموزشی
مدلهای نظارتشده بهطور مستقیم به برچسبها وابستهاند. اگر برچسبها اشتباه، ناپیوسته یا متأثر از سوگیری انسانی باشند، مدل همان خطاها را یاد میگیرد و این خطاها در خروجی بازتولید میشوند. برای حل این مشکل روشهایی مثل پالایش فعال برچسب، یادگیری مقاوم به نویز و بررسی آماری برچسبها پیشنهاد میشوند تا اثر آن کاهش یابد.
2. جابجایی توزیع دادهها (Dataset / Covariate Shift)
مدلها معمولاً فرض میکنند توزیع داده آموزش و تست مشابه است. اما در دنیای واقعی توزیع ورودیها یا نسبت برچسبها ممکن است تغییر کند. سختافزار سنسورها فرق کند، جمعیت هدف متفاوت باشد، یا شرایط عملیاتی تغییر کند. این مساله باعث میشود مدلی که در آزمایش نتایج خوبی داشت، در محیط جدید بهطور غیرمنتظرهای بدعمل کند. روشهای تطبیق دامنه و شناسایی و جبران تغییر توزیع ابزارهای متداول برای مقابلهاند.
3. بایاس و واریانس
این تصویر کلاسیک که افزایش بایاس و کاهش واریانس باعث کم کردن پیچیدگی میشود، یک راهنمای مفید برای طراحی مدلها بود؛ اگر مدل خیلی ساده باشد (بایاس بالا) ساختار داده را از دست میدهد و اگر مدل خیلی پیچیده باشد (واریانس بالا) بیشبرازش میکند. اما تحقیقات اخیر نشان دادهاند که در شبکههای عصبی بسیار بزرگ رفتارها پیچیدهتر و طراحی چالشبرانگیزتر شده است. (مثلاً پدیده double descent که خطای آزمون با افزایش اندازه مدل ابتدا بالا میرود و سپس دوباره کاهش مییابد)
4. ارزیابی در یادگیری بدون نظارت
در روشهای بدون نظارت معمولاً «برچسب درست» وجود ندارد، پس ارزیابی کیفیت مدل سختتر است. از سنجههای داخلی مثل Silhouette برای خوشهبندی تا ارزیابی بر مبنای پایش وظیفه پایین دستی (downstream task) همه ابزارهایی هستند که برای سنجش کارآیی به کار میروند، اما هیچیک بهتنهایی کامل نیست. پژوهشهای مروری و مقایسهای نشان میدهند که انتخاب روش و معیار ارزیابی باید براساس کاربرد و ساختار داده انجام شود.
5. چالشهای مهندسی، نابرابری دادهها و مسائل اخلاقی
پیادهسازی عملی مدلها چالشهایی فراتر از خود الگوریتم دارد: نگهداری مدل، فرسودگی مرزهای داده (boundary erosion) و وابستگیهای پنهان بین اجزا که نگهداری و بروزرسانی را دشوار میکند. افزون بر آن، نابرابری در دادهها یا سوگیریهای تاریخی میتواند خروجی را تبعیضآمیز کند؛ یعنی حتی اگر الگوریتم فنی درست باشد، داده ضعیف یا جانبدار منجر به تصمیمات ناعادلانه میشود.
جمعبندی: دو مسیر، یک هدف
در نهایت، یادگیری با نظارت و بدون نظارت دو مسیر متفاوت برای رسیدن به یک هدف مشترکاند: فهم بهتر دادهها و تصمیمگیری هوشمندانهتر.
اگر یادگیری با نظارت شبیه دانشآموزی است که از معلم خود پاسخها را میگیرد، یادگیری بدون نظارت بیشتر به کاوشگری میماند که در تاریکی با اتکا به شهود خود، نظم پنهان در دادهها را کشف میکند.
اما در دنیای امروز مرز این دو رویکرد در حال کمرنگ شدن است؛ مفاهیمی مانند یادگیری نیمهنظارتی (Semi-Supervised Learning) و یادگیری خودنظارتی (Self- Supervised Learning) بهوجود آمدهاند که ترکیبی از مزایای هر دو روش را ارائه میدهند و اساس بسیاری از مدلهای بزرگ امروزی، مانندChatGPT بر همین پایه است.
وقتی یادگیری نظارت شده و نشده در کنار هم قرار میگیرند، مرز میان «دانستن» و «کشف کردن» کمرنگ میشود و این همان نقطهای است که هوش مصنوعی، هوشمند واقعی میشود.