

تفسیر تشابه معنایی متون از مدلهای ترانسفورمر
 تیم تحریریه
تیم تحریریه- ۱ بهمن ۱۴۰۱
مدلهای مبتنی بر ترانسفورمرTransformer-based models برای جستوجوی اسناد متنی به کار برده میشوند. امروزه کتابخانه huggingface روند اجرا را آسانتر کرده و نتایج فوقالعادهای رقم زده است. پیشتر در پی بررسی این موضوع بودم که چرا فلان نتیجه به دست آمد. در ابتدا، مقالهها و پستهای وبلاگی بسیاری را زیر و رو کردم، تا بینش بهتری درباره سازوکارهای توجه Attention mechanisms درون ترانسفورمرها کسب کنم، چرا که این سازوکارها میتوانند نقش مؤثری داشته باشند. در نوشتار حاضر، روش بسیار سادهای برای بررسی تشابهات محتوایی در پیش گرفتهایم. در این راستا، از چند بردار استفاده کردهایم.
مدلی از کتابخانه «sentence-transformers» به کار گرفته شده که به منظور جستوجوی تشابهات معنایی متون بهینهسازی شده است. این مدل میتواند بردار بردار بازنمایی1024 بُعدی1024-dimensional embedding برای هر جمله ایجاد کند. تشابه بین دو جمله با تشابه کسینوسی بین دو بردار قابل محاسبه است. فرض کنید دو پرسش به نام A و B داریم که به ترتیب در بردارهای 1024 بُعدیِ A و B بازنمایی میشوند. تشابه کسینوسی بین جملات بهصورت زیر محاسبه میشود:
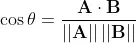
بر این اساس، تشابه کسینوسی 1 به معنای یکسان بودنِ پرسشها است (زاویه صفر). تشابه کسینوسی 1- نیز از متفاوت بودن پرسشها حکایت دارد. برای درک بهتر این مسئله، مجموعهای متشکل از 1700 پرسش از دیتاست طبقهبندی پرسش ARCARC question classification dataset تعبیه شده است. کل نوتبوک در google colab قابل دسترس است. بخش اصلیِ بازنمایی جمله در رشته کد زیر نشان داده شده است:
به این ترتیب، میتوان پایگاه داده پرسشها را به آسانی جستوجو کرد. فرض کنید پایگاه دادهای متشکل از 1700 پرسش داریم که با استفاده از رشته کد فوق در ماتریس تعبیه گردیده است. در گام نخست باید هر سطر را نرمالسازی کرد. به تعبیری، هر بردار پرسش به منظور برخورداری از طول 1 نرمالسازی میشود. لذا معادله پیشین به نحوی سادهسازی میشود که تشابه کسینوسی بین A و B حاصلضرب داخلیِ دو بردار باشد. پس از اتمام کار فرایند تعبیه در رشته کد پیشین، میتوان این چنین وانمود کرد که پرسش اولِ دیتاست نقش « کوئری Query یا پرس و جو» را دارد. در وهله بعدی، باید نزدیکترین ورودی را از بقیه پرسشها پیدا کرد:
پرسش اول در دیتاست نمونهما این بود: «چه عاملی میتواند در بروز تب در فرد نقش داشته باشد؟» مشابهترین پرسشِ شناسایی شده نیز این بود: «چه دلایلی به بهترین نحو نشان میدهند که چرا فرد مبتلا به علائم باکتریایی تب دارد؟» این دو پرسش تطابق خوبی با هم دارند. هر دو جمله به فردی اشاره میکنند که با تب دست و پنجه نرم میکند. با این حال، از کجا میتوان فهمید که الگوریتم این دو جمله را به خاطر شروع یکسان دو جمله با کلمه «چه» انتخاب نکرده است؟
باید این موضوع را به خاطر سپرد که مدلهای ترانسفورمر برداری 1024 بعدی , برای هر توکن از جمله خروجی می دهد. این بازنمایی ها از فیلتر mean-pooling عبور میکنند تا بازنمایی جمله حاصل شود ..برای کسب اطلاعات بیشتر در خصوص مفاد مورد استفاده در راستای یافتن مطابقت در فرایند جستوجو، میتوان فاصله کسینوسی بین هر توکن را محاسبه کرد و نتیجه را در ماتریس دو بعدی نمایش داد:
لذا، نمودار زیر به دست میآید:
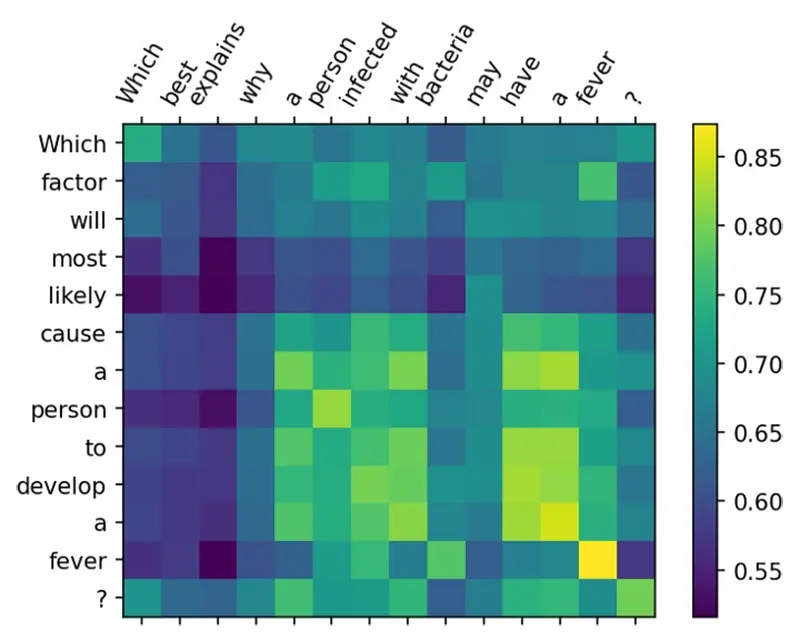
اکنون، میتوان تشابه کسینوسی میان هر توکن را در پرس و جو (کوئری) و هر توکن در بهترین نتیجه جستوجو مشاهده کرد. مبرهن است که کلیدواژه«تب» انتخاب شده و بخش مهمی از بافت معناییSemantic context به حساب میآید که نتیجه جستوجو را رقم زده است. با این حال، نمودار فوق نشان میدهد که مؤلفههای بیشتری میتوانند وارد بافت معنایی شوند؛ برای نمونه، « توسعه یکto develop a …» و « داشتنِ یک have a …» دارای نمره تشابه کسینوسی بالایی هستند. کلیدواژه « فرد person» نیز مدنظر قرار دارد. این در حالی است که واژه « چه which» که در هر دو جمله دیده میشود، اهمیت کمتری دارد.
این روش ساده محاسبه تشابه کسینوسی بین توکنها میتواند بینش بهتری درباره نقش هر توکن در نمره تشابه نهایی فراهم کند. پس، میتوان این موضوع را به راحتی توضیح داد که وقتی مدل به نتیجه جستوجوی معینی میرسد، دقیقاً چه پروسهای را پشت سر میگذارد. باید به این نکته اشاره کرد که وقتی نوبت به جستوجو میرسد، باید میانگین کلیه توکنها را پیش از محاسبه تشابه کسینوسی بین جملات مختلف به دست آورد. که با کاری که ما اینجا انجام دادیم متفاوت است و دانش در زمینه این که کدام توکن در جمله مورد جستجو مخالف کدام توکن در جمله خروجی جستجو است میتواند بینشی در زمینه اینکه چجوری بازنمایی جمله مورد نیاز برای جستجوی معنایی ساخته میشود را, به ما بدهد.





