

تنسورفلو یا پای تورچ؟
 تیم تحریریه
تیم تحریریه- ۱۷ آذر ۱۴۰۰
یکی از دانشجویان دانشکدۀ «UPC Barcelona Tech» از من پرسید که بهترین چهارچوب برای برنامهنویسی شبکههای عصبی کدام است؟ تنسورفلو TensorFlow یا پایتورچ؟ PyTorch این پاسخِ من بود: «نگران این مسئله نباش! با هر کدام که راحتتر هستی کار را شروع کن. مهم نیست کدام یک رو انتخاب میکنی. مهمترین کار این است که اقدام به شروع کنی.»مراحل برنامهنویسی شبکههای عصبی در هر دو محیط در یادگیری ماشین مشترک است:
• وارد کردن کتابخانههای مورد نیاز
• بارگذاری و پردازش دادهها
• تعریف کردن مدل
• تعریف کردن بهینهکننده و تابع زیان
• آموزش دادن مدل
• ارزیابی مدل
این مراحل به شکل مشابهی در هر یک از چارچوبها قابل اجرا هستند. به همین منظور، ما به دنبال ساخت مدل شبکه عصبی هستیم که ارقام دستنوشت را در API PyTorch و API Keras of TensorFlow طبقهبندی کند. امکان آزمایشِ کد در GitHub وجود دارد.
مراحل برنامهنویسی شبکههای عصبی
1. وارد کردن کتابخانههای مورد نیاز
در هر دو چارچوب باید در ابتدا چند کتابخانه پایتون وارد و چند پارامتر برای پیشبرد اهداف آموزش تعریف کنیم:
import numpy as np import matplotlib.pyplot as plt epochs = 10 batch_size=64
در چارچوب تنسورفلو فقط این کتابخانه مورد نیاز است:
import tensorflow as tf
اما در پای تورچ باید از دو کتابخانه زیر استفاده کرد:
import torch import torchvision
2. بارگذاری و پیش پردازش دادهها Preprocessing data
بارگذاری و آمادهسازیِ دادهها با تنسورفلو با کدهای زیر انجامپذیر است:
(x_trainTF_, y_trainTF_), _ = tf.keras.datasets.mnist.load_data() x_trainTF =
x_trainTF_.reshape(60000, 784).astype('float32')/255 y_trainTF =
tf.keras.utils.to_categorical(y_trainTF_,
num_classes=10)
اما در پایتورچ به کدهای زیر نیاز است:
xy_trainPT = torchvision.datasets.MNIST(root='./data', train=True, download=True,transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor()])) xy_trainPT_loader = torch.utils.data.DataLoader(xy_trainPT, batch_size=batch_size)
میتوان این نکته را تأیید کرد که هر دو کد، دادههای یکسانی را با کتابخانه matplotlib.pyplot بارگذاری میکنند:
print("TensorFlow:")
fig = plt.figure(figsize=(25, 4))
for idx in np.arange(20):
ax = fig.add_subplot(2, 20/2, idx+1, xticks=[], yticks=[])
ax.imshow(x_trainTF_[idx], cmap=plt.cm.binary)
ax.set_title(str(y_trainTF_[idx]))

print("PyTorch:")
fig = plt.figure(figsize=(25, 4))
for idx in np.arange(20):
ax = fig.add_subplot(2, 20/2, idx+1, xticks=[], yticks=[])
ax.imshow(torch.squeeze(image, dim = 0).numpy(),
cmap=plt.cm.binary)
image, label = xy_trainPT [idx]
ax.set_title(str(label))
3. تعریف کردن مدل
تعریف مدل در هر دو مورد با ساختار نسبتاً مشابهی انجام میگیرد. این مرحله در تنسورفلو با کد زیر انجام میشود:
modelTF = tf.keras.Sequential([ tf.keras.layers.Dense(10,activation='sigmoid',input_shape=(784,)), tf.keras.layers.Dense(10,activation='softmax') ])
این مرحله در پای تورچ با کد زیر انجامپذیر است:
modelPT= torch.nn.Sequential( torch.nn.Linear(784,10),torch.nn.Sigmoid(), torch.nn.Linear(10,10), torch.nn.LogSoftmax(dim=1) )
4. تعریف کردن تابع بهینهکننده Optimizer function و تابع زیان
مجدداً، روش تصریح بهینهکننده و تابع زیان کاملاً یکسان است. این کار در تنسورفلو به صورت زیر انجام میشود:
modelTF.compile( loss="categorical_crossentropy", optimizer=tf.optimizers.SGD(lr=0.01), metrics = ['accuracy'] )
این کار در پایتورچ به صورت زیر انجام میشود:
criterion = torch.nn.NLLLoss() optimizer = torch.optim.SGD(modelPT.parameters(), lr=0.01)
5-آموزش دادنِ مدل Model training
وقتی نوبت به آموزش میرسد، تفاوتها خود را نمایان میکنند. آموزش در تنسورفلو فقط با این کد انجام میپذیرد:
_ = modelTF.fit(x_trainTF, y_trainTF, epochs=epochs, batch_size=batch_size, verbose = 0)
این مرحله در پای تورچ کمی طولانی است:
for e in range(epochs): for images, labels in xy_trainPT_loader: images = images.view(images.shape[0], -1) loss = criterion(modelPT(images), labels) loss.backward() optimizer.step() optimizer.zero_grad()
پایتورج فاقد تابع تنظیم مدلهای داده است. بنابراین، برنامهنویس باید حلقه آموزش را تصریح کند.
6. ارزیابیِ مدل
شرایط مشابه زمانی پیش میآید که بخواهیم به ارزیابی مدل اقدام کنیم. در تنسورفلو فقط کافی است مدل را به کمک دادههای آزمایشی evaluate() نامگذاری کنید:
_, (x_testTF, y_testTF)= tf.keras.datasets.mnist.load_data()
x_testTF = x_testTF.reshape(10000, 784).astype('float32')/255
y_testTF = tf.keras.utils.to_categorical(y_testTF, num_classes=10)
_ , test_accTF = modelTF.evaluate(x_testTF, y_testTF)
print('\nAccuracy del model amb TensorFlow =', test_accTF)TensorFlow model Accuracy = 0.8658999800682068
فرد برنامهنویس در پایتورچ ملزم به تصریح حلقه ارزیابی است:
xy_testPT = torchvision.datasets.MNIST(root='./data', train=False, download=True,
transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor()]))
xy_test_loaderPT = torch.utils.data.DataLoader(xy_testPT)
correct_count, all_count = 0, 0
for images,labels in xy_test_loaderPT:
for i in range(len(labels)):
img = images[i].view(1, 784)
logps = modelPT(img)
ps = torch.exp(logps)
probab = list(ps.detach().numpy()[0])
pred_label = probab.index(max(probab))
true_label = labels.numpy()[i]
if(true_label == pred_label):
correct_count += 1
all_count += 1
print("\nAccuracy del model amb PyTorch =", (correct_count/all_count))TensorFlow model Accuracy = 0.8657
همان طور که در این مثال ساده ملاحظه کردید، شیوه ساخت شبکه عصبی در تنسورفلو یا پای تورچ تفاوت چندانی با یکدیگر ندارند؛ به جز چند مورد استثنا که برنامهنویس باید آنها را در هنگام اجرای حلقه ارزیابی و آموزش مد نظر قرار دهد. برخی از پارامترها از قبیل دوره یا اندازۀ دسته در مراحل مختلف مشخص میشوند. در واقع، این دو چارچوب در طول دو سال گذشته به طور پیوسته در حال همگرایی بودهاند؛ از همدیگر یاد گرفتهاند و از بهترین ویژگیها و قابلیتهای خود برای مواجهه با مسائل استفاده میکنند.
برای نمونه، در نسخۀ جدید تنسورفلو 2.2 که چند هفته پیش خبر آن منتشر شد، میتوان مرحله آموزش را به مانند پای تورچ انجام داد و برنامهنویس میتواند با اجرای traint_step() محتوای جامع پیکرۀ حلقه را تصریح کند. پس نگران این نباشید که شاید چارچوب اشتباهی را انتخاب کرده باشید، زیرا در نهایت همگرا خواهند شد. مهمترین موضوع این است که مفاهیم یادگیری عمیق را به خوبی فرا گرفته باشید. دانشی که در زمینه یکی از چارچوبها کسب میکنید، در چارچوب دیگر هم مفید واقع خواهد شد.
تولید یا تحقیق؟
اگر بخواهید مدل شبکه عصبی خود را وارد مرحله تولید و اجرا کنید یا در مورد شبکههای عصبی به تحقیق بپردازید، دو رویکرد متفاوت در پیش خواهید داشت. در این مورد، تصمیمگیری و انتخاب یکی از بین این دو اهمیت زیادی دارد. تنسورفلو کتابخانهی پایتون بسیار قوی و کارآمدی است و از ویژگیهای بصری و طیف کثیری از گزینهها جهت ارتقای عملکرد در توسعه مدل بهره میبرد.
تنسورفلو گزینههایی برای تولید و حمایت خودکار از پلتفرمهای موبایل و وب دارد. اما از سوی دیگر، پایتورچ هنوز چارچوب نوپایی است، اما جامعه فعالی دارد که در عرصه تحقیق نیز بیوقفه در حال تلاشاند. پورتال The Gradient، به همراه پیدایش و بکارگیری پایتورچ . جامعه تحقیق بر اساس تعداد مقالههای منتشر شده در مضامین عمدۀ کنفرانس در شکل زیر به نمایش در آمده است (CVPR, ICRL, ICML, NIPS, ACL, ICCV و غیره).
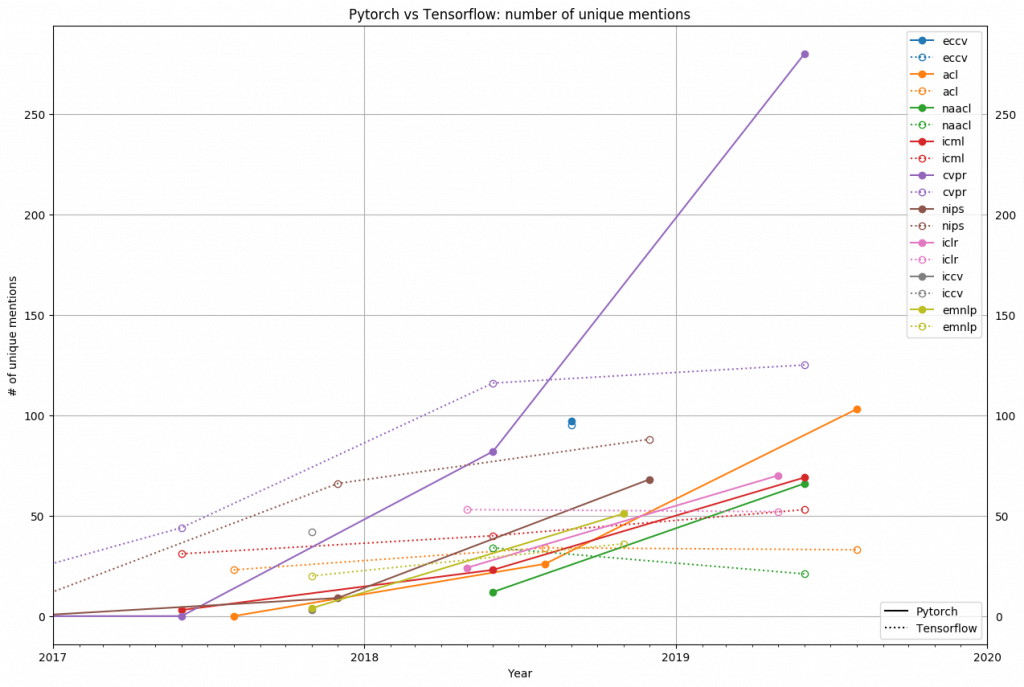
همانطور که در بخش 2018 این شکل میبینید، استفاده از چارچوب پای تورچ مورد توجه عده قلیلی بوده است؛ اما در سال 2019 شرایط دیگری حاکم شده و محققان میزان استفاده از این چارچوب را افزایش دادهاند. بنابراین، اگر میخواهید محصولاتی مرتبط با هوش مصنوعی ایجاد کنید، تنسورفلو گزینه مناسبی است. اگر میخواهید تحقیق کنید، توصیۀ ما این است که از پایتورچ استفاده کنید.
البته اگر تردید به دلتان راه یافت، Keras را انتخاب کنید.
اگر اطمینان کامل ندارید، از Keras API تنسورفلو استفاده کنید. API پایتورچ دارای کنترل و انعطافپذیری بیشتری است، اما یقیناً Keras API تنسورفلو میتواند راحتتر اجرا شود. افزون بر این، مستندات بیشتری در سایر مقالهها در خصوص Keras موجود است که میتوانید برای کسب اطلاعات بیشتر به آنها مراجعه کنید. Keras قابلیتهای جدیدی در سال 2020 برای کاربران عرضه خواهد کرد و انتظار میرود کار با آن آسانتر شود. در بخش زیر میخواهیم به ویژگیها و قابلیتهای جدیدی اشاره کنیم که در نسخه بعدی ارائه خواهند شد:
لایهها و پیشپردازش APIها
تا به الان، مرحله پیشپردازش با ابزارهای کمکیِ نوشته شده در NumPy و کتابخانه PIL انجام شده است. این نوع پیشپردازش بیرونی قابل حمل بودنِ مدلها را کاهش میدهد، زیرا هر بار که یک فرد از مدلِ از پیش آموزش دیده استفاده کند، باید خط لوله پیشپردازشگر دوباره اجرا شود. بنابراین، عملِ پیشپردازش اکنون میتواند از طریق لایههای پیشپردازش، بخشی از مدل باشد. این کار شامل جنبههایی نظیر استاندارد کردنِ متن، جداسازی واژگان، بردارسازی، نرمالسازی عکس، دادهافزایی و غیره باشد. لذا این فرصت در اختیار مدلها قرار داده میشود تا متن یا تصاویر خام را به عنوان ورودی بپذیرند. من شخصاً فکر میکنم این کار میتواند خیلی جالب باشد.
Keras Tuner
این چارچوب به کاربران کمک میکند تا بهترین پارامترهای مدل را در Keras پیدا کنند. اگر زمان زیادی را صرفِ کار کردن در حوزه یادگیری عمیق کنید، خواهید دید که این چارچوب میتواند یکی از پرهزینهترین مسائل مدلسازی را برطرف کند؛ مثل اصلاح پارامترها برای اینکه مدل بهترین عملکردش را ارائه کند. این کار همیشه دشواریهای زیادی به همراه داشته است.
AutoKeras
این پروژه به دنبال یافتنِ مدل یادگیری ماشین خوبی برای دادههاست و به صورت خودکار بهترین مدل ممکن را بر اساس فضای مدلها مورد جستجو قرار میدهد. در این راستا از Keras Tuner برای تنظیم پارامترها نیز استفاده میکند. AutoKeras این امکان را به کاربران پیشرفته میدهد تا کنترل بیشتری روی پیکربندیِ فضای جستجو و فرایند مربوطه داشته باشند.
Cloud Keras
هدف این است که برنامهنویسها به آسانی کد را به فضای ابری انتقال دهند؛ بدین ترتیب، کد به صورت کارآمد و توزیعشده در Cloud قابل اجرا خواهد بود و دیگر نباید نگرانِ دسته یا پارامترهای Docker بود.
یکپارچهسازی با تنسورفلو
محققان در تلاشاند تا زمینه را برای استفاده از پلتفرم TFX و وارد کردن مدل به TF Lite فراهم کنند. بیتردید، پشتیبانیِ بیشتر از تولید مدل امری ضروری برای وفاداریِ برنامهنویسها در Keras است.
جمعبندی
فکر میکنید کدام یک بهترین زبان برای آغاز برنامهنویسی است: C ++ یا جاوا؟ بستگی دارد که چه هدفی از بکارگیری این زبانها داشته باشید. همچنین باید به این نکته توجه داشت که چه ابزارهایی برای یادگیری در اختیار داریم. شاید موافق این کار نباشیم زیرا باورهایِ از پیش تعیین شده باعث میشود تغییر جواب با دشواری همراه باشد. اما قطعاً بر سر این موضوع توافق نظر داریم که چگونگی برنامهنویسی اهمیت بسیار بالایی دارد. در واقع، هر آنچه از برنامهنویسی در یک زبان یاد میگیریم، در صورت کار با زبان دیگر نیز برایمان مفید واقع میشود. این طور نیست؟ همین امر برای چارچوبها نیز صدق میکند. نکته مهم این است که به کسب اطلاعات درباره یادگیری عمیق بپردازیم، نَه جزئیات دستوری چارچوبها.
نظر شما چیست؟ تنسورفلو یا پای تورچ؟





