

داده افزایی و جلوگیری از بیشبرازش مدل در مسائل طبقهبندی تصویر
 تیم تحریریه
تیم تحریریه- ۱۳ دی ۱۴۰۰
فرض کنید یک مدل طبقهبندی تصویری آموزش دادهاید که عملکرد نسبتاً ضعیفی دارد؛ آیا میدانید روشهای زیادی برای بهبود عملکرد و کاهش سوگیریهای مدل وجود دارد؟ زمان زیادی را صرف ایجاد روال پردازشی مدل کردهاید و با استفاده از شبکههای عصبی یک مدل پیشبینی کننده ساختهاید، اما نتایج ، آنطور که انتظار داشتید، نیست… در چنین مواردی، بهتر است پیش از هر اقدام دیگری تکنیکهای داده افزایی را امتحان کنید.
تمامی کدهای به کار رفته در این مطلب آموزش را میتوانید از GitHub دانلود کنید. این دادهها با استفاده از Google Colab و GPU فعال، آموزش داده شدهاند.
در این مقاله آموزشی به معرفی روش داده افزایی خواهیم پرداخت و به شما نشان میدهیم چگونه میتوان با استفاده از این تکنیک عملکرد مدلهای یادگیری ماشین، به ویژه مدلهای طبقهبندی تصویر، را بهبود بخشید.
مهندسان یادگیری ماشین با اتکا به تکنیک داده افزایی و بدون نیاز به جمعآوری دادههای جدید میتوانند تنوع دادههای موجود برای آموزش مدلها را افزایش دهند. به زبان ساده در تکنیک داده افزایی، از تصاویر موجود، تصاویر زیادی بازآفرینی میشوند. در ضمن این تکنیک به ما کمک میکند یک عکس را در ابعاد و اشکال متفاوت بازآفرینی کنیم.
برای درک بهتر این تکنیک به تصویر زیر نگاه کنید. تصویر مقابل، تصویر یک سگ است و به نظر میرسد به دفعات و از جهات مختلف از این سگ عکسبرداری شده است؛ اما در واقع تکنیک داده افزایی بر روی این عکس اجرا شده تا تصاویر بیشتری ایجاد شود. تأثیرات این تکنیک بر عملکرد الگوریتم به شرح زیر است:
- سوگیری مدل نسبت به یک کلاس خاص را کاهش میدهد. در نتیجهی این عمل الگوریتم به خوبی میتواند تعمیم دهد.
به کلاسهایی که نمونه کمتری در خود جای دادهاند، نمونه اضافه میکند (از طریق افزایش نمونههای اصلی و ایجاد نمونههای بیشتر).

مقدمه
برای شروع از دیتاستی استفاده میکنم که همگی ما کم و بیش با ان آشنایی داریم: دیتاست گربه و سگ Kaggle. پیش از اعمال تکنیک داده افزایی بر روی این دیتاست، باید یک پایپلاین داده بسازیم.
[irp posts=”12564″]ساخت پایپلاین داده
فارغ از مشکلی که قصد دارید آن را به کمک ML حل کنید، بر روی دادههایتان، پیش از اینکه در مدلسازی مورد استفاده قرار بگیرند، چندین عملیات مختلف انجام میشود. این روال پردازشی اغلب موارد زیر را در بر میگیرد:
- تغییر ابعاد تصویر ورودی
- تبدیل تصاویر به آرایهها
- فیلتر کردن تصاویر (اجباری نیست)
- تغییر مقیاس تصاویر ( افزایش وضوح عکس یا کاهش وضوح عکس)
در این مقاله آموزشی به توصیف مورد 1 و 2 بسنده میکنیم.
در گام اول برای آشنایی بیشتر با نحوه بارگذاری یک تصویر در یک آرایه، دادهها را به صورت دستی بارگذاری میکنیم (به جای استفاده از tf.data). برای انجام این کار میتوانیم از کد زیر استفاده کنیم:
1 train_dir = '/root/.kaggle/training_set/training_set' 2 test_dir = '/root/.kaggle/test_set/test_set' 3 default_dir = '/root/.kaggle' 4 5 train_cat, train_dog, test_cat, test_dog = [], [],[],[] 6 def get_data(): 7 os.chdir(default_dir) 8 # get data's on training cat 9 current_dir = train_dir+'/cats' 10 os.chdir(current_dir) 11 train_data_cat = os.listdir() 12 train_cat.extend(train_data_cat) 13 14 # get data's on training dog 15 current_dir = train_dir +'/dogs' 16 os.chdir(current_dir) 17 train_data_dog = os.listdir() 18 train_dog.extend(train_data_dog) 19 20 # get data's on test cat 21 current_dir = test_dir+'/cats' 22 os.chdir(current_dir) 23 test_data_cat = os.listdir() 24 test_cat.extend(test_data_cat) 25 26 # get data's on test dog 27 current_dir = test_dir +'/dogs' 28 os.chdir(current_dir) 29 test_data_dog = os.listdir() 30 os.chdir(default_dir) 31 test_dog.extend(test_data_dog) 32 return 33 34 get_data()
و با اجرای کد زیر هم میتوانیم تعداد دادههایی که باید بارگذاری کنیم را بررسی کنیم:
1 print('Number of cats in our train data is: ', len(train_cat))
2 print('Number of dog in our train data is: ', len(train_dog))
3 print('Number of cats in our test data is: ', len(test_cat))
4 print('Number of dogs in our test data is: ', len(test_dog))
5 print('Total training data is: ', len(train_cat)+len(train_dog))
6 print('Total test data is: ', len(test_cat)+len(test_dog))
در این قسمت به شما نشان میدهیم که چگونه میتوان با استفاده از کلاس image (در کتابخانه Keras) دادههای را به صورت دستی بارگذاری کرد. ما دادهها را به صورت تصایر رنگی با ابعاد 224 در 224 بارگذاری میکنیم. برای انجام این کار gray_scale را بر روی False تنظیم میکنیم:
1 import numpy as np 2 np.random.seed(100) 3 4 import keras 5 from keras.preprocessing import image 6 7 train_images = [] 8 train_target = [] 9 test_images = [] 10 test_target = [] 11 12 13 for i in train_cat: 14 try: 15 directory = train_dir + '/cats/' + i 16 img = image.load_img(directory, target_size = (224,224), grayscale = False) 17 img=image.img_to_array(img) 18 img = img/255 19 train_images.append(img) 20 os.chdir(default_dir) 21 train_target.append(0) 22 except OSError as err: 23 continue 24 25 for i in train_dog: 26 try: 27 directory = train_dir + '/dogs/' + i 28 img = image.load_img(directory, target_size = (224,224), grayscale = False) 29 img=image.img_to_array(img) 30 img = img/255 31 train_images.append(img) 32 os.chdir(default_dir) 33 train_target.append(1) 34 35 except OSError as err: 36 continue 37 38 39 for i in test_cat: 40 try: 41 directory = test_dir + '/cats/' + i 42 img = image.load_img(directory, target_size = (224,224), grayscale = False) 43 img=image.img_to_array(img) 44 img = img/255 45 test_images.append(img) 46 os.chdir(default_dir) 47 test_target.append(0) 48 except OSError as err: 49 continue 50 51 for i in test_dog: 52 try: 53 directory = test_dir + '/dogs/' + i 54 img = image.load_img(directory, target_size = (224,224), grayscale = False) 55 img=image.img_to_array(img) 56 img = img/255 57 test_images.append(img) 58 os.chdir(default_dir) 59 test_target.append(1) 60 61 except OSError as err: 62 pass 63
با اجرای کد زیر میتوانید تصاویری را که به صورت دستی (به صورت فهرستی از آرایهها) بارگذاری کردید، به arrays تبدیل میکنید:
1 train_images = np.array(train_images) 2 test_images = np.array(test_images) 3 train_target = np.array(train_target) 4 test_target = np.array(test_target) 5 train_images.shape, test_images.shape, train_target.shape, test_target.shape
حالا که تمامی تصاویر را به آرایه تبدیل کردیم، میتوانیم فرایند ساخت مدل را آغاز کنیم.
ساخت مدل
برای ساخت مدل باید موارد زیر را در نظر بگیریم:
- یک شبکه ورودی که تصاویری در ابعاد 224×224×3 و یک تابع فعالسازی ReLU را به عنوان ورودی دریافت میکند.
- اولین لایه کانولوشن 2 بُعدی با 32 فیلتر؛ اندازه هر یک از فیلترهای این لایه 7 در 7 است.
- یک لایه پولینگ ماکزیمم 2 بُعدی برای اولین لایه کانولوشن؛ اندازه کرنل این لایه 2 در 2 است.
- دومین لایه کانولوشن 2 بُعدی با 16 فیلتر؛ اندازه هر یک از فیلترهای این لایه 5 در 5 است و یک تابع فعالسازی ReLU هم دارند.
- یک لایه ادغام بیشینه 2 بُعدی برای دومین لایه کانولوشن؛ اندازه کرنل این لایه 2 در 2 است.
- سومین لایه کانولوشن 2 بُعدی با 8 فیلتر؛ اندازه هر یک از فیلترهای این لایه 5 در 5 است و یک تابع فعالسازی ReLu هم دارند.
- یک لایه ادغام بیشینه 2 بُعدی برای سومین لایه کانولوشن؛ کرنل این لایه 2 در 2 است.
- یک لایه مسطح ( تا تمامی اطلاعات را به یک لایه FC منتقل کند).
- یک لایه پنهان متشکل از 300 نورون و یک تابع فعالسازی ReLU.
- یک لایه پنهان متشکل از 100 نورون و یک تابع فعالسازی ReLU.
- دو لایه خروجی، به این دلیل که میخواهیم مدل احتمال اینکه تصویر به کلاس Dog تعلق دارد یا به کلاس Cat را پیشبینی کند.
برای نوشتن تمامی این موارد در TensorFlow میتوانیم از کد زیر استفاده کنیم:
1 model = models.Sequential() 2 model.add(layers.Conv2D(32, (7,7), activation='relu', input_shape=(224,224, 3))) 3 model.add(layers.MaxPooling2D((2, 2))) 4 model.add(layers.Conv2D(16, (5, 5), activation='relu')) 5 model.add(layers.MaxPooling2D((2, 2))) 6 model.add(layers.Conv2D(8, (2, 2), activation='relu')) 7 model.add(layers.MaxPooling2D((2, 2))) 8 model.add(layers.Flatten()) 9 model.add(layers.Dense(300, activation='relu')) 10 model.add(layers.Dense(100, activation='relu')) 11 model.add(layers.Dense(2, activation = 'softmax')) 12 model.summary()
جدول زیر خلاصهای از مدل است. همانگونه که در این جدول هم نشان داده شده، شبکه محاسبهبر نیست و فقط با 5/1 میلیون پارامتر آموزش دیده (برخلاف مدلهایی که 300 میلیون پارامتر دارند) و با همین تعداد پارامتر توانسته به نتایج فوقالعادهای دست پیدا کند.
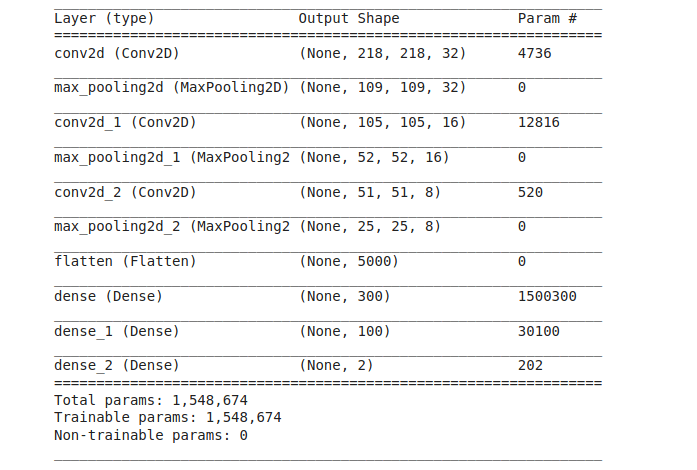
با اجرای کد فوق توانستید شبکه خود را طراحی کنید. پس از اتمام این مرحله، شبکه را کامپایل میکنیم و سپس دادهها را به شبکه تغذیه میکنیم تا آموزش ببیند. کد زیر در انجام این کار به ما کمک میکند.
برای کامپایل کردن شبکه، model.compile را اجرا میکنیم و سپس آرگومانهای لازم را به آن میدهیم. و در آخر برای اینکه مدل شروع به یادگیری کند، از تابع fit مدل استفاده میکنیم و سپس دادهها را به مدل تغذیه میکنیم تا از آنها یاد بگیرد. مدل را فقط 10 تکرار (epoch) آموزش میدهیم- شما میتوانید تعداد مراحل آموزش را به دلخواه انتخاب کنید، اما فراموش نکنید که تعداد مراحل آموزش نباید آنقدر زیاد باشد که مدل برای مدتی طولانی اجرا شود.
ما از بهینهساز Adam استفاده میکنیم و تابع هزینه هم آنتروپی متقاطع دستهای است. و متریک نهایی برای ارزیابی عملکرد مدل، نرخ دقت آن خواهد بود.
1 model.compile(optimizer='adam', 2 loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), 3 metrics=['accuracy']) 4 5 history = model.fit(train_images, train_target, epochs=10, 6 validation_data=(test_images, test_target))
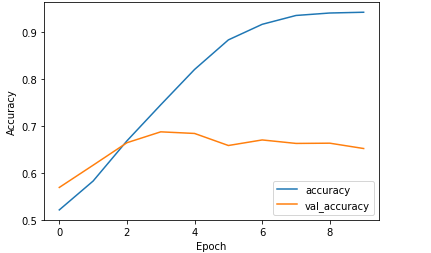
با نگاهی به نتایج آموزش مدل (نمودار فوق) متوجه میشویم که در آغاز آموزش مدل، نرخ دقت آن 50% بوده و به تدریج به 100% رسید، اما نرخ دقت آن بر روی دادههای اعتبارسنجی در آغاز 50% بود و بر روی 68% ثابت مانده است.
با توجه به نمودار پایین هم متوجه میشویم مدل در زمان آموزش با دادههای آموزشی، تمامی الگوها و اطلاعات را یاد گرفته است و به همین دلیل در زمان ارزیابی عملکردش به نرخ دقتی برابر با 100% دست پیدا کرد.
اما زمانی که دادههای اعتبارسنجی را به مدل تغذیه کردیم ( که قبلاً آنها را ندیده بود) و نتایج را با نتایج واقعی مقایسه کردیم، متوجه شدیم که این مدل توانسته با نرخ دقتی برابر با 68%، کلاس تصاویر را به درستی پیشبینی کند. با این تفاسیر میتوانیم نتیجه بگیریم که مدل، دادههای آموزشی را به خوبی یاد گرفته اما عملکردش بر روی دادههای اعتبار سنجی (که قبلاً آنها را ندیده) از چیزی که انتظار داشتیم ضعیفتر بوده است.
نرخ دقت 68% خوب است، اما زمانی که آن را با نرخ دقت مدل در هنگام آموزش با دادههای آموزشی مقایسه میکنیم (که 97% بوده)، اصلاً قابل قوبل نیست و نشان میدهد که مدل دچار بیشبرازش شده است. برای رفع این مشکل میتوانیم از راهکارهای زیر استفاده کنیم:
- داده افزایی
- تکنیکهای منظمسازی ( مثل dropouts)
داده افزایی
داده افزایی به مجموعهای از تکنیکها اطلاق میشود که در فرایند پردازش تصویر مورد استفاده قرار میگیرند. در دنیای واقعی از تکنیکهای داده افزایی به همراه پایپلاینهای داده استفاده میشود تا سوگیری مدل کاهش و در نتیجه عمکرد آن ارتقا پیدا کند و مدل به خوبی بتواند تعمیم دهد.
برای ارزیابی عملکرد مدل در مسائل طبقهبندی تصویر، عملکرد مدل در تمامی کلاسهایی که پیشبینی کرده را نسبت به عملکردش بر روی کلاسهایی میسنجیم که حداقل نمونه را در خود جای دادهاند (عملکرد مدل در این دو نوع کلاس را با هم مقایسه میکنیم). به کمک تکنیک داده افزایی میتوانیم در کلاسهایی که نمونههای کمتری در خود جای دادهاند، نمونههای بیشتر بازآفرینی کنیم، در نتیجه این عمل تعداد نمونههای موجود در تمامی کلاسهایی که باید پیشبینی شوند، یکسان خواهد بود. تنوع دادهها به مدل کمک میکند تعمیم دهد و در همان حال سوگیری مدل را کاهش میدهد.
به زبان ساده در تکنیک داده افزایی از تصاویر موجود، تصاویر جدید زیادی بازآفرینی میشوند. فقط لازم است کاری کنید که مدلتان دادههایی را ببیند که آنها را با ابعاد جدید میدیده است. برای انجام این کار میتوانید از کلاس image generator که جزئی از کتابخانه پیشپردازش کتابخانه TensorFlow است، استفاده کنید.
به کمک کلاس image generator و اجرای یکی از تکنیکهای زیر میتوانیم تصاویر بیشتری ایجاد کنیم:
- چرخش عکس
- زوم کردن
- برگردان عکس
- برش عکس
- افزودن نویز به عکس
برای افزایش دادهها، در قدم اول باید image data generator را از Keras بارگذاری کنید. کلاسهای مربوط به دادههای آموزشی و دادههای اعتبارسنجی را به صورت جداگانه نمونهسازی کنید. سپس پارامترهایی که میخواهید به صورت خودکار بر روی دادههای موجود اعمال شوند و دادههای جدید ایجاد کنند را مشخص کنید. برای نمونه میتوان به برگردان افقی، چرخش ( با تعیین زاویه چرخش) و غیره اشاره کرد.
1 from tensorflow.keras.models import Sequential 2 from tensorflow.keras.layers import Dense, Conv2D, Flatten, Dropout, MaxPooling2D 3 from tensorflow.keras.preprocessing.image import ImageDataGenerator 4 5 #initialize your train generator and validation generator 6 train_image_generator = ImageDataGenerator(rescale=1./255) # Generator for our training data 7 validation_image_generator = ImageDataGenerator(rescale=1./255) # Generator for our validation data 8 9 batch_size = 100 10 target_size = (224,224) 11 image_gen = ImageDataGenerator(rescale=1./255, horizontal_flip=True) 12 train_data_gen = image_gen.flow_from_directory(batch_size=batch_size, 13 directory=train_dir, 14 shuffle=True, 15 target_size=target_size) 16 val_data_gen = validation_image_generator.flow_from_directory(batch_size=batch_size, 17 directory=test_dir, 18 target_size=target_size, 19 class_mode='binary')
اجرای تکنیک داده افزایی
برگردان عکس
برای اجرای تکنیک برگردان عکس، horizontal_flip را بر روی True تنظیم کرده و کد مقابل را اجرا کنید. این کد به صورت تصادفی تصاویری از دادههای آموزشی شما انتخاب کرده و تکنیک برگردان عکس را بر روی آن اجرا میکند تا تصاویر جدیدی ایجاد کند و حجم دادهها را افزایش دهد:
1 image_gen = ImageDataGenerator(rescale=1./255, horizontal_flip=True) 2 train_data_gen = image_gen.flow_from_directory(batch_size=batch_size, 3 directory=train_dir, 4 shuffle=True, 5 target_size=target_size)

چرخش عکس
برای چرخاندن عکس، زاویه چرخش را مشخص کرده و کد زیر را اجرا کنید، من زاویه چرخش را بر روی 45 درجه تنظیم کردهام:
1 image_gen = ImageDataGenerator(rescale=1./255, rotation_range=45) 2 3 train_data_gen = image_gen.flow_from_directory(batch_size=batch_size, 4 directory=train_dir, 5 shuffle=True, 6 target_size=target_size) 7 8 augmented_images = [train_data_gen[0][0][0] for i in range(5)]

زوم کردن
در تکنیک زوم کردن، بازه زوم بین 0 تا 1 مشخص شده است. به همین دلیل اگر بازه زوم را بر روی 7/0 تنظیم کنید، زوم تصویر به صورت تصادفی بین 0 و 70% متغیر خواهد بود. برای اجرای تکنیک زوم کردن، ایتدا باید بازه زوم عکس را مشخص کنید. من بازه زوم را بر روی 6/0 تنظیم کردهام ( یعنی حداکثر میزان زوم 60% خواهد بود):
1 # zoom_range from 0 - 1 where 1 = 100%. 2 image_gen = ImageDataGenerator(rescale=1./255, zoom_range=0.5) # 3 4 train_data_gen = image_gen.flow_from_directory(batch_size=batch_size, 5 directory=train_dir, 6 shuffle=True, 7 target_size=target_size) 8 9 augmented_images = [train_data_gen[0][0][0] for i in range(5)]

حالا تمامی این تکنیکها را در کنار هم قرار میدهیم تا ببینیم تکنیکهای داده افزایی توانستهاند به بهبود عملکرد مدل کمک کنند یا نه:
1 image_gen_train = ImageDataGenerator( 2 rescale=1./255, 3 rotation_range=45, 4 width_shift_range=.15, 5 height_shift_range=.15, 6 horizontal_flip=True, 7 zoom_range=0.5 8 ) 9 10 train_data_gen = image_gen_train.flow_from_directory(batch_size=batch_size, 11 directory=train_dir, 12 shuffle=True, 13 target_size=target_size, 14 class_mode='binary') 15 16 17 image_gen_val = ImageDataGenerator(rescale=1./255)v 18 19 val_data_gen = image_gen_val.flow_from_directory(batch_size=batch_size, 20 directory=test_dir, 21 target_size=target_size, 22 class_mode='binary') 23 24 #using the same model 25 model = models.Sequential() 26 model.add(layers.Conv2D(32, (7,7), activation='relu', input_shape=(224,224, 3))) 27 model.add(layers.MaxPooling2D((2, 2))) 28 model.add(layers.Conv2D(16, (5, 5), activation='relu')) 29 model.add(layers.MaxPooling2D((2, 2))) 30 model.add(layers.Conv2D(8, (2, 2), activation='relu')) 31 model.add(layers.MaxPooling2D((2, 2))) 32 model.add(layers.Flatten()) 33 model.add(layers.Dense(300, activation='relu')) 34 model.add(layers.Dense(100, activation='relu')) 35 model.add(layers.Dense(2, activation = 'softmax')) 36 model.summary() 37 38 # complie the model 39 model.compile(optimizer='adam', 40 loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), 41 metrics=['accuracy']) 42 43 # train the generator 44 epochs = 10 45 history = model.fit_generator( 46 train_data_gen, 47 steps_per_epoch=8005// batch_size, 48 epochs=epochs, 49 validation_data=val_data_gen, 50 validation_steps=2023// batch_size 51 ) 52

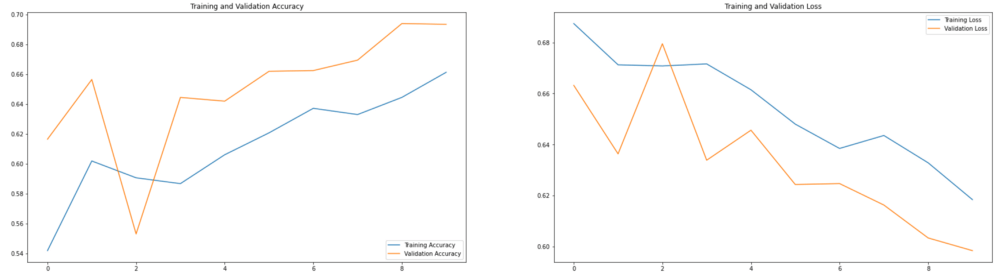
همانگونه که در دو دو نمودار زیر مشاهده میکنید، عملکرد مدل تا حدودی بهبود یافته است. در زمان آموزش، مدل میتوانست 69% از دادهها را به درستی پیشبینی کند و در زمان اعتبارسنجی آن بر روی دادههایی که قبلا ندیده بود، توانست 66% از دادهها را به درستی پیشبینی کند.
مدل به کمک تکنیکهای داده افزایی توانست تعمیم دهد و این در حالی است که در ابتدا نسبت به یک کلاس خاص سوگیری داشت و بیشتر دادهها را در همان کلاس قرار میدهد.
[irp posts=”17766″]این تکنیکها از این لحاظ خوب هستند که اگر مدل بتواند 80 تا 90 درصد از دادهها را به درستی یاد بگیرد، میتوانیم مطمئن شویم که در سناریوهای واقعی هم عملکرد یکسانی خواهد داشت.
با این وجود، عملکرد مدل هنوز هم به اندازه کافی خوب نیست. زمانی که مدل را با دادههای اعتبارسنجی آموزش میدهیم، عملکرد آن بین 65 تا 70 درصد است، اما ما امیدواریم بتوانیم مدل بسازیم که نرخ دقت آن بر روی بین 95 تا 100 درصد باشد. برای دستیابی به این هدف میتوانیم تعداد دورهای آموزش مدل را افزایش دهیم و یا تکنیکهای منظمسازی بیشتری به آن اضافه کنیم. در مقالات آتی بیشتر به این موضوع میپردازیم.
نتیجهگیری / مقایسه مدل
اگر به نتایج عملکرد مدل، پیش از اجرای تکنیکهای داده افزایی و پس از اجرای تکنیکهایی داده افزایی نگاه کنیم، متوجه میشویم که بیش برازش مدل تا زیادی کاهش پیدا کرده است و مدل ما توانست تعیم دهد.
نتایج حاصل از این مقایسه، این فرضیه را که تکنیکهای داده افزایی باعث کاهش بیشبرازش مدل و افزایش قابلیت مدل در تعیمدهی میشوند را تأیید و اثبات میکند. علاوه بر تمامی مواردی که گفته شد، با ارتقای معماری مدل هم میتوان عملکرد آن را بهبود بخشید.
معماری مدلی که در این مطلب آموزشی ساختیم، از 3 لایه کانولوشن با 32، 16 و 8 فیلتر و یک لایه FC و 2 لایه پنهان (300 نورون در لایه اول و 100 نورون در دومین لایه پنهان) تشکیل شده بود.
ما برای اینکه نشان دهیم معماریهای عصبی رایانشی هم میتوانند تعمیم دهند از این مدل استفاده کردیم؛ محاسبات ساده هم میتوانند با صرف هزینه کمتر این کار را انجام دهند و این در حالی است که معماریهای عصبی بزرگ برای انجام این کار انرژی زیادی صرف میکنند.





