

نگاهی به نقش هوش مصنوعی در سیستم های تشخیص چهره
 تیم تحریریه
تیم تحریریه- ۶ دی ۱۴۰۰
ایده «مَستر فیس » چندی پیش سر و صدای زیادی در رسانههای مختلف به پا کرده است. به مجموعهای از تصاویر جعلی که به دست الگوریتمهای یادگیری ماشین ساخته میشود، مستر فیس میگویند. این مفهوم با جعل هویت افراد، زمینه را برای نفوذ به سیستمهای بیومتریک فراهم میکند و سیستم های تشخیص چهره هم برای شناسایی آنها مشکلات زیادی دارند.
اما بررسیهای دقیق از نقاط ضعف فاحشی حکایت دارد که بعید است این ایده در محیط واقعی به کار برده شود. محققان در مقاله خود این چنین توضیح دادهاند: «مستر فیس به به تصویری از یک صورت اطلاق میشود که احراز هویت بخش بزرگی از جمعیت را امکانپذیر میکند. این شیوه بر پایه چهره افراد استوار است. میتوان از این چهرهها برای جعل هویت افراد استفاده کرد که احتمال موفقیت بالایی هم دارد؛ همچنین، نیاز نیست لزوماً به اطلاعات کاربر دسترسی داشته باشیم.»
به باور سه تَن از محققان هوش مصنوعی، اکنون مدلی ساخته شده که میتواند نُه مستر فیس ایجاد کند؛ این چهرهها میتوانند %40 از کل جمعیت را پوشش دهند. عملکرد این مدل به مراتب بهتر از سیستم های تشخیص چهره عمیقی بوده است که امروز به آنها دسترسی داریم.
عملکرد سیستم های تشخیص چهره
در نگاه اول، این نتایج بسیار شگفتآور به نظر میرسند، اما نرمافزارهایی که مستلزم شناسایی چهره هستند، با مشکلات امنیتی بزرگی روبرو خواهند شد. محققان در ابتدا از سیستم «StyleGAN» اِنویدیا برای ایجاد تصاویر واقعگرایانه از تصاویر غیرواقعی استفاده کردند. هر کدام از خروجیهای جعلی با یکی از تصاویر واقعیِ 5749 فرد مختلف در دیتاست LFW مقایسه شد. الگوریتم کلاسیفایر مجزایی تعیین میکند که چهرههای ایجاد شده با هوش مصنوعی در مقایسه با تصاویر واقعی در دیتاست چقدر به یکدیگر شباهت دارند.
تصاویری که امتیاز بالایی به لحاظ شباهت دارند، حفظ میشوند؛ بقیه تصاویر کنار گذاشته میشوند. از این امتیازها برای آموزشِ الگوریتمهای تکاملی استفاده میکنند تا تصاویر غیرواقعی بیشتری با سیستم «StyleGAN» ایجاد شود. این تصاویر شباهت زیادی به افراد در دیتاست دارند. محققان با گذشت زمان میتوانند مجموعهای از تصاویر «مستر فیس» پیدا کنند که بیشترین تعداد تصاویر را در دیتاست بازتاب دهد. به طور خلاصه، محققان به نُه تصویر دست یافتند که توانست بازتابدهنده %40 از 5749 فرد مختلف در دیتاست LFW باشد.
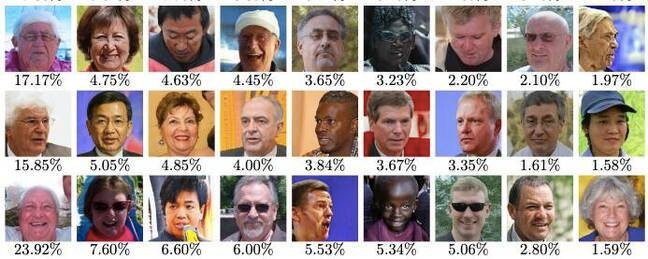
آنها در وهله بعدی از این تصاویر برای فریب سه مدل تشخیص چهره مختلف (Dlib, FaceNet, SphereFace) استفاده کردند. این سیستمها در مسابقه بهترین الگوریتمهای تطابق چهره به بالاترین امتیاز دست یافتند. نگاه اجمالی به مستر فیسهایی که بیشترین امتیاز را کسب کردند و قادرند عملکرد بهتری در مقایسه با سایر مدلها از خود بر جای گذارند، از محدودیتهای پژوهشی فاحشی حکایت دارد. این تصاویر همگی تا حد زیادی تصاویری جعلی از مردان مسن قفقازی هستند که ریش، عینک و موی سفید دارند. اگر این نوع از تصاویر قادر به نمایش حجم عظیمی از دیتاست LFW باشند، با اطمینان میتوان گفت که دیتاست ایراد دارد.

مخالفت با سیستم
اما یک وبسایت محتوایی در مخالفت با این سیستم منتشر کرده است: «گروههای بسیاری در دیتاست LFW به خوبی نشان داده نمیشوند. برای مثال، کودکان بسیار کمی پوشش داده شده است؛ هیچ خبری از نوزادان نیست، افراد بالای 80 سال چندان مورد توجه قرار نگرفتهاند؛ و جمعیت زنان نیز کمتر بررسی شده است. افزون بر این، اقلیتها نیز کمترین پوشش را در این دیتاست داشتهاند.» امتیاز نُه مستر فیس، محدودیتهای دیتاست LFW را نشان میدهد. چهره زنان با پوستهای تیره و جوان دارای امتیاز
پایینتری هستند؛ لذا، بعید است عملکردی بهتر از سه مدلِ آزمایش شده داشته باشند.
در وبسایت یاد شده آمده است: «اگرچه دیتاست LFW از بُعد نظری میتواند برای ارزیابی عملکرد زیرگروههای معینی مورد استفاده قرار گیرد، اما این دیتابیس به گونهای طراحی نشده که دارای دادههای کافی برای نتیجهگیریهای آماری قوی درباره زیرگروهها باشد. به تعبیری، LFW به قدر کافی بزرگ نیست تا شواهدی مبنی بر آزمایش جامع نرمافزاری خاص عرضه کند.»
اگرچه این ایده عده کثیری را مجذوب خود ساخته است که مستر فیس میتواند چهره تعداد عظیمی از افراد را جعل نماید و به سیستم های تشخیص چهره نفوذ یابد، اما پژوهش حاضر نمونهی دیگری از یک مدل یادگیری ماشین را به تصویر کشیده که با استفاده از دادههای معیوب آموزش یافته و آزمایش شده است. متخصصان میگویند که دادههای بهدردنَخور به خروجیهای بهدردنخور میانجامد. دیتاست LFW تنوع ناچیزی دارد؛ بنابراین، تصاویر چهرهای که با کامپیوتر ایجاد شده باشند، به احتمال زیاد بخش اعظمی از آن دیتاست را پوشش میدهند. بعید است این تصاویر کاربردهای حقیقی داشته باشند.
محدودیتهای LFW
تومر فریدلندر، یکی از نویسندههای مقاله و محقق هوش مصنوعی در مصاحبه با «The Register» اظهار داشت: «LFW از محدودیتهایی رنج میبرد که جزئیات آن در وبسایت رسمی توضیح داده شده است. علیرغم این محدودیتها، LFW به طور گسترده در پژوهشهای آکادمیک برای ارزیابی روشهای تشخیص چهره به کار میرود. مقاله ما به یکی از آسیبپذیریهای احتمالیِ سیستم های تشخیص چهره اشاره میکند که هکرها و عوامل متخاصم میتوانند از آن نقطه ضعف برای نیل به اهداف بدخواهانهی خود استفاده کنند.
بنابراین، توسعهدهندگان و کاربرانِ روشهای تشخیص چهره باید این مسائل را مد نظر قرار دهند. میتوان مدل را با دیتاستهای بهتری تطبیق داد که تنوع بیشتری دارند. ما تمایل بالایی برای بررسی این احتمال داریم که آیا میتوان از مستر فیسهای ایجاد شده با روش خودمان نیز برای پشتیبانی از سیستم های تشخیص چهره فعلی در مقابل چنین حملاتی استفاده کرد یا خیر. این موضوع باید در پژوهشهای آتی مورد استفاده قرار گیرد. نکته پایانی این است که فریب سرخطهای خبری را نخورید که میگویند چهره افراد به راحتیِ هر چه تمام میتواند جعل شود و مورد سوء استفاده قرار گیرد.»
به نظر شما اگر جعل تصویر قابل شناسایی نباشد چه مشکلاتی میتواند برای افراد ایجاد کند؟





