
شبکه عصبی Siamese و یادگیری One-shot: بیشترین کار با کمترین دیتا
 تیم تحریریه
تیم تحریریه- ۱۱ مهر ۱۴۰۰
بیاید با خبری شروع کنیم که ممکن است شما را کمی بترساند. البته نگران نباشید، بعد از آن خبرهای خوبی از شبکه عصبی برایتان داریم. چهار ماه پیش، دانشجویی در دانشگاه هنر و طراحیِ «امیلی کار» به دلیل استفاده از چک تقلبی، 600 دلار از حساب بانکیاش را از دست داد. نکته تعجببرانگیز این بود که این پول از چند چک به ارزش 100 دلار برداشت شد که یکی از چکها دارای امضای مشابه بود. کارکنان بانک باید مسئولیت این سرقت را برعهده بگیرند، زیرا نباید بدون بررسی دقیق امضا، اجازه برداشت را صادر میکردند.
اما اگر کارمند بانکی باشید که مجبور است هر روز صدها چک را به پول نقد تبدیل کند، شاید آن را کاری طاقتفرسا و خستهکننده بدانید. جذاب نمیشد اگر هوش مصنوعی و یادگیری عمیق در قرن 21 بتوانند با کمترین دخالت انسانی این مساله را حل کنند؟
اما چه راهحلی برای این مشکل وجود دارد؟ یادگیری One-shot و شبکه عصبی Siamese میتواند به حل این مشکل کمک کند!
شبکه عصبی Siamese
شبکه عصبی Siamese به یک شبکه عصبی مصنوعی گفته میشود که بسته به میزان شباهت ورودیها، از راهکار متمایزی برای بهکارگیری آنها استفاده میکند. پیش از اینکه معماری این شبکه را بررسی کنیم، نوعی از شبکه را در ذهنتان تصور کنید که برای تفکیک دو عکس از یکدیگر استفاده میشود. این کار میتواند بهوسیله دو شبکه پیچشی با پارامترهای از پیشتعیین شده انجام شود که از اختلاف میان آنها جهت تعیین شباهت دو عکس استفاده میشود.
این دقیقاً همان کاری است که شبکه Siamese انجام میدهد. معماری پیچشیِ متقارن، پذیرایِ انواع مختلفی از ورودیها است. این ورودیها شامل عکس، دادههای عددی، جملات و… هستند. وزنها با استفاده از تابع انرژی یکسانی که ویژگیهای متمایز هر ورودی را نشان میدهد، محاسبه میشوند.
اما این یک شبکه عصبی است! شبکه عصبی نیازمند مجموعه آموزشی بزرگی از عکس است تا مدل مفیدی بسازد. بنابراین، اگر مثالِ امضاء را در نظیر بگیرید، این شبکهها به نسخههای زیادی از امضای هر فرد نیاز دارند و این کار مقدور نیست.
چگونه میتوانیم با این مشکل کنار بیاییم؟ برای حل این مشکل باید مفهوم «یادگیری One-shot» را بدانیم. بر این اساس، فقط باید با یک یا چند عکس برچسبدار از هر دسته ممکن، آموزش را انجام دهیم. این روش مزیت بزرگی در مقایسه با روشهای سنتی یادگیری ماشین دارد، چرا که روشهای سنتی به صدها یا هزاران نمونه نیاز دارند.
گردش کار این الگوریتم چه ویژگیهایی دارد؟
در کنار یادگیری One-shot اکنون نوبت به بررسی جامع مدل رسیده است. شکل زیر اصول کاریِ شبکه عصبی Siamese را نشان میدهد:
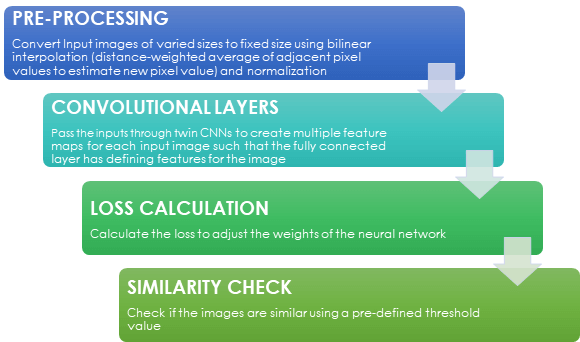
چگونه میتوان با یادگیری One-shot نمودار گردش کار شبکه عصبی Siamese را بادر مسئله تایید امضا به کار برد؟
پیشپردازش: مجموعهداده برچسبداری که برای آموزشِ شبکه عصبی Siamese استفاده میکنیم، باید بهصورت زیر باشد:

ANCHOR — امضای اصلی
POSITIVE — همان امضای اصلی
NEGATIVE — امضایی که فرق دارد
عکس امضاهای مختلف میتوانند در اندازههای متفاوت باشند. تمامی عکسهای ورودی با استفاده از روش درونیابی دوخطی به اندازه ثابت تبدیل میشوند. روش مقیاسبندی خاکستری مقیاسبندی خاکستری Grey scale هم برای تبدیل عکس های ورودی به سیاه و سفید استفاده شده است.
[irp posts=”17100″]شبکه عصبی
هر شبکه عصبی پیچشی از یک لایه پیچشی 11×11، یک لایه پیچشی 5×5 و دو لایه پیچشی 3×3 تشکیل شده تا چندین نگاشت ویژگی Feature map را تحت پوشش قرار دهد. هر یک از این نگاشتها ویژگی خاصی از عکس را نشان میدهند. تابع فعالسازیِ Activation function مورد استفاده «ReLU» نام دارد که با استفاده از واحدهای شبکه، به ایجاد مقادیرِ فعالسازیِ نامحدود میپردازد.
استفاده از روش «نرمالسازی واکنش محلی» Local response normalization نیز در دستور کار قرار دارد که میتواند حساسیت نورون را در مقایسه با محیط پیرامون آن، افزایش دهد و اگر فعالسازی در آن ناحیه زیاد باشد، بخشی از نورونها تضعیف میشوند.
از لایههای ادغام حداکثری 2×2 برای کاهش اندازه نگاشتهای ویژگی و از بروناندازی 0.3 و 0.5 برای کاهش حداقلیِ بیشبرازش استفاده میشود. در این راستا، واحدهای تصادفی در لایههای پنهان حذف میشوند. لایه نهایی یک لایه کاملاً متصل است که به صورت خطی با همه ویژگیهای عکس ورودی تلفیق شده است.

محاسبۀ زیان
توابع زیان برای تنظیم وزنهای شبکه عصبی در طی آموزش ضروری هستند. روش انجامِ کار به دو صورت است:
1. زیان مقابلهای دوبهدو (Pairwise Contrastive Loss):
در این روش از مقایسه میان دو جفت برای تخمینِ زیان در هر نقطه آموزشی، استفاده میشود. نقاط آموزشی به صورت مثبت یا منفی هستند. تابع زیان به محاسبه فاصله اقلیدسی (D) بین دو عکس آموزشی (s1,s2) با وزنهای آموزشیافته (w1,w2) میپردازد.
![]()
فاصله اقلیدسی (D)
![]()
زیان مقابلهای
شاید متوجه شده باشید که y برچسبی است که در مجموعه داده وجود دارد. اگر y=0 باشد، بدین معناست که (s1,s2) به دستههای یکسانی تعلق دارد. بنابراین، زیانِ حاصل از چنین جفتهای مشابهی برابر با D²(s1,s2) است. اگر y =1 باشد، میتوان اینطور برداشت کرد که (s1,s2) به دستههای مختلفی تعلق دارد.
بنابراین، زیانِ حاصل از جفتهای متفاوت برابر با max(0, α-D)² خواهد بود. یکی از مسائل پیچیدهای که ممکن است در طول آموزش با آن مواجه شویم، این است که شاید شبکه عصبی همه عکسها را به طور مشابه رمزگذاری کند. این عامل میتواند به راهحلهای پیشپا افتاده ختم شود (زیان صفر شود). بنابراین ابرپارامتر ‘α’ افزوده میشود تا میان جفتهای مثبت (s1,s2 = positive) و منفی (s1,s2 = negative) تفاوت ایجاد شود. مقدار این پارامتر معمولاً 1 تا 2 در نظر گرفته میشود. از این رو، زیان کل در نمونههای آموزشیِ M به صورت زیر خواهد بود:

2. زیان سهبخشی (Triplet Loss):
اگر از این روش استفاده میکنید، باید دادهها را پیشپردازش کنید تا به ساختار دلخواه برسید. زیانِ یک نقطه آموزشی خاص از فرمول زیر محاسبه میشود:

زیان سهبخشی
بر اساس فرمول فوق، پارامتر‘α’ نشان دهنده حاشیه است. s1، s2 و s₃ به ترتیب به معنای لنگر، امضای مثبت و امضای منفی یا متفاوت هستند. وزنها با استفاده از الگوریتم پسانتشار استاندارد بهروزرسانی میشوند.
بررسی مشابهت: پس از آموزشِ مدل، از آستانۀ ‘d’برای تعیین اینکه عکس به دسته یکسانی تعلق دارد یا خیر، استفاده میشود. انتخاب آستانه به شاخص عدم مشابهت بستگی دارد که با محاسبه فاصله اقلیدسیِ مجموعه آزمایشی به دست میآید.
شاخص عدم مشابهت پایینتر به این معناست که عکسها مشابه هستند؛ اما شاخص عدم مشابهت بالاتر بر این نکته دلالت دارد که عکسها با یکدیگر مطابقت ندارند. انتخاب آستانه باید نوعی مصالحه میان هر دو مورد باشد که بر اساس آزمون و خطا شناسایی میشوند.
آیا روشی ایدهآل برای انتخاب نقاط آموزشی وجود دارد؟
میدانیم که در موارد مثبت باید عکسهای مثبت امضا و لنگر در مجموعه آزمایشی یکسان باشند. اما در موارد منفی چه باید کرد؟ آیا میتوان از امضاهای منفی که تفاوت زیادی با لنگر دارند استفاده کرد؟ دو روش برای انتخاب نمونههای آموزشی قابل استفاده هستند.
نمونهگیری تصادفی: نمونه های ورودی به صورت تصادفی انتخاب میشوند.
نمونهگیری سخت: نمونهها بر این مبنا انتخاب میشوند که لنگر و عکسهای منفی به قدر کافی شبیه به هم هستند، اما قدری عدم مشابهت میان آنها دیده میشود.
مدل کاربردی باید ترکیبی از هر دو نمونه تصادفی و سخت را در خود داشته باشد. آیا تابهحال فکر کردهاید چرا به نمونههای سخت نیاز داریم؟ به مثال زیر از جفت مثبت s1,s2 نگاه کنید:

چون رمزگذاری s1 و s2 یکسان است، خواهیم داشت: D(s1,s2) ≥ 0. زیانِ این جفت آموزشی نزدیک به صفر است.
به مثال زیر از جفت منفی s1,s2 نگاه کنید:

چون رمزگذاری s1 و s2 خیلی متفاوت است، D(s1,s2) مقداری مثبت و بزرگتر از حاشیه خواهد بود. بنابراین، (0, α – D(s1,s2)) max صفر میشود. بنابراین، s1,s2 را به گونهای انتخاب کنید که s1 و s2 تقریباً مشابه باشند، نَه یکسان. این وضعیت مثلِ مقایسۀ امضای واقعی با امضای جعلی است. هدفمان این است که مدل بتواند این موارد را بررسی کند. حالا مثالی را در نظر بگیرید که وضعیت فوق را توصیف میکند:

در این مورد، s1 و s2 تقریباً مشابهاند، اما یکسان نیستند. به این نوع نمونهها «نمونههای سخت» گفته میشود.
بنابراین، در این مقاله یاد گرفتیم که چگونه با استفاده از این شبکه، یک سیستم تصدیق امضاء بسازیم. این روش چه کاربردها و منافع دیگری میتواند داشته باشد؟
یادگیری One-shot بسیار کاربردی است و از شبکه عصبی Siamese به عنوان ابزار استخدام و راهنمای شغلی استفاده میشود، چرا که میتواند فاصله معناییِ میان رزومههای مشابه و شرح وظایف را کاهش دهد و مواردی را که همخوانی ندارند، از هم جدا کند.
آیا رباتی وجود دارد که شما را بر اساس صدایتان بشناسد، بدون اینکه خودتان را معرفی کنید؟ شناسایی سخنگو با استفاده از ابزار تایید مبتنی بر شبکه عصبی پیچشی، از جمله موضوعات هیجانانگیزی است که میتوانید اطلاعات بیشتری درباره آن کسب کنید.
ردیابی چند نفری از یک محیط شلوغ، کاری چالشبرانگیزی است. در این راستا میتوان از روشهای ‘Learning by Tracking’ adapts Siamese CNN و ارتقای گرادیان استفاده کرد. این دو شبکه برای یادگیری میزان تشابهِ دو فریم با اندازه یکسان آموزش داده میشوند.





