

افزایش وضوح تصاویر کلاسیک با شبکه عصبی SRCNN
 تیم تحریریه
تیم تحریریه- ۴ خرداد ۱۴۰۰
مقاله حاضر به مرور و بررسیِ یک روش افزایش وضوح تصاویر کلاسیک تحت عنوان شبکه عصبی SRCNN (شبکه عصبی پیچشی سوپر رزولوشن Super-Resolution Convolutional Neural Network (SRCNN)) میپردازد. معمولاً در یادگیری عمیق یا شبکه عصبی پیچشی Convolutional Neural Network از CNN برای طبقهبندی تصاویر استفاده میشود. CNN در شبکه عصبی پیچشی سوپر رزولوشن برای سوپر رزولوشن تک تصویری مورد استفاده قرار میگیرد و مسئلهای کلاسیک در بینایی رایانه به شمار میآید. در صورت وجود سوپر رزولوشن تک تصویری، کیفیت بهتری در تصاویر بزرگ به دست میآید.

شبکه عصبی پیچشی سوپر رزولوشن (SRCNN)
با توجه به شکل فوق، شبکه عصبی پیچشی سوپر رزولوشن زمینه را برای بدست آوردن PSNR با مقدار 27.58 دسیبل فراهم میکند و این بسیار بهتر از Bicubic و کدگذاری پراکنده Sparse Coding (SC) است. محققان بسیاری به این موضوع علاقمند هستند و تحقیقات بسیاری در این زمینه انجام شده است. موضوع شبکه عصبی پیچشی سوپر رزولوشن در مقالههای 2014 ECCV و 2016 TPAMI به طور جامع مورد بررسی قرار گرفته و تاکنون بیش از هزار بار به آن مقاله ارجاع داده شده است.
چه موضوعاتی پوشش داده شده است؟
- شبکه SRCNN
- تابع زبان Loss function
- رابطه با کدگذاری پراکنده
- مقایسه با جدیدترین روشها
- مطالعه Ablation
1. شبکه SRCNN
شبکه در SRCNN عمیق نیست. فقط سه بخش به نام استخراج و نمایش وصلهها
Patch extraction and representation، نگاشت غیر خطی Non-Linear Mapping و بازسازی Reconstruction وجود دارد. جزئیات این بخشها را در شکل زیر مشاهده میکنید.
1.1 نمایش و استخراج وصلهها
باید به این نکته توجه داشت که اندازۀ ورودیِ با رزولوشن پایین در ابتدا با استفاده از فرایند bicubic interpolation تغییر داده میشود و این کار باید پیش از ارسال ورودی به شبکه SRCNN به انجام برسد.
X: تصویر برچسب خورده رزولوشن بالا Ground truth high-resolution image
Y: نمونه تصویر کم وضوح بهبود وضوح داده شده با الگوریتم Bicubic upsampled version of low-resolution image
لایه اول فرایند کانولوشن استاندارد را برای بدست آوردن (F1(Y انجام میدهد.
![]()
لایه اول
اندازه W1: c×f1×f1×n1
اندازه B1: n1
بر طبق معادله فوق، c، f1 و n1 به ترتیب نشاندهندۀ تعداد کانالهای تصاویر، اندازه فیلتر و تعداد فیلترها هستند. B1 است و برای افزایش درجه آزادی تا میزان 1 استفاده میشود.
در این مورد داریم: c=1, f1=9, n1=64.
1.2 نگاشت غیر خطی Non-Linear Mapping
در اقدام بعدی، نگاشت غیرخطی به انجام میرسد
لایه دوم
اندازه W2: n1×1×1×n2
اندازه B2: n2
بردار n1 بُعدی در بردار n2 بعدی ترسیم میشود. در صورتی که n1>n2 باشد، چیزی شبیه PCA Principal component analysis به دست میآید، اما به صورت غیرخطی خواهد بود.
در این مورد داریم: n2=32.
این 1×1 به کانولوشن 1×1 اشاره دارد که در شبکه NIN پیشنهاد شد. در شبکه NIN، کانولوشن 1×1 برای ارائه خاصیت غیرخطیِ بیشتر جهت افزایش دقت پیشنهاد میشود. این کانولوشن در GoogLeNet نیز برای کاهش تعداد پیوستها پیشنهاد شده است. اگر به این موضوع علاقمند هستید، مقاله مروری مرا در خصوص «کانولوشن 1×1 در GoogLeNet» مطالعه کنید.
1.3 بازسازی
پس از پایان نگاشت، باید به بازسازی تصویر پرداخت؛ بنابراین، عمل کانولوشن دوباره باید انجام شود.
![]()
لایه سوم
اندازه W3: n2×f3 ×f3×c
اندازه B3: c
2. تابع زیان

تابع زیان
در سوپر رزولوشن، تابع زیان L عبارت است از خطای جذر میانگین مربعات Average of mean square error (MSE)
در نمونههای آموزش (n).
3. رابطه با کدگذاری پراکنده

در کدگذاری پراکنده، از منظر کانولوشن، تصویر ورودی عبارت است از conv با f1 و n1=n2 معمولاً در مورد کدگذاری پراکنده (SC) دیده میشود. نگاشت n1 در n2 با همان ابعاد و بدون کاهش انجام میشود. این کار تا حد زیادی به نگاشت بردار رزولوشن پایین در بردار رزولوشن بالا شباهت دارد. سپس هر وصله با f3 بازسازی میشود. وصلههای همپوشانی به جای اینکه با وزنهای مختلف توسط کانولوشن با یکدیگر جمع بسته شود، میانگین گرفته میشوند.
4. مقایسه با جدیدترین روشها
از روی 91 تصویر موجود، برای آموزش تقریباً 24.800 تصویر با روش محوی گائوسی Gaussian Blurring ارائه میشود. عملِ آموزش روی GTX 770 GPU با 8×10⁸ پسانتشار 3 روز به طول میانجامد. مقیاسهای مختلف از 2 تا 4 آزمایش میشوند.


شبکه SRCNN بالاترین میانگین PSNR Peak signal to noise ratio را به دست میآورد.
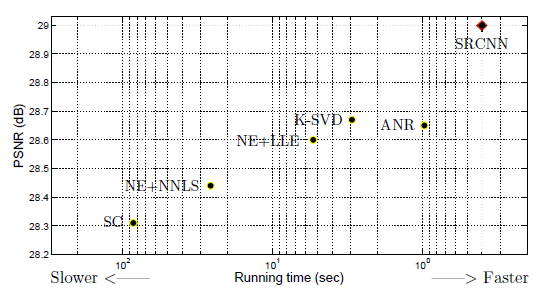
هر قدر به سمت راست تمایل داشته باشد، سرعت بالاتر است. هر چقدر بالاتر باشد، کیفیت بالاتر خواهد بود. SRCNN در سمت بالا گوشه سمت راست است و بهترین عملکرد را دارد.

چند ویژگی بصری:



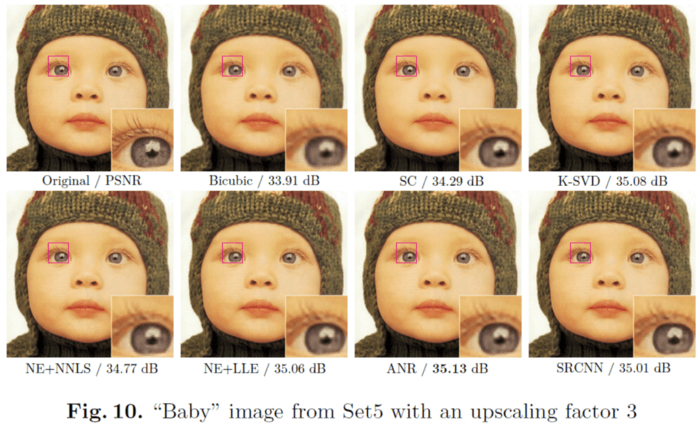
5. مطالعه Ablation

اگر شبکه SRCNN با استفاده از 395.909 تصویر اقدام به آموزش کرده باشد، نتیجهای که به دست میآید بهتر از آموزش با 91 تصویر است.

هر قدر n1 و n2 بزرگتر باشند، PSNR بالاتر خواهد بود. عادی است که در صورت وجود فیلترهای بیشتر، عملکرد بهتری حاصل آید. اگر اندازه فیلتر بزرگتر باشد، کیفیت نتایج قدری بهتر میشود. (اما در واقع فقط 3 لایه وجود دارد و این تعداد لایه برای اثبات مورد فوق کافی نیست. باید تعداد لایهها نیز افزایش پیدا کند. اگر لایههای بیشتری وجود داشته باشد، چند فیلتر کوچک جای فیلترهای بزرگتر را میگیرند.) SRCNN فقط سه لایه دارد.





