

شبکه پیچشی متراکم یا DenseNet و مروری بر آن (در مسائل ردهبندی تصویر)
 تیم تحریریه
تیم تحریریه- ۱۵ فروردین ۱۴۰۰
در این نوشتار DenseNet (شبکه پیچشی متراکم) را با هم مرور خواهیم کرد. شبکه پیچشی متراکم توسط یکی از مقالات 2017 CVPR مطرح شد که با بیش از 2000 ارجاع جایزهی بهترین مقاله را به خود اختصاص داد. این شبکهها حاصل همکاری مشترک دانشگاه کرنول Cornwell University، دانشگاه سینگوا Tsinghua University و تیم تحقیقاتی Facebook AI (FAIR) هستند.
شبکههای DenseNet به دلیل داشتن اتصالات متراکم، پارامترهای کمتر و دقت بالاتری نسبت به ResNet و Pre-Activation ResNet دارند.
فهرست مطالب
- بلوک متراکم Dense block
- معماری DenseNet
- مزایای DenseNet
- نتایج DenseNet روی دیتاستهای کوچک CIFAR و SVHN
- نتایج DenseNet روی دیتاست بزرگ ImageNet
- بررسی دقیقتر روش Feature Reuse
1- بلوک متراکم

در شبکه ConvNet استاندارد، تصویر ورودی وارد چندین کانولوشن شده و ویژگیهای سطح بالا دریافت میکند.

در ResNet برای ارتقای انتشار گرادیانی Gradient propagation از تابع نگاشت همانی Identity mapping استفاده میشود. عملیات جمع مؤلفهای Element-wise addition به کاررفته را میتوان به صورت الگوریتمهایی در نظر گرفت که حالتی را از یک ماژول ResNet به ماژول دیگر آن منتقل میکنند.

هرکدام از لایههای شبکه پیچشی متراکم ورودیهایی اضافی از همهی لایههای قبلی دریافت و نگاشتهای ویژگی خود را به لایههای بعدی منتقل میکند. از روش الحاق Concatenation نیز میتوان استفاده کرد؛ در این روش، هر لایه دانش جمعی Collective knowledge همهی لایههای قبلی را دریافت میکند.

از آنجایی که هر لایه نگاشتهای ویژگی همهی لایههای قبلی را دریافت میکند، شبکه میتواند باریکتر و فشردهتر باشد؛ یعنی تعداد کانالهای کمتری داشته باشد. نرخ رشد Growth rate k معیاری است که تعداد کانالهای اضافه شده در هر لایه را نشان میدهد.
بنابراین میتوان گفت شبکه پیچشی متراکم از نظر محاسباتی و حافظه کارآیی بیشتری دارد. شکل پایین مفهوم روش الحاق طی انتشار رو به جلو را نشان میدهد.

2- معماری DenseNet
لایهی اصلی تشکیلدهنده DenseNet

برای هر لایهی تشکیلدهنده، تابع پیش-فعالسازی BN (Batch Norm) و ReLU و سپس کانولوشن 3×3 را اجرا میکنیم؛ خروجی این توابع نگاشتهای ویژگی از k کانال است که، برای مثال، به منظور تبدیل x0, x1, x2, x3 به x4 مورد استفاده قرار میگیرند. ایدهی زیربنایی این مرحله از Pre-Activation ResNet گرفته شده است.
[irp posts=”3068″]DenseNet-B (لایههای گلوگاهی)

برای کاهش پیچیدگی و اندازهی مدل، کانولوشن BN-ReLU-1×1 قبل از کانولوشن BN-ReLU-3×3 اجرا میشود.
چندین بلوک متراکم با لایههای گذار

کانولوشن 1×1 و تابع میانگین تجمع Average pooling 2×2 که بعد از آن میآید به عنوان لایههای گذار بین دو بلوک متراکم همجوار استفاده میشوند.
نگاشتهای ویژگی درون یک بلوک متراکم هماندازه هستند تا بتوان عملیات الحاق را به راحتی روی آنها اجرا کرد.
در انتهای آخرین بلوک متراکم، یک تابع سراسری میانگین تجمع اجرا میشود و سپس یک کلسیفایر softmax به آن متصل میشود.
DenseNet-BC (فشردهسازی بیشتر)
اگر یک بلوک متراکم m نگاشت ویژگی داشته باشد، لایهی گذار θm نگاشت ویژگی به عنوان خروجی تولید میکند؛ θ (0<θ≤1 ) به فاکتور فشردهسازی Compression factor اشاره دارد.
وقتی θ=1 ، تعداد نگاشتهای ویژگی موجود بین لایههای گذار بدون تغییر باقی میماند. شبکه پیچشی متراکم که در آن θ<1، یک DenseNet-C است. در آزمایشات θ=0.5 بوده است.
زمانیکه هم لایههای گلوگاهی و هم لایههای گذاری با θ<1 مورد استفاده قرار میگیرند، مدل DenseNet-BC خواهد بود.
همهی شبکههای DenseNet صرف نظر از داشتن B/C، تعداد لایههای L و یا نرخ رشد k آموزش داده میشوند.
3- مزایای DenseNet
گردش گرادیان قوی

سیگنال خطا را میتوان به راحتی و به صورت مستقیمتر به لایههای قبلی انتشار داد. این عمل یک نظارت عمیق و ضمنی به شمار میرود، زیرا لایههای قبلی میتوانند تحت نظارت مستقیم لایهی ردهبندی نهایی قرار گیرند.
کارآیی محاسباتی و پارامتری
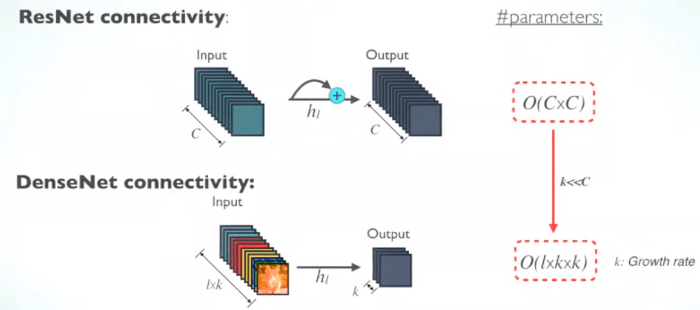
تعداد پارامترهای هرکدام از لایههای ResNet به صورت مستقیم از نسبت CxC تأثیر میپذیرند؛ اما تعداد پارامترهای شبکه پیچشی متراکم تحت تأثیر مستقیم نسبت و مقدار lxkxk هستند.
از آنجایی که k<<C ، اندازهی شبکه پیچشی متراکم بسیار کوچکتر از ResNet است.
ویژگیهای متفاوتتر (نامتجانستر)

از آنجایی که هر لایهی شبکه پیچشی متراکم همهی لایههای قبلی را به عنوان ورودی دریافت میکند، ویژگیهای متفاوتتر و الگوهای غنیتری دارد.
[irp posts=”3003″]نگهداری ویژگیهایی با پیچیدگی کمتر

در شبکهی استاندارد ConvNet، طبقه بند از پیچیدهترین ویژگیها استفاده میکند.

اما در شبکه پیچشی متراکم، ویژگیهایی که طبقه بند استفاده میکند سطوح متفاوتی از پیچیدگی دارند. در نتیجه این شبکه مرزهای تصمیمگیری Decision boundaries تولید میشود که درجه اطمینان بالاتری دارند. این امر میتواند توجیهکنندهی این موضوع باشد که چرا شبکه پیچشی متراکم روی دادههای آموزشی محدود، همچنان عملکرد خوبی از خود نشان میدهد.
4- نتایج شبکه DenseNet روی دیتاستهای کوچک CIFAR و SVHN
CIFAR-10
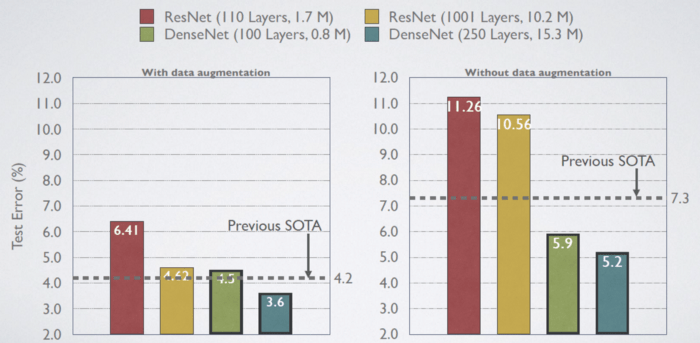
با دادهافزایی (C10+)، مقادیر خطای آزمایشی:
- Small-size ResNet-110: 6.41%
- Large-size ResNet-1001 (10.2M parameters): 4.62%
- State-of-the-art (SOTA) 4.2%
- Small-size DenseNet-BC (L=100, k=12) (Only 0.8M parameters): 4.5%
- Large-size DenseNet (L=250, k=24): 3.6%
بدون دادهافزایی (C10)، مقادیر خطای آزمایشی:
- Small-size ResNet-110: 11.26%
- Large-size ResNet-1001 (10.2M parameters): 10.56%
- State-of-the-art (SOTA) 7.3%
- Small-size DenseNet-BC (L=100, k=12) (Only 0.8M parameters): 5.9%
- Large-size DenseNet (L=250, k=24): 4.2%
همانطور که مشاهده میکنید، در استفاده از Pre-Activation ResNet به بیشبرازشی شدید برخورد میکنیم؛ اما شبکه DenseNet با وجود محدودیت در نوع آموزشی داده ها عملکرد خوبی از خود نشان میدهد، زیرا شبکه پیچشی متراکم از انواع ویژگیها با پیچیدگیهای متفاوت استفاده میکند.

CIFAR-100
همانطور که مشاهده میکنید، روند مشابهی در آزمایش روی دیتاست CIFAR-100 نیز اجرا شد:

جزئیات یافتهها
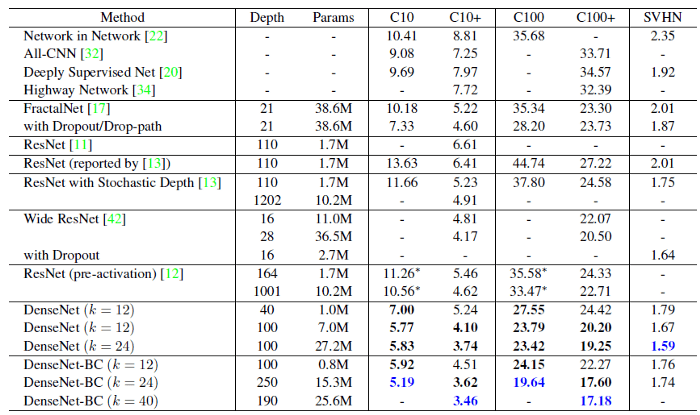
دادههای دیتاست SVHN شامل نمای پلاک خانهها از خیابان است. رنگ آبی نشاندهندهی بهترین نتایج است. DenseNet-BC نمیتواند به نتایجی بهتر از شبکهای اصلی DenseNet دست یابد. نویسندگان مقاله معتقدند SVHN نسبتاً ساده به شمار میرود و مدلهای بسیار عمیق روی چنین دیتاستهایی ممکن است به مشکل بیشبرازش overfitting برخورد کنند.
5-نتایج شبکه DenseNet روی دیتاست بزرگ ImageNet

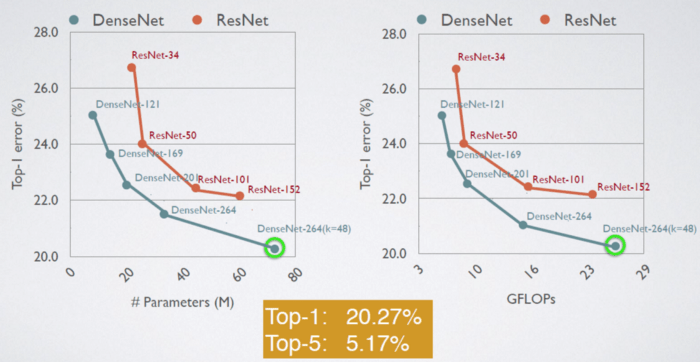
6- تجزیه و تحلیل روش Feature Reuse

- ویژگیهایی که توسط هرکدام از لایههای قبلی استخراج شدهاند به صورت مستقیم توسط لایههای عمیقتر همان بلوک متراکم مورد استفاده قرار میگیرند.
- وزن لایههای گذار نیز به لایههای پیشین انتشار مییابند.
- لایههای داخل بلوک متراکم دوم و سوم به صورت پیوسته، آخرین وزن را به خروجیهای لایههای گذار اختصاص میدهند (ردیف اول).
- به نظر میرسد وزنهای آخرین لایه، الحاقی از نگاشتهای ویژگی نهایی باشند. چندین ویژگی سطح بالای دیگر در مراحل انتهایی در شبکه تولید میشوند.





