

آنچه متخصصین علوم داده باید درباره پیش پردازش داده بدانند
 تیم تحریریه
تیم تحریریه- ۳۰ آذر ۱۴۰۰
آشنایی با مفاهیم پیش پردازش داده و اجرای آنها در هنگام استفاده از کتابخانه scikit learn
داده به مجموعهای از دانستهها، آمار، مشاهدات یا توصیفات مربوط به مفهومی گفته میشود که به صورت سازمانیافته و یا غیرسازمانیافته ارائه میشوند. دادهها انواع مختلفی دارند و برای نمونه میتوان به تصویر، واژه، اعداد و ارقام، نویسه، ویدئو، فایل صوتی و غیره اشاره کرد.
پیش پردازش داده
پیش از ساخت مدل ML و به منظور تحلیل دادهها و استخراج دانستهها از آنها لازم است دادهها را پردازش کنیم؛ به بیان سادهتر باید دادهها را به صورتی درآوریم که برای مدل قابل فهم باشند. دلیل آن هم این است که ماشینها قادر به درک دادههایی با فرمت تصویر، فایل صوتی و غیره ارائه میشوند، نیستند.
دادهها به نحوی پردازش (با فرمتی مناسب) میشوند که الگوریتم به سادگی بتواند آنها را تفسیر کند و خروجیِ مورد انتظار را تولید کند.
دادههایی که در دنیای واقعی استفاده میکنیم بی نقض نیستند؛ این دادهها ناکافی، غیرمنسجم (دارای داده پرت و مقادیر نویزی) و ساختارنیافته هستند. پیش پردازش داده های خام به سازماندهی، مقیاسبندی، پاکسازی (حذف دادههای پرت) و استانداردسازی آنها کمک میکند؛ به عبارت دیگر در این فرایند دادههای خام ساده میشوند و میتوانیم آنها را به الگوریتم ML تغذیه کنیم.
فرایند پیش پردازش داده از چندین مرحله تشکیل شده است:
- پاکسازی داده: دادههایی که استفاده میکنیم ممکن است داده گمشده Missing point (برای مثال سطرها و ستونهایی که هیچ مقداری در آنها وجود ندارد) و یا داده نویزی (دادههای بیربط که ماشین در تفسیر آنها به مشکل میخورد) داشته باشند. برای رفع مشکلاتی که به آنها اشاره شد میتوانیم سطرها و یا ستونهای خالی را حذف کنیم و یا آنها را با مقادیر دیگر پُر کنیم و برای دادههای نویزی هم میتوانیم از متدهای همچون رگرسیون و خوشهبندی استفاده کنیم.
- تبدیل داده: تبدیل داده به فرایندی اطلاق میشود که طی آن دادههای خام به فرمتی قابل فهم برای مدل تبدیل میشوند. فرایند تبدیل داده از مراحل گوناگونی از جمله کدبندی رستهای Categorical encoding ، مقیاسبندی، نرمالسازی، استانداردسازی و غیره.
- کاهش داده: این کار ضمن حفظ یکپارچگی دادههای اصلی به کاهش اندازه دادهها کمک میکند (برای تحلیل آسانتر).
کتابخانه Scikit-learn و پیش پردازش داده ها
Scikit-learn یک کتابخانه ML است که به صورت متنباز در دسترس است. این کتابخانه دارای ابزارهای مختلفی است و برای نمونه میتوان به الگوریتمهایی برای جنگلهای تصادفی، طبقهبندی، رگرسیون و البته پیش پردازش داده ها اشاره کرد. این کتابخانه بر روی NumPy و SciPy ساخته شده و یادگیری و کار کردن با آن آسان است.
برای بارگذاری این کتابخانه در فضای کاری (workspace) میتوانید از کد مقابل استفاده کنید:
import sklearn
برای بارگذاری ویژگیها (ابزارها) که در فرایند پیش پردازش داده کاربرد دارند میتوانید از کد زیر استفاده کنید:
from sklearn import preprocessing
در مقاله پیشرو به معرفی چند ویژگی اصلی پیش پردازش یعنی استانداردسازی، نرمالسازی، کدبندی رستهای، گسستهسازی، جایگذاری مقادیر گمشده، ایجاد ویژگیهای چندجملهای و مبدلهای سفارشی بسنده میکنیم.
استانداردسازی
استانداردسازی تکنیکی برای مقیاسبندی دادهها است به نحوی که میانگین دادهها صِفر (0) و انحراف معیار یک (1) شود. در این تکنیک دادهها به دامنه خاصی محدود نیستند. زمانیکه دامنه تغییرات (Range) میان ویژگیهای دیتاست ورودی طولانی باشد میتوانیم از تکنیک استانداردسازی استفاده کنیم.

به مثال روبهرو توجه کنید:
from sklearn import preprocessing import numpy as np x = np.array([[1, 2, 3], [ 4, 5, 6], [ 7, 8, 9]]) y_scaled = preprocessing.scale(x) print(y_scaled)
در این مثال ابعاد آرایه ورودی 3×3 است و مقادیر آن در بازه 1 تا 9 قرار دارند. با استفاده از تابع scale که در preprocessing قرار دارد میتوانیم دادهها را مقیاسبندی کنیم.

StandardScaler یکی دیگر از توابع موجود در این کتابخانه است؛ با استفاده از این تابع میتوانیم میانگین و انحراف معیارِ دیتاست آموزشی را محاسبه کنیم و با اجرای Transformer API مجدداً همان تبدیلات را بر روی دیتاست آموزشی اعمال کنیم.
اگر بخواهیم ویژگیها در یک دامنه مشخص مقیاسبندی شوند میتوانیم از MinMaxScaler (با استفاده از پارامتر feature_range=(min,max )) و یا MinAbsScaler استفاده کنیم ( تفاوت آنها در این است که حداکثر مقدار مطلقِ هر ویژگی در MinAbsScaler طبق اندازه واحد مقیاسبندی میشود).
from sklearn.preprocessing import MinMaxScaler import numpy as np x = MinMaxScaler(feature_range=(0,8)) y = np.array([[1, 2, 3], [ 4, -5, -6], [ 7, 8, 9]]) scale = x.fit_transform(y) scale
در این مثال، مقادیر آرایهای با ابعاد 3×3 در بازه (0,8) قرار دارند و با اجرای تابع .fit_transform() توانستیم همان تبدیلات را بر روی دیتاست دیگری هم اِعمال کنیم.

نرمالسازی
در تکنیک نرمالسازی دادهها در بازه 1- و 1 قرار میگیرند؛ به عبارت دیگر مقادیر (مقیاس) دادهها یکسانسازی میشود. اجرای این تکنیک این اطمینان را به ما میدهد که مقادیر بزرگِ دیتاست بر فرایند یادگیری مدل تأثیر نمیگذارند و تأثیر یکسانی بر روند یادگیری مدل دارند. در صورتی که بخواهیم شباهت میان دو نمونه، برای مثال ضرب نقطهای، را به صورت عددی نشان دهیم، میتوانیم از این تکنیک استفاده کنیم.
from sklearn import preprocessing import numpy as np X = [[1,2,3], [4,-5,-6], [7,8,9]] y = preprocessing.normalize(X) y

این ماژول جایگزین دیگری برای Transformer API دارد، با اجرای تابع Normalizer نیز میتوانیم همین عملیات را انجام دهیم.
کدبندی ویژگیهای رستهای
در بسیاری ممکن است دادههایی که از آنها استفاده میکنیم ویژگی مقادیر را به صورت پیوسته نداشته باشند و در عوض ویژگی مقادیر به صورت دستههایی با برچسب متنی باشد. برای اینکه مدل ML بتواند این نوع دادهها را پردازش کند، لازم است این ویژگیهایی رستهای را به نحوی تبدیل کنیم که برای مداشین قابل فهم باشند.
این ماژول دارای دو تابع است که با اجرای آنها میتوانیم ویژگیهای رستهای را کدبندی کنیم:
OrdinalEncoder: با اجرای این تابع ویژگیهای رستهای به مقادیر صحیح تبدیل میشوند، به این صورت که تابع هر یک از ویژگیهای رستهای را به یک ویژگی جدید از مقادیر صحیح (0 تا 1-n_categories ) تبدیل میکند.
import sklearn.preprocessing import numpy as np enc = preprocessing.OrdinalEncoder() X = [['a','b','c','d'], ['e', 'f', 'g', 'h'],['i','j','k','l']] enc.fit(X) enc.transform([['a', 'f', 'g','l']])
در این مثال سه رسته به صورت 0,1,2 کدبندی شدهاند و خروجیِ ورودی فوق به صورت زیر است:
![]()
- OneHotEncode: این انکودر با استفاده از مقادیر احتمالی n_categories هر یک از ویژگیهای رستهای را به ویژگیهای باینری n_categories تبدیل میکند، به نحوی که یکی از آنها 1 و سایر ویژگیها برابر با 0 خواهند بود. برای درک بهتر این مطلب به مثال مقابل توجه کنید:
import sklearn.preprocessing import numpy as np enc = preprocessing.OneHotEncoder() X = [['a','b','c','d'], ['e', 'f', 'g', 'h'],['i','j','k','l']] enc.fit(X) enc.transform([['a', 'f', 'g','l']]).toarray().reshape(4,3)

گسستهسازی
در فرایند گسستهسازی ویژگیهای پیوستهی دادهها به مقادیر مجزا تبدیل میشوند ( این فرایند با نامهای binning و کوانتیزاسیون هم شناخته میشود). این فرایند مشابه ایجاد یک هیستوگرام با استفاده از دادههای پیوسته است ( که در آن گسستهسازی بر اختصاص مقادیر ویژگی به این binها تمرکز دارد). برخی مواقع به کمک گسستهسازی میتوانیم غیرخطی را در مدلهای خطی تعریف کنیم.
import sklearn.preprocessing
import numpy as np
X = np.array([[ 1,2,3],
[-4,-5,6],
[7,8,9]])
dis = preprocessing.KBinsDiscretizer(n_bins=[3, 2, 2], encode='ordinal')
dis.fit_transform(X)
این تابع با استفاده از KBinsDiscretizer() ویژگیها را به k عدد bin گسستهسازی میکند. خروجی به صورت پیش فرض one-hot encoded میشود و به کمک پارامتر encode میتوانیم آن را تغییر دهیم.
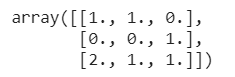
جایگذاری مقادیر گمشده
در این فرایند مقادیر گمشده ( Nanها، فضاهای خالی و غیره) با نسبت دادن یک مقدار به آنها پردازش میشوند (فرایند جایگذاری بر مبنای بخشهای مشخص دیتاست انجام میشود)، در نتیجه مدل میتواند دادهها را پردازش کند. برای درک بهتر این فرایند به مثال زیر توجه کنید:
from sklearn.impute import SimpleImputer import numpy as np impute = SimpleImputer(missing_values=np.nan, strategy='mean') X = [[np.nan, 1,2], [3,4, np.nan], [5, np.nan, 6]] impute.fit_transform(X)
در این مثال، برای جایگذاری مقادیر گمشده از تابع SimpleImputer() استفاده کردیم. پارامترهاییی که در این تابع مورد استفاده قرار گرفتند عبارتند از: missing_values ، برای مشخص کردن مقادیر گمشدهای که باید جایگذاری شوند، strategy ، برای مشخص کردن شیوه جایگذاری مقادیر، همانگونه که در مثال فوق مشاهده میکنید ما از mean استفاده کردیم؛ منظور از mean این است که مقادیر گمشده با میانگین مقادیر موجود در ستون جایگزین خواهند شد. از پارامترهای دیگری همچون میانه و مد، most_frequent (بر مبنای بشامد تکرار یک مقدار در یک ستون) یا constant (مقدار ثابت) هم میتوانیم برای strategy استفاده کنیم.
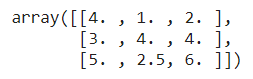
ایجاد ویژگیهای چندجملهای
برخی مواقع برای اینکه مدل به نتایج دقیقتری دست پیدا کند بهتر است مدل را با غیرخطی کردن آن پیچیده کنیم. برای انجام این کار میتوانیم تابع PolynomialFeatures() را اجرا کنیم.
import numpy as np
from sklearn.preprocessing import PolynomialFeatures
x = np.array([[1,2],
[3,4]])
nonl = PolynomialFeatures(2)
nonl.fit_transform(x)

در مثال فوق، در تابع PolynomialFeatures() میزان غیر خطی بودن مدل را 2 تعیین کردیم. مقادیر ویژگیِ آرایه ورودی از (X1,X2) به (1,X1,X2,X12, X1*X2,X22) تبدیل شدند.
مبدلهای سفارشی
اگر بخواهیم با استفاده از یک تابع خاص (موجود در پایتون) کُل دادهها را برای عملیات خاصی همچون پردازش و یا پاکسازی دادهها تبدیل کنیم، با اجرای تابع FunctionTransformer() میتوانیم یک مبدل سفارشی بسازیم و تابع مورد نظر را در آن بنویسیم.
import sklearn.preprocessing
import numpy as np
transformer = preprocessing.FunctionTransformer(np.log1p, validate=True)
X = np.array([[1,2,3],
[4,5,6],
[7,8,9]])
transformer.transform(X)
در این مثال، برای تبدیل مقادیر دیتاست از تابع لگاریتمی استفاده کردیم:

جمعبندی
امیدوارم این مقاله به شما در درک بهتر مفاهیم و مراحل پیش پردازش داده در مدلهای ML کمک کرده باشد و بتوانید این تکنیکها را در دادههای واقعی هم به کار ببندید.
توصیه میکنم برای درک بهتر این مفاهیم یک بار این تکنیکها را بر روی دادههایتان اجرای کنید. دست از یادگیری داده کاوی برندارید، مطمئن باشید در این مسیر ویژگیهای جدیدی کشف خواهید کردید.





