

مسیر پردازشی یادگیری عمیق و نحوه تسریع فرایند مراحل آن
 تیم تحریریه
تیم تحریریه- ۲۹ آذر ۱۴۰۰
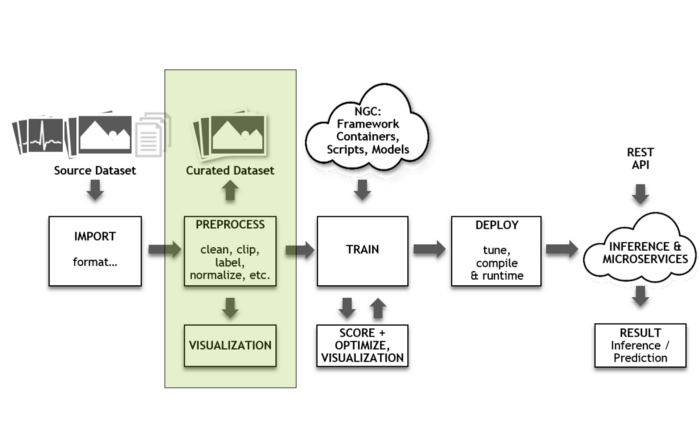
پیشپردازش
به محض اتمام فراخوانی، دادهها در ابتدا باید مرحله پیشپردازش یا دادهافزایی را پشت سر بگذارند. دادهها در این مرحله برای آموزش آماده میشوند. علاوه بر این، دیتاست هم به همراه نمونههای بیشتر برای هوشمندتر کردنِ شبکه اضافه میشود. برای نمونه، امکان چرخاندن، مقیاسدهی و دستکاری تصاویر فراهم میآید. چون تصاویر برچسبدار هستند، میتوانید شبکه را با این نمونههای تغییریافته آموزش داده و آن را توانمندتر کنید. کتابخانه منبع باز «DALI GPU» سرعت فرایند دادهافزایی را افزایش میدهد.
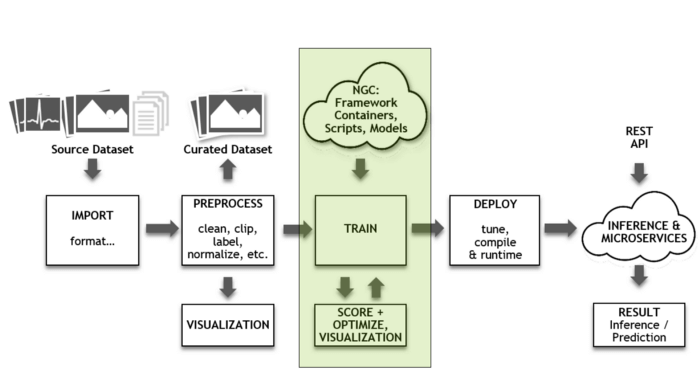
آموزش
با نزدیک شدن به بخش اصلی مرحله آموزش، نمونهدادهها (تصاویر، نمونههای صوتی، بخشهای زبانی و غیره) تا جایی که سطح قابلقبولی از دقت یا همگرایی به دست آید، در شبکه بررسی میشوند. در اینجا شبکه شروع به حدس زدن بر روی ورودی میکند (استنتاج). این استنتاج با پاسخ درست مورد مقایسه قرار میگیرد.
[irp posts=”14736″]اگر شبکه به درستی حدس بزند، کارِ آموزش ادامه مییابد. اگر حدس اشتباه باشد، مقدار خطایی محاسبه میشود و در مسیر برگشت شبکه انتشار مییابد تا سرانجام پاسخ یا وزن درست حاصل آید. این فرایند تا جایی تکرار میشود که شبکه به سطح قابلقبولی از دقت برسد (مثلاً 90 درصد). این فرایند آموزش تکراری تاثیرگذار است، اما حساسیت محاسبات در آن بالاست. اگرچه کیفیت خروجی در این فرایند خیلی خوب است، اما دقت و همگرایی نیز به همان اندازه حائز اهمیت هستند و باید برای بهبود این دو مورد تلاش کرد. NVIDIA افزون بر افزایش سرعتِ چارچوبهای یادگیری عمیق، به توسعه قابلیت «دقت ترکیبی خودکار یا AMP» نیز در تنسورفلو، MXNet و PyTorch پرداخته است.
این کتابخانه عملیات ریاضی را با دقت FP16 انجام داده و نتایج را در FP32 انباشت میکند. AMP میتواند چهار برابر سریعتر به راهحل رسیده و دقت نتایج را نیز حفظ کند. AMP به صورت رایگان در NGC قابل دسترس است. امکان دسترسی به مدلهای از پیشآموزشدیده و کد مدلها در NGC فراهم شده است. هدف از این کار این است که پروژههای خود را با سرعت بیشتری انجام دهید. علاقمندان میتواند به اطلاعات جامعی در خصوص نحوه استفاده از این ابزارها در وبسایت NVIDIA Developer دسترسی پیدا کنند.
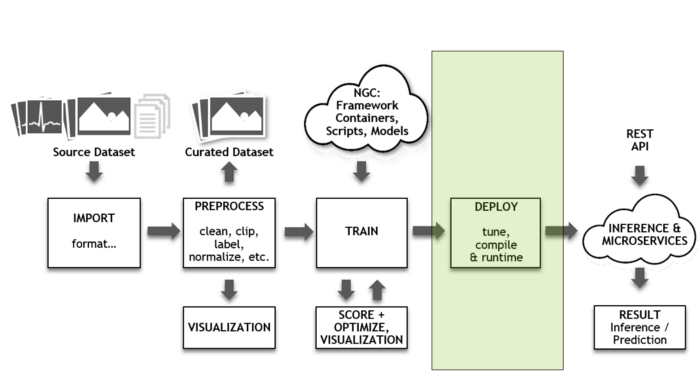
بهینهسازی استنتاج
به محض اینکه شبکه با سطح قابلقبولی از دقت آموزش داده شد، باید از آن برای استنتاج در خصوص دادههای جدید استفاده شود. سادهترین روش استنتاج این است که نمونهها را در چارچوب شبکه به اجرا در آورده و از شبکه پسانتشار خودداری کنید. با این حال، این اقدام برای انجام استنتاج بهینه نیست.
[irp posts=”19199″]سرویسهای هوش مصنوعی به دنبال ارائه بالاترین سطح خدمات با کمترین تعداد سرور هستند. بخش اعظمی از فرایند بهینهسازی با استفاده از FP16 و INT8 انجامپذیر است. این اقدام باعث میشود توسعهدهندگان با سرعت بیشتری شبکهها را بهینهسازی کرده و زمینه برای بکارگیری شبکهها با بالاترین سطح توانش عملیاتی و دقت قابلتوجهی فراهم شود. TensorRT به خوبی در چارچوب تنسورفلو ادغام میشود، به طور کامل از ONNX پشتیبانی میکند و به صورت رایگان در NGC قابل دسترس است.
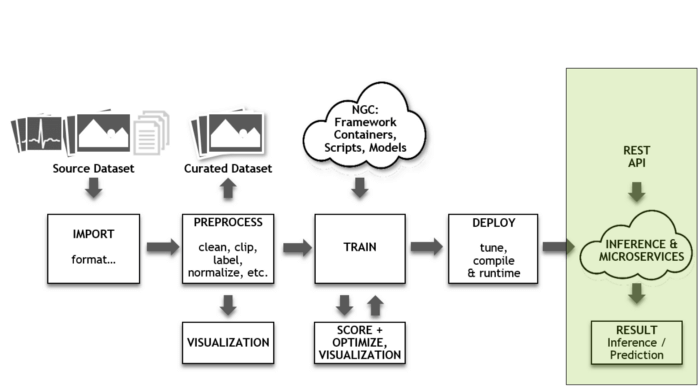
استقرار
اکنون که کارِ آموزش شبکه به منظور انجام استنتاج به پایان رسیده، باید دید شبکه در عمل چگونه کار میکند. همانطور که در بخشهای فوق اشاره شد، عملِ آموزش اساساً بر توانش عملیاتی، خروجی و همگرایی تاکید میکند. با این حال، عوامل عملکردی دیگری در استنتاج دخیل هستند که از جملۀ آنها میتوان به توانش عملیاتی، خروجی، دقت، تاخیر و کارآیی اشاره کرد. قابلیت برنامهنویسی و انطباقپذیری نیز از جمله عوامل کلیدی به شمار میآیند که سرعت طیف وسیعی از شبکهها را افزایش میدهند.
استنتاج در دو دسته جای میگیرد: حجم کاری با توان بالا و خدمات حساس به تاخیر بلادرنگ که باید بلافاصله پاسخ درست را ارائه کنند. شبکهها و مجموعهدادهها با سرعت قابل توجهی در حال رشد هستند. شرکت مایکروسافت به تازگیGPU-accelerated service را معرفی کرد. این سرویس از سه نوع متفاوت شبکه استفاده میکند ( شناسایی اشیا، Object detection پرسش و پاسخ و متن به گفتار text-to-speech ). اکنون TensorRT Inference Server را برای کاربرد آسانِ این سرورها توسط مدیران زیرساخت IT و DevOps پیشنهاد میکنیم.
[irp posts=”20561″]Inference Server میتواند استفاده از GPU را افزایش دهد. این سرور از یکپارچهسازی kubernates برای مقیاسدهی، توزیع پردازش Load-Balancing و فعالیتهای ارتباطی به طور مساوی بر روی سروهای اصلی شبکههای کامپیوتری استفاده میکند. این سرور متنباز این فرصت را به چندین شبکه میدهد تا در یک GPU اجرا شوند. استنتاج و آموزش مسیر پردازشی یادگیری عمیق به دلیل ماهیت محاسباتی حساسی که دارند، باید مورد توجه ویژه قرار گرفته و تدابیری برای افزایش سرعت این فرایندها اندیشیده شود. پلتفرم مرکز داده NVIDIA امکان افزایش سرعت این فرایندها را نه تنها در یادگیری عمیق، بلکه در یادگیری ماشین و غیره فراهم میکند.





