

چطور یادگیری نیمهنظارتشده و خودنظارتی مشکل داده های نامتوازن را حل میکنند
 تیم تحریریه
تیم تحریریه- ۴ بهمن ۱۴۰۰
کار پژوهشی اخیر ما مقالهی Rethinking the Value of Labels for Improving Class-Imbalanced Learning بود که در کنفرانس NeurIPS 2020 نیز پذیرفته شد. در این مقاله اساساً به مسئلهی در شرایط عدم توازن دادهها (که به عنوان توزیع دادهها با دنبالهی کشیده نیز شناخته میشود) پرداختیم که مسئلهای قدیمی و در عین حال متداول و کاربردی به شمار میرود. طی مدلسازی نظری و آزمایشات گسترده دریافتیم در شرایطی که با داده های نامتوازن سروکار داریم، یادگیری نیمهنظارتشده و خودنظارتی میتوانند عملکرد یادگیری را تا حد چشمگیری بهبود ببخشند.
منبع کد (به همراه دادههای مربوطه و بیش از ۳۰ مدل آموزشدادهشده) را میتوانید در این لینک GitHub مشاهده کنید.
دستاورد اصلی این مقاله، تأیید نظری و تجربی این بوده است که در مسائل یادگیری روی دادهها (دستهها)ی نامتوازن میتوان با استفاده از:
- یادگیری نیمهنظارتشده (که به استفاده از دادههای بدون برچسب اشاره دارد)،
- یادگیری خودناظر (فرآیندی که در آن از هیچ داده اضافی استفاده نمیشود، بلکه در ابتدای کار، تنها یک گام پیشآموزش خودناظر روی داده های نامتوازن، بدون در دست داشتن برچسبها، اجرا میگردد)،
عملکرد مدل را بهبود بخشید. سادگی و انعطافپذیری این تکینکها باعث میشود بتوانیم به آسانی آنها را با روشهای قدیمی ترکیب کرده و یادگیری را بیشتر افزایش دهیم.
در این نوشتار ابتدا پیشزمینهای از مسئلهی داده های نامتوازن و پژوهشهای مربوطه ارائه میدهیم. سپس بدون پرداختن به جزئیات اضافه، فرضیات و روشهای خود را توضیح خواهیم داد.
پیشزمینه مشکل داده های نامتوازن در دنیای واقعی کاملاً متداول است. دادههای واقعی عموماً توزیع نرمال و ایدهآلی ندارند و اغلب نامتوازن هستند. اگر دستههای دادهها را براساس تعداد نمونههای موجود در آنها از زیاد تا کم مرتب کنیم، توزیعی از دادهها به دست خواهیم آورد که اصطلاحاً به آن توزیع با دنبالهی کشیده میگویند؛ ما این مسئله را اثر دنبالهی کشیده میخوانیم. توزیع برچسبها در دیتاستهای بزرگ غالباً دنبالهی کشیده دارد:

مشکل عدم توازن دستهها نه تنها در مسائل کلاسبندی، بلکه در مسائل تشخیص شیء یا قطعهبندی تصویر نیز دیده میشود. علاوه بر حوزهی بینایی، در کاربردهای مهم در حوزههایی همچون امنیت یا بهداشت و سلامت (مثل رانندگی خودکار و یا تشخیص بیماریها) نیز دادهها ذاتاً به شدت نامتوازن هستند.
چرا عدم توازن وجود دارد؟ یک توضیح ساده این است که گردآوری نوع خاصی از دادهها کار دشواری است. برای مثال مسئلهی کلاسبندی گونههای جانوری (دیتاست بزرگ iNaturalist) را در نظر بگیرید. برخی از گونهها (مثل گربه یا سگ) فراوانی و رواج زیادی دارند، اما بعضی دیگر از گونهها (مثل کرکس) بسیار نادر هستند. در مسئلهی رانندگی خودکار نیز دادههای مربوط به رانندگی معمولی بخش عمدهی دیتاست را تشکیل میدهند، اما دادههای مربوط به یک موقعیت غیرعادی یا تصادف خیلی کمتر هستند. در تشخیص بیماری هم نسبت تعداد افرادی که بیماریهای خاص دارند به جمعیت عادی بسیار نامتوازن است.
مشکل «دادهها با دنبالهی کشیده» یا «داده های نامتوازن» چیست؟ اگر نمونههای نامتوازن را مستقیماً وارد مدلی کنیم تا بر اساس اصل ERM (کمینهسازی ریسک تجربی) بیاموزد، مدل روی نمونههای موجود در دستههای اکثریت یادگیری بهتری خواهد داشت، اما قابلیت تعمیمپذیری آن به دستههای اقلیت کاهش مییابد. زیرا تعداد نمونههایی که از دستههای اکثریت میبیند بسیار بیشتر از دستههای اقلیت است.
در حال حاضر چه راهکارهایی برای مقابله با داده های نامتوازن وجود دارد؟ ما راهکارهای اصلی موجود را در این دستهها جمعبندی کردیم:
- نمونهگیری مجدد: تکنیکهای این رویکرد را میتوان به دو دسته تقسیم کرد: بیشنمونهگیری نمونههای اقلیت و کمنمونهگیری نمونههای اکثریت. بیشنمونهگیری به بیشبرازش طبقهی اقلیت اشاره دارد و باعث میشود مدل نتواند ویژگیهای قویتر و تعمیمپذیرتر را بیاموزد؛ به علاوه، تکنیک بیشنمونهگیری در کار با دادههای به شدت نامتوازن اغلب عملکرد ضعیفی دارد. از سوی دیگر روش کمنمونهگیری منجر به از دست دادن شدید اطلاعات مربوط به دستهی اکثریت شده و درنتیجه مشکل کمبرازش را به وجود میآورد.
- نمونههای ساختگی: در این راهکار، دادههایی مشابه با نمونههای اقلیت تولید میشوند. روش کلاسیک SMOTE از تکنیک K نزدیکترین همسایه برای انتخاب نمونههای مشابه با نمونههای اقلیتی استفاده میکند که به صورت تصادفی انتخاب شدهاند و سپس از طریق درونیابی خطی نمونههای جدید تولید میکند.
- وزندهی مجدد: در این روش به دستههای مختلف (یا حتی نمونههای مختلف) وزنهای متفاوت اختصاص داده میشود. توجه داشته باشید که وزن میتواند انطباقی باشد. این روش نسخههای متعددی دارد که سادهترین آنها وزندهی براساس تعداد متقابل دستههاست.
- یادگیری انتقال: ایدهی زیربنایی این راهکار، مدلسازی ردههای اکثریت و اقلیت به صورت مجزا و سپس انتقال اطلاعات/بازنماییها/دانش مربوط به نمونههای اکثریت به دستهی اقلیت است.
- یادگیری متریک: این روش اصولاً به یادگیری تعبیههای بهتر و مدلسازی بهتر مرزها/حاشیههای نزدیک به دستههای اقلیت اشاره دارد.
- فرایادگیری /انطباق حوزهای: برای یادگیری شیوهی وزندهی مجدد یا فرمولبندی مشکل به عنوان یک مسئلهی انطباق حوزهای میتوان دادههایی که در ابتدا و انتهای توزیع قرار دارند را به صورت متفاوت پردازش کرد.
تا اینجا با پیشزمینه و روشهای متداول آشنا شدیم. با این حال در کار با دادههای به شدت نامتوازن، حتی اگر از الگوریتمهای تخصصی مثل نمونهگیری مجدد داده یا تابع زیان توازن-طبقه استفاده کنیم، عملکرد مدل عمیق همچنان دچار فرسایش خواهد شد. بنابراین لازم است تأثیر توزیع نامتوازن برچسب دادهها را به خوبی درک کنیم.
انگیزش و ایدهها
ما سعی در پیدا کردن راهکاری متفاوت با موارد بالا داشتیم و بدین منظور تصمیم گرفتیم از «ارزش» برچسبهای نامتوازن استفاده کنیم. برچسبها در کار با داده های نامتوازن، بر خلاف دادههای نرمال، نقشی بسیار حیاتی ایفا میکنند. اما در مورد «ارزش» این نقش با یک دوراهی روبرو هستیم: (1) از یک سو معمولاً الگوریتمهای یادگیری نظارتشده نسبت به الگوریتمهای بدون نظارت دستهبندهای دقیقتری ایجاد میکنند؛ این نکته حاکی از ارزش مثبت برچسبهاست. (2) اما از سوی دیگر، برچسبهای نامتوازن ذاتاً منجر به «سوگیری برچسب» طی یادگیری میشوند و بدین ترتیب تصمیمگیری نهایی عمدتاً توسط کلاس اکثریت صورت میگیرد؛ این امر نشاندهندهی تأثیر منفی برچسبهاست. پس میتوان گفت برچسبهای نامتوازن همچون شمشیری دولبه هستند و سؤال مهم این است که چطور میتوان برای بهبود یادگیری دستههای نامتوازن از ارزش برچسبها بیشترین بهره را برد؟
بدین ترتیب سعی کردیم به صورت سیستماتیک دو نقطهنظر متفاوتی که بالا بیان شد را تجزیه و تحلیل کنیم. نتایج پژوهش ما نشان داد که میتوان از هر دو رویکرد استفاده کرد و با بهرهگیری از ارزش مثبت و همچنین منفی برچسبهای نامتوازن، دقت نهایی دستهبند را ارتقاء بخشید:
- رویکرد مثبت: دریافتیم وقتی دادههای بدون برچسب زیادی داریم، برچسبهای نامتوازن میتوانند اطلاعات نظارتی نادری فراهم کنند. بدین ترتیب حتی اگر دادههای بدون برچسب توزیعی با دنبالهی کشیده داشته باشند، میتوانیم از یادگیری نیمهنظارتشده استفاده کرده و نتایج نهایی کلاسبندی را به میزان چشمگیری بهبود ببخشیم.
- رویکرد منفی: برچسبهای نامتوازن همیشه هم مفید نیستند؛ عدم توازن برچسبها یقیناً باعث سوگیری میشود. بنابراین طی آموزش ابتدا باید اطلاعات برچسبها را کنار بگذاریم و سپس از طریق یادگیری خودنظارتی، درک خوبی از ویژگیها به دست بیاوریم. یافتههای ما نشان میدهند مدلی که به روش خودناظر پیشآموزش دیده باشد، میتواند دقت کلاسبندی را به شکل موفقیتآمیز بهبود ببخشد.
یادگیری نامتوازن با دادههای بدون برچسب
ما ابتدا یک مدل نظری ساده را مورد مطالعه قرار دادیم و در مورد نحوهی تأثیرگذاری دادههایی که اصالتاً نامتوازن بودند و دادههای اضافی بر فرآیند کلی یادگیری نکاتی آموختیم. بدین منظور فرض میکنیم یک کلاسبند ابتدایی داریم که با استفاده از یک دیتاست نامتوازن و مقداری دادهی بدون برچسب آموزش دیده است و ما میتوانیم از این کلاسبند ابتدایی برای برچسبزنی به دادههای آزمایشی استفاده کنیم. این دادههای بدون برچسب میتوانند (به شدت) نامتوازن باشند. از بیان جزئیات در این نوشتار پرهیز میکنیم. اینجا چندین مورد از مشاهدات جالب پژوهش خود را به صورت خلاصه بیان میکنیم:
- عدم توازن دادههای آموزشی بر میزان دقت برآورد مدل تأثیر میگذارد؛
- عدم توازن دادههای بدون برچسب (آزمایشی) بر احتمال رسیدن به برآوردی خوب تأثیر میگذارد.
چارچوب یادگیری نامتوازن نیمهنظارتشده: یافتههای نظری ما نشان میدهند که استفاده از برچسبزنی دادههای آزمایشی (و در نتیجه اطلاعات برچسب دادههای آموزشی) میتواند به یادگیری نامتوازن کمک کند. میزان تأثیر این کمک به عدمتوازن دادهها بستگی دارد. ما با الهام از این موضوع، کارآمدی دادههای بدون برچسب را به صورت سیستماتیک مورد مطالعه قرار دادیم. بدین منظور از سادهترین روش یادگیری خودآموزشی نیمهنظارتشده استفاده کردیم که برای دادههای بدون برچسب، برچسبهای آزمایشی تولید میکند و سپس با استفاده از همهی این برچسبها آموزش میبیند. به بیان دقیقتر، ابتدا مدل را با استفاده از دیتاست اصلی که نامتوازن و بدون برچسب است آموزش میدهیم تا یک کلاسبند متوسط به دست بیاوریم. سپس از این کلاسبند برای تولید برچسبهای آزمایشی برای دادههای بدون برچسب استفاده میکنیم. با ادغام این دو گروه از دادهها، تابع زیان مشترک یادگیری مدل نهایی را به حداقل میرسانیم.
شایان ذکر است که علاوه بر خودآموزشی، میتوانید از سایر الگوریتمهای نیمهنظارتشده نیز در چارچوب ما استفاده کنید، تنها لازم است تابع زیان را تغییر دهید. علاوه بر این، از آنجایی که استراتژی یادگیری مدل نهایی را مشخص نکردهایم، چارچوب نیمهنظارتشده میتواند به راحتی با الگوریتمهای نامتوازن موجود ترکیب شود.
آزمایشات: ابتدا شرایط آزمایش را شرح میدهیم. ما نسخهای با دنبالهی کشیده از دیتاستهای CIFAR-10 و SVHN به صورت مصنوعی تولید و انتخاب کردیم، زیرا هردوی این دیتاستها دادههای بدون برچسب با توزیع مشابه دارند: CIFAR-10 متعلق به دیتاست Tiny-Images است و SHVN خود یک دیتاست اضافه دارد که میتواند برای شبیهسازی دادههای بدون برچسب کاربرد داشته باشد. دادههای مربوطه نیز برای استفادهی عموم متنباز شدهاند. ما به احتمال وجود عدم توازن/توزیع با دنبالهی کشیده در دادههای بدون برچسب نیز توجه داشتیم و اثر دادههای بدون برچسب با توزیعهای متفاوت را به صورت آشکار مقایسه کردیم.

یافتههای تجربی در جدول زیر به نمایش گذاشته شدهاند. میتوان به وضوح مشاهده کرد که در کار با دادههای بدون برچسب با وجود تفاوت در (1) دیتاستها، (2) روشهای یادگیری پایه، (3) نسبتهای عدم توازن دادههای برچسبدار و (4) نسبتهای عدم توازن دادههای بدون برچسب، یادگیری نیمهنظارتشده میتواند نتایج کلاسبندی نهایی را تا حد معنادار و به صورت ثابت و پایا بهبود ببخشد. علاوه بر این، در ضمیمهی 5، نتایج مقایسه بین انواع روشهای یادگیری نیمهنظارتشده و بررسی مؤلفههای کارکرد سیستم مقادیر متفاوت داده نشان داده شده است.

در آخر نوبت به بیان یافتههای کیفی آزمایشات میرسد. ما تصاویر t-SNE را برای دیتاست آموزشی و آزمایشی به همراه و بدون دادههای بدون برچسب ترسیم کردیم. همانطور که در شکل مشهود است، استفاده از دادههای بدون برچسب به مدلسازی مرزهایی واضحتر برای دستهها و تفکیک بهتر آنها کمک میکند، به خصوص وقتی نمونههای این دستهها در دنبالهی توزیع قرار داشته باشند. یافتهها نیز از این موضوع حمایت میکنند. وقتی تراکم نمونهها (دادهها)ی موجود در دنباله پایین است، مدل نمیتواند طی یادگیری به خوبی مرزهای نواحی کمتراکم را مدلسازی کند و این منجر به ابهام و تعمیمپذیری ضعیف میشود. در مقابل، دادههای بدون برچسب میتوانند به صورت کارآمد اندازهی نمونه را در نواحی کمتراکم افزایش دهند و افزودن فرآیند منظمسازی قویتر به مدلسازی بهتر مرزها توسط مدل کمک میکند.

سخنی در مورد یادگیری نامتوازن نیمهنظارتشده
با اینکه به کمک یادگیری نیمهنظارتی میتوان عملکرد مدل روی داده های نامتوازن را به حد معناداری بهبود بخشید، این روش خود مشکلاتی عملی دارد که در کار با داده های نامتوازن میتوانند تشدید شوند. در مرحلهی بعد پژوهش خود، این موقعیتها را با طراحی آزمایشات لازم و به صورت سیستماتیک شفافسازی و تجزیه و تحلیل میکنیم تا بلکه راهنمایی برای تحقیقات آینده باشد که در حوزهی ارزش منفی برچسبهای نامتوازن انجام میشوند.
نکتهی اول این است که ارتباط بین دادههای بدون برچسب و دادههای اصلی تأثیری شگرف بر نتایج یادگیری نیمهنظارتشده دارد. برای مثال، ممکن است بعضی از دادههای بدون برچسب در دیتاست CIFAR-10 (کلاسبندی 10 کلاسه) به هیچکدام از ده کلاس اصلی تعلق نداشته باشند. در چنین شرایطی، ممکن است اطلاعات بدون برچسب ناصحیح بوده و تأثیر عمیقی بر آموزش و نتایج مدل بگذارند. به منظور اعتبارسنجی این رویکرد، دادههای بدون برچسب و دادههای آموزشی اصلی را به عنوان متغیر ثابت در نظر گرفتیم تا نسبت عدم توازن یکسانی داشته باشیم؛ اما ارتباط بین دادههای بدون برچسب و دادههای آموزشی اصلی را متغیر در نظر گرفتیم تا دیتاستهای بدون برچسب متفاوتی ساخته شود. همانطور که در شکل 2 میبینید، برای اینکه دادههای بدون برچسب در یادگیری نامتوازن مفید واقع شوند، همبستگی باید بیشتر از 60% باشد.
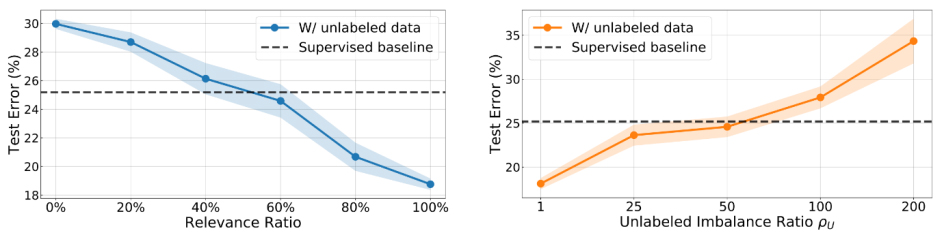
از آنجایی که دادههای آموزشی اولیه نامتوازن هستند، دادههای بدون برچسب نیز میتوانند به شدت نامتوازن باشند. برای مثال دیتاستی از دادههای پزشکی میسازید که به صورت خودکار نوع خاصی از بیماری را تشخیص میدهد. در بین موارد موجود تعداد بسیار کمی مورد مثبت وجود دارد (شاید حدود 1% از کل). با این حال، از آنجایی که نرخ بیماری در واقعیت نیز حدود 1% است، حتی اگر تعداد زیادی داده بدون برچسب هم جمعآوری شود، تعداد دادههای مربوط به بیماری در میان آنها همچنان بسیار کم خواهد بود.
وقتی میخواهیم ارتباط را هم به صورت همزمان در نظر بگیریم (شکل 3)، ابتدا کاری میکنیم که مجموعهی بدون برچسب به اندازهی کافی (60%) مرتبط باشد، اما نسبت عدم توازن دادههای بدون برچسب را تغییر میدهیم. در این آزمایش، نسبت عدم توازن دادههای آموزشی اصلی را روی 50 تنظیم کردیم. همانطور که میبینید، زمانی که دادههای بدون برچسب بیش از حد نامتوازن باشند (یعنی نسبت عدم توازن بیشتر از 50 باشد)، استفاده از دادههای بدون برچسب میتواند نتایج ضعیفتری به دست دهد.
مشکلاتی که بالا مطرح شد در برخی از مسائل کاربردی یادگیری نامتوازن بسیار متداول هستند. برای نمونه در مسئلهی تشخیص بیماری، بیشتر دادههای بدون برچسب موجود از نمونههای عادی (نرمال) جمعآوری شدهاند که، اولاً باعث عدم توازن دادهها شده و دوماً (حتی برای مواردی که بیماری تشخیص داده میشود) ممکن است توسط چندین عامل زیربنایی دیگر به وجود آمده باشد و این باعث میشود میزان ارتباط بیماری کاهش یابد. بنابراین در مواردی که استفاده از یادگیری نیمهنظارتشده سخت است، به یک روش متفاوت نیاز داریم که کارآمد باشد. اینجا رویکرد ارزش منفی مطرح میشود و ما را به سمت ایدهی دیگری سوق میدهد: یادگیری خودناظر.
یادگیری نامتوازن با رویکرد خودنظارتی
در این قسمت نیز از یک مدل نظری برای مطالعهی تأثیر مثبت خودنظارتی روی یادگیری نامتوازن استفاده کردیم. نتایج امیدوارکننده و جالب بودند:
- با استفاده از بازنمایی آموخته شده طی یک مسئلهی خودناظر، به احتمال زیاد کلاسبندی با کیفیت رضایتبخش به دست میآوریم که احتمال خطای آن روی بُعد ویژگی به صورت نمایی کاهش مییابد.
- عدم توازن دادههای آموزشی روی احتمال به دست آوردن چنین کلاسبندی تاثیر میگذارد.
چارچوب یادگیری نامتوازن خودناظر: اگر قصد دارید از خودنظارتی به منظور غلبه بر سوگیری ذاتی برچسب استفاده کنید، پیشنهاد میکنیم ابتدا اطلاعات برچسب را کنار گذاشته و به صورت خودنظارتی پیشآموزش (SSP) را اجرا کنید. هدف از این فرآیند، یادگیری بهتر اطلاعات مقداردهی/ویژگی به صورت مستقل از برچسب داده های نامتوازن است. در مرحلهی بعدی برای آموزش میتوانیم از هر روش آموزشی استانداردی برای یادگیری مدل نهایی استفاده کنیم. این استراتژی برای همهی الگوریتمهای نامتوازن یادگیری قابل کاربرد است. بعد از اینکه اطلاعات مقداردهی خوبی طی پیشآموزش خودناظر تولید شد، شبکه میتواند با بهرهگیری از مسائل پیشآموزش، در نهایت یک بازنمایی عمومیتر بیاموزد.
آزمایشات: اینجا به دادههای اضافی نیازی نداریم. در این آزمایشات، برای اعتبارسنجی الگوریتم در دیتاست CIFAR-10/100 با دنبالهی کشیده، نسخهای با دنبالهی کشیده از دیتاست ImageNet و همچنین یک بنچمارک واقعی iNaturalis استفاده میکنیم. برای الگوریتمهای خودناظر، روشهای کلاسیک پیشبینی چرخشی و جدیدترین روش یادگیری تطبیقی MoCo را به کار میبریم. در ضمیمهی مقاله، بررسی مؤلفههای کارکردی سیستم را ارائه داده و نتایج 4 روش متفاوت خودنظارتی را مقایسه میکنیم.
یافتههای آزمایشات در دو جدول بعدی نشان داده شدهاند. به طور خلاصه میتوان گفت استفاده از SSP حتی با انواع مختلف (1) دیتاستها، (2) نسبتهای عدم توازن و (3) الگوریتمهای آموزشی، به صورت پایا و تأثیرگذار منجر به ارتقای عملکرد شود.


در آخر نیز نتایج کیفی خودنظارتی را نشان میدهیم. همچون گذشته، تصاویر حدودی t-SNE را برای مجموعههای آموزشی و آزمایشی ترسیم میکنیم. از این شکل به سادگی میتوان استنباط کرد که مرز تصمیمگیری آموزش CE به وسیلهی نمونههای دستهی بالایی (اکثریت) به شدت تغییر مییابد و این امر باعث میشود طی آموزش تعداد زیادی از نمونهها وارد دستههای موجود در دنباله شوند و در نتیجه تعمیمپذیری مدل کاهش مییابد. در مقابل، استفاده از SSP میتواند با حفظ یک اثر تفکیکی واضح، ورود نمونهها به دنبالههای توزیع را کاهش دهد (به خصوص بین دستههای سر و دنباله که مجاور هم قرار دارند).
به صورت شهودی نیز میتوان به همین نتیجه رسید؛ یادگیری خودناظر از وظایف اضافی استفاده میکند تا فرآیند یادگیری را محدود کند، ساختار فضای دادهها را بهتر یاد بگیرد و اطلاعات گسترده را استخراج کند. بدین ترتیب میتوان به شکلی کارآمد، وابستگی شبکه به ویژگیهای معنایی ردهبالا و بیشبرازش دادههای موجود در دنباله را کاهش داد. بازنمایی ویژگی آموختهشده قویتر و تعمیم آن نیز آسانتر خواهد بود، به همین دلیل مدل عملکرد بهتری در مسائل یادگیری با نظارت خواهد داشت.

سخن پایانی
در این مقاله ابتدا سعی کردیم با استفاده از دو رویکرد متفاوت، دادهها (برچسبها)ی نامتوازن را درک کرده و با کاربرد آنها آشنا شویم؛ این دو رویکرد متفاوت یادگیری نیمه نظارتی شده و خودناظر هستند. بعد از اعتبارسنجی، عملکرد هردوی این چارچوبها در بهبود مسئلهی یادگیری نامتوازن تأیید شد. این مقاله شامل تجزیه و تحلیل و توضیحات نظری بسیار شهودی میشود و از یک چارچوب دقیق و عمومی برای بهبود مسائل یادگیری در توزیع دادهها با دنبالهی کشیده استفاده میکند. نتایج به دست آمده برای کاربرد در مقیاسهای بزرگتر نیز جذاب و مفید خواهند بود.





