

دانشمندان دیپ مایند: حوزه یادگیری تقویتی برای هوش مصنوعی عمومی کافیست
 تیم تحریریه
تیم تحریریه- ۱۴ تیر ۱۴۰۰
این مقاله بخشی از بررسیهای محققان در حوزه پژوهشهای هوش مصنوعی را در بردارد و آخرین یافتههای دنیای هوش مصنوعی در حوزه یادگیری تقویتی را بررسی میکند.
دانشمندان علوم کامپیوتر طی دههها تلاش خود برای ایجاد هوش مصنوعی، انواع مکانیسمها و فناوریهای پیچیده را برای شبیهسازی تواناییهای انسان در ماشین، نظیر بینایی، قدرت درک زبان، توانایی استدلال، مهارتهای حرکتی و سایر تواناییهای مرتبط با زندگی هوشمند طراحی و توسعه دادهاند. در حالی که این تلاشها منجر به ایجاد سیستمهای هوش مصنوعی شده است که میتواند به طور کارآمد مشکلات خاص را در محیطهای محدود حل کند، اما همچنان در توسعه نوعی هوش عمومی که در انسان و حیوان دیده میشود، کاستیهایی دارد.

در مقاله جدیدی که در مجله هوش مصنوعی منتشر شده است، دانشمندان آزمایشگاه هوش مصنوعی دیپ مایند مستقر در انگلستان، استدلال میکنند که هوش و تواناییهای مرتبط با آن نه از طریق فرمولسازی و حل مشکلات پیچیده، بلکه با پایبندی به یک اصل ساده اما قدرتمند شکل میگیرد و آن «حداکثرسازی پاداش» است.
این مقاله که با عنوان «پاداش کافی است!» منتشر شده، هنوز در مرحله پیشفرض بوده و به اثبات نرسیده است. محققان در این پژوهش از مطالعه تکامل هوش طبیعی و همچنین آخرین دستاوردهای هوش مصنوعی الهام میگیرند. نویسندگان در این مقاله اذعان میکنند که حداکثرسازی پاداش و تجربه آزمون و خطا برای توسعه رفتاری که نوع تواناییهای مرتبط با هوش را به نمایش بگذارد، کافی است. آنها از این امر نتیجه میگیرند که حوزه یادگیری تقویتی، به عنوان شاخهای از هوش مصنوعی، بر اساس حداکثرسازی پاداش عمل میکند و میتواند به توسعه هوش مصنوعی عمومی منجر شود.
دو راه برای توسعه هوش مصنوعی وجود دارد!
یک روش معمول برای توسعه هوش مصنوعی تلاش برای تکرار عناصر رفتار هوشمندانه و انسانگونه در رایانههاست. به عنوان مثال، درک ما از سیستم بینایی پستانداران باعث ایجاد انواع مختلفی از سیستمهای هوش مصنوعی شده است که میتواند تصاویر را دستهبندی کند، اشیا را در عکسها تشخیص دهد، مرزهای بین اشیا را مشخص کند و موارد دیگر. به همین ترتیب، درک ما از زبان به توسعه سیستمهای مختلف پردازش زبان طبیعی، مانند پاسخ به سوال، تولید متن و ترجمه ماشینی کمک کرده است.

اینها همه مواردی از هوش مصنوعی محدود است. هوش مصنوعی محدود، سیستمهایی را شامل میشود که به جای داشتن تواناییهای کلی حل مسئله، تنها برای انجام کارهایی خاص طراحی شدهاند. برخی از دانشمندان بر این باورند که مونتاژ چندین ماژول محدود هوش مصنوعی، سیستمهای هوشمند سطح بالاتر و پیشرفتهتری را تولید میکند. به عنوان مثال، شما میتوانید یک سیستم نرمافزاری داشته باشید که بین بینایی جداگانه رایانه، پردازش صدا، NLP و ماژولهای کنترل موتور برای حل مشکلات پیچیدهای که به مهارتهای زیادی نیاز دارند، هماهنگ باشد. یک روش متفاوت برای ایجاد هوش مصنوعی، که توسط محققان موسسه دیپ مایند ارائه شده است، بازآفرینی یک قانون ساده و در عین حال موثر است که باعث ایجاد هوش طبیعی شده است.
اصولاً طبیعت اینگونه کار میکند. تا آنجا که به علم مربوط میشود، هیچ طراحی هوشمندانهای از بالا به پایین در موجودات پیچیدهای که در اطراف خود میبینیم وجود نداشته است. میلیاردها سال انتخاب طبیعی و تغییرات تصادفی، شکل زندگی را برای تناسب اندام آنها برای زنده ماندن و تولید مثل تغییر داده است. موجودات زندهای که برای کنار آمدن با چالشها و شرایط موجود در محیط زندگی خود از تجهیزات بهتری برخوردار بودند، موفق به زنده ماندن و تولید مثل شدند و بقیه آنها که در سازگارشدن با محیط خود ناتوان بودند، حذف شدند.
این مکانیسم ساده و در عین حال کارآمد، باعث تکامل موجودات زنده با انواع مهارتها و تواناییها برای درک، پیمایش، اصلاح محیطهای خود و برقراری ارتباط بین خود شده است.
محققان میگویند: «دنیای طبیعی که حیوانات و انسانها با آن روبهرو هستند و همچنین محیطهایی که در آینده توسط عوامل مصنوعی با آن روبهرو میشوند، ذاتاً آنقدر پیچیده هستند که برای موفقیت (به عنوان مثال برای زنده ماندن) در آن محیطها به تواناییهای پیشرفتهای نیاز دارند. بنابراین، همانطور که میزان «موفقیت» با به حداکثر رساندن پاداش اندازهگیری میشود، نیاز به تواناییهای مختلف نیز ارتباط نزدیکی با هوش دارد. در چنین محیطهایی، هر رفتاری که پاداش را به حداکثر برساند، لزوماً باید این تواناییها را به نمایش بگذارد. از این لحاظ، هدف اصلی حداکثرسازی پاداش، بسیاری از اهداف هوشمندسازی را در خود جای داده است.
به عنوان مثال، سنجابی را در نظر بگیرید که به دنبال پاداشی برای به حداقل رساندن گرسنگی است. از یک طرف، مهارتهای حسی و حرکتی به او کمک میکند تا هنگام تهیه غذا، آجیلها را پیدا و جمعآوری کند. اما سنجابی که فقط غذا پیدا میکند، وقتی غذا کمیاب شود، از گرسنگی میمیرد. به همین دلیل مهارت و حافظه برنامهریزی برای ذخیره آجیل و بازیابی آن در زمستان را دارد. سنجاب از مهارت و دانش اجتماعی برخوردار است تا اطمینان حاصل کند حیوانات دیگر آجیلهایش را نمیدزدند. اگر از مقیاسی بزرگتر به این توانایی نگاه کنیم، درمییابیم که به حداقل رساندن گرسنگی میتواند یکی از زیرمجموعههای «زنده ماندن» باشد، که به مهارتهایی مانند شناسایی و پنهان شدن از حیوانات خطرناک، محافظت از خود در برابر تهدیدات محیطی و جستجوی زیستگاههای بهتر با تغییرات فصلی نیز نیاز دارد.
محققان میگویند: «وقتی تواناییهای مرتبط با هوش به عنوان راهحلی برای رسیدن به هدف «حداکثرسازی پاداش» به وجود میآیند، این در حقیقت میتواند شناخت عمیقتری را فراهم کند. زیرا دلیل وجود چنین توانایی را توضیح میدهد. در مقابل، وقتی هر توانایی به عنوان راهحلی برای هدف ویژه خود درک میشود، دلیل وجود چنین توانایی رنگ میبازد، تا بتوانیم روی آنچه این توانایی انجام میدهد تمرکز کنیم.»
سرانجام، محققان استدلال میکنند که «عمومیترین و مقیاس پذیرترین» راه برای به حداکثر رساندن پاداش، از طریق عواملی است که از طریق تعامل با محیط آموخته میشود.
توسعه تواناییها از طریق حداکثرسازی پاداش
در این مقاله، محققان هوش مصنوعی چند مثال ارائه میدهند که نشان میدهد چگونه «هوش و تواناییهای مرتبط به طور ضمنی در خدمت به حداکثر رساندن سیگنالهای پاداش، مطابق با بسیاری از اهداف عملی میشود که هوش طبیعی یا مصنوعی میتواند به سمت آنها هدایت شود.»
به عنوان مثال، مهارتهای حسی نیاز به زنده ماندن در محیطهای پیچیده را تأمین میکنند. تشخیص اشیا در فرایندهای شناختی حیوانات، آنها را قادر میسازد تا غذا، طعمه، دوستان و تهدیدها را تشخیص دهند، یا مسیرها، پناهگاهها و نشیمنها را پیدا کنند. تقسیم بندی تصویر، آنها را قادر میسازد تا بین اجسام مختلف تفاوت قائل شوند و از اشتباهات مهلکی مانند فرار از صخره یا افتادن از روی شاخههای درختان جلوگیری کنند. در همین حال، توانایی شنیدن در هنگام استتار حیوان که نمیتواند طعمه خود را ببیند یا پیدا کند، به تشخیص تهدیدهایی کمک میکند که در محیط وجود دارد. قدرت لامسه، چشایی و بویایی نیز به حیوان این قدرت را میدهد که تجربه حسی غنیتری از زیستگاه خود به دست آورد و شانس بیشتری برای زنده ماندن در محیطهای خطرناک داشته باشد.
پاداشها و نیز واکنشهای محیطی که حیوان در آن میزید، همچنین دانش ذاتی و آموخته شده را در حیوانات شکل میدهند. به عنوان مثال، زیستگاههای خصمانهای که توسط حیوانات شکارچی مانند شیر و یوزپلنگ تصرف میشوند، به گونههای حیوانی نشخوارکنندهای که از بدو تولد، دانش ذاتیشان برای فرار از تهدیدات است، پاداش میدهند. در عین حال، حیوانات وحشی دیگر نیز به خاطر قدرت خود در یادگیری دانش خاص از زیستگاه خود، مانند محل یافتن غذا و سرپناه، پاداش میگیرند.
محققان همچنین درباره مبانی پاداش زبانی، هوش اجتماعی، تقلید و سرانجام، هوش عمومی بحث میکنند و آنها را «به حداکثر رساندن پاداش واحد در یک محیط پیچیده و واحد» توصیف میکنند. آنها بین هوش طبیعی و AGI قیاس میکنند: «قدرت تجربه حیوانات به اندازه کافی غنی و متنوع است که ممکن است توانایی دستیابی به طیف گستردهای از زیرمجموعهها (مانند جستجوی غذا، جنگیدن یا فرار) را بهدست آورد و در به حداکثر رساندن پاداش کلی آن (مانند گرسنگی یا تولید مثل) موفق شود. به همین ترتیب میتوان نتیجه گرفت: اگر جریان تجربه یک عامل مصنوعی به اندازه کافی غنی باشد، ممکن است بسیاری از اهداف (مانند عمر باتری یا بقا) به طور ضمنی، توانایی دستیابی به یک طیف گستردهای از اهداف فرعی را داشته باشند، و بنابراین حداکثر پاداش برای توسعه و تولید یک هوش عمومی مصنوعی کافی است.»
آموزش تقویت برای به حداکثر رساندن پاداش
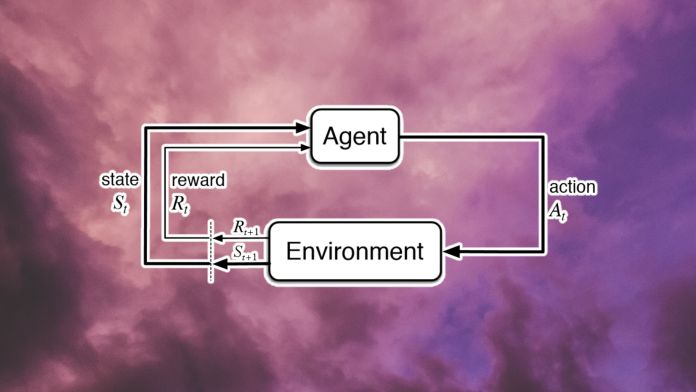
یادگیری تقویتی شاخه خاصی از الگوریتمهای هوش مصنوعی است که از سه عنصر اصلی تشکیل شده است: محیط، عامل و پاداش.
با آموزش به هوش مصنوعی، این سامانه هوشمند قادر خواهد بود حالت خود و محیط را تغییر دهد. بر اساس اینکه چقدر این تغییرات در یادگیری هوش مصنوعی تاثیر مثبت یا منفی داشته است، برای هوش مصنوعی پاداش یا مجازات تعریف میشود. بسیاری از مشکلات موجود در حوزه یادگیری تقویتی، به این دلیل است که هوش مصنوعی شناخت اولیهای از محیط ندارد و با اقدامات تصادفی شروع به انجام وظایف میکند. سپس، براساس بازخوردی که میگیرد، میآموزد که اقدامات خود را تنظیم کند و سیاستهایی را توسعه دهد که پاداش آن را به حداکثر برساند.

محققان موسسه دیپ مایند در مقاله خود، حوزه یادگیری تقویتی را به عنوان الگوریتم اصلی پیشنهاد میکنند که میتواند حداکثر پاداش را همانطور که در طبیعت دیده میشود، تکرار کند و در نهایت منجر به هوش مصنوعی عمومی شود.
محققان این مرکز میگویند: «اگر یک هوش مصنوعی بتواند به طور مداوم رفتار خود را به گونهای تنظیم کند که پاداش خود را بهبود بخشد، پس هرگونه توانایی که محیط او مرتباً طلب میکند، باید در نهایت در رفتار آن هوش مصنوعی ایجاد شود.». پاداشی که با این موفقیتها کسب میکند این است که حوزه یادگیری تقویتی میتواند سرانجام قدرت درک، توانایی شناخت زبان، مهارت هوش اجتماعی و موارد دیگر را به هوش مصنوعی بیاموزد.
با این حال، محققان تأکید میکنند که برخی از چالشهای اساسی حوزه یادگیری تقویتی همچنان حل نشده باقی ماندهاند. به عنوان مثال، آنها میگویند: «ما هیچ تضمین نظری در مورد کارایی نمونه عوامل یادگیری تقویتی ارائه نمیدهیم. یادگیری تقویتی به نیاز به مقدار زیادی داده مشهور است. به عنوان مثال، یک هوش مصنوعی که با روش یادگیری تقویتی آموزش میبیند، ممکن است برای تسلط بر یک بازی رایانهای به قرنها بازی کامپیوتری نیاز داشته باشد. محققان هوش مصنوعی هنوز نتوانستهاند نحوه ایجاد سیستمهای یادگیری تقویتی را که بتواند یادگیری را در چندین حوزه تعمیم دهد، درک کنند. بنابراین، تغییرات جزئی در محیط اغلب به بازآموزی کامل مدل نیاز دارد.
محققان همچنین اذعان میکنند که مکانیسمهای یادگیری، برای به حداکثر رساندن پاداش یک مسئله حل نشده است و این همچنان یک سوال اصلی است که باید بیشتر در یادگیری تقویت مورد مطالعه قرار گیرد.





