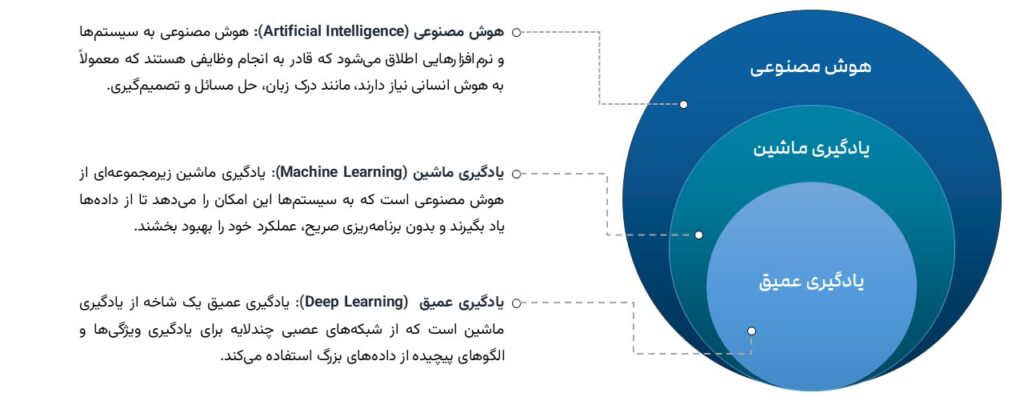
یادگیری عمیق یا Deep Learning چیست؟
یادگیری عمیق (Deep Learning) از مفاهیم کاربردی در هوش مصنوعی است که تلاش میکند به تقلید از نحوه یادگیری دانش توسط انسان بپردازد. یادگیری عمیق زیرمجموعهای از یادگیری ماشین است که در اصل یک شبکه عصبی با سه لایه یا بیشتر است. الگوریتمهای شبکههای عصبی مصنوعی تلاش میکنند تا با شبیه سازی ساختار مغز، به ماشینها بیاموزند تا مانند انسان فکر کنند.
یادگیری عمیق بخشی از روشهای یادگیری ماشین است که به تقلید از شیوه یادگیری انسانها میپردازد. با استفاده از یادگیری عمیق دیگر نیاز نیست دانشمندان و پژوهشگران محاسبات آماری و مدلسازیهای پیشبینیکننده را به طور ذهنی انجام دهند و یادگیری عمیق به طور اتوماتیک این تحلیلها را انجام میدهد. در واقع Deep Learning تلاش میکند تا نوعی مغز انسان را شبیهسازی میکند. در یادگیری ماشین فرد باید نظارت کند و جزئیات را به طور دقیق در کامپیوتر تعریف کند در صورتی که در یادگیری عمیق به ماشینها این توانایی داده میشود تا تصمیمهای مشابه با تصمیمهای انسانی بگیرند و به این منظور از چند لایه مختلف شبکههای عصبی استفاده میشود.
یادگیری عمیق چگونه کار میکند؟
در فرایند توسعه مدلهای یادگیری عمیق به ماشینها این امکان داده میشود تا از دادهها یاد بگیرند و الگوهای پیچیده را شناسایی کنند. این فناوری به ویژه در زمینههایی مانند بینایی ماشین، پردازش زبان طبیعی و تشخیص گفتار کاربرد دارد. در اینجا، مراحل و اصول کارکرد یادگیری عمیق را بررسی میکنیم.
گام ۱
ساختار شبکههای عصبی
یادگیری عمیق عمدتاً بر پایه شبکههای عصبی مصنوعی (Artificial Neural Networks) ساخته شده است. این شبکهها از مجموعهای از نورونها (neurons) تشکیل شدهاند که به صورت لایهای سازماندهی شدهاند:
لایه ورودی (Input Layer)
این لایه دادههای خام را دریافت میکند. هر نورون در این لایه نمایانگر یک ویژگی از دادهها است.
لایههای پنهان (Hidden Layers)
این لایهها بین لایه ورودی و لایه خروجی قرار دارند و وظیفه پردازش دادهها را بر عهده دارند. هر لایه شامل چندین نورون است که ورودیها را از لایه قبلی دریافت کرده و خروجیهایی تولید میکنند.
لایه خروجی (Output Layer)
این لایه نتایج نهایی مدل را تولید میکند و معمولاً شامل نورونهایی است که هر کدام نمایانگر یک کلاس یا نتیجه خاص هستند.

گام ۲
پیشپردازش دادهها
قبل از آموزش مدل، دادهها باید پیشپردازش شوند. این مرحله شامل موارد زیر است:
تمیز کردن دادهها:
حذف دادههای نامناسب یا نادرست.
نرمالسازی:
مقیاسبندی دادهها به یک بازه مشخص (مثلاً 0 تا 1) برای بهبود کارایی مدل.
تقسیمبندی دادهها:
تقسیم دادهها به مجموعههای آموزشی، اعتبارسنجی و آزمایشی.
گام ۳
آموزش مدل
مدل یادگیری عمیق با استفاده از دادههای آموزشی تولید میشود. این فرآیند شامل مراحل زیر است:
محاسبه خروجی:
دادهها از لایه ورودی به لایههای پنهان و سپس به لایه خروجی منتقل میشوند. هر نورون در هر لایه، ورودیها را با وزنهای خاصی ترکیب میکند و با استفاده از یک تابع فعالسازی (Activation Function) خروجی تولید میکند.
محاسبه خطا:
پس از تولید خروجی، خطا (Loss) محاسبه میشود. این خطا نشاندهنده تفاوت بین خروجی پیشبینیشده و خروجی واقعی (برچسب گذاری شده) است.
بهروزرسانی وزنها:
با استفاده از الگوریتمهای بهینهسازی مانند نزول گرادیان (Gradient Descent) ، وزنها و بایاسها (Bias) در شبکه بهروزرسانی میشوند تا خطا کاهش یابد. این فرآیند از طریق الگوریتم پسانتشار (Backpropagation) انجام میشود که خطا را از لایه خروجی به لایههای قبلی منتقل میکند و وزنها را بر اساس آن تنظیم میکند.
گام ۴
تست و اعتبارسنجی مدل
پس از آموزش، مدل باید با استفاده از دادههای اعتبارسنجی و آزمایشی ارزیابی شود. این مرحله شامل بررسی دقت مدل و توانایی آن در تعمیم به دادههای جدید است. اگر مدل عملکرد خوبی نداشته باشد، ممکن است نیاز به تنظیم مجدد پارامترها یا تغییر ساختار شبکه باشد.
گام ۵
استفاده از مدل
پس از اینکه مدل به طور مؤثری آموزش دید و اعتبارسنجی شد، میتوان از آن برای پیشبینی دادههای جدید استفاده کرد. این مدل میتواند در کاربردهای مختلفی مانند تشخیص تصویر، ترجمه زبان، و سیستمهای توصیهگر به کار رود.
کاربردهای یادگیری عمیق
یادگیری عمیق در حال حاضر زندگی روزمره ما را تحت تاثیر قرار میدهد و در بسیاری از حوزهها به طور روزانه مورد استفاده قرار میگیرد. یادگیری عمیق کمک میکند وظایفی که نیروهای انسانی انجام میدهند را به بهترین شکل ممکن صورت دهد و بهترین خروجی را در پی دارد. برخی از مهمترین کاربردهای یادگیری عمیق عبارتند از:
تجربه مشتری
این کاربرد یادگیری عمیق در بیشتر کسب و کارها و حوزههای خدماتی مورد استفاده قرار میگیرد و همه ما با آنها سر و کار داریم. چتباتها و نرمافزارهای گفتگوی آنلاین که در رسانههای اجتماعی یا وبسایتها مشاهده میکنید توسط مدلهای یادگیری عمیق تهیه شدهاند و به سوالات و نیازهای مشتریان پاسخ میدهند.
اهداف نظامی
مراکز نظامی برای پیشبرد اهداف خود مانند انجام عملیات با استفاده از الگوریتمهای یادگیری عمیق رباتهایی را آموزش میدهند. به این ترتیب از دادههای خام محیط اطراف استفاده میشود و ربات از طریق آزمون و خطا آموزش میبیند و وظیفه خود را تکمیل میکند. همچنین با کاربرد در هوافضا اشیا موجود در تصاویر ماهوارهای را تشخیص میدهد و نقاط امن و ناایمن را در اختیار مراکز نظامی قرار میدهد.
اتوماسیون صنعتی
برقراری ایمنی در صنایع و انبارها بهواسطه الگوریتمهای یادگیری عمیق امکانپذیر است و با استفاده از سرویسهای موجود اشیا یا کارگران نزدیک شده به دستگاه را تشخیص و هشدار میدهد.
تولید متن
با در اختیار قرار دادن گرامر و استایل یک متن در اختیار کامپیوتر مدلهای یادگیری میتوانند یک متن جدید تولید کنند که با متن اصلی از نظر گرامر و املا تطابق داشته باشد.
حوزه پزشکی
یکی دیگر از کاربردهای دیپ لرنینگ در حوزه پزشکی است که محققان و پژوهشگران از طریق مدلهای یادگیری عمیق میتوانند تومور و بیماریهای مختلف را تشخیص دهند و داروهای مخصوص برای هر شخص به دست آوردند.
شناسایی تصاویر
مدلهای یادگیری ماشین میتوانند تصاویر هزاران فرد را با دقت بسیار بالایی تشخیص دهند. استفاده از این تکنولوژی در دوربینهای مداربسته دقت تشخیص چهره افراد را تا حد قابل توجهی افزایش میدهد که امکان تشخیص آن برای انسان دشوار است.
رنگآمیزی تصاویر
تصاویر و ویدئوهای قدیمی که به رنگ سیاه و سفید هستند تا چند سال اخیر توسط انسان رنگآمیزی میشدند. اما امروزه یادگیری عمیق میتواند رنگهای احتمالی اشیا را تشخیص دهد و آنها را رنگآمیزی نماید.
اتومبیلهای خودران
تولید اتومبیلهای خودران که امروزه توجهات بسیاری را به خود جلب کردهاند از طریق مدلهای یادگیری عمیق انجام شده است. این اتومبیلها میتوانند مسیر جاده و نشانههای توقف را به راحتی تشخیص دهند و انسان و کوچکترین اشیا را به راحتی تشخیص میدهند و از بروز تصادفات جلوگیری میکنند.
دستیارهای صوتی
دستیارهای صوتی که به ارائه پیشنهادات و انجام دستورات انسان میپردازند؛ مانند سیری و الکسا برای درک وظایف خود از یادگیری عمیق استفاده میکنند.
صنعت ساخت و ساز
انواع عملیات ساخت و ساز مانند پیریزی و اجرای بتن آرمه از طریق مدلهای یادگیری عمیق امکانپذیر است و باعث تسریع و بهینهسازی پروژههای عمرانی میشود.
خدمات مالی
یادگیری عمیق با تجزیه و تحلیل دادههای مالی میتواند فرصتهای سرمایهگذاری بینظیر ارائه دهد. این کاربرد برای شرکتهای بزرگ بسیار حائز اهمیت است و حجم وسیع از دادههای متنی را در کوتاهترین زمان پردازش و تجزیه و تحلیل میکند.
تاریخچه یادگیری عمیق
دهه ۱۹۵۰
آغاز شبکههای عصبی
«فرانک روزنبلات» اولین شبکه عصبی مصنوعی به نام «پرسیپترون» را معرفی کرد.

دهه ۱۹۵۰
دهه ۱۹۸۰
الگوریتم پسانتشار خطا
در دهه ۱۹۸۰، با ظهور الگوریتمهای جدید و بهبود تکنیکهای یادگیری، دوباره توجهها به شبکههای عصبی جلب شد. یکی از این تکنیکها، الگوریتم «پسانتشار خطا» (Backpropagation) بود که به شبکههای عصبی این امکان را میداد تا به طور مؤثرتری یاد بگیرند.
«دیوید پاکر» و «ژرار هینتون» الگوریتم «پسانتشار خطا» را معرفی کردند که به شبکههای عصبی کمک کرد تا به طور مؤثرتری یاد بگیرند. این شبکه ساده، توانایی یادگیری از دادهها را داشت، اما به دلیل محدودیتهایش در پردازش دادههای پیچیده، به سرعت مورد انتقاد قرار گرفت و تا دههها بعد از آن به فراموشی سپرده شد.
دهه ۱۹۸۰
دهه ۱۹۹۰
توسعه شبکههای عصبی
دوباره توجه به شبکههای عصبی افزایش یافت، اما محدودیتهای محاسباتی و نبوده دادهها کافی همچنان مانع از پیشرفتهای بزرگ میشد.
دهه ۱۹۹۰
۲۰۰۶
ظهور یادگیری عمیق
ورود به دهه ۲۰۰۰، دوران جدیدی برای یادگیری عمیق بود. با پیشرفتهای چشمگیر در قدرت محاسباتی و افزایش حجم دادههای دیجیتال، محققان توانستند شبکههای عصبی عمیقتری را توسعه دهند.«ژرار هینتون» و همکارانش مفهوم «یادگیری عمیق» را معرفی کردند و روشهای جدیدی برای آموزش شبکههای عمیق ارائه دادند.
۲۰۰۶
۲۰۱۲
موفقیت AlexNet
شبکه عصبی عمیق “AlexNet” به عنوان یک نقطه عطف در یادگیری عمیق شناخته شد. این شبکه توانست در مسابقه تشخیص تصویر ImageNet با فاصلهای چشمگیر از رقبای خود پیروز شود و توجهات جهانی را به سمت یادگیری عمیق جلب کند.
۲۰۱۲
۲۰۱۴
ظهور GANs
«ایان گودفلو»، دانشمند برجسته در حوزه هوش مصنوعی و یادگیری ماشین، به همراه همکارانش در سال 2014 مفهوم شبکههای مولد رقابتی (Generative Adversarial Networks یا GANs) را معرفی کردند. این نوآوری به عنوان یکی از مهمترین پیشرفتها در زمینه یادگیری عمیق شناخته میشود و تأثیر عمیقی بر نحوه تولید دادههای جدید و واقعی در دنیای دیجیتال گذاشته است.
۲۰۱۴
۲۰۱۵
پیشرفت در پردازش زبان طبیعی
مدلهای یادگیری عمیق مانند LSTM و GRU در پردازش زبان طبیعی به کار گرفته شدند و به ماشینها این امکان را میدادند تا زبان انسانی را درک و تحلیل کنند.
۲۰۱۵
۲۰۱۶
AlphaGo
سیستم هوش مصنوعی AlphaGo شرکت «دیپمایند» توانست قهرمان جهان بازی «گو» را شکست دهد و نشاندهنده قدرت یادگیری عمیق در بازیهای استراتژیک بود.

۲۰۱۶
۲۰۱۷
ترنسفورمرها وارد میشوند
مدل Transformer معرفی شد که به پیشرفتهای چشمگیری در پردازش زبان طبیعی منجر شد و پایهگذار مدلهای جدید مانند BERT و GPT شد.
۲۰۱۷
۲۰۲۰
پیشرفتهای گسترده
یادگیری عمیق در حوزههای مختلفی مانند پزشکی، خودروهای خودران، و بینایی ماشین به کار گرفته شد و به یکی از کلیدیترین فناوریها در هوش مصنوعی تبدیل شد.
۲۰۲۰
۲۰۲۳
تحقیقات و نوآوریهای جدید
تحقیقات در زمینه یادگیری عمیق ادامه دارد و محققان به دنبال بهبود الگوریتمها و کاربردهای جدید هستند.
۲۰۲۳
معرفی الگوریتمهای یادگیری عمیق
برای تولید مدلهای هوش مصنوعی مبتنی بر یادگیری عمیق از رویکردهای مختلفی استفاده میشود که مهمترین آنها عبارتند از:
کاهش نرخ یادگیری (Learning Rate Decay) یکی از تکنیکهای مهم در یادگیری عمیق است که به بهبود فرآیند آموزش مدلها کمک میکند. نرخ یادگیری (Learning Rate) یک هایپرپارامتر است که تعیین میکند چقدر وزنها و بایاسها در هر مرحله از آموزش بهروزرسانی میشوند. تنظیم صحیح این پارامتر میتواند تأثیر زیادی بر عملکرد نهایی مدل داشته باشد.
از این الگوریتم زمانی استفاده میشود که وزن مدل دچار تغییر میشود و در اینجا نرخ یادگیری به محاسبه میزان تغییر میپردازد و خطای تخمین زده شده را پاسخ میدهد. نرخ یادگیری بالا میتواند باعث شود که مدل به سرعت به یک نقطه محلی از بهینهسازی برسد، اما این احتمال وجود دارد که از حد بهینه دور شود و نتواند به بهینهسازی جهانی دست یابد. از طرف دیگر، نرخ یادگیری پایین ممکن است باعث شود که فرآیند آموزش بسیار کند شود و در نهایت به زمان زیادی نیاز داشته باشد تا به نقطه بهینه برسد. بنابراین، کاهش تدریجی نرخ یادگیری میتواند به مدل کمک کند تا در مراحل پایانی آموزش به دقت بیشتری دست یابد.
یادگیری انتقالی (Transfer Learning) یک روش نوین در یادگیری ماشین و یادگیری عمیق است که به طور خاص به تکمیل و بهینهسازی مدلهای آموزشدیدهشده قبلی میپردازد. در این الگوریتم، دادههای زیادی توسط کاربر به شبکه عصبی ارائه میشوند تا مدل بتواند با استفاده از آنها سازگاریهای جدیدی را انجام دهد. این فرآیند به شبکه این امکان را میدهد که از دانش قبلی خود بهرهبرداری کند و به سرعت به یادگیری ویژگیهای جدید بپردازد. به عبارت دیگر، به جای شروع از صفر، مدل میتواند از اطلاعات و تجربیات قبلی خود استفاده کند و به همین دلیل زمان محاسبه و آموزش به طور قابل توجهی کاهش مییابد. این ویژگی به ویژه در شرایطی که دادههای جدید به سختی قابل دسترسی هستند، یک مزیت بزرگ محسوب میشود. در نهایت، کاربر با توجه به تواناییها و مهارتهای خود میتواند وظایف و کارهای جدیدی را با استفاده از این مدلهای بهینهشده انجام دهد، که این امر به تسریع در توسعه و پیادهسازی راهحلهای هوش مصنوعی کمک میکند.
آموزش از ابتدا (From Scratch Training) در یادگیری عمیق به فرایند ایجاد و آموزش یک مدل از پایه اشاره دارد. در این روش، مجموعهای از دادههای برچسبگذاریشده وسیع توسط کاربر جمعآوری میشوند و سپس یک معماری شبکه مناسب برای یادگیری مدل پیکربندی میشود. این رویکرد بهویژه برای برنامههایی مناسب است که دارای طبقات زیاد یا دادههای جدید و منحصر به فرد هستند، زیرا امکان یادگیری ویژگیهای خاص و پیچیده را فراهم میکند. با این حال، یکی از چالشهای اصلی در این روش نیاز به دادههای بسیار زیاد و متنوع است، که میتواند زمان و منابع زیادی را به خود اختصاص دهد. به همین دلیل، آموزش از ابتدا معمولاً در شرایطی که دادههای کافی و با کیفیت وجود داشته باشد، مورد استفاده قرار میگیرد و در غیر این صورت، استفاده از روشهای یادگیری انتقالی یا دیگر تکنیکها که به دادههای کمتری نیاز دارند، معمولتر و رایجتر است. این فرایند ممکن است برای پروژههای بزرگ و پیچیده زمانبر باشد، اما در نهایت میتواند به مدلهای قدرتمند و دقیقتری منجر شود که به خوبی با نیازهای خاص کاربران سازگار هستند.
در روش حذف تصادفی یا تکنیک Drop Out در شبکههایی که با پارامترهای زیادی مواجه هستند به طور تصادفی واحدها و اتصالات را حذف میکند و منجر به رفع مشکل تناسب بیش از حد در یک شبکه میشود. این روش نقش موثری در بهبود شبکههای عصبی با یادگیری نظارت شده دارد و در زمینههایی مانند تشخیص گفتار، زیستشناسی محاسباتی و طبقهبندی مستندات به کار میرود.
مزایای یادگیری عمیق
استفاده از یادگیری عمیق در آموزش مدلهای هوش مصنوعی با مزایای متعددی همراه است که عبارتند از:
1
2
3
4
5
5
عدم نیاز به برچسبگذاری دادهها
یادگیری عمیق به دلیل توانایی مدیریت دادهها در روابط پیچیده بسیار کاربردی است. برای انجام عملیات و محاسبات علاوه بر دادههای برچسبدار میتوانید از دادههای بدون برچسب نیز استفاده کنید. برای انجام عملیات ساده نیازی به برچسبگذاری دادهها نیست چرا که هزینه و زمان زیادی را به خود اختصاص میدهد و معمولاً در صنایع از آن استفاده میشود. برای مثال برای دستهبندی عکسها نیاز به استفاده از برچسبگذاری دادهها نیست.
خروجی با کیفیت بالا
زمانی که حجم بسیار وسیعی از دادهها به کامپیوتر داده شوند و آموزش یک مدل یادگیری عمیق به درستی انجام شود هر بار نتیجه و خروجی کیفیت بسیار بالایی ارائه میدهد و توانایی آن را دارد تا در کمترین زمان بیش از هزار فعالیت تکراری و پیش پا افتاده را انجام دهد. توجه داشته باشید دادهها نباید خام باشند و باید بتوانند نیاز و مشکلات را به خوبی شناسایی و برطرف کنند.
کاهش نیاز به مهندسی ویژگی
کاهش نیاز به مهندسی ویژگی (Feature Engineering) یکی از مزایای مهم یادگیری عمیق است که به طور قابل توجهی فرآیند توسعه مدلهای یادگیری ماشین را تسهیل میکند. مهندسی ویژگی به فرآیند استخراج و انتخاب ویژگیهای مناسب از دادهها اشاره دارد که برای بهبود عملکرد مدلهای یادگیری ماشین ضروری است. در روشهای سنتی یادگیری ماشین، مهندسان داده باید به طور دستی ویژگیهای معناداری را شناسایی و ایجاد کنند که بتوانند به مدل کمک کنند تا الگوهای موجود در دادهها را شناسایی کند. این فرآیند زمانبر و نیازمند دانش عمیق در مورد دادهها و دامنه مورد نظر است.
Deep Learning با در اختیار داشتن دادهها ویژگیهای مرتبط را شناسایی و تجزیه و تحلیل میکند و آنها را بهمنظور یادگیری سریعتر با یکدیگر ترکیب میکند.
مقیاسپذیری
با توجه به این که یادگیری عمیق توانایی تجزیه و تحلیل حجم وسیعی از دادهها را دارد و میتواند محاسبات را در زمان بسیار کم انجام دهد میتوان گفت بسیار مقیاسپذیر است. دیپ لرنینگ میتواند تفاوتهای جزئی در دادهها و اطلاعات را تشخیص دهد و باعث افزایش بهرهوری و قابلیت حمل مدل میشود.
مقرونبهصرفه
ایجاد مدلهای یادگیری عمیق و توسعه آنها ممکن است با هزینههای زیادی همراه باشد؛ اما یکی از بهترین روشهای سرمایهگذاری است و استفاده از آن در کسب و کار و سرمایه میتواند مشکلات جدی و پرهزینه مانند نقص محصول را شناسایی کند. در نتیجه باعث کاهش هزینهها و خسارات کسب و کار میشود و هزینهای که بابت یادگیری عمیق پرداخت میکنید برای شما بهصرفه خواهد بود.
پشتیبانی از یادگیری عمیق در دو حالت موازی و توزیع شده
با استفاده از الگوریتمهای موازی و توزیع شده مشکلاتی مانند زمان بر بودن مدلسازی برطرف میشوند و مدلهای یادگیری عمیق با سرعت بالاتری آموزش داده میشوند. این ویژگی به عواملی مانند حجم دادههای آموزشی و ظرفیت پردازش جی پی یو بستگی دارد و با داشتن تعداد کامپیوتر بالا میتوان زمان آموزش یادگیری عمیق را بسیار کاهش داد.
معایب یادگیری عمیق
1
2
3
4
نیاز به دادههای وسیع
یادگیری عمیق برای آموزش و مدلسازی نیاز به حجم وسیعی از دادهها و اطلاعات دارد تا بتواند نتایج را با دقت و کیفیت بالا را تولدی کند. همچنین دادهها باید بسیار متنوع باشند و بازههای زمانی متعددی را پوشش دهند. این مشکل معمولاً گریبانگیر کسب و کارهای کوچک است که امکان ذخیرهسازی دادههای زیادی را ندارند و همچنین صنایع ممکن است از نظر دسترسی به دادهها با محدودیت مواجه شوند و در نتیجه یادگیری عمیق محدود خواهند شد.
نیاز به دادههای واقعی
علاوه بر نیاز به حجم وسیع از دادهها باید دادههای دریافت شده واقعی باشند؛ ممکن است در دنیای واقعی دادههای معمول تغییر پیدا کنند و مدلهای یادگیری عمیق در این خصوص در محیط نا آشنایی قرار میگیرند و عملکرد خوبی نخواهند داشت.
نیاز به قدرت پردازش بالا
یادگیری عمیق برای مدلسازی به قدرت پردازش بالایی نیاز دارد و برای این کار باید از سختافزارهایی با کارایی بالا استفاده شود. این سختافزارها شامل تراشههای گرافیکی هستندکه برای انجام عملیات برق زیادی مصرف میکنند. همچنین باید از ماژولهای حافظه با ظرفیت کافی استفاده کرد تا بهترین عملکرد حاصل شود. از این رو یادگیری عمیق یک سرمایهگذاری پر هزینه تلقی میشود و باید این موضوع را در نظر گرفت.
مشکل جعبه سیاه
فرایند یادگیری عمیق مانند یک جعبه سیاه عمل میکند و تنها به دریافت ورودی و خروجی میپردازد. با این حساب شما نمیتوانید عملیات انجام شده توسط کامپیوتر را مشاهده کنید و در صورتی که مشکلاتی به وجود آید و عملیات با شکست مواجه شود کاربران و برنامهنویسان نمیتوانند متوجه نقص شوند. برای مثال در زمینه پزشکی هنگام تشخیص تومور مناطقی توسط مدلهای یادگیری عمیق علامتگذاری میشوند که پزشک علت دقیق آن را نمیداند. شاید نتایجی که از یک مدل یادگیری عمیق دریافت میکنیم دقیق و صحیح باشند اما روند و چرایی این انتخابها و نتایج را نمیدانیم.
تفاوت یادگیری ماشین با یادگیری عمیق چیست؟
یادگیری عمیق زیر مجموعهای از روشهای یادگیری ماشین به شمار میرود؛ اما با سایر روشهای یادگیری ماشین تفاوتهایی دارد و به همین دلیل یک دانش مجزا شناخته میشود. یادگیری ماشین به دانشی گفته میشود که کامپیوتر وظایف و کارهای مختلف را بدون نیاز به کمک انسان انجام میدهد؛ اما برای استخراج ویژگی باید از یک فرد متخصص استفاده شود. در صورتی که در یادگیری عمیق نیازی به مهندسی ویژگی نیست و با الگوریتمهای موجود میتواند ویژگیهای موردنظر را درک و شناسایی کند. همین موضوع باعث شده آموزش الگوریتمهای عمیق نسبت به آموزش الگوریتمهای یادگیری ماشین زمان بیشتری را به خود اختصاص دهد. میزان یادگیری کامپیوترها در دیپ لرنینگ از روش یادگیری ماشین عمیقتر است و مدلی شبیه به مغز انسان تولید میکند. یکی از مهمترین تفاوتهای دیپ لرنینگ و یادگیری ماشین حجم دادهها است؛ در یادگیری ماشین با حجم محدودی از دادهها سر و کار داریم در صورتی که یادگیری عمیق به دادههای بسیار وسیع و منابع فراوان برای تجزیه و تحلیل نیاز دارد. تحلیل تصاویر و ویدئوها توسط یادگیری ماشین دشوار است که این ویژگی یکی از مهمترین کاربردهای یادگیری عمیق به شمار میرود. دادههای دریافت شده توسط یادگیری ماشین از نوع ساختار یافته و در یادگیری عمیق از نوع غیر ساختار یافته هستند.