
آنچه در مورد مدل زبانی BERT نمیدانیم
 تیم تحریریه
تیم تحریریه- ۲۹ شهریور ۱۴۰۱
سال 2019 را میتوان سال ورود ترنسفورمر به حوزه پردازش زبان طبیعی نامگذاری کرد؛ در این سال این معماری در صدر تمامی جدولهای ردهبندی (Leaderboards) قرار گرفت و الهامبخش مطالعات تحلیلی بسیاری بود. بیشک مشهورترین ترنسفورمر، مدل زبانی BERT است (دولین، چانگ، لی و توتانووا، 2019). این مدل زبانی کاربردهای بیشماری دارد و پژوهشگران زیادی در مطالعات خود دانش زبانی این مدل را از جهات مختلف بررسی و ارزیابی کردهاند تا وجود چنین دانشی را، هرچند کم، اثبات کنند (گلدبرگ،2019؛ هویت و مانینگ، 2019؛ اتینگر، 2019).
سؤال: در مدل زبانی BERT که به صورت دقیق تنظیم شده چه روی میدهد؟ به بیان دقیقتر، این مدل زبانی از چه تعداد الگوی خودتوجه که به لحاظ زبانی قابل تفسیر هستند و ادعا میشود نقاط قوت این مدل هستند، برای انجام مسائل downstream استفاده میکند؟
برای پاسخ دادن به این سؤال، BERT را بر روی تعدادی از مسائل و دیتاستهای GLUE (ونگ و همکاران، 2018) به صورت دقیق تنظیم کردیم:
- تشخیص بازنویسی Paraphrase detection ( MRPC و QQP)
- تشابه متنی Textual similarity (STS-B)
- تحلیل احساسات (SST-2)
- ارتباط متنی Textual entailment (RTE)
- استنباط زبان طبیعی ( QNLI، MNLI)
مقدمهای کوتاه بر مدل زبانی BERT
BERT کوتاهشده عبارت Bidirectional Encoder Representations from Transformers است. این مدل زبانی در واقع یک انکودر ترنسفورمر دوسویه و چندلایه است (دولین، چانگ، لی و توتانووا، 2019) و مطالب آموزشی متعددی در مورد نحوه عملکرد آن نوشته شده است و برای نمونه میتوان به IIIustrated Transformer اشاره کرد. در این نوشتار به معرفی یکی از اجزای اصلی معماری ترنسفورمر یعنی مکانیزم خودتوجه میپردازیم. به زبان ساده، در مکانیزم خودتوجه اجزای توالی ورودی و خروجی ارزیابی و وزندهی میشوند و بر همین اساس میتواند روابط بین آنها را حتی در جملات با وابستگیهای طولانی، مدلسازی کند.
به این مثال ساده توجه کنید: فرض کنید میخواهیم یک بازنمایی از جمله «تام یک گربه سیاه است» ایجاد کنیم. ممکن است مدل زبانی BERT توجه خود را به واژه «تام» معطوف کند و به صورت همزمان کلمه «گربه» را رمزگذاری کند و توجه کمتری به لغات «است»، «یک» و «سیاه» نشان دهد. این روند را میتوان به صورت بُرداری از وزنها نشان داد (برای هر یک از کلمات تشکیلدهنده جمله). پس از اینکه مدل هر یک از کلمات تشکیلدهنده توالی را کدگذاری کرد، بُردارها محاسبه میشوند و در نتیجه یک ماتریس مربعی به دست میآید که نگاشت خودتوجه نامیده میشود.
بدیهی است که ارتباط میان «تام» و «گربه» همیشه بهترین رابطه نیست. مدل برای پاسخ دادن به سؤالات مرتبط با رنگ گربه بهتر است به جای «تام» بر روی کلمه «سیاه» تمرکز کند. خوشبختانه در چنین مواردی مدل مجبور به انتخاب نیست. برتری BERT (و دیگر ترنسفورمرها) تا حد زیادی ناشی از این واقعیت است که لایههای این مدل از شاخههای (head) متعددی تشکیل شده و تمامی این شاخهها شیوه ساخت نگاشتهای خود توجه مستقل را یاد میگیرند. به لحاظ نظری، این امر مدل را قادر میسازد تا « در موقعیتهای گوناگون به اطلاعات به دست آمده از زیرفضای بازنماییهای مختلف توجه کند» (واسوانی و همکاران، 2017). به زبان ساده، در این حالت مدل برای حل مسئله مورد بحث، از میان بازنمایی مختلف حق انتخاب دارد.
در مدل زبانی BERT وزنهای خود توجه بیشتر در طول فرایند پیش آموزش محاسبه میشوند: مدل بر روی دو مسئله ( مدلسازی زبانی مخفی Mask language model و پیشبینی جمله بعدی)، (از قبل) آموزش داده میشود و به دنبال آن برای حل مسائل downstream (برای مثال تحلیل احساسات) به صورت دقیق تنظیم میشود. ایده اصلی تقسیمبندی فرایند آموزش به دو مرحله پیش آموزش نیمهنظارتی و تنظیم دقیق بانظارت، به یادگیری انتقالی برمیگردد: به طور معمول، دیتاستهای مسئله به اندازهای کوچک هستند و به همین دلیل نمیتواند چیز زیادی در مورد زبان یاد بگیرند، اما برای مدلسازی زبانی میتوانیم از پیکرههای متنی بزرگ استفاده کنیم. بدین ترتیب میتوانیم از جملات و متون بازنماییهایی به دست بیاوریم که حاوی اطلاعات مفید و مستقل از مسئله هستند و آنها را برای حل مسائل downstream «تطبیق» دهیم.
لازم به ذکر است که نه تنها در مقاله BERT بلکه در گزارش تخصصی GPT هم (که در آن به پیش آموزش/ تنظیم دقیق اشاره شده) کارکرد «تطبیق» به طور کامل توضیح داده نشده است. اگر توجه بتواند راهی برای «پیوند دادن» اجزای توالیِ ورودی پیش روی ما بگذارد و از این طریق سطح اطلاعات آن را افزایش دهد و از سوی دیگر برای ایجاد نگاشتهای توجه به معماری چند لایه و چند شاخه نیاز باشد، مدل در طول فرایند آموزش مدل یاد میگیرد به نگاشتهایی توجه کند که به حل بهتر مسئله مورد بحث کمک میکنند. برای مثال، میتوان انتظار داشت که در اجرای عملیات تحلیل احساسات، رابطه بین اسمها و صفتها مهمتر از رابطه بین اسمها و حروف اضافه باشد و مدل از طریق تنظیم دقیق یاد میگیرد که توجه بیشتری به نگاشتهای خودتوجه مفید نشان دهد.
مدل چه نوع الگوهای خودتوجه و از هر نوع چه تعدادی را یاد میگیرد؟
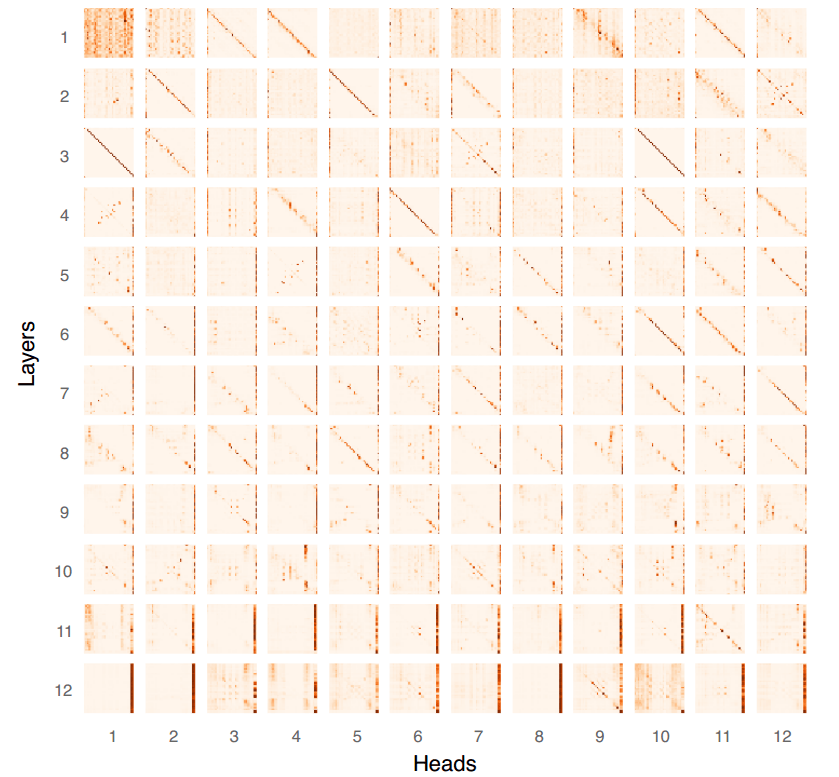
در مدل زبانی BERT چه نوع الگوهای خودتوجهی وجود دارد؟ همانگونه که در تصویر مقابل مشاهده میکنید، پنج نوع الگو در این مدل وجود دارد.

- الگوی عمودی، توجه به یک توکن واحد را نشان میدهد؛ به طور معمول این توکن یا توکن [SEP] است (توکنی که پایان جمله را نشان میدهد) یا توکن [CLS] است (توکن مخصوص BERT که به عنوان بازنمایی کامل توالی به کلاسیفایرها تغذیه میشود).
- الگوی قُطری، توجه به کلمه قبلی/بعدی را نشان میدهد.
- الگوی بلوک، توجه تقریباً یکنواخت به تمامی توکنهای یک توالی را نشان میدهد.
- الگوری ناهمگن تنها الگویی است که به لحاظ نظری میتواند با هر چیزی، برای مثال با روابط معناردار میان اجزای توالی ورودی، مطابقت داشته باشد.
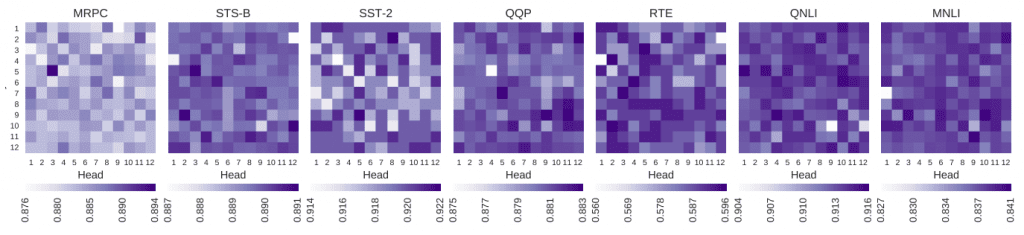
در نمودار مقابل نسبت این پنج نوع توجه در مدل BERT که به صورت دقیق بر روی 7 مسئله GLUE تنظیم شده ، نشان داده شده است ( هر یک از ستونها 100% تمامی شاخهها در تمامی لایهها را نشان میدهد):

این نسبتها برحسب مسئله مورد بحث متغیر هستند، اما در بسیاری موارد این الگوهای معنادار کمتر از نیمی از وزنهای خود توجه مدل BERT را تشکیل میدهند. حداقل یک سوم از شاخههای مدل BERT به توکنهای [SEP] و [CLS] توجه میکنند – استراتژیای که نمیتواند حجم زیادی از اطلاعات مفید را به بازنماییهای لایه بعدی ارسال کند. علاوه بر این از این مطب میتوانیم چنین استنباط کنیم که تعداد پارامترهای مدل بیش از اندازه زیاد است و به همین دلیل است که اخیراً افرادی تلاش کردهاند آن را فشرده کنند و البته موفق هم بودهاند (سان، دبو، شوموند و وولف، 2019؛ جیائو و همکاران، 2019).
توجه داشته باشید که ما BERT پایه را بررسی کردیم؛ این مدل کوچکتر است و 12 شاخه و 16 لایه دارد. در صورتیکه تعداد پارامترهای این مدل زیاد باشد، بر روی BERT بزرگ و مدلهای آتی که بعضی از آنها 30 برابر بزرگتر هستند، تأثیر خواهد گذاشت (وو و همکاران، 2016)
وابستگی مدل به توکنهای [SEP] و [CLS] میتواند دو معنی داشته باشد: 1- این توکنها به نوعی بازنماییهای مفیدی که از لایههای ابتدایی به دست آمده را «فراگرفته» و نیازی به نگاشتهای خودتوجه نیست و یا 2- BERT آنقدر که انتظار میرود به نگاشتهای خودتوجه وابسته نیست.
در فرایند تنظیم دقیق چه روی میدهد؟
سؤال دوم: در طول فرایند تنظیم دقیق BERT چه تغییراتی روی میدهد؟
هیتمپ زیر شباهت کسینوسی میان ماتریسهای نگاشت مسطح (flattened) خودتوجه هر شاخه و لایه، قبل و بعد از اجرای عملیات تنظیم دقیق را نشان میدهد. رنگهای تیرهتر مبین تفاوت بیشتر در بازنمایی هستند. عملیات تنظیم دقیق برای تمامی مسائل GLUE در سه قدم (epoch) انجام شد.

همانگونه که میبینید اکثر وزنهای توجه فقط کمی تغییر کردهاند و برای بیشتر مسائل، دو لایه آخر دستخوش تغییرات زیادی شدهاند. به نظر میرسد این تغییرات در نوع خاصی از الگوهای توجه روی نمیدهد و در تمامی آنها یکسان است. در عوض، متوجه شدیم که مدل یاد میگیرد به الگوهای عمودی توجه بیشتر دقت کند. به مثال SST مقابل توجه کنید: الگوهای عمودی توجه در لایه آخر به این دلیل پهنتر هستند که به [SEP] نهایی و توکنهای نشانهگذاری قبل از آن به یک اندازه توجه میشود و به نظر میرسد الگوهای توجه عمودی در آن بیشتر است.
این حالت میتواند دو معنا داشته باشد:
- الگوی عمودی به نوعی کافی است؛ به عبارت دیگر بازنماییهای توکن [SEP] الگوهای معنادار توجه را از لایههای قبلی فراگرفتهاند. در ضمن ما متوجه شدیم که لایههای ابتدایی بیشتر به [CLS] توجه میکنند و [SEP] بر روی بیشتر مسائل تسلط دارد (شکل 6)؛
- هرچند الگوهای معنادار توجه یکی از ویژگیهای اصلی ترنسفورمرها هستند اما برای حل مسائل مورد بحث به آنها نیازی نیست.
انجام عملیات تنظیم دقیق تا چه میزان تأثیرگذار است؟
با توجه به اینکه حجم دیتاستهای مورد استفاده در فرایند پیشآموزش و تنظیم دقیق بسیار متفاوت است و مدلها هم برای دستیابی به اهدافی کاملاً متفاوت آموزش میبینند، دانستن اینکه انجام عملیات تنظیم دقیق تا چه میزان تأثیرگذار است و تفاوت ایجاد میکند، خالی از لطف نیست. تا جایی که اطلاع داریم این سؤال تا به امروز بیجواب مانده است.
برای پاسخ دادن به این سؤال سه آزمایش بر روی دیتاستهای GLUE (7 دیتاست مورد استفاده در این پژوهش) انجام دادیم و عملکرد مدل را در سه شرایط و موقعیت متفاوت بررسی و ارزیابی کردیم:
- حالت اول: وزنهایی که در مرحله پیش آموزش منجمد شده بودند را به کلاسیفایرهای مختص حل مسئله تغذیه کردیم؛
- حالت دوم: از مدلی استفاده کردیم که به صورت تصادفی مقداردهی شده بود (این مقادیر در بازه توزیع نرمال قرار داشتند) و آن را طی سه مرحله (epoch) بر روی دیتاستهای حل مسئله به صورت دقیق تنظیم کردیم؛
- حالت سوم: از مدل BERT پایه که از قبل آموزش دیده بود و طی سه مرحله بر روی دیتاستهای حل مسئله به صورت دقیق تنظیم شده بود، استفاده کردیم.
نتایج این آزمایش را میتوانید در جدول مقابل مشاهده کنید:

بدیهی است مدلی که از قبل آموزش دیده و به صورت دقیق تنظیم شده بهترین نتایج را کسب میکند، اما مدل BERT که به صورت تصادفی مقداردهی شده و به صورت دقیق تنظیم شده هم توانست بر روی تمامی مسائل، به غیر از تشابه متنی (STS)، عملکرد فوقالعاده خوبی داشته باشد. نتایج حاصل از این آزمایش نشان میدهد اگر مدل BERT را به صورت تصادفی مقداردهی و به صورت دقیق تنظیم کنیم، میتواند بدون اینکه لازم باشد از قبل آموزش ببنید، به نرخ دقت 80 درصدی دست پیدا کند.
با توجه به مقیاس ترنسفورمرهای بزرگی که از قبل آموزش دیدهاند، این سؤال اساسی مطرح میشود که آیا اجرای فرایند هزینهبر پیشآموزش ضروری و لازم است، یا به عبارتی آیا نتایج حاصل از این فرایند ارزش مقدار هزینهای که صرف میکنیم را دارد یا خیر. سؤال دیگری که مطرح میشود متوجه آن دسته از دیتاستهای NLP است که ظاهراً برای حلشان به دانش زبانی زیادی، که از فرایند پیشآموزش و تنظیم دقیق انتظار میرفت، لازم نیست.
تاریخ به روزرسانی (18/01/2020): با تشکر از سَم بُومن برای یادآوری این نکته که نتایج مدل تصادفی BERT به خطوط مبنای GLUE (پیش از روی کار آمدن ترنسفورمر) نزدیک هستند و همین نکته نشان میدهد که بدون کسب دانش زبانی زیاد هم میتوان این مسائل را حل کرد. لذا جامعه NLP باید زمان بیشتری را صرف کار و آزمایش بر روی دیتاستهای دشوارتر بکند که حل آنها نیازمند چنین سطحی از دانش زبانی است و در همین میان ما هم باید به جای GLUE از SuperGLUE استفاده کنیم.
توجه داشته باشید که خطوط مبنای GLUE و ورودی بیشتر مدلهایی که برای انجام این مسائل اجرا شده بودند، تعبیههای کلمات یا بردارهای مبتنی بر شمارش کلمات بودهاند، در حالیکه مدل تصادفی BERT ما به طور کامل تصادفی بوده است. لذا مقایسه این دو منصفانه نیست. هرچند فقط برای SST میتوانیم این مقایسه را به کمک Recursive Neural Tensor Network انجام دهیم (ساچر و همکاران، 2013). این مدل که در سال 2013 طراحی و ساخته شده نسبت به BERT بسیار کوچکتر است و ورودی آن بُردارهای تصادفی هستند، اما توانسته در مسئله طبقهبندی باینری با کسب 7 امتیاز بیشتر بر مدل BERT که به صورت تصادفی مقداردهی و به صورت دقیق تنظیم شده، غلبه کند.
آیا شاخههای خود توجهی که به لحاظ زبانی قابل تفسیر باشند وجود دارد؟
در این برحه از زمان، پژوهشهای متعددی به منظور یافتن شاخههای خود توجهی که نوع خاصی از اطلاعات را کدگذاری میکنند، انجام شده است اما تمرکز بیشتر آنها بر نحو (Suntax) بوده است. ما با تمرکز بر روی مؤلفههای معناییِ فریم آزمایشی انجام دادیم: برای انجام این آزمایش 473 جمله را که طول بیشتر آنها به اندازه 12 توکن بود (برای کاهش تعداد جملاتی که چندین فریم را فراخوان (ایجاد) میکنند) را از FrameNet 1.7 استخراج نمودیم. هر کدام از این جملات یک فریم اصلی (مرکزی) داشتند که به اندازه دو توکن تا کلمه هدف (صرفنظر از کارکرد نحوی) فاصله داشت.
در مثال مقابل، رابطه میان Experiencer و فعل گذشته “agitated” فریم Emotion_directed را فراخوان کرده است. به طور قطع چنین روابطی در درک موقعیتهایی که در جملات توصیف میشود اهمیت زیادی دارند و تمامی مکانیزمهایی که مدعی هستند نگاشتهای خودتوجهی دارند که دارای اطلاعات زبانی سودمند و غنی هستند باید این روابط (از میان تمام روابطی که احتمالاً وجود دارد) را منعکس کنند.
ما با استفاده از BERT که از قبل آموزش دیده بود بازنماییهای این جملات را به دست آوردیم و حداکثر وزن میان دو توکن مربوط به روابط معنایی فریم حاشیهنویسی شده را محاسبه کردیم. شکل 5 نشاندهنده میانگین امتیاز تمامی نمونههای موجود در دیتاست FrameNet است. نتایج حاصل از این آزمایش نشان میدهد که دو شاخه (شاخه دوم در لایه اول، شاخه ششم در لایه هفتم) نسبت به شاخههای دیگر، توجه بیشتری به این روابط معنایی نشان میدهند.

در زمان استنباط از چه اطلاعاتی استفاده میشود؟
به عقیده ما نمیتوان بر مبنای وزنهای مدل از پیش آموزش دیده BERT اطلاعات کدگذاریشده را مشخص کرد. با توجه به اندازه مدل شاید بتوانیم نشانههایی مبنی بر کدگذاری روابط دیگر پیدا کنیم ( جواهر و همکاران متوجه شدند طرحهای متفاوت تجزیه تفاوت چندانی با یکدیگر ندارند (جواهر، ساگوت و سداح، 2019)). سؤالی که در اینجا مطرح میشود این است که آیا مدل در زمان استنباط یاد میگیرد به این اطلاعات توجه کند؟
برای اینکه نشان دهیم آیا مدل زبانی BERT که به صورت دقیق تنظیم شده، از آن دو شاخهای که گفتیم روابط معنایی فریم را کدگذاری میکنند، استفاده می کند یا خیر، پژوهشی انجام دادیم و مؤلفههای کارکرد مدل Ablation study را بررسی کردیم و هر بار فقط یک شاخه را غیرفعال کردیم ( به عبارت دیگر، وزنهای یکسان را جایگزین وزنهای توجه آموخته شده کردیم). شکل 6، هیتمَپ مسائل GLUE در نمونه ما است و هر سلول عملکرد را با هر با غیرفعال شدن شاخه، نشان میدهد.
بدیهی است که الگوی کلی هر مسئله با مسئله دیگر تفاوت دارد، اما بهتر است شاخه تصادفی را حذف کنیم، به بیان سادهتر شاخههایی که فکر میکردیم عملکرد بهتری در کدگذاری اطلاعات معنادار دارند برای تمامی مسائل کاربرد دارند. علاوه بر این بسیاری از شاخهها را میتوان بدون آنکه خللی در عملکرد مدل ایجاد کنند، حذف کرد که حاکی از این امر است که تعداد پارامترهای BERT پایه بیش از اندازه زیاد است.
در مسائل یادگیری ماشین وزنها را صفر کردیم و آنها را با توجه یکسان جایگزین کردیم و به نتایج مشابهی دست پیدا کردیم (میشل، لِوی و نیوبیگ، 2019). در ضمن متوجه شدیم که این مشاهدات علاوه بر شاخهها، لایهها را هم شامل میشوند؛ بسته به مسئلهای که قصد داریم حل کنیم، یک لایه کامل میتواند بر عملکرد مدل تأثیرگذار باشد.

جمعبندی
نوآوری پژوهش ما در این است که فرایند تنظیم دقیق مدل را به دقت بررسی کردیم و میزان تأثیرگذاری و اهمیت بازنماییهایی که از مکانیزم خود توجه به دست میآیند را مشخص کردیم. تا به این لحظه نمیتوانستیم تأثیرگذاری و اهمیت نگاشتهای زبانی را بر روی عملکرد مدل زبانی BERT که به صورت دقیق تنظیم شده اثبات کنیم.
پژوهش ما به جهات مختلفی با مباحثات حول موضوع مدلهای مبتنی بر ترنسفورمر مرتبط است:
- تعداد پارامترهای BERT بیش از اندازه زیاد است: ما در پژوهشمان هر بار یکی از شاخهها را غیرفعال کردیم و اینکه غیرفعال کردن شاخهها در بسیاری موارد خللی در عملکرد مدل ایجاد نکرده به این معناست که بسیاری از شاخهها کارکرد یکسانی دارند؛ به بیانی ساده، غیرفعال کردن یکی از شاخهها، تأثیر مخربی بر مدل ندارد چرا که این اطلاعات در بخشهای دیگری هم در دسترس هستند. نتایج حاصل از این پژوهش دال بر بیش پارامتری بودن مدل است و همین امر توجیهی بر موفقیت مدلهای کوچکتر BERT از جمله AIBERT و TinyBERT است.
بیش پارامتری بودن به این معنا است که BERT احتمالاً شاخههای مهم زیادی با الگوهای خودتوجهی زبانی دارد، اما برای اثبات وجود چنین شاخههایی میبایست تمامی ترکیبات شاخهایِ ممکن را غیرفعال میکردیم. در پژوهشی که به تازگی انجام شده، جایگزین مناسبی برای آن پیشنهاد شده است: ووآتا، تَلبوت، موآسیو، سِنریچ و تیتوو، 2019 مدل را با هدف منظمسازی به صورت دقیق تنظیم کردند (که در نتیجه آن عمل هرس کردن انجام شد) و از این طریق شاخههای «مهم» ترنسفورمر را شناسایی کردند.
- BERT برای حل این مسائل به این میزان از هوشمندی نیاز ندارد. این واقعیت که BERT میتواند بدون اینکه از قبل آموزش ببیند، در حل بیشتر مسائل GLUE به خوبی عمل کند مبین این نکته است که حل این مسائل مستلزم کسب دانش زبانی زیادی نیست. شاید این مدل به جای استدلال کلامی یاد بگیرد که برای پیشبینی صحیح به میانبرها، سوگیریها و آرتیفکتهای موجود در دیتاست تکیه کند. در چنین موقعیتی، نگاشتهای خودتوجه مدل لزوماً نباید برای ما معنادار باشند. یافتههای این پژوهش وجود اشکلات و ایراداتی که در دیتاستهای موجود به چشم میخورد، را اثبات میکند (گورورانگان و همکاران، 2018؛ مککوی، پالویک و لینزن، 2019).
در ضمن میتواند به این معنا باشد که دلیل موفقیت مدل زبانی BERT ، جادوی سیاه، یا چیزی غیر از مکانیزم خودتوجه است. برای نمونه، توجه بیش از اندازه به نشانهگذاری پیش از فرایند تنظیم دقیق میتواند مبین این نکته باشد که مدل واقعاً یاد گرفته به مؤلفههای دیگر توجه کند یا این نتایج متأثر از الگوی دیگری هستند که ما از درک آن عاجز هستیم. البته مذاکرات پیرامون این موضوع که از کدام توجه میتوان برای توضیح پیشبینیهای مدل استفاده کرد، همچنان ادامه دارد (جِین و والِس، 2019؛ سِرانو و اسمیت،2019؛ ویگریف و پینتر، 2019).





