
استفاده از مدلهای آموزشدیده Keras برای استخراج ویژگی در مسائل خوشهبندی تصویر
تیم تحریریه
- ۱ آبان ۱۴۰۰
کتابخانه Keras مجموعهای از آخرین مدلهای یادگیری عمیق فراهم کرده است که وزنهای آن با استفاده از دیتاست ImageNet از پیش آموزش دیدهاند. این مدلهای آموزش دیده را میتوان برای طبقهبندی تصویر، استخراج ویژگی و یادگیری انتقالی استفاده کرد. در این نوشتار مقالهای را با هم مرور خواهیم کرد که درباره استفاده از این مدلها در مسئله خوشهبندی یک زیرمجموعه از تصاویر سگ/گربه (گرفته شده از دیتاستهای Kaggle و Microsoft) نوشته شده است. رویکرد ما در اینجا سه مؤلفهی اساسی دارد:
- استفاده از یک مدل آموزشدیده در کتابخانه Keras، همچون VGG، برای استخراج ویژگی از یک تصویر خاص؛
- استفاده از الگوریتم kMeans در کتابخانه Scikit-Learn برای خوشهبندی مجموعهای از تصاویر سگ/گربه بر اساس ویژگیهای مرتبط؛
- استفاده از ضریب نیمرخ و شاخص رند اصلاحشده در کتابخانه Scikit-Learn به منظور ارزیابی عملکرد روش خوشهبندی.
علاوه بر این موارد، عملکرد چهار مدل آموزشدیده (Vgg16، VGG19، InceptionV3، و ResNet50) را در استخراج ویژگی و انتخاب تعداد خوشههای متفاوت برای الگوریتم kMeans در Scikit-Learn نیز مقایسه خواهیم کرد.
1. استفاده از یک مدل آموزشدیده در Keras به منظور استخراج ویژگی از یک تصویر
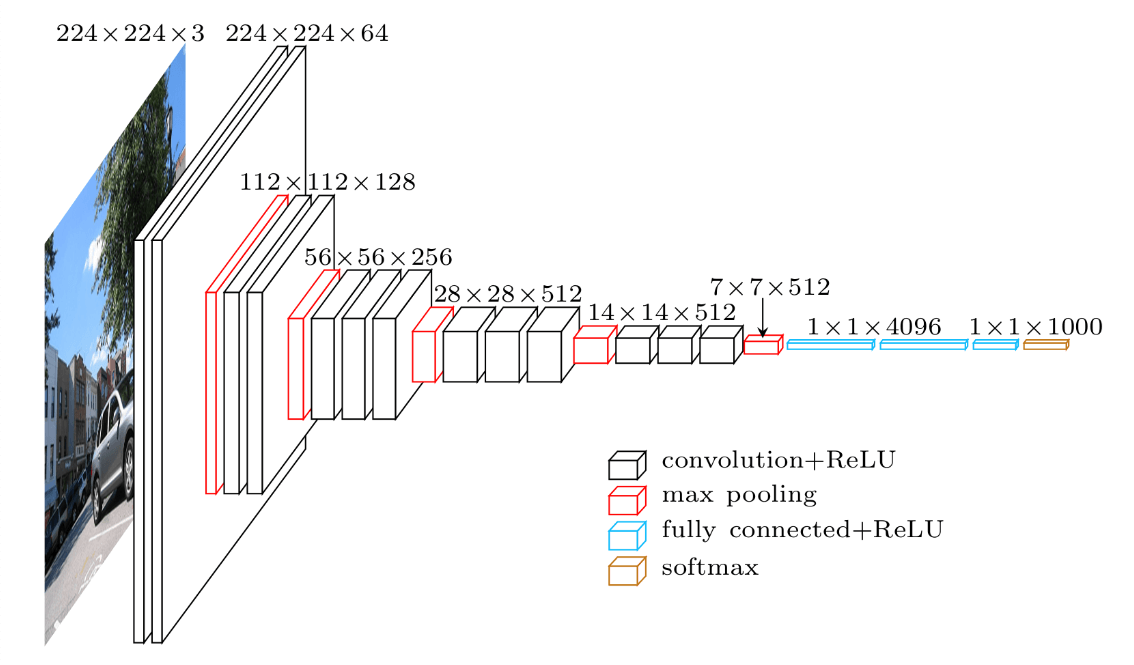
برای استخراج ویژگی ابتدا سراغ VGG میرویم. VGG یک شبکهی عصبی کانولوشنی است که در تشخیص تصویر کاربرد دارد و توسط گروه هندسه تصویری دانشگاه آکسفورد معرفی شده است؛ نام VGG16 به یک مدل VGG اشاره دارد که 16 لایه وزن دارد، به همین ترتیب مدل VGG19 نیز 19 لایه وزن دارد. شکل 2 معماری VGG16 را نشان میدهد: لایهی ورودی تصویری با اندازه (224 x 224 x 3) را دریافت میکند، و لایهی خروجی یک تابع پیشبینی softmax با 1000 کلاس هست. از لایهی ورودی تا لایهی نهایی بیشینه ادغام (که به صورت 7 x 7 x 512 برچسب خورده) به عنوان بخش استخراج ویژگی مدل در نظر گرفته میشود، بقیه قسمتهای شبکه نیز بخش دسته بندی مدل را تشکیل میدهند.
در شکل 3 برنامهای در Keras را مشاهده میکنید که یک تصویر را دریافت کرده و ویژگیهای آن را استخراج میکند. شکل 4 شکل ویژگی را نشان میدهد که مشابه با خروجی مدل استخراج ویژگی است که بالاتر ذکر شد. به خاطر داشته باشید این برنامه برای استخراج ویژگی کاربرد دارد، نه دستهبندی تصویر. برای پیشبینی کلاسهای مربوطه به دیتاست ImageNet مراجعه کنید.
from keras.preprocessing import image from keras.applications.vgg16 import VGG16 from keras.applications.vgg16 import preprocess_input import numpy as np model = VGG16(weights='imagenet', include_top=False) model.summary() img_path = 'train/dogs/1.jpg' img = image.load_img(img_path, target_size=(224, 224)) img_data = image.img_to_array(img) img_data = np.expand_dims(img_data, axis=0) img_data = preprocess_input(img_data) vgg16_feature = model.predict(img_data) print vgg16_feature.shape
کد بالا مربوط به استخراج ویژگی در مدل VGG16 است و کد زیر شکل ویژگیهای استخراجشده توسط مدل VGG16 را نشان میدهد.
(1L, 7L, 7L, 512L)
2. استفاده از الگوریتم kMeans در Scikit-Learn به منظور خوشهبندی تصاویر
در این شکل برنامهای را میبینید که یک مجموعه از تصاویر را تکرار و ویژگیهای آنها را در یک لیست جمعآوری میکند و سپس برای خوشهبندی این ویژگیها از الگوریتم kMeans در Scikit-Learn استفاده میکند.
vgg16_feature_list = []
for idx, dirname in enumerate(subdir):
# get the directory names, i.e., 'dogs' or 'cats'
# ...
for i, fname in enumerate(filenames):
# process the files under the directory 'dogs' or 'cats'
# ...
img = image.load_img(img_path, target_size=(224, 224))
img_data = image.img_to_array(img)
img_data = np.expand_dims(img_data, axis=0)
img_data = vgg16_preprocess(img_data)
vgg16_feature = model_vgg16.predict(img_data)
vgg16_feature_np = np.array(vgg16_feature)
vgg16_feature_list.append(vgg16_feature_np.flatten())
vgg16_feature_list_np = np.array(vgg16_feature_list)
kmeans = KMeans(n_clusters=2, random_state=0).fit(vgg16_feature_list_np)
در اجرای الگوریتم kMeans در Scikit-Learn برای خوشهبندی دو مسئلهی اساسی وجود دارد. اول اینکه، همانطور که مشاهده میکنید، در خط 18 در کد بالا برای اینکه یک ویژگی را از مدل به یک آرایهی تکبُعدی منتقل کنیم، از numpy.ndarray.flatten استفاده میشود؛ الگوریتم kMeans که ورودی آن به ابعاد [n_samples, n_features] است، به این آرایهی تکبُعدی نیاز دارد.
- بعد ویژگی VGG16: (1L, 7L, 7L, 512L)
- بعد ویژگی VGG19: (1L, 7L, 7L, 512L)
- بعد ویژگی InceptionV3: (1L, 5L, 5L, 2048L)
- بعد ویژگی ResNet50: (1L, 1L, 1L, 2048L)
نکتهی دوم مربوط به خط 21 در کد بالا است؛ این خط 2 خوشه را به عنوان یک پارامتر برای الگوریتم kMeans در Scikit-Learn معرفی میکند، امری که با ذات دیتاست ما (تصاویر سگ/گربه) همخوانی دارد. با این حال میتوان گفت تعیین تعداد خوشههای موجود در یک دیتاست یا اعتبارسنجی تعدادی که به صورت پیشفرض در نظر گرفتهایم، گامی حیاتی و مهم در حل مسئلهی خوشهبندی به شمار میرود. از ضریب نیمرخ برای تعیین تعداد خوشهها استفاده میکنیم و بدین وسیله در مراحل بعد تفاوت بین مدلهای آموزشدیده را مقایسه خواهیم کرد.
3. ارزیابی عملکرد روشهای مختلف خوشهبندی
برای ارزیابی عملکرد روشهای خوشهبندی از دو رویکرد استفاده خواهیم کرد:
- اعتبارسنجی خوشهای درونی: در این روش، ساختار نتایج خوشهبندی را بدون استفاده از اطلاعات خارج از دیتاست، یعنی بدون برچسبهای شناخته شده، مورد بررسی قرار میدهیم. به منظور اعتبارسنجی خوشهای درونی، از ضریب نیمرخ در Scikit-Learn استفاده میکنیم. این معیار مقداری بین 1- (برای خوشهبندی اشتباه) تا 1+ (برای خوشهبندیهایی به شدت متراکم) دارد؛ مقادیر نزدیک به صفر نشاندهندهی همپوشانی بین خوشهها هستند.
- اعتبارسنجی خوشهای بیرونی: این رویکرد نتایج روش خوشهبندی را با مقایسه با برچسبهای شناختهشده مقایسه میکند. برای اعتبارسنجی خوشهای بیرونی از شاخص رند تعدیلیافته در Scikit-Learn استفاده میکنیم. این معیار مقداری بین -1 تا +1 دارد؛ مقادیر منفی حاکی از این هستند که خوشههای پیشبینیشده و خوشههای موجود (شناختهشده) به شدت متفاوتاند و مقادیر مثبت به ما میگویند خوشههای پیشبینیشده و خوشههای شناختهشده شباهت دارند. مقدار 1 نشاندهندهی انطباق کامل است.
ابتدا با استفاده از گزیدهای از خوشهها، عملکرد مدل در خوشهبندی 1000 تصویر سگ و 1000 تصویر گربه را با رویکرد اعتبارسنجی خوشهای درونی را مورد بررسی قرار میدهیم.

شکل بالا نمرات معیار نیمرخ مربوط به 4 مدل آموزشدیده (ResNet50، InceptionV3، VGG16 و VGG19) را با استفاده از تعداد خوشههای متفاوت (از 2 تا 10 خوشه) نشان میدهد. از این جدول نکات بسیاری را میتوان دریافت کرد که جای بحث و بررسی بیشتر دارند. برخی از یافتههای این جدول عبارتاند از:
- نمرات معیار نیمرخ برای مدل ResNet50 (ستونهای زردرنگ) نشان میدهند استفاده از 2 خوشه در الگوریتم kMeans در Scikit-Learn بالاترین نمرات را به دست میآورد. بنابراین میتوان گفت که در نظر گرفتن 2 به عنوان k در kMeans بهترین نتیجه را به دست خواهد داد.
- نمرات معیار نیمرخ برای مدل InceptionV3 (ستونهای آبیرنگ) نیز به ما نشان میدهند اختصاص 2 به k در kMeans ما را به بهترین نتیجه میرساند.
- اما، با توجه به نمرات معیار نیمرخ برای مدل VGG16 (ستونهای قرمزرنگ) و نمرات معیار نیمرخ مدل VGG19 (ستونهای سبزرنگ) میتوان اینطور نتیجه گرفت که استفاده از 2 و 3 خوشه نتایجی نزدیک به هم به دست میدهد.
- با بررسی متقاطع نمرات هر چهار مدل (با تعداد خوشههای متفاوت) به این نتیجه میرسیم که ResNet50 همواره بالاترین نمرات را به دست آورده است. InceptionV3 نیز در جایگاه دوم قرار دارد و مدلهای VGG16 و VGG19 به ترتیب در ردههای 3 و 4 جای میگیرند.
به طور خلاصه میتوان گفت ResNet50 با استفاده از 2 خوشه بهترین مدل استخراج ویژگی خواهد بود. با این حال باید از خود بپرسیم آیا نتیجه اعتبارسنجی خوشهبندی درونی با نتیجه اعتبارسنجی خوشهبندی بیرونی توافق نظر دارد؟
شکل زیر نمرات شاخص رند تعدیلبافته را تحت شرایطی که هر چهار مدل از 2 خوشه استفاده کردهاند نشان میدهد. اگر به خاطر داشته باشید شاخص رند تعدیلبافته شباهت بین خوشههای پیشبینی شده و برچسبهای موجود (در حقیقت پایه) را نشان میدهد. با توجه به شکل 7 میبینیم که مدل ResNet50 جایگاه اول، InceptionV3 جایگاه دوم و VGG16 و VGG19 جایگاه سوم و چهار را به دست میآورند. بنابراین میتوان گفت نتایج این رویکرد با رویکرد قبلی (اعتبارسنجی خوشهای درونی) همخوانی دارد.

4. نتیجهگیری
اینجا مقالهای را توضیح دادیم که مربوط به استفاده از مدلهای آموزشدیده برای استخراج ویژگی در مسئلهی خوشهبندی تصویر بود. ما برای ارزیابی عملکرد مدلهای VGG16، VGG19، InceptionV3 و ResNet50 به عنوان مدلهای استخراج ویژگی، روش اعتبارسنجی خوشهای درونی (استفاده از ضریب نیمرخ) و روش اعتبارسنجی خوشهای بیرونی (استفاده از شاخص رند تعدیلبافته) را به کار بردیم. خوشهبندی تصویر بدون شک مسئلهای چالشبرانگیز است. هدف از این نوشتار تعریف چارچوبی برای طراحی و ارزیابی راهکاری برای خوشهبندی تصاویر بود.





