
تحلیل اکتشافی داده ها (EDA) و مقدمهای بر فرآیند آن
 تیم تحریریه
تیم تحریریه- ۲۹ آذر ۱۴۰۰
تحلیل اکتشافی دادهExploratory Data Analysis مهمترین بخش تحلیل داده/ یادگیری ماشین است. این عملیات حدود 70 تا 80% چرخهی زندگی هر پروژهی علوم داده را به خود اختصاص میدهد. اکتشاف، آمادهسازی و درک دادهها، بخشی از روششناختی استاندارد این حوزه است. برای اطلاعات بیشتر میتوانید به این لینک مراجعه کنید.
شناخت انواع دادهها بخش مهمی از فرآیند تحلیل اکتشافی داده به شمار میرود، زیرا روش آماری که برای تجزیه و تحلیل عمقی به کار میبریم به نوع دادهها بستگی دارد. ابتدا نگاهی مختصر به انواع دادهها خواهیم داشت.
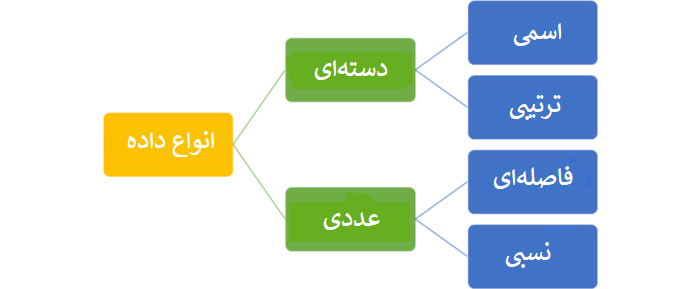
انواع دادهها
- دادههای دستهای: این نوع دادهها دستههایی با ویژگیهای متفاوت دارند؛ مواردی همچون جنسیت، نژاد، رنگ، مقیاس لیکرتیLikert scale ، و غیره در این گروه جای میگیرند. دو نوع داده دستهایcategorical وجود دارد:
- دادههای اسمی: دادههای اسمیNominal data گسسته و غیرکمی هستند؛ برای مثال، جنسیت، رنگ، نژاد و … . این دادهها را نمیتوان رتبهبندی کرد.
- دادههای ترتیبی یا رتبهای: دادههای ترتیبیOrdinal data گسسته هستند اما میتوان آنها را به ترتیب خاصی قرار داد. برای مثال: مقیاس لیکرتی، سطح تحصیلات، ردهی سازمانی (دستیار، دستیار ارشد، مدیر و …).
- دادههای عددی: این نوع دادهها ذاتاً کمی هستند. دو نوع دادهی عددیNumerical وجود دارد:
- فاصلهای: این دادهها ترتیب دارند و میتوان تفاوت و فاصله بین آنها را محاسبه کرد. برای مثال، دما یک متغیر فاصلهای است. دادههای فاصلهایinterval نمیتوانند صفر واقعی داشته باشند.
- نسبی: این نوع دادهها نیز ترتیب دارند و همچون دادههای فاصلهای، فاصلهی بینشان را میتوان محاسبه کرد؛ اما صفر واقعی نیز دارند. نمونهی خوبی از متغیرهای نسبیRatio ، فاصله و یا وزن هستند که مقدار منفی نمیگیرند و صفر واقعی دارند.
اکنون که انواع دادهها را میشناسیم، گامهای فرآیند تحلیل اکتشافی داده را توضیح میدهیم.

1- تعیین نوع داده: دادهها به شکل ردیف و ستون (جدول) ساختاربندی میشوند. ستونهای یک دیتاست دو نوع داده را نشان میدهند: پیشبینPredictor (ورودی)، پاسخResponse (خروجی)؛ این مورد در مورد مدلهای یادگیری نظارتشده صدق میکند. در یادگیری غیرنظارتشده همهی متغیرها باید در گروه ورودی قرار گیرند. جدول پایین به تعیین نوع دادهها کمک میکند:
| نوع داده | نوع متغیر | نقش |
| کمی (عددی) | پیوسته | پاسخ |
| کیفی (متن) | گسسته/ ردهای | پیشبین |
2- تحلیل یکمتغیره: همانطور که از نامش مشخص است، در این مرحله هر کدام از متغیرها باید مورد تجزیه و تحلیل قرار گیرند. دو نوع متغیر پیوسته و گسسته وجود دارد. روش تحلیل هر کدام از این دو نوع در جدول پایین نمایش داده شده است:
| نوع متغیر | ||
| نوع تحلیل | پیوسته | گسسته |
| تحلیل عددی | · تحلیل معیارهای گرایش مرکزی: میانگین، میانه و نما
· معیارهای پراکندگی: دامنه، دامنهی میانچارکی، واریانس، کجی و کشیدگی | · جداول فراوانی برای تعیین فراوانی و فراوانی درصدی
|
| تحلیل تصویری | · نمودار جعبهای و هیستوگرام | · نمودار میلهای، نمودار دایرهای |
3- تحلیل دو متغیری: در این گام رابطهی بین هر دو متغیر موجود در دیتاست را بررسی میکنیم. شناخت این روابط در تعیین متغیر هدف یا متغیرهای پیشبین اهمیت بالایی دارد. این گام کمک میکند متغیرهایی را که ممکن است نویز غیرضروری تولید کرده یا عملکرد مدل را کاهش دهند، تشخیص دهیم. تجزیه و تحلیلی که اینجا انجام میشود به نوع جفتدادهای که انتخاب کردهایم بستگی دارد.
| نوع جفتداده | پیوسته و پیوسته | پیوسته و گسسته | گسسته و گسسته |
| نمودار پراکندگی | نمودار جعبهای متغیر پیوسته با توجه به متغیر گسسته | آزمون خیدو ارتباط بین دو متغیر | |
| روشهای تحلیلی | نقشهی حرارتی همبستگی | آزمون Z یا T برای بررسی این نکته که آیا میانگین دستههای مختلف شبیه هستند یا خیر | جداول دوراهه با فراوانی و سهمها |
| جدول همبستگی | آزمون ANOVA برای بررسی این نکته که آیا میانگین گروههای مختلف به هم شبیه است یا خیر | نمودار میلهای متراکم برای هر کدام از متغیرهای گسسته |
4- مدیریت مقادیر گمشده: مقادیر گمشده میتوانند به دلیل دادههای غیرموجود یا خطاهای دستی در دیتاست به وجود آمده باشند. تشخیص و مدیریت این مقادیر اهمیت زیادی دارد، زیرا تأثیر تعیینکنندهای روی عملکرد مدل خواهد گذاشت. روشهایی که میتوان برای مدیریت این مقادیر به کار برد در جدول زیر به صورت خلاصه بیان شدهاند:
| روش | نحوهی کارکرد |
| حذف | · حذف لیستی: در این روش کل ردیف یا نمونهای که مقدار گمشده به آن تعلق دارد حذف میشود. این روش اندازهی نمونه را کاهش میدهد، اما اجرای آن بسیار آسان است.
· حذف جفتی: در این روش، مکان دادهی گمشده از ستون حذف میشود. این روش باعث میشود اندازهی نمونه برای متغیرهای گوناگون، نابرابر باشد. |
| جایگذاری میانگین/ میانه/ نما | در این روش، یکی از پارامترهای میانگین/ میانه/ نما (هرکدام که برای متغیر موجود مناسبتر بود) در جای خالی مقدار گمشده قرار میگیرد. |
| پیشبینی | یک الگوریتم یادگیری ماشینی مناسب برای پیشبینی مقادیر گمشده به کار میرود. در نتیجه دو مجموعه داده به دست میآید که در یکی مقادیر گمشده وجود دارد و در دیگری نه. از دیتاستی که همهی دادهها را دارد برای آموزش مدل یادگیری ماشینی استفاده میشود و مقادیر گمشدهی دیتاست دیگر، پیشبینی و جایگذاری میشوند. |
| جایگذاری مورد مشابه | در این روش، گروههاِ مرتبط (برای مثال بالاترین سطح تحصیلات) مشخص میشوند و سپس میانگین (مثلاً اگر درآمد مقدار گمشده باشد) بر اساس میانگین آن گروه دیگر جایگذاری میشود. |
5- مدیریت مقادیر تکراری: در این گام، نمونههای تکراری از دیتاست حذف میشوند. مقادیر تکراریDuplicate values میتوانند کارآمدی مدل را کاهش دهند.
6- مدیریت مقادیر پرت: دادههای پرت، مقادیری هستند که به صورت غیرطبیعی از سایر مقادیر ستون خود کوچکتر یا بزرگتر هستند. برای مثال، فرض کنید ارزش خالصNet worth افراد ساکن در یک منطقه را اندازه میگیریم و مقداری بسیار بزرگ در میان این دادهها پیدا میکنیم؛ این میتواند بدین معنا باشد که آن مورد خاص یک تاجر پولدار یا مدیر عالی یک سازمان است که در آن منطقه زندگی میکند. دادههای پرت لزوماً همیشه رخ نمیدهند؛ وجود آنها میتواند به دلیل خطای دفتری هنگام ورود دادهها باشد. در جدول زیر روشهای مدیریت مقادیر پرت را مشاهده میکنید:
| تشخیص | مدیریت | |
| تشخیص تک متغیری | استفاده از نمودارهای جعبهای یا هیستوگرامها که دادههای پرت را نشان میدهند. |
حذف نمونهها، پوشاندن مقادیر پرت در چارک بالاتر (Q4) یا پایینتر (Q1)، دستهبندی (binning) مقادیر |
| تشخیص دو متغیری | استفاده از نمودار پراکندگی در یک فضای n بُعدی که مقادیر پرت و غیرعادی را مشخص میکند. |
7- تبدیل متغیرها: متغیرهایی که با آنها سروکار داریم همیشه در حالت مناسب و ایدهآل قرار ندارند. ممکن است لازم باشد آنها را وارد یک مقیاس رایج کنیم، واریانس ستون را کاهش دهیم، رابطهی بین آنها را خطی کنیم، و یا موارد دیگری از این دست. برخی از این روشها را در جدول پایین میبینید:
| تبدیل | روش استفادهشده |
| تبدیل خطی | تبدیل خطی رابطهی خطی بین متغیرها را حفظ میکند. از روشهایی که برای تبدیل خطی مورد استفاده قرار میگیرند میتوان به این موارد اشاره کرد: ضرب، جمع، تقسیم بر یک یا چند مقدار. |
| تبدیل غیرخطی | مقادیر متغیرها را با استفاده از لگاریتم، جذر، واروونهسازی و … تبدیل میکنند. این روشها به کاهش سوگیری، کجی و دادههای پرت موجود در دیتاست کمک میکنند. |





