
تشخیص کنایه در عناوین خبری با cAInvas
 تیم تحریریه
تیم تحریریه- ۹ تیر ۱۴۰۰
کنایه که در لغت به معنای «پوشیده سخن گفتن» است، در اصطلاح به ترکیب یا جملهای اطلاق میشود که مراد گوینده معنای ظاهری آن نباشد. این عنصر میتواند بار معنایی جمله را دستخوش تغییر قرار دهد. بنابراین، تشخیص کنایه به بخش مهمی از تحلیل احساسات تبدیل شده است. بخش عمدهای از مجموعهدادههای موجود از توئیتهای کاربران شبکه اجتماعی توئیتر گردآوری شده است. این اقدام میتواند به دادههای نویزی با برچسبهای نادرست ختم شود. درکِ محتوای مکالمات، نقشی حیاتی در برچسبزنی متن دارد. در مقاله حاضر، از مجموعهدادهای متشکل از عناوین خبری استفاده خواهیم کرد. این مجموعهداده قابلاطمینان است زیرا عناوین خبری نوشته شده به دست متخصصان حوزه رسانه نوشته شده است. میتوان از آن منبع برای برچسب زدن به نمونههای مجموعهداده استفاده کرد.
پیادهسازی ایده در cAInvas – به این لینک مراجعه کنید.
مجموعهداده
On Kaggle – ریشاب میسرا
این مجموعهداده از دو وبسایت خبری گردآوری شده است. Onion در نظر دارد تا نسخههای کنایهآمیزِ رخدادهای فعلی را ایجاد کند. عناوین خبری نیز از بخش «خلاصه اخبار» و «تصاویر خبری» جمعآوری شدهاند. همچنین، عناوین خبری واقعی (بدون کنایه) از Huffpost گردآوری شده است.


همانطور که در تصویر بالا مشخص است این مجموعهداده از توازن خوبی برخوردار است.
پردازش داده
برای پردازش داده متن و تشخیص کنایه عنوان خبری باید تغییرتی داشته باشد.برای مثال، باید عناصر HTML و URL حذف شوند. در وهله بعد، همه کاراکترهایی که در زمرهی حروف الفبا جای ندارند، حذف شوند. توابع به صورت زیر تعریف شدهاند:
# Remove html tags
def removeHTML(sentence):
regex = re.compile('<.*?>')
return re.sub(regex, ' ', sentence)
# Remove URLs
def removeURL(sentence):
regex = re.compile('http[s]?://\S+')
return re.sub(regex, ' ', sentence)
# remove numbers, punctuation and any special characters (keep only alphabets)
def onlyAlphabets(sentence):
regex = re.compile('[^a-zA-Z]')
return re.sub(regex, ' ', sentence)
کد: توابع پردازش متن
به محض اِتمام عمل پردازش، جمله پیش از آنکه به واژگان ریشه تجزیه شود، به صورت حروف کوچک نوشته میشود. بنابراین، واژگانی که اَشکال متفاوتی از واژگان یکسان هستند، به راحتی مورد شناسایی قرار میگیرند (مثال: خوردن، خورد، میخورد). از ماژول nltk.stem برای یافتن ریشه کلمات استفاده میشود. کلمات توقف حذف نمیشوند زیرا میتوانند به ارائه بافت جمله به صورت کل کمک کنند.
sno = nltk.stem.SnowballStemmer('english') # Initializing stemmer
wordcloud = [[], []]
all_sentences = [] # All cleaned sentences
for x in range(len(df['headline'].values)):
headline = df['headline'].values[x]
sarcasm = df['is_sarcastic'].values[x]
cleaned_sentence = []
sentence = removeURL(headline)
sentence = removeHTML(sentence)
sentence = onlyAlphabets(sentence)
sentence = sentence.lower()
for word in sentence.split():
#if word not in stop:
stemmed = sno.stem(word)
cleaned_sentence.append(stemmed)
wordcloud[sarcasm].append(word)
all_sentences.append(' '.join(cleaned_sentence))
# add as column in dataframe
X = all_sentences
y = df['is_sarcastic']
کد: پردازش متن
واژگان متعلق به هر یک از دستهها با استفاده از WordCloud به صورت جداگانه ذخیره میشوند تا عمل مصورسازی صورت گیرد.


اندازه واژه با فراوانیِ آن در مجموعهداده همخوانی دارد. نمیتوان بر پایه این تصاویر استنباط کرد.
تفکیک آموزش – اعتبارسنجی
تقسیم مجموعهداده به مجموعههای آموزش و اعتبارسنجی با نسبت 20-80.
# Splitting into train and val set -- 80-20 split Xtrain, Xval, ytrain, yval = train_test_split(X, y, test_size = 0.2)
کد: Train-val split
میبینیم که مجموعه آموزش 22895 نمونه و مجموعه اعتبارسنجی 5724 نمونه دارد.
نشانهگذاری
از عمل نشانهگذاریِ ماژول keras.preprocessing.text برای تبدیل متن به توالی اعداد صحیح استفاده میشود. این اعداد به عنوان ورودی در اختیار مدل قرار میگیرند. برای اینکه طول حداکثر 200 به دست آید، این اعداد چمد صفر نیز دارند.
# Tokenization vocab = 1500 mlen = 200 tokenizer = Tokenizer(num_words = vocab, oov_token = '<UNK>') tokenizer.fit_on_texts(Xtrain) Xtrain = tokenizer.texts_to_sequences(Xtrain) Xtrain = pad_sequences(Xtrain, maxlen=mlen) Xval = tokenizer.texts_to_sequences(Xval) Xval = pad_sequences(Xval, maxlen=mlen)
کد: Tokenization (نشانهگذاری)
مدل
برای تشخیص کنایه مدلی که باید آموزش داده شود، از یک لایه تعبیه Embedding layer تشکیل شده که نمونههای ورودی را به آرایههایی با اندازه ثابت تبدیل میکند. یک شبکه حافظه طولانی کوتاهمدت و سه لایه متراکم نیز به کار برده میشوند. دو مورد اول با فعالسازی ReLU و مورد آخر با فعالسازی Sigmoid شناخته میشود. این مدل با استفاده از تابع زیان آنتروپی متقاطع دودویی کامپایل میگردد زیرا فقط دو دسته (صفر و یک) وجود دارد. ابزار بهینهسازی Adam مورد استفاده قرار گرفته و دقت مدل به طور پیوسته بررسی میشود. عمل بازخوانی Early Stopping در ماژول keras.callbacks متریکی برای تعداد دورههای مشخص دارد. اگر این متریک (ابزار سنجش) بهبود نیابد، آموزش متوقف میشود. بر اساس پارامتر restore_best_weights، مدلی که کمترین زیان اعتبارسنجی را دارد، به متغیر مدل بازگردانیده میشود.
# Build and train neural network
embedding_dim = 128
model = models.Sequential([
layers.Embedding(vocab, embedding_dim, input_length = mlen),
layers.LSTM(128, activation='tanh'),
layers.Dense(32, activation = 'relu'),
layers.Dense(16, activation = 'relu'),
layers.Dense(1, activation = 'sigmoid')
])
cb = [callbacks.EarlyStopping(patience = 5, restore_best_weights = True)]
model.compile(optimizer = optimizers.Adam(0.01), loss = loss-es.BinaryCrossentropy(), metrics = ['accuracy'])
history = model.fit(Xtrain, ytrain, batch_size=64, epochs = 256, valida-tion_data=(Xval, yval), callbacks = cb)
کد: Model and training (مدل و آموزش)
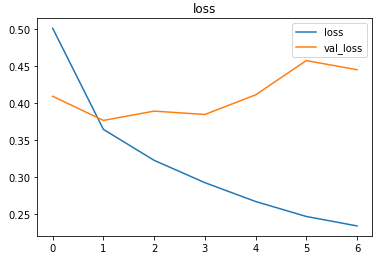
پس از آموزش با نرخ یادگیری 01/0، مدل به دقت %5/83 در مجموعه آزمایشی دست یافت.

پیشبینیهای مجموعه آزمایشی
بررسی اجمالی ماتریس درهمریختگی برای درک بهتر نتایج


پیشبینی
انجام پیشبینی در نمونههای آزمایشی تصادفی
x = np.random.randint(0, Xval.shape[0] - 1)
headline = df['headline'].values[x]
print("Headline: ", headline)
cleaned_text = []
sentence = removeURL(headline)
sentence = removeHTML(sentence)
sentence = onlyAlphabets(sentence)
sentence = sentence.lower()
for word in sentence.split():
#if word not in stop:
stemmed = sno.stem(word)
cleaned_text.append(stemmed)
cleaned_text = [' '.join(cleaned_text)]
print("Cleaned text: ", cleaned_text[0])
cleaned_text = tokenizer.texts_to_sequences(cleaned_text)
cleaned_text = pad_sequences(cleaned_text, maxlen=mlen)
category = df['is_sarcastic'].values[x]
print("\nTrue category: ", class_names[category])
output = model.predict(cleaned_text)[0][0]
pred = (output>0.5).astype('int64')
print("\nPredicted category: ", class_names[pred], "(", output, "-->", pred, ")")
کد: Prediction on test samples (پیشبینی در نمونههای آزمایشی)

deepC
چارچوب استنباط، کامپایلر و کتابخانه deepC با این هدف طراحی شدهاند که شبکه های عصبی یادگیری عمیق به اجرا درآیند. در همین راستا، ویژگی وسیلههای فرم-فکتور از قبیل ریزکنترلگرها، Efpga، CPU و سایر وسیلههای تعبیه شده از قبیل raspberry-pi، odroid، Arduino، SparkFun Edge، RISC-V، تلفن همراه و لپتاپ مورد تاکید قرار میگیرد.
کامپایل کردن مدل با استفاده از deepC
برای تشخیص کنایه ، اجرا و ایجاد فایل .exe خودتان به پلتفرم cAInvas مراجعه کنید.





