خوشه بندی با K-means
 تیم تحریریه
تیم تحریریه- ۲۴ اسفند ۱۴۰۰
• میزان شباهت میاندستهای پایین باشد.
دو نوع اصلی خوشه بندی تحت عنوان خوشه بندی K-means و خوشه بندی سلسلهمراتبی متراکمشونده Hierarchical Agglomerative Clustering وجود دارد. در خوشه بندی K-means، پیدا کردنِ مراکز خوشه k به عنوان میانگین نقطه دادهای در دستور کار قرار دارد. اینجا، تعداد خوشهها (k) از قبل تعیین گردیده است و مدل سعی میکند بهینهترین خوشهها را بر این اساس پیدا کند. ما در مقاله حاضر فقط بر خوشه بندی K-means تمرکز خواهیم کرد.
در همین راستا، میخواهیم از دیتاست وضعیت هوا Kaggle استفاده کنیم. این دیتاست حاوی شاخصهایی از قبیل فشار هوا، سرعت حداکثر باد، رطوبت نسبی و غیره است. دادهها در بازه سه ساله (از ماه سپتامبر 2011 تا ماه سپتامبر 2014) در سندیگو جمعآوری شد. لازم به ذکر میباشد که این دادهها دربردانده اندازهگیریهای حسگر خام بوده و در بازههای یکدقیقهای جمعآوری شده است.در مرحله اول باید کتابخانههای لازم را وارد کرد:
import pandas as pd import numpy as np import matplotlib.pyplot as plt %matplotlib inline import seaborn as sns import sklearn from sklearn.preprocessing import StandardScaler from sklearn.cluster import KMeans from sklearn import metrics from sklearn.cluster import AgglomerativeClustering
و حالا دیتاست:
df = pd.read_csv('minute_weather.csv')
df.head()
 میتوان با بررسی دقیق دادهها به این نتیجه رسید که 1.587.257 ردیف و 13 ستون وجود دارد. چون این دیتاست خیلی بزرگ است، باید نمونهها را به صورت تصادفی به دست آوریم. علاوه بر این، ضروری است که ابتدا در روش خوشه بندی K-means، موقعیت مرکز اولیه هر خوشه را پیدا کنیم تا الگوریتم به همگرایی برسد.
میتوان با بررسی دقیق دادهها به این نتیجه رسید که 1.587.257 ردیف و 13 ستون وجود دارد. چون این دیتاست خیلی بزرگ است، باید نمونهها را به صورت تصادفی به دست آوریم. علاوه بر این، ضروری است که ابتدا در روش خوشه بندی K-means، موقعیت مرکز اولیه هر خوشه را پیدا کنیم تا الگوریتم به همگرایی برسد.
پس به جای کار کردن با کل دیتاست، یک نمونه انتخاب کرده و نقاط مرکزی اولیه به صورت تصادفی مورد بررسی قرار میگیرند.
یک نمونه از هر ده ردیف انتخاب کرده و دیتافریم نمونههای جدید را به صورت زیر ایجاد میکنیم:
sample_df = df[(df['rowID'] % 10) == 0] sample_df.shape
این اقدام باعث ایجاد 158.726 ردیف و 13 ستون میشود.
با بررسی مقادیر پوچ، زمینه برای صرفنظر کردن از rain_accumulation و rain_duration فراهم میشود.
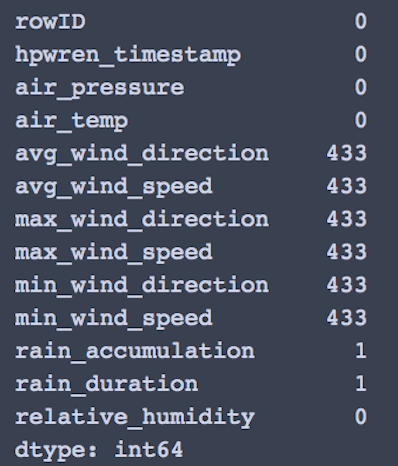
df1 = sample_df.drop(columns =['rain_accumulation','rain_duration']) print(df1.columns)

از میان دو مقدار (سرعت حداکثر باد/ جهت و سرعت حداقل باد/ جهت)، فقط سرعت حداکثر باد با هدف خوشه بندی در این مقاله انتخاب شده است. البته هر کس این اختیار را دارد که مقادیر دیگر را در فرایند تحلیل بگنجاند. سرانجام، ستونهایی که در خوشه بندی به آنها علاقمندیم، به ترتیب زیر در یک دیتافریم جدید سامان داده میشود:
cols_of_interest = ['air_pressure', 'air_temp', 'avg_wind_direction', 'avg_wind_speed','max_wind_direction', 'max_wind_speed', 'relative_humidity']
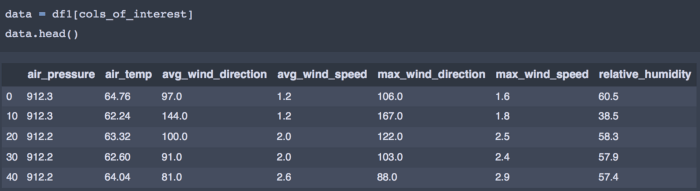
گام بعدی این است که مقادیر را مقیاسبندی کنیم تا همگی اهمیتی برابر داشته باشند. مقیاسبندی از دید خوشه بندی نیز حائز اهمیت میباشد زیرا فاصله میان نقاط بر نحوه شکلگیری خوشهها تاثیر میگذارد.
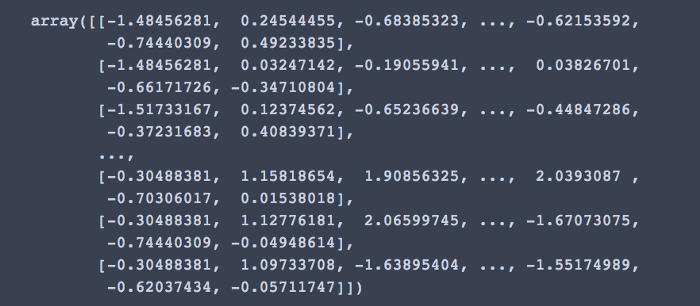
حال نوبت آن است که دیتافریممان را با استفاده از StandardScaler تغییر دهیم:
X = StandardScaler().fit_transform(data) X
خوشه بندی K-means
همانطور که پیشتر اشاره شد، تعداد خوشهها در K-means برای اجرای مدل از قبل تعیین شده است. میتوان تعداد پایه برای k در نظر گرفت و آن را برای یافتن بهینهترین مقدار تکرار کرد. به منظور اینکه مشخص شود چه تعداد خوشه در دیتاستمان وضعیت بهینه دارند یا برازش خوشه را محاسبه گردد، میتوان از دو روش امتیازدهی «ضریب نیمرخ» Silhouette Coefficient و «شاخص کالینسکی هاراباسز» Calinski Harabasz Score استفاده کرد. در واقعیت، بسته به اینکه کدام معیار اندازهگیری بالاترین اهمیت را در مدل دارد، میتوان از روشهای امتیازدهی مختلفی استفاده نمود.
معمولاً یکی از مدلها به عنوان مدل استاندارد انتخاب میشود. من در این مقاله از دو مدل برای تجزیه و تحلیل نتایج استفاده کردم. ضریب نیمرخ با استفاده از فاصله میانگین دروندستهای mean intra-cluster distance و فاصله میانگین نزدیکترین خوشه mean nearest-cluster distance در هر نمونه مورد محاسبه قرار میگیرد.
شاخص کالینسکی هاراباسز یا نسبت واریانس به نسبت میانِ پراکندگی درون خوشهای within-cluster dispersion و پراکندگی بین خوشهای پراکندگی بین خوشهای between-cluster dispersion اطلاق میشود.اکنون نوبت اجرای الگوریتم K-means با استفاده از sci-kit learn مهیا شده است.
n_clusters= 12
#Set number of clusters at initialisation time k_means = KMeans(n_clusters=12) #Run the clustering algorithm model = k_means.fit(X) model #Generate cluster predictions and store in y_haty_hat = k_means.predict(X)
محاسبه ضریب نیمرخ …
from sklearn import metrics labels = k_means.labels_ metrics.silhouette_score(X, labels, metric = 'euclidean')
0.2405
محاسبه شاخص کالینسکی هاراباسز …
metrics.calinski_harabasz_score(X, labels)
39078.93
حالا بیایید همین کار را برای مقدار تصادفی دیگری انجام دهیم (مثلاً n_clusters = 8)
k_means_8 = KMeans(n_clusters=8) model = k_means_8.fit(X) y_hat_8 = k_means_8.predict(X)
باید ضریب نیمرخ و شاخص کالینسکی هاراباسز را مجدداً محاسبه کرد:
labels_8 = k_means_8.labels_ metrics.silhouette_score(X, labels_8, metric = 'euclidean')
ضریب نیمرخ: 0.244
metrics.calinski_harabasz_score(X, labels_8)
شاخص کالینسکی هاراباسز: 41105.01
نکته قابل توجه در هر دو شاخص این است که 8 خوشه، مقدار بهتری ارائه میدهند. با این حال، لازم است این فرایند چندین بار با تعداد خوشههای مختلف تکرار شود تا خوشه بهینه به دست آید. در همین راستا، امکانِ استفاده از روشی موسوم به elbow plot برای یافتن مقدار بهینه وجود دارد. اینجا دو معیار حائز اهمیت است: اعوجاج و لَختی اعوجاج به متوسط فاصله اقلیدسی از مرکز خوشه گفته میشود. اما لَختی مجموع مجذور فاصله نمونهها با نزدیکترین مرکز خوشه است.
#for each value of k, we can initialise k_means and use inertia to identify the sum of squared distances of samples to the nearest cluster centresum_of_squared_distances = [] K = range(1,15) for k in K: k_means = KMeans(n_clusters=k) model = k_means.fit(X) sum_of_squared_distances.append(k_means.inertia_)
به خاطر داشته باشید که شباهت درون خوشهای در K-means حائز اهمیت است و elbow plot نقش مهمی در این زمینه ایفا میکند.
plt.plot(K, sum_of_squared_distances, 'bx-')
plt.xlabel('k')
plt.ylabel('sum_of_squared_distances')
plt.title('elbow method for optimal k')
plt.show()
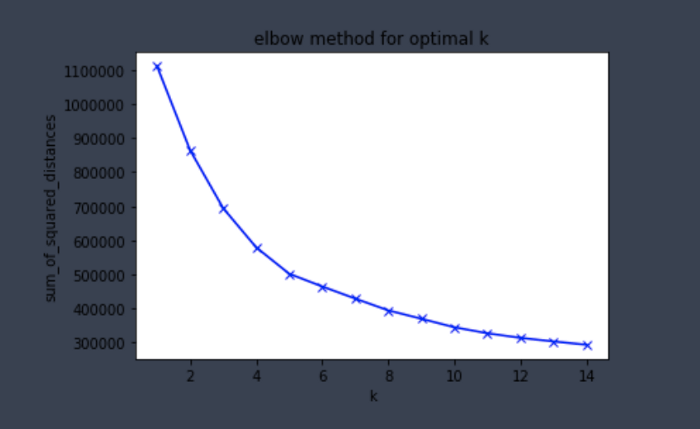 کاهشِ مجموع مجذور فاصله پس از k=5 مشهود است. از این رو، 5 به عنوان تعداد بهینه خوشهها در تحلیل شناخته میشود. این ادعا با محاسبه ضریب نیمرخ و شاخص کالینسکی هاراباسز در k=5 قابل محاسبه است.
کاهشِ مجموع مجذور فاصله پس از k=5 مشهود است. از این رو، 5 به عنوان تعداد بهینه خوشهها در تحلیل شناخته میشود. این ادعا با محاسبه ضریب نیمرخ و شاخص کالینسکی هاراباسز در k=5 قابل محاسبه است.
k_means_5 = KMeans(n_clusters=5) model = k_means_5.fit(X) y_hat_5 = k_means_5.predict(X)labels_5 = k_means_5.labels_ metrics.silhouette_score(X, labels_5, metric = 'euclidean')metrics.calinski_harabasz_score(X, labels_5)
ضریب نیمرخ: 0.261
شاخص کالینسکی هاراباسز: 48068.32

هر دو مقدار بالاتر از مقادیری هستند که در خوشههای 12 و 8 به دست آمد. پس میتوان این چنین نتیجه گرفت که k=5 تعداد بهینه برای خوشههاست. از تابع زیر برای ایجاد نقشه استفاده شد.
#function that creates a dataframe with a column for cluster numberdef pd_centers(cols_of_interest, centers):
colNames = list(cols_of_interest)
colNames.append('prediction')# Zip with a column called 'prediction' (index)
Z = [np.append(A, index) for index, A in enumerate(centers)]# Convert to pandas data frame for plotting
P = pd.DataFrame(Z, columns=colNames)
P['prediction'] = P['prediction'].astype(int)
return PP = pd_centers(cols_of_interest, centers)
P