
درخت تصمیم گیری تحولی: وقتی یادگیری ماشین از علم زیستشناسی الهام میگیرد
 تیم تحریریه
تیم تحریریه- ۲۱ دی ۱۴۰۰
پیش از شروع بحث درباره درخت تصمیم، بهتر است به عنوان مقدمه، مطلب را اینطور آغاز کنیم. رشد چشمگیر دانش در حوزه زیستشناسی (علم زندگی) در گذر زمان، الهامبخش بسیاری از مهندسانی شده که به مسائل چالشبرانگیزی برخورده و به دنبال راهحلهای خلاقانه هستند.
برای نمونه قطار پرسرعت ژاپنی Shinkansen را در نظر بگیرید که با سرعت 300 کیلومتر بر ساعت یکی از سریعترین قطارهای جهان به شمار میرود. در زمان طراحی این قطار، مهندسان به یک مشکل جدی برخوردند و آن صدای بسیار بلند قطار بود که به دلیل جابجایی سریع جریان هوای جلوی قطار ایجاد میشد؛ این صدا به قدری زیاد بود که میتوانست به بعضی از تونلها آسیب وارد کند.
مهندسان برای حل این مسئله از یک منبع غیرمعمول استفاده کردند: مرغ ماهیخوار kingfisher! این پرنده یک نوک بلند و کشیده دارد که او را قادر میسازد با کمترین سروصدا درون آب شیرجه بزند.
بدین ترتیب با طراحی مجدد قطار به شکل این پرنده مهندسان توانستند مشکل صدای بلند قطار را از بین ببرند، علاوه بر این مصرف برق قطار را 15% کاهش و سرعت آن را 10% افزایش دهند.

درخت تصمیم گیری تحولی
در این مقاله روی درختهای تصمیم تمرکز خواهیم داشت.
درختهای تصمیمگیری ردهبند classifierهایی هستند که از الگوریتمهای تحولی Evolutionary algorithms استفاده میکنند. این الگوریتمها متکی بر مکانیزمهایی الهامگرفته از فرآیند تحول طبیعی هستند که به ساخت درختهای تصمیم با عملکردی خوب و قوی منجر میشوند. بعد از مطالعه این متن قادر خواهید بود به این سؤالات پاسخ دهید:
- درخت تصمیم چیست؟
- چطور از الگوریتمهای تحولی برای ساخت یک درخت تصمیم استفاده کنیم؟
- عملکرد درختهای تصمیم تحولی در مقایسه با سایر ردهبندها چگونه است؟
دیتاست
برای روشنسازی مفاهیم مطرحشده در این مقاله، از دیتاستی استفاده شده که دادههای آن نتایج یک نظرسنجی از رضایت مسافران یک شرکت هواپیمایی هستند.
هدف پیشبینی میزان رضایت مشتری از خدمات این شرکت هواپیمایی است. مطالعه این نتایج برای سیاستهای تصمیمگیری شرکت اهمیتی حیاتی دارد. بدین صورت که به شرکتهای ارائهدهنده خدمات و کالاها میگوید کدام جنبههای محصولات خود را باید بهبود بخشند و این بهبود باید چه جهت و چه سرعتی داشته باشد.
[irp posts=”24220″]1- درخت تصمیم چیست؟
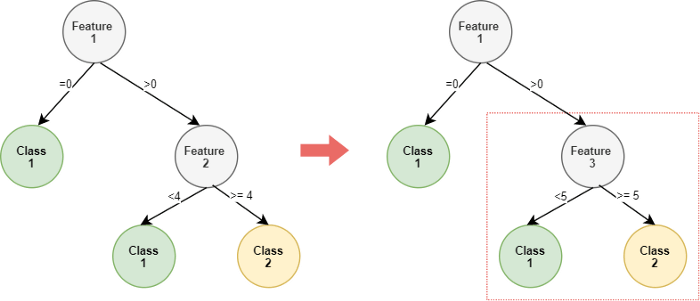
درخت تصمیم به ردهبندی گفته میشود که بر یک گردشکار Flow-chart شبه درخت مبتنی است. مدل زیربنایی درختِ تصمیم با یادگیری چند قانون تصمیمگیری ساده که از ویژگیهای دادهها استنباط شدهاند، مشاهدات را ردهبندی میکند.
نمودار پایین نمونهای از یک درخت تصمیم را نشان میدهد که بر روی دادههای نظرسنجی مذکور و با استفاده از ماژول درخت تصمیم Sickit-learn آموزش داده شده است.

این درخت تصمیم به ما میگوید که عامل اصلی رضایت مشتریان در سفرهای کاری امکان بوردینگ آنلاین است؛ در نتیجه شرکت میفهمد که بوردینگ آنلاین و بهصرفه رضایت مسافران را افزایش خواهد داد. از این درخت همچنین میتوانیم استنباط کنیم که کیفیت وایفای طی پرواز هم از اهمیت بالایی برخوردار است.
درختهای تصمیم کاربرد زیادی در مسائل ردهبندی دارند، زیرا از مزایای متعددی برخوردارند از جمله:
- ذات تفسیرپذیر interpretable و قابل درکی comprehensible دارند که به استدلال آدمی شبیه است؛
- قابلیت کار با دادههای عددی numerical و دستهای categorial را دارند؛
- به صورت هرمی تجزیهپذیر Hierarchical decomposition هستند که باعث میشود از متغیرها استفاده بهتری داشته باشند.
اکثر الگوریتمهایی که به منظور ساخت یک درخت تصمیم به کار برده میشوند بر یک راهکار پارتیشنبندی بالا به پایین بازگشتی حریصانه A greedy top-down recursive partitioning strategy متکی هستند.
این دیتاستِ منبع که گره ریشهای درخت را مشخص میکند بر اساس قوانین خاصی به زیرمجموعهها (گرههای فرزند) تقسیم میشود. این فرآیند در هر زیرمجموعه نیز تکرار میشود تا زمانی که یا زیرمجموعه حاصل همه مقادیر متغیر هدف را داشته باشد و یا این تقسیم شدن دیگر ارزشی به پیشبینیها اضافه نکند.
معیارهایی که برای تعیین بهترین راه تولید آزمون در گرهها و شاخهها وجود دارند، برای هر الگوریتم متفاوت هستند. متداولترین معیارها کسب اطلاعات Information gain (یا آنتروپی) و ناخالصی جینی Gini impurity هستند. این دو مورد مربوط به اندازهگیری ناخالصی میباشند، بدین معنی که زمانی که همه نمونههای یک گره به یک رده تعلق داشته باشند، مقدار آنها برابر صفر است و وقتی یک توزیع یکسان A uniform class distribution داریم به حداکثر مقدار خود میرسند.
اما این استراتژی دو مشکل بزرگ دارد:
- ممکن است به راهکارهای زیربهینه ختم شود؛
- میتواند درختهایی با پیچیدگی بیش از حد تولید کند که قابلیت تعمیم از دادههای آموزشی به سایر دادهها را ندارند و در نتیجه منجر به مشکل بیشبرازش overfitting میشوند.
به منظور فائق آمدن بر این مشکلات چندین راهکار بیان شده است:
- تکنیک هرس pruning: ابتدا یک درخت تصمیم به صورت کامل ( یعنی تا زمانی که همه نمونههای یک برگ به یک رده تعلق داشته باشند) ساخته میشود. سپس با حذف گرهها یا درختچههای اضافی و غیرمعنیدار اندازه درخت را کاهش میدهیم.
- درختهای گروهی Ensemble trees: درختهای متفاوت ساخته میشوند و ردهبندی نهایی بر اساس قانونی خاص که در اغلب موارد یک طرح رأیگیری Voting scheme است انجام میگیرد. توجه داشته باشید که این تکنیک منجر به از دست رفتن فهمپذیری درختان تصمیم میشود.
با توجه به آنچه گفته شد دریافتیم لازم است گزینههای دیگر را هم برای تولید درختهای مدل بررسی کنیم. در همین راستا اخیراً الگوریتمهای تحولی (EAs) توجه زیادی را به خود جلب کردهاند.
این الگوریتمها به جای جستجوی محلی، یک جستجوی کلی در فضای راهکارهای داوطلب Candidate solutions انجام میدهند. در نتیجه نسبت به روشهای حریصانه بهتر میتوانند با درهمکنشهای ویژگیها Feature interactions کار کنند.
حال نحوه کار این الگوریتمها را با هم مشاهده میکنیم.
[irp posts=”14677″]2- چطور از الگوریتمهای تحولی برای ساخت یک درخت تصمیم استفاده کنیم؟
الگوریتمهای تحولی، الگوریتمهای اکتشافی Search heuristics محسوب میشوند و از مکانیزمهایی استفاده میکنند که الهامگرفته از تحول زیستی در طبیعت هستند.
در این پارادایم هر فرد individual یا هر جمعیت نشاندهنده یک راهکار داوطلب برای یک مسئله خاص است. هر فرد توسط یک مقدار شایستگی Fitness value ارزیابی میشود (مقدار تناسب کیفیت فرد را به عنوان یک راهکار میسنجد). بنابراین اولین جمعیت معمولاً به صورت اتفاقی تعریف شده و سپس در جهت نواحی بهتری از فضا تحول مییابد.
فرآیند انتخاب در هر نسل اطمینان حاصل میکند که احتمال تولید مثل بهترین افراد با مقدار تناسب پایین بیشتر باشد.
علاوه بر این، جمعیت نیز خود دستخوش فرآیندهای خاصی میشود که الهامگرفته از ژنتیک هستند؛ همچون:
- تقاطع crossover و جهش mutation یا مکانیزمهای از ترکیب recombination: اطلاعات دو فرد با هم ترکیب شده و به فرزندانشان offspring منتقل میشود.
- جهش: تغییرات کوچک و اتفاقی روی افراد اعمال میشود.
این فرآیند تا زمانی که معیار توقف Stopping criterion برآورده شود تکرار میگردد. سپس مناسبترین فرد به عنوان راهکار انتخاب میشود.

درختهای تصمیم مبتنی بر الگوریتمهای تحولی جایگزین خوبی برای تکنیکهای متداول کنونی به شمار میروند؛ زیرا:
- به عنوان تکنیکهای جستجو تصادفی Randomized search techniques میتوانند از مینیموم (کمینه) محلی
Local minima (که راهبرد پارتیشنبندی بالا به پایین حریصانه بازگشتی ایجاد میکنند) دوری کنند؛ - قابلیت درک درختان تصمیم نقطه مقابل روشهای گردآوری Ensemble methods است؛
- به جای بهینهسازی تنها یک معیار، میتوانند چندین هدف گردآوری شده را در مقدار تناسب به کار ببرند.

2.1. جمعیت اولیه
در بحث درختان تصمیم تحولی، درخت را به منزله فرد (در تحول طبیعی) در نظر میگیریم. اولین جمعیت از درختهایی تشکیل شده که به صورت تصادفی تولید شدهاند.
درختهای تصادفی بدین طریق تولید میشوند:
الگوریتم از یک گره ریشهای و دو فرزند شروع کرده و سپس تصمیم میگیرد این فرزندان هم شاخه شاخه شوند یا اینکه گره، گره نهایی (برگ) با میزان احتمال از پیشتعیین شده p باشد.
- اگر فرزندان تقسیم (یا شاخهشاخه) شوند، الگوریتم به صورت تصادفی ویژگیها را انتخاب کرده و مقادیر را تقسیم میکند.
- اگر گره، گره نهایی (برگ) باشد، یک برچسب رده به صورت تصادفی اختصاص داده میشود.
2.2. معیار برازش
هدف ردهبند، دست یافتن به بالاترین صحت پیشبینی دادههای بدون برچسب است. ردهبندهای درختهای تصمیم باید اندازه درخت نهایی را نیز کنترل کنند، زیرا درخت کوچک میتواند منجر به کمبرازشی underfitting و درخت پیچیده منجر به بیشبرازشی شود.
بدین ترتیب میتوان یک تابع برازش Fitness function تعریف کرد که بین این دو معیار (صحت پیشبینی و اندازه درخت) تعادل ایجاد میکند:
Fitness = α1 f1 + α2 f2
در این معادله:
- f1 میزان صحت مجموعه آموزشی است؛
- f2 اندازه فرد را از نظر عمق درخت جریمه میکند؛
- α1 و α2 پارامترهایی انتخابی هستند.
2.3. انتخاب
برای انتخابِ والدینی که قرار است نسل بعدی را به وجود آورند، چندین راهکار وجود دارد که رایجترین آنها عبارتند از:
- انتخاب بر اساس تابع برازش Fitness proportionate selection یا انتخاب بر اساس چرخ رولت Roulette wheel selection: از میزان شایستگی هر فرد در مقایسه با جمعیت استفاده میکنیم تا احتمال انتخاب را مشخص نماییم.
- انتخاب بر اساس تورنمنت Tournament selection: از میان نمونهای تصادفی از جمعیت، افرادی که بالاترین مقدار تناسب را دارند به عنوان والد انتخاب میکنیم.
- الیتیسم elitism: افرادی که بالاترین مقادیر تناسب را دارند مستقیماً به نسل بعدی منتقل میشوند. این روش اطمینان حاصل میکند که موفقترین افراد در مدل باقی بمانند.
توجه داشته باشید که یک فرد میتواند چندین بار انتخاب شود و بدین ترتیب قادر باشد ژن خود را به فرزندانش منتقل کند.
2.4. تقاطع
فرزندانی که از طریق فرآیند تقاطع به وجود میآیند، حاصل ترکیب جفت والدین هستند.
ابتدا دو فرد به عنوان والد انتخاب میشوند. سپس یک گره تصادفی در هر دو درخت (فرد) انتخاب میشود. فرد جدید (فرزند) با جانشینی درختچه (شاخههای درخت از گره انتخاب شده به پایین) والد اول توسط درختچه والد دوم تولید خواهد شد.

2.5. جهش
جهش به انتخابهای کوچک و تصادفی در افراد یک جمعیت اشاره دارد. جهش برای کسب اطمینان از وجود تنوع ژنتیکی در جمعیت ضروری است و بدین ترتیب الگوریتم ژنتیکی را قادر میسازد فضای گستردهتری را جستجو کند.
جهش در بحث درختهای تصمیم میتواند از طریق اعمال تغییرات کوچک و تصادفی روی خصیصهها و تقسیم مقدار گره تصادفی صورت گیرد.
2.6. معیار توقف
الگوریتم بدین صورت طراحی شده که اگر مقدار تناسب بهترین فرد در جمعیت طی تعداد مشخصی تکرار بهبود نیابد، همگرا شود.
به منظور محدودسازی زمان محاسبه در صورت کند بودن همگرایی، حداکثر تعداد نسلهای ممکن از پیش تعیین میشود.
[irp posts=”7626″]3-عملکرد درختهای تصمیم تحولی در مقایسه با سایر ردهبندها چگونه است؟
درختهای تصمیم تحولی بسیار رضایتبخش به نظر میرسند. اما عملکرد آنها در مقایسه با الگوریتمهای معمول یادگیری ماشین چگونه است؟
3.1. یک آزمایش ساده
برای اینکه از کارآیی این الگوریتم شناخت بهتری به دست آید، روی یک دیتاست آموزش داده و پیادهسازی شده است (دادههای حاصل از نظرسنجی رضایت مسافران از یک شرکت هواپیمایی).
هدف تشخیص عواملی بود که به رضایت بالاتر مشتریان میانجامند. بدین منظور نیاز است یک مدل ساده اما قوی داشته باشیم که مسیر رسیدن به رضایت مشتریان را به خوبی توجیه میکند.

دیتاست استفاده شده بزرگ بود و بیش از 100 هزار خط داشت. آنچه باید در مورد دیتاست بدانید:
- اطلاعات حقیقی در مورد مسافران و سفر آنها را در برمیگرفت: جنسیت و سن مسافر، نوع مسافر (وفادار/همیشگی یا خیر)، نوع سفر (شخصی یا کاری)، رده پرواز (بیزینس کلاس، اکو، اکو پلاس) و مسافت پرواز.
- شامل سطح رضایت مسافران از این خدمات میشد: خدمات وایفای درون پرواز، زمان پرواز از مبدأ و رسیدن به مقصد، آسانی رزرو آنلاین، موقعیت گیت، پذیرایی، بوردینگ آنلاین، راحتی صندلیها، سرگرمی طول پرواز، خدمات حین پرواز، امکانات مربوط به جای پا جلوی صندلی، بار و بستهبندی، خدمات سوار شدن و تمیزی.
متغیر هدف سطح رضایت مشتریان است که به صورت «راضی» و «ناراضی یا خنثی» مشخص میشود.
روششناسی
در این قسمت خلاصهای از گامهایی که طی شد را مشاهده میکنید:
- پیش-پردازش Pre-processing دادهها: تبدیل متغیرهای دستهای Categorial variables به متغیرهای نشانگر Indicator variables. تقسیم دادههای دیتاست به زیرمجموعههای آموزشی و آزمایشی.
- مدلسازی و آزمون: آموزش مدلهای مدنظر با استفاده از زیرمجموعه آموزشی و اندازهگیری مدلها با استفاده از زیرمجموعه آزمایشی (اعتباریابی).
- مقایسه عملکرد مدلها.
رویکرد درخت تصمیم تحولی (EDT) تنها با مدلهای درخت-محور Tree-based (درخت تصمیم یا DT و جنگل تصادفی Random forest یا RF) و با محدودیت لایهای 3، مقایسه شد. همچنین اندازه جمعیت EDT و تعداد برآوردکنندههای estimator RF روی 10 تنظیم شدند تا مقایسهای پایا از زمان محاسباتی آنها انجام شود.
یافتهها
یافتههای این آزمایش را میتوانید در این نمودار ببینید.




در این شرایط، عملکرد EDT به دو الگوریتم دیگر یادگیری ماشین بسیار نزدیک بود.
با اینحال مدل EDT یک مزیت برجسته دارد و آن ارائه یک درخت تصمیم واحد است:
- این یک درخت برخلاف مدل RF که در آن چندین درخت تصمیم جمع میشوند، میتواند مصورسازی گردد.
- این درخت بر خلاف درخت مدل DT قوی و پربار است. زیرا در این روش بهترین درخت از میان جمعیت انتخاب میشود.
در قسمت پایین بهترین درخت تصمیم انتخاب شده از بین جمعیت EDT به نمایش گذاشته شده است، در شرایطی که الگوریتم با حداکثر عمق (لایه) 2 آموزش دیده است.

3.2.یک اعتباریابی تجربی و عمومیتر از رویکرد EDT
بدیهی است آزمایشاتی که پیشتر شرح دادیم برای ارزیابی عملکرد و پایایی درختهای تصمیم تحولی در مقایسه با الگوریتمهای دیگر یادگیری ماشین کافی نیست.
از آنجایی که در این آزمایش تنها از یک دیتاست استفاده شده، نمیتوان همه احتمالات (همچون اثر تعداد ردههای متغیر هدف، یا اثر تعداد ویژگیها و مشاهدات یا موارد دیگر) را در نظر گرفت.
در دومین مقالهای که در قسمت منابع میبینید، نویسندگان با استفاده از دیتاستهای حقیقی UCI عملکرد یک رویکرد EDT را با روشهای دیگر یادگیری ماشین مقایسه کردند.
دیتاست این مقاله
جدول زیر به صورت خلاصه دیتاست را توصیف میکند:

همانطور که میبینید دیتاستها از نظر تعداد مشاهدات، ویژگیها و ردههای هدف تفاوت چشمگیری با هم دارند.
دشوارترین دیتاست اولین مورد است، زیرا تعداد ردههای بیشتر و تعداد مشاهدات محدودتری دارد.
روششناسی
در این قسمت با روش پژوهشی نویسندگان (به منظور مقایسه عملکرد EDT با الگوریتمهای کلاسیک یادگیری ماشینی) بیشتر آشنا خواهید شد:
- مدل EDT با این ابرپارامترها Hyperparameter آموزش دیده شده است: تعداد نسلهای 500، اندازه جمعیت 400، احتمال تقاطع/ جهش 6/0.4، و روش انتخاب تصادفی با رویکرد الیتیسم.
- عملکرد مدلها با استفاده از اعتباریابی متقاطع Cross-validation 5×2 اندازهگیری شد.
یافتهها

همانطور که نویسندگان بیان کردهاند از جدول بالا دو نکته کلیدی میتوان استنباط کرد:
- در تقریباً تمامی موارد عملکرد الگوریتمهای درخت-محور از عملکرد الگوریتمهای دیگر یادگیری ماشینی بهتر است. این یافته را میتوان اینطور توجیه کرد که درختهای تصمیم ذاتاً توانایی بیشتری در انتخاب مهمترین ویژگیها دارند. علاوه بر این مدلهای قانون-محور Rule-based models با دیتاستهای خاص تطابق بیشتری دارند، به ویژه زمانی که مدلسازی رابطه بین هدف و ویژگی کار دشواری است.
- نتایج به دست آمده در دیتاست abalone ضعیف هستند. زیرا متغیر هدف 28 رده و در عین حال مشاهدات بسیار کمی (تنها 210) دارد. با اینحال، مدل EDT بالاترین صحت را در این دیتاست به دست آورده است که خود حاکی از توانایی آن در کار با دیتاستهای دشوار و پرهیز از بیشتطبیقی است.
توجه داشته باشید که نتایج EDT با پارامترهای پیشفرض به دست آمدهاند. با سازگار کردن پارامترها عملکرد بهتری هم امکانپذیر بود.





