
بردار کلمات و راهنمای استفاده از آن با gensim و keras
 تیم تحریریه
تیم تحریریه- ۲۰ شهریور ۱۴۰۱
در نوشتار حاضر با انواع بردار کلمات، نحوهی ایجاد آنها در پایتون و بکارگیریشان به همراه شبکههای عصبی در keras آشنا خواهید شد. روشهای پردازش زبان طبیعی برای مدتی طولانی از مدل vectorspace برای نمایش کلمات استفاده میکردند. بردارهای رمزگذاریشدهی وان-هات به طور متداول به کار برده میشوند. البته روش «سبد واژگان» نیز عملکرد بسیار موفقی در بسیاری از امور داشته است. به تازگی، روشهای جدیدی برای نمایش کلمات در vectorspace پیشنهاد شده و شاهد ارتقای عملکرد چشمگیری در بسیاری از امور پردازش زبان طبیعی بودهایم. جزئیات این روشها به همراه چگونگی ساخت بردارها در پایتون در نوشتار حاضر توضیح داده خواهد شد.
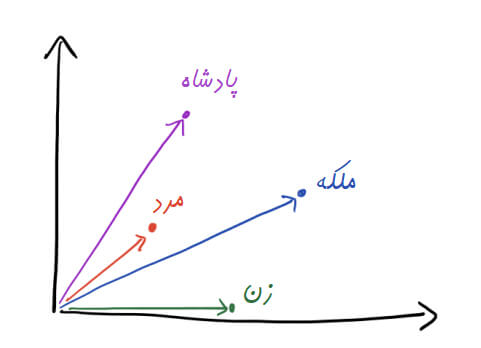
سبد واژگان پیوسته
مفهوم اصلی این ابزار در فرضیه توزیع نهفته است که بیان میدارد: «معنای کلمه از واژههای کناریِ آن قابل استنباط است.» از این رو، سبد واژگان پیوسته قصد دارد از بافت کلمات برای پیشبینی احتمال بکارگیری کلمات استفاده کند.
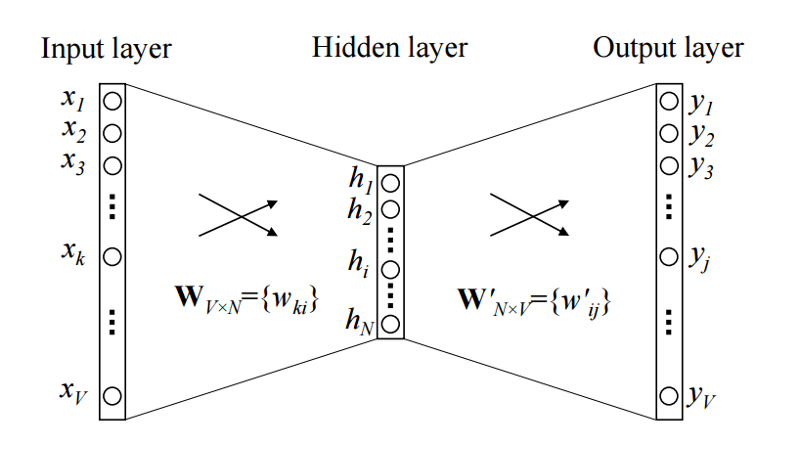
تصویر فوق، مدل CBOW سادهای با یک کلمه نشان میدهد. پس، ورودی عبارت است از واژه بافت رمزگذاری شده وانهات و اندازه پنهان NN و اندازه کلمه VV. پس از اینکه این شبکه کوچک آموزش دید، ستونهای W^\primeW′ میتواند بردار NN بُعدی را برای همه کلمات نشان دهد. بردار کلمات به این طریق به کار برده میشود.
هدف ساختن بردار برای یک کلمه هم همین است که نشان دهیم یک کلمه از نظر معنایی چقدر و از چه ابعادی به دیگر کلمات شبیه است. با همین ایدهی ساده میتوانید بردارهای کلمهی خودتان را بسازید. به عنوان مثال میتوانید برای هر کلمهی منحصربهفرد متن را جستجو کنید و مثلا دو کلمه قبل و دو کلمه بعدش را ثبت کرده و نهایتا برای کلماتتان یک جدول همرخداد بسازید.
بارگذاری دیتاست
دیتاست ما از دوره مسابقات «Toxic Comment Classification Challenge» به دست آمده است. در این مسابقات افراد موظفاند مدل چندجانبهای بسازند که قادر به شناسایی انواع مختلفی از مسائل مثل تهدیدها، توهینها، نفرت هویتی و محتوای نامناسب باشد. در ابتدا به پیشپردازشِ کامنتها و آموزش بردار کلمات میپردازیم. سپس، لایه تعبیهگذاری keras را با بردار کلماتِ از پیش آموزشیافته به اجرا در آورده و عملکرد آن را با فرایند تعبیه تصادفی مقایسه میکنیم. شبکه حافظه بلند کوتاهمدت نیز در این راستا به کار برده میشود.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.style.use("ggplot")
path = 'data/' TRAIN_DATA_FILE = path + 'train.csv' TEST_DATA_FILE = path + 'test.csv'
train_df = pd.read_csv(TRAIN_DATA_FILE) test_df = pd.read_csv(TEST_DATA_FILE)
train_df.head(10)

پیشپردازش متن
حال، نوبت به پردازش کامنتها رسیده است. برای انجام این کار، “URL”را جایگزین URLها و “IPADDRESS” را جایگزین آدرسهای IP میکنیم. سپس، متن را توکن بندی کرده و با حروف کوچک مینویسیم.
########################################
## process texts in datasets
########################################
print('Processing text dataset')
from nltk.tokenize import WordPunctTokenizer
from collections import Counter
from string import punctuation, ascii_lowercase
import regex as re
from tqdm import tqdm
# replace urls
re_url = re.compile(r"((http|https)\:\/\/)?[a-zA-Z0-9\.\/\?\:@\-_=#]+\
.([a-zA-Z]){2,6}([a-zA-Z0-9\.\&\/\?\:@\-_=#])*",
re.MULTILINE|re.UNICODE)
# replace ips
re_ip = re.compile("\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}")
# setup tokenizer
tokenizer = WordPunctTokenizer()
vocab = Counter()
def text_to_wordlist(text, lower=False):
# replace URLs
text = re_url.sub("URL", text)
# replace IPs
text = re_ip.sub("IPADDRESS", text)
# Tokenize
text = tokenizer.tokenize(text)
# optional: lower case
if lower:
text = [t.lower() for t in text]
# Return a list of words
vocab.update(text)
return text
def process_comments(list_sentences, lower=False):
comments = []
for text in tqdm(list_sentences):
txt = text_to_wordlist(text, lower=lower)
comments.append(txt)
return comments
list_sentences_train = list(train_df["comment_text"].fillna("NAN_WORD").values)
list_sentences_test = list(test_df["comment_text"].fillna("NAN_WORD").values)
comments = process_comments(list_sentences_train + list_sentences_test, lower=True)
پردازش دیتاست متن 100%|██████████| 312735/312735 [00:17<00:00, 18030.28it/s]
print("The vocabulary contains {} unique tokens".format(len(vocab)))
مدلسازیِ بردار کلمات با Gensim
اکنون، آمادهی آموزش بردار کلمات هستیم. کتابخانهی genism در پایتون مورد استفاده قرار میگیرد که از دستههای مختلفی برای امور پردازش زبان طبیعی پشتیبانی میکند.
from gensim.models import Word2Vec
model = Word2Vec(comments, size=100, window=5, min_count=5, workers=16, sg=0, negative=5)
word_vectors = model.wv
print("Number of word vectors: {}".format(len(word_vectors.vocab)))
تعداد بردار کلمات: 70056
اجازه دهید بینیم آیا بردار کلماتی که به لحاظ معنایی منطقی باشند، آموزش دادهایم؟
model.wv.most_similar_cosmul(positive=['woman', 'king'], negative=['man'])
[('prince', 0.9849334359169006),
('queen', 0.9684107899665833),
('princess', 0.9518582820892334),
('bishop', 0.9380313158035278),
('duke', 0.9368391633033752),
('duchess', 0.9353090524673462),
('victoria', 0.920809805393219),
('mary', 0.9180552363395691),
('mayor', 0.912704348564148),
('prussia', 0.9100297093391418)]
خب، شرایط تا بدین جای کار خوب به نظر میرسد. اکنون، میتوان سراغ مدل طبقهبندی متن بعدی رفت.
تعبیهگذاری در keras
در ابتدا، باید کامنتهای توکن بندی شده را با طول معینی برش یا pad بدهیم.
MAX_NB_WORDS = len(word_vectors.vocab) MAX_SEQUENCE_LENGTH = 200
from keras.preprocessing.sequence import pad_sequences
word_index = {t[0]: i+1 for i,t in enumerate(vocab.most_common(MAX_NB_WORDS))}
sequences = [[word_index.get(t, 0) for t in comment]
for comment in comments[:len(list_sentences_train)]]
test_sequences = [[word_index.get(t, 0) for t in comment]
for comment in comments[len(list_sentences_train):]]
# pad
data = pad_sequences(sequences, maxlen=MAX_SEQUENCE_LENGTH,
padding="pre", truncating="post")
list_classes = ["toxic", "severe_toxic", "obscene", "threat", "insult", "identity_hate"]
y = train_df[list_classes].values
print('Shape of data tensor:', data.shape)
print('Shape of label tensor:', y.shape)
test_data = pad_sequences(test_sequences, maxlen=MAX_SEQUENCE_LENGTH, padding="pre",
truncating="post")
print('Shape of test_data tensor:', test_data.shape)
Using TensorFlow backend. Shape of data tensor: (159571, 200) Shape of label tensor: (159571, 6) Shape of test_data tensor: (153164, 200)
حالا، سرانجام ماتریس تعبیه را ایجاد میکنیم. این ماتریس در اختیار لایه تعبیه keras قرار خواهد گرفت. میتوانید از همان کد برای اجرای فرایند تعبیه با Glove یا سایر بردار کلماتِ از پیش آموزش دیده استفاده کنید.
WV_DIM = 100
nb_words = min(MAX_NB_WORDS, len(word_vectors.vocab))
# we initialize the matrix with random numbers
wv_matrix = (np.random.rand(nb_words, WV_DIM) - 0.5) / 5.0
for word, i in word_index.items():
if i >= MAX_NB_WORDS:
continue
try:
embedding_vector = word_vectors[word]
# words not found in embedding index will be all-zeros.
wv_matrix[i] = embedding_vector
except:
pass
تنظیم رده بندی برای دادگان کامنت
from keras.layers import Dense, Input, CuDNNLSTM, Embedding, Dropout,SpatialDropout1D, Bidirectional from keras.models import Model from keras.optimizers import Adam from keras.layers.normalization import BatchNormalization
باید از شبکه حافظه بلند کوتاهمدت با دراپاوت و نرمالسازی دستهای استفاده کرد. توجه داشته باشید که keras با روش CUDA به اجرا در میآید که سریعتر از حالت معمول در GPU اجرا میشود.
wv_layer = Embedding(nb_words,
WV_DIM,
mask_zero=False,
weights=[wv_matrix],
input_length=MAX_SEQUENCE_LENGTH,
trainable=False)
# Inputs
comment_input = Input(shape=(MAX_SEQUENCE_LENGTH,), dtype='int32')
embedded_sequences = wv_layer(comment_input)
# biGRU
embedded_sequences = SpatialDropout1D(0.2)(embedded_sequences)
x = Bidirectional(CuDNNLSTM(64, return_sequences=False))(embedded_sequences)
# Output
x = Dropout(0.2)(x)
x = BatchNormalization()(x)
preds = Dense(6, activation='sigmoid')(x)
# build the model
model = Model(inputs=[comment_input], outputs=preds)
model.compile(loss='binary_crossentropy',
optimizer=Adam(lr=0.001, clipnorm=.25, beta_1=0.7, beta_2=0.99),
metrics=[])
hist = model.fit([data], y, validation_split=0.1,
epochs=10, batch_size=256, shuffle=True)
Train on 143613 samples, validate on 15958 samples Epoch 1/10 143613/143613 [==============================] - 15s 103us/step - loss: 0.1681 - val_loss: 0.0551 Epoch 2/10 143613/143613 [==============================] - 14s 97us/step - loss: 0.0574 - val_loss: 0.0502 Epoch 3/10 143613/143613 [==============================] - 14s 97us/step - loss: 0.0522 - val_loss: 0.0486 Epoch 4/10 143613/143613 [==============================] - 14s 96us/step - loss: 0.0501 - val_loss: 0.0466 Epoch 5/10 143613/143613 [==============================] - 14s 97us/step - loss: 0.0472 - val_loss: 0.0464 Epoch 6/10 143613/143613 [==============================] - 14s 97us/step - loss: 0.0460 - val_loss: 0.0448 Epoch 7/10 143613/143613 [==============================] - 14s 97us/step - loss: 0.0448 - val_loss: 0.0448 Epoch 8/10 143613/143613 [==============================] - 14s 97us/step - loss: 0.0438 - val_loss: 0.0453 Epoch 9/10 143613/143613 [==============================] - 14s 98us/step - loss: 0.0431 - val_loss: 0.0446 Epoch 10/10 143613/143613 [==============================] - 14s 97us/step - loss: 0.0425 - val_loss: 0.0454
حال نوبت به مقایسه زیان آموزش و زیان اعتبارسنجی رسیده است.
history = pd.DataFrame(hist.history)
plt.figure(figsize=(12,12));
plt.plot(history["loss"]);
plt.plot(history["val_loss"]);
plt.title("Loss with pretrained word vectors");
plt.show();

به نظر میرسد زیان رو به کاهش است، اما کماکان میتوان به عملکردی بهتر از این دست یافت. میتوانید به طور دلخواه از روشهای تعبیه، دراپ اوت و معماری شبکه استفاده کنید. اکنون، قصد داریم بردار کلماتِ از پیش آموزش دیده را با تعبیههای تصادفی مقایسه کنیم.
wv_layer = Embedding(nb_words,
WV_DIM,
mask_zero=False,
# weights=[wv_matrix],
input_length=MAX_SEQUENCE_LENGTH,
trainable=False)
# Inputs
comment_input = Input(shape=(MAX_SEQUENCE_LENGTH,), dtype='int32')
embedded_sequences = wv_layer(comment_input)
# biGRU
embedded_sequences = SpatialDropout1D(0.2)(embedded_sequences)
x = Bidirectional(CuDNNLSTM(64, return_sequences=False))(embedded_sequences)
# Output
x = Dropout(0.2)(x)
x = BatchNormalization()(x)
preds = Dense(6, activation='sigmoid')(x)
# build the model
model = Model(inputs=[comment_input], outputs=preds)
model.compile(loss='binary_crossentropy',
optimizer=Adam(lr=0.001, clipnorm=.25, beta_1=0.7, beta_2=0.99),
metrics=[])
hist = model.fit([data], y, validation_split=0.1,
epochs=10, batch_size=256, shuffle=True)
Train on 143613 samples, validate on 15958 samples Epoch 1/10 143613/143613 [==============================] - 14s 99us/step - loss: 0.1800 - val_loss: 0.1085 Epoch 2/10 143613/143613 [==============================] - 14s 97us/step - loss: 0.1117 - val_loss: 0.1063 Epoch 3/10 143613/143613 [==============================] - 14s 98us/step - loss: 0.1063 - val_loss: 0.0990 Epoch 4/10 143613/143613 [==============================] - 14s 97us/step - loss: 0.0993 - val_loss: 0.1131 Epoch 5/10 143613/143613 [==============================] - 14s 98us/step - loss: 0.0951 - val_loss: 0.0999 Epoch 6/10 143613/143613 [==============================] - 14s 97us/step - loss: 0.0922 - val_loss: 0.0907 Epoch 7/10 143613/143613 [==============================] - 14s 98us/step - loss: 0.0902 - val_loss: 0.0867 Epoch 8/10 143613/143613 [==============================] - 14s 97us/step - loss: 0.0868 - val_loss: 0.0850 Epoch 9/10 143613/143613 [==============================] - 14s 97us/step - loss: 0.0838 - val_loss: 0.1060 Epoch 10/10 143613/143613 [==============================] - 14s 97us/step - loss: 0.0821 - val_loss: 0.0860
history = pd.DataFrame(hist.history)
plt.figure(figsize=(12,12));
plt.plot(history["loss"]);
plt.plot(history["val_loss"]);
plt.title("Loss with random word vectors");
plt.show();

آنطور که ملاحظه میکنید، زیان به کُندی در حال کاهش است و زیان اعتبارسنجی پایداری کافی را ندارد.





