
روش ساده ساخت سیستم توصیه گر
 تیم تحریریه
تیم تحریریه- ۳۰ شهریور ۱۴۰۱
برای اینکه به قدرت سیستم توصیه گر Recommendation System پی ببرید، کافی است به سرویس رسانهایِ «نِتفیلیکس» توجه کنید؛ سیستم توصیه گر نوین این شرکت، برای چندین ساعت ما را پای تلویزیون میخکوب میکنند.
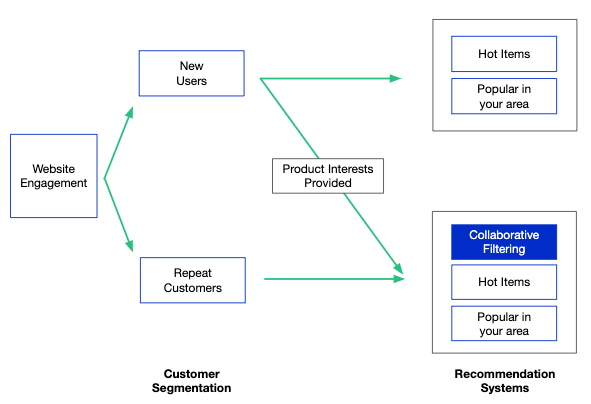
ساخت سیستمهای توصیه گر
با این حال، اکنون طیف وسیعی از توصیهگرها وجود دارند و در بخشهای گوناگونی به ایفای نقش میپردازند؛ از جمله آنها میتوان به فروش سراسریِ محصولات، شناسایی کارکنانی که از سطح مهارتی مشابهی برخوردارند و یافتن مشتریانی که به پیامهای تبلیغاتی پاسخ میدهند، اشاره کرد. این مثالها تنها گوشه بسیار ناچیزی از کاربرد سیستم توصیه گر است.
اگرچه توصیهگرها میتوانند پیچیدگی بالایی داشته باشند، اما دو روش ساده وجود دارد که مثل نقطه شروع عمل میکنند:
- فیلترینگ محتوامحور Content based filtering :
از ویژگی اجناس برای توصیۀ اجناس مشابهی که کاربران قبلی از آنها ابراز رضایت کردهاند، استفاده میکند. پروژه ژنوم موسیقی پاندورا به شناسایی ویژگیهای موسیقیاییِ هر قطعه آهنگ پرداخته و از آن اطلاعات برای یافتن آهنگهای مشابه و توصیه به شنوندگان استفاده میکند.
- فیلترینگ همکاریمحور Collaborative filtering :
بر اساس اینکه کاربران مشابه چه امتیازی به اجناس یا اقلام دادهاند، آنها را شناسایی میکند. شرکت نتفیلیکس با شناساییِ اینکه کاربران مشابه چه محتوایی را تماشا کردهاند، به این نتیجه میرسد که کابران از تماشای کدام برنامهها و فیلمها لذت خواهند برد.
شروع کار
باید از «Surprise» (بسته scikit پایتون) برای ساخت سیستم توصیه گر استفاده و در گام نخست از یک مجموعهداده استفاده کنیم. این دیتاست از هشت جدول تشکیل شده است. این جداول قبلا به یکدیگر الحاق شده و ستون های مورد نیاز تفکیک تفکیک شده اند. کُد کامل به صورت زیر است:
#Import packages
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from surprise import NormalPredictor, Reader, Dataset, accuracy,
SVD, SVDpp, KNNBasic, CoClustering, SlopeOne
from surprise.model_selection import cross_validate, KFold,
GridSearchCV, train_test_split
#import dataset
olist_data = pd.read_csv('olist_data.csv')
این دیتاست کاملاً به منظور ساخت سیستم توصیه گر طراحی نشده است. چالش پیش رویمان این است که تقریباً 90 درصد کاربران را مشتریانی تشکیل میدهند که برای نخستین بار با این رویه مواجه میشوند. یعنی جدول امتیازدهی مشتریان قبلی وجود ندارد تا کالاهای مدنظرشان را پیدا کنند. در همین راستا، ما مجموعهداده را به دو بخشِ کاربران تکراری و کاربران بار اوّلی تقسیم میکنیم. کاربران تکراری فقط در مدل فیلترینگ همکاریمحور گنجانده میشوند. مشتریان بار اوّلی کماکان میتوانند از توصیههای ما بهرهمند شوند، اما تمرکز عمده آنها روی محبوبیت کالاها و موقعیت کاربر معطوف خواهد بود.
def repeat_and_first_time(data):
repeaters = data.groupby('customer_unique_id').filter(lambda x:
len(x) > 1)
first_timers = data.groupby('customer_unique_id').filter(lambda x:
len(x) == 1)
return repeaters, first_timers
استفاده از بستۀ «Surprise»
برای استفاده از تبدیل ماتریس امتیازدهی کاربران user-ratings matrix در بستۀ «Surprise» باید دیتافریمی را به کار بریم که حاوی سه ستون شامل شماره شناسایی کاربران، شماره شناسایی کالا و امتیازدهی باشد.
def create_user_ratings_df(data):
df=data.groupby(['customer_unique_id','product_id'])
['review_score'].agg(['mean']).reset_index()
df = df.rename({'mean':'estimator', 'product_id':'productId'},
axis=1)
return df
user_ratings_df = create_user_ratings_df(repeater_data)
user_ratings_df.head()
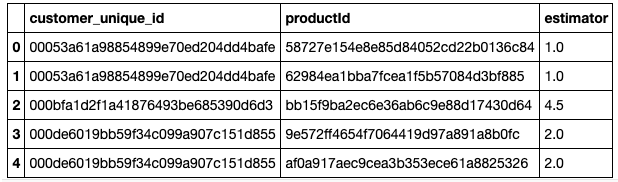
ابزار Surprise کمک میکند تا یک ماتریس امتیازهی کاربر بسازیم. در این ماتریس، شناسه کاربران در یک ردیف قرار میگیرد و محصولات عرضه شده از طرف شرکت در ستونی دیگر. این کار تاثیرگذاریِ یکسانی با ساخت جدول محوری «Pandas» خواهد داشت. این دیتافریم با نسبت 80/20 به مجموعه آزمایش و آموزش تقسیم خواهد شد.
def surprise_df(data):
scale = (data.estimator.min(), data.estimator.max())
reader = Reader(rating_scale=scale)
df = Dataset.load_from_df(data[['customer_unique_id',
'productId',
'estimator']], reader)
return df
user_ratings_matrix=surprise_df(user_ratings_df)
train_set,test_set=train_test_split(user_ratings_matrix,
test_size=0.2, random_state=19)
ابزار Surprise یازده الگوریتم پیشبینی عرضه میکند که چند نوع الگوریتم KNN و روشهای کاهش ابعاد از قبیل SVD و NMF نیز در میان آنها وجود دارند. برای نشان دادن نحوه عمکرد یک توصیه گر، چند نمونه از الگوریتم های فوق مورد استفاده قرار گرفته و توسط اعتبار سنجی 5 تکه با یکدیگر مقایسه شده اند. این الگوریتم ها عبارتند از:
- NormalPredictor: این مدل مبنا، بر اساس توزیع مجموعه آموزش به پیشبینیِ امتیاز تصادفی میپردازد. مفروض است که این مجموعه دارای توزیع نرمال است.
- SVD: این روش فاکتورگیری ماتریس، محبوبیت خود را مرهون «سایمون فانک» است.
- KNNBasic: این روش از شباهت سینوسی برای انجام KNN استفاده میکند.
- CoClustering: این الگوریتم مشابه روش k-means، نقاط را به خوشهها تخصیص میدهد.
دو روش برای ارزیابی عملکرد مدل وجود دارد. از دیدگاه کِیفی، میتوان کاربری به صورت تصادفی انتخاب کرد و دید که آیا توصیهها با توجه به محصولات دیگری که دوست دارند، منطقی است یا خیر. برای مثال، اگر کسی به تماشای فیلمهای ترسناک علاقه دارد و علاقهای به ژانر کمدی عاشقانه نشان نمیدهد، فیلم «The Shining» نسبت به «Love Actually» توصیه بهتری است.
ما در این مجموعهداده هیچ اطلاعاتی درباره هر یک از محصولات نداریم. لذا مجبور به استفاده از یک معیار کمی (مجذور میانگین مربعات خطا (Root Mean Square Error (RMSE یا rmse هستیم. ترکیبی از این دو روش میتواند ایدهآل باشد، علیرغم اینکه معیار کمّی، واقعگرایانهتر است.
kf = KFold(n_splits=5, shuffle=True, random_state=19)def model_framework(train_data): #store the rmse values for each fold in the k-fold loop
normp_rmse, svd_rmse, knn_rmse, co_rmse, slope_rmse = [],[],[], [],[]
for trainset, testset in kf.split(train_data):
#baseline
normp = NormalPredictor()
normp.fit(trainset)
normp_pred = normp.test(testset)
normp_rmse.append(accuracy.rmse(normp_pred,verbose=False))
#svd
svd = SVD(n_factors=30, n_epochs=50,biased=True, lr_all=0.005, reg_all=0.4, verbose=False)
svd.fit(trainset)
svd_pred = svd.test(testset)
svd_rmse.append(accuracy.rmse(svd_pred,verbose=False))
#knn
knn = KNNBasic(k=40,sim_options={'name': 'cosine', 'user_based': False}, verbose=False)
knn.fit(trainset)
knn_pred = knn.test(testset)
knn_rmse.append(accuracy.rmse(knn_pred,verbose=False))
#co_clustering
co = CoClustering(n_cltr_u=3,n_cltr_i=3,n_epochs=20)
co.fit(trainset)
co_pred = co.test(testset)
co_rmse.append(accuracy.rmse(co_pred,verbose=False))
mean_rmses = [np.mean(normp_rmse),
np.mean(svd_rmse),
np.mean(knn_rmse),
np.mean(co_rmse),
np.mean(slope_rmse)]
model_names = ['baseline','svd','knn','coclustering','slopeone']
compare_df = pd.DataFrame(mean_rmses, columns=['RMSE'], index=model_names)
return compare_dfcomparison_df = model_framework(train_set)
comparison_df.head()

بر اساس کدهای فوق، SVD دارای پایینترین rmse است بنابراین مدل مورد نظرِ ما برای ادامۀ کار خواهد بود.
تنظیم مدل: جستجوی شبکۀ Surprise
بستۀ Surprise گزینهای برای تنظیم پارامترها با استفاده از GridSearchCV ارائه میکند. ما یک دیکشنری از پارامترها برای GridSearchCV در نظر گرفتهایم. rmse مورد محاسبه قرار گرفته و بر اساس آن هر ترکیب از پارامترها با یکدیگر مقایسه خواهند شد.
def gridsearch(data, model, param_grid):
param_grid = param_grid
gs = GridSearchCV(model, param_grid, measures=['rmse'], cv=5)
gs.fit(data)
new_params = gs.best_params['rmse']
best_score = gs.best_score['rmse']
print("Best score:", best_score)
print("Best params:", new_params)
return new_params, best_scoresvd_param_grid = {'n_factors': [25, 50,100],
'n_epochs': [20,30,50],
'lr_all': [0.002,0.005,0.01],
'reg_all':[0.02,0.1, 0.4]}
svd_params, svd_score = gridsearch(train_set, SVD, svd_param_grid)
From that search, we receive an output that tells us the best score (lowest rmse) obtained was 1.27 which was produced using the parameters {‘n_factors’: 25, ‘n_epochs’: 50, ‘lr_all’: 0.01, ‘reg_all’: 0.1}.
با توجه به این جستجو، یک خروجی دریافت کردیم که نشان میدهد بهترین امتیازِ بدستآمده (پایینترین rmse) برابر با 1.27 بود. این مقدار با استفاده از پارامترهای {‘n_factors’: 25, ‘n_epochs’: 50, ‘lr_all’: 0.01, ‘reg_all’: 0.1} به دست آمد.
متریک و مدل نهایی
با توجه با پارامترهای فوق، مدل را در مجموعه آموزشی کامل بدون استفاده از اعتبارسنجی متقابل cross validation اجرا کرده و دقّت آن را ثبت میکنیم.
def final_model(train_set, test_set):
params = {'n_factors': 10, 'n_epochs': 50, 'lr_all': 0.01,
'reg_all': 0.1}
svdpp = SVDpp(n_factors=params['n_factors'],
n_epochs=params['n_epochs'],
lr_all=params['lr_all'],
reg_all=params['reg_all'])
svdpp.fit(train_set)
predictions = svdpp.test(test_set)
rmse = accuracy.rmse(predictions,verbose=False)
return predictions, rmse
final_predictions, model_rmse = final_model(train_set, test_set)
ویژگی .test سبب تولید پیش بینی هایی نظیر، شناسه کاربر، شناسه آیتم، امتیاز واقعی کاربر، امتیاز تخمین زده شده توسط مدل و یک نشانگر که تعیین کننده امکان پیش بینی است میشود. علاوه بر بررسی خروجیِ model_rmse از مدل آموزشیافته و نهایی، توزیعِ خطاهای مطلق در کل پیشبینیها بررسی خواهد شد. برای انجام این کار، خروجیِ پیشبینیها را در یک دیتافریم قرار داده و ستونی را اضافه خواهیم کرد که خطای هر پیشبینی را نشان میدهد. امکان نشان دادن تصویریِ نتایج با ترسیم نموداری از خطاها نیز وجود دارد.
results = pd.DataFrame(final_predictions, columns=['userid', 'item_id', 'user_rating', 'model_est', 'details']) results['err'] = abs(results.model_est - results.user_rating)
در شکلهای زیر، اگرچه مقدار خطا در مجموعهداده برابر با 1.0 بود، اما وقتی کاربری به محصولی امتیازی بالای 3 داد، مدل پیشبینیهای بهتری انجام داد؛ بهطوریکه خطا به 0.8 کاهش یافت. در مقابل، وقتی کاربری به یک محصول امتیازی کمتر از 3 داد، خطا بالاتر از 1.5 بود. این نتیجه خوبی است و میتواند توصیههای خوبی در اختیار کاربران قرار دهد. پیشبینیِ دقیق برای ما حائز اهمیت است.

نکات پایانی
شما میتوانید از مجموعهدادههای Surprise برای آشناییِ بیشتر با این فرایند استفاده کنید و ویژگی های دیگری نظیر روشهای اعتبار سنجی متقابل، معیارهای شباهت و الگوریتم های پیش بینی را مورد بررسی قرار دهید
در حال حاضر، Surprise قادر به بررسی دقیق امتیازدهی تلویحی، انجام فیلترینگ محتوا یا ارائه توصیهگر ترکیبی نیست. با این حال، Surprise یک بسته ساده و مناسب برای افراد مبتدی است.





