
ساخت یک سیستم توصیه گر برای پیشنهاد فیلم به کمک گراف دانش و Neo4j
 تیم تحریریه
تیم تحریریه- ۳۰ بهمن ۱۴۰۰
زمانیکه به وبسایت نتفلیکس مراجعه میکنید با فهرستهای متعددی از فیلمها مواجه میشوید و میتوانید یکی از این فیلمها را انتخاب کنید و به تماشای آن بنشینید. در این وبسایت میتوانید فیلمهایی که به تازگی اکران شدهاند، فیلمهایی که نسبت به سایر فیلمها محبوبتر هستند و از همه جالبتر، فیلمهای برتر پیشنهادی به شما Top Picks for You را تماشا کنید. وبسایت نتفلیکس برای ایجاد این فهرستها از یک سیستم توصیه گر Recommendation systems قوی استفاده میکند. این سیستم توصیه گر بر مبنای فیلمهایی که تماشا کردهاید و فیلمهایی که به آنها امتیاز دادهاید، پروفایلی از ژانرها، طرح داستان، بازیگران و غیره ایجاد میکند و با در نظر گرفتن این پروفایل فیلمهایی به شما پیشنهاد میدهد که متناسب با سلقیه شما است.
پلتفرمهای بیشماری از جمله آمازون، نتفلیکس، فیسبوک و بسیاری دیگر از پلتفرمهای تجارت الکترونیک و ارائه خدمات از سیستمهای توصیه گر یا توصیهگرها استفاده میکنند. هدف از استفاده از این سیستمها ساده است: محصول/ فیلم/ فردی به کاربر معرفی و پیشنهاد شود که به احتمال زیاد کاربر آن را میخرد/ تماشا میکند/ و یا با آن رابطه دوستی برقرار میکند.
در مقاله پیشرو چگونگی ساخت یک سیستم توصیه گر با استفاده از Neo4j را توضیح خواهیم داد.
علیرغم اینکه نحوه عملکرد یک سیستم توصیه گر به نحوه عملکرد چندین زیرسیستم وابسته است که با یکدیگر در تعامل هستند (برای مثال خوشههای یادگیری ماشین Machin learning cluster که دادهها را آموزش میدهند و یا به صورت مستقیم دادهها را از دیتابیس مرکزی استخراج میکنند)، ما توصیهگرهایی پیادهسازی و اجرا خواهیم کرد که با بهرهگیری از قابلیتهای بیشمار گراف دانش، به صورت مستقیم در دیتابیس اجرا میشوند.
علاوه بر این نشان خواهیم داد که چگونه از این فناوری در ساخت MindReader استفاده کردهایم؛ MindReader یک سیستم توصیه گر است که با استفاده از فناوریهای گراف ( که در ادامه آن را توضیح خواهیم داد) این امکان را برای کاربران فراهم میکند که به صورت مشترک دیتاست بسازند که با تمامی دیتاستهای مورد استفاده در حیطه پژوهشی پیشنهاد شخصیسازی شده متفاوت است.
مروری بر سیستم توصیه گر
اگر طرفدار فیلمهای ترسناک هستید، وبسایت نتفلیکس با در نظر گرفتن سلیقه شما به جای پیشنهاد فیلمهای کمدی، انیمیشنهای کودکانه و غیره، فیلمهای ترسناک را به شما پیشنهاد میدهد. فارغ از اینکه هر فرد در چه حرفهای مشغول به فعالیت است، پیشنهاد فیلم بر اساس سلایق شخصی مورد پسند همگان است. اما مشکلی که در اینجا با آن مواجه هستیم این است که چگونه میتوانیم به نحوی مؤثر، کارآمد و آسان سلایق و ترجیحات کاربران را استنباط کنیم.
به طور کلی، برای انجام این کار میتوان از سه روش بهره جست: پالایش مشارکتی یا پالایش مبتنی بر محتوا، یا ترکیبی (دوگانه) از این دو.
[irp posts=”13592″]توصیهگر پالایش مشارکتی با استفاده از تعاملات کاربرانی همچون شما، سلایق هر فرد را استنباط میکند.
دو کاربر فرضی به نامهای مایک و درو را در نظر بگیرید که هر دو از طرفداران فیلمهای علمی تخیلی هستند و هر دو فیلم جنگ ستارگان را دوست دارند. فرض کنید مایک فیلم میانستارهای را هم دوست دارد اما درو حتی یک بار هم این فیلم را تماشا نکرده است. پیشنهاددهنده پالایش مشارکتی ، فیلم میانستارهای را به درو پیشنهاد میدهد، به این دلیل که مایک که سلیقهای مشابه درو در فیلم دارد، فیلم میانستارهای را دوست داشته است.
علاقه و عدم علاقه دو کاربر به مجموعه خاصی از موضوعات میتواند به نحوی کارآمد سلایق و ترجیحات کاملاً پیچیده را مشخص کند؛ در این حالت نگرانی راجع به اینکه این سلایق و ترجیحات چه هستند معنایی ندارد و به همین دلیل است که پالایش مشارکتی، یک استراتژی سودمند و کارآمد به شمار میآید.
از سوی دیگر، توصیهگرهای پالایش مبتنی بر محتوا، با در نظر گرفتن محتوای دو فیلم تعیین میکنند که آیا میتوان تشابهات میان محتوای فیلمها را مبنایی برای پیشنهاد فیلم قرار داد یا خیر. به عبارت دیگر، تشابهات میان دو یا چند فیلم/ محصول کاربرانی را که سلایقی مشابه دارند به سوی خود جذب میکند.

چرا گرافها؟
برای پیادهسازی و اجرای توصیهگرهای مبتنی بر محتوا، ابتدا باید در دیتابیس SQL، تمامی فیلمها را به اشیای سادهای تبدیل کنیم و فهرستی از ویژگیها را برای آنها ( برای مثال، ژانر، بازیگران و موضوعات) مشخص کنیم. در واقع، با استفاده از چندین جدول که از طریق روابط مناسب به یکدیگر متصل هستند میتوان آن را اجرا کرد.
قابلیت دیتابیسهای مبتنی بر گراف زمانی برای ما آشکار میشود که بخواهیم روابطی به غیر از Movie→HasProperty→Property را مد نظر قرار دهیم. به بیانی دیگر، هدف ما ارائه مدلی بسیار غنیتر است که در آن روابط میان ویژگیها را به نحوی کارآمد نشان دهیم و برای ویژگیها نیز ویژگیهای و خصوصیات جداگانهای متصور شویم. علاوه بر این، با انجام این کار میتوانیم ماهیت میان هر یک از روابط را مشخص کنیم. در این حالت، مدل گراف گویاتر و شفافتر خواهد بود.

تصویر بالا نمونهای از گرافهای دانش است که در آن فیلمها ، کتابها و همچنین بازیگران، ژانرها و روابط پیچیده میان آنها به نمایش گذاشته شده است. در گرافهای دانش، علاوه بر اینکه میدانیم چه آیتمی با چه ویژگیهایی در ارتباط است، چگونگی روابط میان آنها را نیز میدانیم و این مسئله هیچ محدودیتی در روابط میان آیتمها و ویژگیها و چگونگی ارتباط میان این دو ایجاد نمیکند.
ساختار گرافهای دانش به گونهای است که به روشهای گوناگونی میتوانیم آیتمهایی که قصد داریم به کاربر پیشنهاد دهیم را توصیف کنیم. به عبارت دیگر، در زمان مقایسه دو آیتم، درک عمیقتری نسبت به اینکه ممکن است یک کاربر چه آیتمی را دوست داشته باشد و چرا خواهیم داشت. برای مثال، اگر کاربری «اطلس ابر» (فیلم) را دوست داشته باشد، ممکن است فیلم «اگه میتونی منو بگیر» را هم دوست داشته باشد چرا که تام هنکس در هر دو فیلم نقشآفرینی کرده است.
از سوی دیگر، ممکن است کاربران در داستانهای تخیلی به دنبال چیزهای متفاوتی باشند. اگر کاربران قصد خرید کتابی را داشته باشند، ممکن است «اطلس ابر» (کتاب) را دوست داشته باشند و اگر «اگه میتونی منو بگیر» را هم دوست داشتند، شاید کتاب « من ملاله هستم» را هم دوست داشته باشند چرا که این کتاب همچون کتاب اطلس ابر زندگینامه است و جوایز مشابهی را از آن خود کرده است.
[irp posts=”21451″]هرچند مدلسازی آن با استفاده از فناوریهای استاندارد SQL امکانپذیر است، اما به دلیل ساختار غنی گرافهای دانش این امر با دشواریهایی همراه است. در عوض، مدلسازی اینچنین ساختاری در دیتابیسهای مبتنی بر گراف آسانتر است. علاوه بر این، جستوجوی حجم بالایی از روابط در دیتابیس SQL روشی کارآمد و مؤثر نیست. مهمتر آنکه در دیتابیسهای مبتنی بر گراف، به دلخواه میتوانیم ساختار گراف دیتابیس را گسترش دهیم و دامنهای که به طور مداوم در حال بسط و گسترش است را به نمایش بگذاریم.
ارائه پیشنهاد
برای پیشنهاد آیتم به کاربران همواره از مدلهای پیچیده یادگیری ماشین استفاده میشود. اما در اینجا از الگوریتم PageRank برای پیشنهاد آیتم به کاربران استفاده میکنیم و بدین وسیله از تمامی قابلیتهای گرافها بهره میگیریم. PageRank الگوریتمی است که گوگل از آن برای رتبهبندی صفحات وبسایتها استفاده میکند. هدف از استفاده از الگوریتم PageRank رتبهبندی مهمترین و مرتبطترین صفحات اینترنت است. به بیانی دیگر از این الگوریتم برای ارزیابی و سنجش میزان اهمیت یک صفحه استفاده میشود.
الگوریتم PageRank با دنبالکردن لینکهای میان صفحات وبسایتها، مشابه یک وبگرد تصادفی Random web-surfer که از یک صفحه به صفحه دیگر منتقل میشود، عمل میکند. صفحات وبسایتها در قالب گرهها Node نمایش داده میشود و زمانیکه یک صفحه شامل لینکی از صفحات دیگر باشد اتصالات (یالها) ایجاد میشوند. PageRank یک وبسایت – که یک گره در گراف وب است – بر اساس اینکه چقدر احتمال دارد کاربری که بی دلیل در وب پرسه میزند، از یک صفحه مشخص سر درآورد، محاسبه میشود.

در گرافی که در تصویر بالا مشاهده میکنید مهمترین صفحه وبسایت ویکیپدیا است و به دنبال آن Neo4j و Dev.to و در رتبه بعد نیز گوگل، Reddit و غیره قرار میگیرند.
در مدل PageRank، فرض بر این است که وبگرد تصادفی میتواند در هر زمان به صفحات کل شبکه انتقال پیدا کند. این وبگرد به جای اینکه لینکهای درون یک صفحه را دنبال کند، مشابه وبگردی عمل میکند که به سادگی با یک URL متفاوت در مرورگر تایپ میشود.
در نوع دیگری که Personalized PageRank نامیده میشود، تعداد صفحاتی که وبگرد میتواند به آن منتقل شود را به یک مجموعه مشخص از گرههای گراف ( و از آنجاییکه نشاندهنده صفحاتی است که یک کاربر بیشتر از سایر صفحات دوست داشته است، مجموعه ترجیحی Preference set یا مجموعه شخصیسازیشده Personalized set نیز نامیده میشود) محدود میکنیم. برای مثال اگر تغییراتی اعمال کنیم و به موجب آن وبگرد فقط بتواند به Medium منتقل شود، PageRank را به اصطلاح «شخصیسازی» کردهایم و در نهایت رتبهبندی که در تصویر مقابل نمایش داده شده را به دست میآوریم:

توجه داشته باشید که در مدل وبگرد تصادفی به چیزی که گراف مدلسازی میکند، نیازی ندارد. چیزی که در پایان به دست میآوریم، رتبهبندی گرههای موجود در گراف بر اساس ربط و اهمیت آنها است و در این رتبهبندی چیزهایی که گرهها به نمایش میگذارند نقشی ندارند.
پس باید بتوانیم کاری مشابه با دیتابیس مبتنی بر گراف فیلم انجام دهیم، درست است؟ بله! PageRank جهانی گراف دانشی که پیش از این نشان دادیم، رتبهبندی مقابل را به ما میدهد:

تصویر بالا رتبهبندیای خواهد بود که ما از آن برای نمایش محصولات به کاربری که به تازگی از وبسایت ما بازدید کرده استفاده میکنیم. این رتبهبندی فهرستی از سه فیلم برتر 1) من ملاله هستم، 2) اطلس ابر و 3) اگه میتونی منو بگیر ایجاد میکند. به همین دلیل به کاربر پیشنهاد میدهیم کتاب «من ملاله هستم» را مطالعه کند.
[irp posts=”6250″]فرض کنید کاربر پیشنهاد ما را میپذیرد و کتاب « من ملاله هستم» را مطالعه میکند و از خواندن آن لذت میبرد. اینکه کتاب « من ملاله هستم» مورد پسند کاربر واقع میشد چه اطلاعاتی به ما میدهد؟ و در نتیجه این اطلاعات چه تغییراتی باید در پیشنهاد محصول اعمال شود؟ اگر هیچ تغییری اعمال نشود، در مرحله بعد باید به کاربر توصیه کنیم که فیلم « اطلس ابر» را تماشا کند، اما شاید از این واقعیت که کتاب « من ملاله هستم» مورد پسند کاربران واقع شده است بتوانیم استفاده بهتری داشته باشیم.
به بیانی دیگر به سادگی میتوانیم PageRank را به سوی «من ملاله هستم» شخصیسازی کنیم. این کار موجب میشود گرههای مرتبط با « من ملاله هستم» در رتبه بالا قرار بگیرند. یکی دیگر از مزیتهای رتبهبندی شخصیسازیشده این است که امکان محدود کردن محاسبات به گرههایی که از محل تأثیر پذیرفتهاند فراهم میکند.
یکی دیگر از مزایای PageRank شخصیسازی شده این است که میتوانیم از میزان اهمیتی که کاربر برای یک رابطه قائل است برای شخصیسازی بیشتر استفاده کنیم. برای مثال اگر کاربری علاقه دارد فیلمی متفاوت تماشا کند اما همان بازیگران در آن نقشآفرینی کنند، میتوانیم وزن رابطه Stars و Co-stars را برای آن کاربر بالا ببریم.
اگر PageRank شخصیسازی شده را در همان گراف «من ملاله هستم» به عنوان تنها گره منبع اجرا کنیم، رتبهبندی مقابل را به دست میآوریم:

با اعمال همین تغییرات جزئی، به کاربر پیشنهاد میکنیم یا فیلم «اگه میتونی منو بگیر» را تماشا کند و یا به جای اینکه فیلم «اطلس ابر» را تماشا کند، کتاب «اطلس ابر» را مطالعه کند.
برای آنکه توانایی PageRank شخصیسازی شده را در مطابقت داشتن با ترجیحات و اولویتهای کاربران نشان دهیم، فرض کنید که کاربری کتاب «اطلس ابر» را مطالعه کرده و از خواندن آن لذت برده است. در این حالت، فقط لازم است کتاب «اطلس ابر» را در مجموعه شخصیسازیشده قرار دهیم و در نتیجه رتبهبندی مقابل را به دست میآوریم:

بنابراین بدون اینکه ما دخالتی داشته باشیم، یک مجموعه شخصیسازیشده از سه فیلم برتر 1) من ملاله هستم (کتاب)، 2) اطلس ابر، 3) اگه میتونی منو بگیر در اختیار داریم که میتوانیم به کاربر پیشنهاد دهیم.
PageRank شخصیسازی شده اثبات کرده است ابزاری بسیار کارآمد در زمینه پیشنهادات شخصیسازیشده است و حتی توییتر نیز از این ابزار استفاده میکند تا حسابهای کاربری را به کاربران نشان دهند که تمایل دارند آنها را دنبال کنند .
متأسفانه، از آنجاییکه PageRank نیازمند چندین پیمایش در یک گراف عظیم است، این ابزار در ابتداییترین حالت خود، الگوریتمی مقیاسپذیر نیست. خوشبختانه گالو و همکاران او روشی پیشنهاد دادهاند تا از پالایش ذرهای Particle filtering برای تخمین دقیق PageRank در گراف دانش استفاده شود. بعدها از این رویکرد در پیادهسازی و اجرا استفاده میکنیم.
MindReader
همانگونه که پیش از این گفتیم، از این رویکرد در ساخت یک سیستم توصیه گر استفاده کردهایم. کاربران MindReader به صورت گروهی در حال ساخت یک دیتاست هستند: این دیتاست حتی با دیتاستهای مورد استفاده در بهروزترین پژوهشهای انجام شده حول موضوع سیستمهای توصیهگر متفاوت است.
در ادامه چگونگی ساخت MindReader را توضیح خواهیم داد. اما در ابتدا لازم است کمی در مورد پیشزمینه آن توضیح دهیم:
MindReader پیش از هر چیز یک سیستم توصیه گر برای ساخت گروهی دیتاست است. چیزی که در میان پژوهشگران دیتاست MindReader را از سایر دیتاستهای معتبر مجزا میکند این است که در این دیتاست علاوه بر اینکه میدانیم کاربران چگونه امتیاز میدهند، برای مثال فیلمهای ترسناک و اکشن با حضور مت دیمن، نظر کاربران در مورد ژانرها و بازیگران را نیز میدانیم.
برای اولین بار، پژوهشگران میتوانند نسبت به صحت و درستی فرضیات شکلگرفته در فرایند استخراج محصولات موردعلاقه و اولویتهای کاربر ( برای مثال درو فیلمهای علمی-تخیلی و کمدی را دوست دارید به این دلیل که فیلم «راهنمای مسافران مجانی کهکشان» را دوست دارد) اطمینان حاصل کنند، چرا که دیگر میدانیم درو چگونه به فیلمها امتیاز میدهد. علاوه بر این با بهرهگیری از این دیتاست خواهیم توانست سلیقه کاربر در فیلم را به درستی و بر مبنای مؤلفههای گستردهتری از جمله ژانر یا موضوعات استنباط کنیم که روشی بسیار سودمند در حل مشکل شروع سرد است، در حالیکه در ابتدا اطلاعات زیادی راجع به کاربر نداشتیم.
در ابتدا MindReader از کاربران میخواهد به تعدادی فیلم، ژانر، بازیگران و کارگردانها امتیاز دهند:

توجه داشته باشید که پیادهسازی بخش «فیلمهای مرتبط» Ne04j بسیار آسان است و همسایگان تک جهشی One-hop neighbor را در گراف نشان میدهد که به صورت تصادفی فیلمهایی هستند که بعداً نشان خواهیم داد. جستوجوهای پیچیده در دیتابیس قدیمی SQL روشی کارآمد و مناسب نخواهد بود.
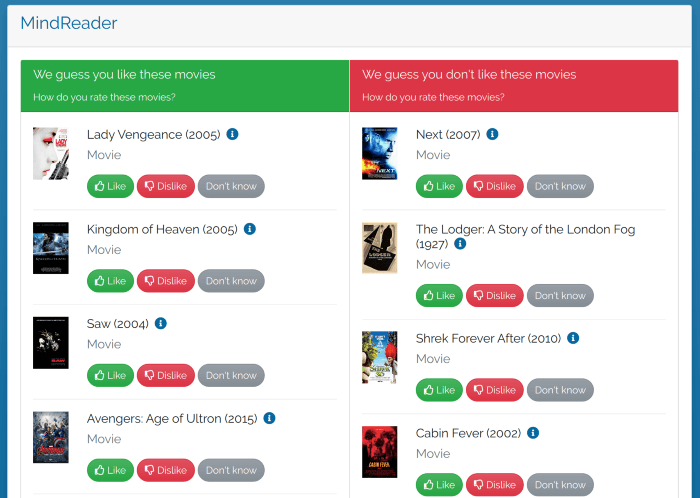
پس از آنکه به تعداد کافی امتیاز جمعآوری شد، دو فهرست به کاربر نمایش داده میشود: فیلمهایی که فکر میکنیم کاربر دوست دارد و فیلمهایی که فکر میکنیم کاربر دوست ندارد. فرایند ایجاد این فهرستها بسیار کوتاه است: PageRank شخصی سازی شده را با گرههایی که مورد پسند کاربر واقع شده و گرههایی که مورد پسند کاربر واقع نشده است را به عنوان گره منبع اجرا کنید، سپس فهرستی از گرهها بر اساس رتبه ایجاد کنید و ده گره برتر را انتخاب کنید:
جستوجوی دیتابیس مبتنی بر گراف
به عقیده ما استفاده از Neo4j با پایتون – زبان منتخب ما برای API -بسیار ساده است. پس از نصب Neo4j Bolt Driver و راهاندازی آن با وارد کردن نام کاربری و رمز عبور دیتابیس، میتوانیم دیتابس را جستوجو کنیم. هرچند پیش از آنکه مستقیماً به سراغ جستوجو از پایتون برویم، از Neo4j Browser بسیار استفاده کردیم و در نتیجه توانستیم گراف خود را جستوجو کنیم و نتایج آن را به تصویر بکشیم. از این روی توانستیم آزمایشات متعددی بر روی جستوجوها انجام دهیم و درک عمیقتری نسبت به ساختار گراف و زبان پرسمان Cypher پیدا کنیم.
برای مثال، با پرسمان مقابل میتوانیم افراد مرتبط با فیلم اطلس ابر را نشان دهیم ( مثال از Guide to Cypher Basics گرفته شده است):
MATCH (people: Person)-[relatedTo]-(movie: Movie {name: "Cloud
Atlas"})
RETURN people, movie

ما فقط از دو جستوجوی Cypher استفاده میکنیم: از یک جستوجو برای واکشی Fetch گرهها استفاده میکنیم تا در مورد (برای مثال ژانر، بازیگران و کارگردانان) سؤالاتی بپرسیم و از جستوجوی دیگر برای پیشنهاد فیلم استفاده میکنیم. هر دو جستوجو از امتیاز PageRank استفاده میکنند و همانگونه که پیش از این نیز گفتیم، از پالایش ذرهای استفاده میکنیم: پالایش ذرهای یک افزونه Neo4j است که بسیار سریعتر از اجرای پیشفرض، PageRank (شخصیسازیشده) را تخمین میزند.
ابتدا URIهای گرههایی که در $uris مورد پسند کاربر واقع شده را ذخیره میکنیم. این URIها مجموعه شخصیسازیشده ما را تشکیل میدهند. منظور از مجموعهشخصیسازیشده گرههای منبعی است که وبگرد تصادفی میتواند به آن منتقل شود. گرههای منطبق با URIها را جمعآوری میکنیم و آنها را به الگوریتم particlefiltering منتقل میکنیم:
MATCH (n) WHERE n.uri IN $uris WITH COLLECT(n) AS nLst CALL particlefiltering(nLst, 0, 100) YIELD nodeId, score
در نتیجه شناسههای گرهها nodeId و امتیازهای Personalized PageRank یا همان score را در اختیار ما قرار میدهد.
البته قصد نداریم گرههایی که کاربر دیده است را برگردانیم. راه حل این مشکل داشتن فهرستی از تمامی URIهایی است که یک کاربر در متغیر $seen دیده است سپس با فرمان آن ار حذف میکنیم:
MATCH (n) WHERE id(n) = nodeId AND NOT n.uri IN $seen WITH DISTINCT id(n) AS id, score, n.name AS name
به لحاظ تئوری میتوانستیم همه چیز را به اینجا برگردانیم، اما متوجه شدیم بدون ارائه اطلاعات و جژئیات مرتبط کاربران به دشواری میتوانند بازیگران را تشخیص دهند و یا موضوع را درک کنند. در نتیجه تمامی فیلمهای مرتبط با موجودیتها (بازیگران، موضوعات و …) را پیدا کردیم.
در گراف ما، فقط فیلمهایی که ادامه و یا پیش درآمد دارند، همبند هستند. بنابراین اگر از کلیدواژه MATCH استفاده میکردیم، تمامی فیلمهایی که امتیاز دارند، حذف میشدند. برای حل این مشکل، یک OPTIONAL MATCH را اجرا کردیم و ازcollect() برای محدود کردن فیلمهای استفاده کردیم که در ارتباط با 5 فیلم برتری هستند که PageRank جهانی آنها بالاتر است.
OPTIONAL MATCH (r)<--(m: Movie) WHERE id(r) = id WITH algo.asNode(id) AS r, m, score ORDER BY m.pagerank DESC WITH r, COLLECT(DISTINCT m)[..5] as movies, score
و حالا میتوانیم برگردیم و اطلاعاتی که نیاز داریم را استخراج کنیم:
RETURN r:Director AS director, r:Actor AS actor, r.imdb AS imdb, r:Subject AS subject, r:Movie AS movie, r:Company AS company, r:Decade AS decade, r.uri AS uri, r.name AS name, r:Genre AS genre, r:Person AS person, r:Category AS category, r.image AS image, r.year AS year, movies, score
با استفاده از Neo4j میتوانیم گرههای مرتبط را پیدا کنیم و بدون نیاز به اجرای سیستم توصیه گر دادههای مرتبط را استخراج کنیم. اگر میخواستیم این کار را با فناوریهای قدیمی SQL انجام دهیم، میبایست گرهها و لبهها را در جدول مدلسازی کنیم، گرههای تک تک پرسمانها را استخراج کنیم، در یک ابزار گراف جداگانه، یک گراف بسازیم و از آنجا رتبهبندیها را محاسبه کنیم. اما به لطف قابلیتهای دیتابیسهای مبتنی بر گراف، تمامی این امور مستقیماً در دیتابیس انجام میشود.
خلاصه
در این مقاله توضیح دادیم که چگونه میتوان از گرافهای دانش و دیتابیسهای مبتنی بر گراف در پیشنهاد محصول به کاربر استفاده کرد. علاوه بر این نشان دادیم چگونه از Neo4j در ساخت MindReader استفاده کردیم و به مطالعه و بررسی مفروضاتی پرداختیم که در طول فرایند به آنها توجه داشتیم. همچنین توضیح دادیم که چگونه سیستم مدیریت دیتابیسی که انتخاب کرده بودیم برای ما سودمند واقع شد.
توجه داشته باشید که مدلسازی یک مسئله با استفاده از گرافها میتواند ابزاری قدرتمند برای حل مسائل پیچیده در اختیار ما قرار دهد. Neo4j امکان پیادهسازی و اجرای یک سیستم توصیه گر را برای ما فراهم کرده که کاربران با بهرهگیری از آنها میتوانند به صورت گروهی دیتابیسی متفاوت از سایر دیتابیسها بسازند. علیرغم اینکه ما دانش و تسلط بیشتری بر SQL داریم، اگر میخواستیم از فناوریهای قدیمی دیتابیس استفاده کنیم، دستیابی به نتایجی مشابه با دشواریهای بیشتری همراه میبود و ممکن بود عملکرد مناسبی نداشته باشد. دیتابیس جدیدی که به منظور ارتقای سطح کیفیت تحقیقات و پژوهشها در زمینه پیشنهاد شخصیسازیشده با دیگران به اشتراک میگذاریم، حیطههای پژوهشی مختلفی پیش روی پژوهشگران قرار میدهد.
شما با استفاده از MindReader به ارتقای سطح کیفیت پژوهشها و همچنین به توسعه و گسترش بهترین دیتاستها در جوامع پژوهشی پیشنهاد شخصیسازهشده، کمک میکنید. اگر پژوهشگر، متخصص علوم داده و یا از علاقهمندان به این حوزه هستید میتوانید دیتاست کامل MindReader را از اینجا دانلود کنید.





