
مدل تشخیص چهره ای که می توانید در کمتر از 30 دقیقه آن را بسازید
 تیم تحریریه
تیم تحریریه- ۳ مرداد ۱۴۰۰
مقدمه
در این نوشتار قصد دارم به جزئیات پیادهسازی مدل تشخیص چهره بپردازم. اخیراً یک رابط کاربری در جستجوگر
Browser-based UI طراحی کردم که برای افزودن یک فرد جدید به پایگاه داده کاربرد دارد. توضیحات مربوط به توسعهی شبکه
Web-development از حوصلهی این بحث خارج است.
نویسندهی این متن فرض را بر شناخت مخاطب از مدل شبکهی Siamese و تابع زیان سهگانه قرار داده است.
فهرست محتوای این مقاله بدین شکل است:
• معماری مدل
• دیتاست
• نسل سهگانه Triplet generation
• جزئیات متفرقه
• نتیجهگیری
معماری مدل
شبکه عصبی پیچشی Convolutional neural network بدیهی است که آموزش یک (CNN) از نقطهی صفر نیازمند دادههای فراوان و قدرت محاسباتی بالاست. بنابراین به جای آن از از یادگیری انتقالی Transfer learning استفاده میکنیم؛ در این روش مدل را برروی دادههایی آموزش میدهیم که به دقت مطابق با نیاز ما تنظیم شدهاند. هندسهی تصویری Visual geometry group گروه (VGG) از دانشگاه آکسفورد سه مدل (VGG-16، ResNet-50 و SeNet-50) برای ردهبندی و تشخیص چهره ساختهاند. من از مدل تشخیص چهره VGG-16 استفاده کردهام زیرا کوچکتر است و روی سیستم محلی من که GPU ندارد، پیشبینی سریعتری انجام میدهد.
برای اینکه مدل یادگیری عمیق VGG-16 را با گروه هندسهی تصویری (VGG) اشتباه نگیرید، از اینجای متن به بعد به این گروه با عنوان گروه آکسفورد اشاره خواهیم کرد.
در این مورد، همهی مدل در Keras با چارچوب TensorFlow v1.14 پیادهسازی شده است. من هم قصد داشتم همین مدل را در TensorFlow v2.3 اجرا کنم، به همین دلیل یک ابزار virtualenv در سیستم محلی خود ایجاد کردم و وزنهای مدل را استخراج نمودم. این وزنها در vgg_face_weights.h5 ذخیره و در گام بعدی روی یک شبکهی آموزش نیافتهی VGG-16 (در TensorFlow v2.3) بارگزاری شدند. اگر قصد کار با ResNet-50 یا SeNet-50 را دارید، میتوانید برای گرفتن مدل و وزنها از Refik Can Malli’s repository استفاده نمایید.
مدل VGG-16 روی دیتاستی آموزش میبیند. در مقالهی مذکور مدل ردهبندی را برروی 2622 چهره آموزش دادهاند. لایهی یکی مانده به آخر 4096 واحد Dense دارد که به آنها یک لایهی Dense 128 واحدی ضمیمه کرده (بدون شرط سوگیری) و لایهی ردهبندی/بیشینههموار softmax را که 2622 واحد دارد، حذف مینماییم. همهی لایههایی که قبل از لایهی Dense 128 مسدود
frozen واحدی قرار دارند، (trainable = False) میشوند و بدین ترتیب فقط لایهی Dense که تازه اضافه شده نیاز به آموزش خواهد داشت.
vggface = tf.keras.models.Sequential()
vggface.add(tf.keras.layers.Convolution2D(64, (3, 3), activation='relu', padding="SAME", input_shape=(224,224, 3)))
vggface.add(tf.keras.layers.Convolution2D(64, (3, 3), activation='relu', padding="SAME"))
vggface.add(tf.keras.layers.MaxPooling2D((2,2), strides=(2,2)))
vggface.add(tf.keras.layers.Convolution2D(128, (3, 3), activation='relu', padding="SAME"))
vggface.add(tf.keras.layers.Convolution2D(128, (3, 3), activation='relu', padding="SAME"))
vggface.add(tf.keras.layers.MaxPooling2D((2,2), strides=(2,2)))
vggface.add(tf.keras.layers.Convolution2D(256, (3, 3), activation='relu', padding="SAME"))
vggface.add(tf.keras.layers.Convolution2D(256, (3, 3), activation='relu', padding="SAME"))
vggface.add(tf.keras.layers.Convolution2D(256, (3, 3), activation='relu', padding="SAME"))
vggface.add(tf.keras.layers.MaxPooling2D((2,2), strides=(2,2)))
vggface.add(tf.keras.layers.Convolution2D(512, (3, 3), activation='relu', padding="SAME"))
vggface.add(tf.keras.layers.Convolution2D(512, (3, 3), activation='relu', padding="SAME"))
vggface.add(tf.keras.layers.Convolution2D(512, (3, 3), activation='relu', padding="SAME"))
vggface.add(tf.keras.layers.MaxPooling2D((2,2), strides=(2,2)))
vggface.add(tf.keras.layers.Convolution2D(512, (3, 3), activation='relu', padding="SAME"))
vggface.add(tf.keras.layers.Convolution2D(512, (3, 3), activation='relu', padding="SAME"))
vggface.add(tf.keras.layers.Convolution2D(512, (3, 3), activation='relu', padding="SAME"))
vggface.add(tf.keras.layers.MaxPooling2D((2,2), strides=(2,2)))
vggface.add(tf.keras.layers.Flatten())
vggface.add(tf.keras.layers.Dense(4096, activation='relu'))
vggface.add(tf.keras.layers.Dropout(0.5))
vggface.add(tf.keras.layers.Dense(4096, activation='relu'))
vggface.add(tf.keras.layers.Dropout(0.5))
vggface.add(tf.keras.layers.Dense(2622, activation='softmax'))
vggface.load_weights(os.path.join(base_dir, 'vgg_face_weights.h5'))
vggface.pop()
vggface.add(tf.keras.layers.Dense(128, use_bias=False))
for layer in vggface.layers[:-2]:
layer.trainable = False
“بارگزاری وزنهای از پیش آموزش دیدهشدهی VGG-16 و سپس اختصاصی کردن مدل.”
حال برای آموزش این شبکه از یک تابع زیان سهگانه استفاده میکنیم. تابع زیان سهگانه سه ویژگی 128 بُعدی را که از شبکهی بالا تولید شدهاند، دریافت میکند. این سه ویژگی را میتوانیم با این نامها و تعاریف مشخص کنیم:
• لنگر anchor : تصویری از یک فرد که برای مقایسه استفاده میشود؛
• مثبت positive : تصویر همان فرد حاضر در تصویر لنگر؛
• منفی negative : تصویر فردی متفاوت از تصویر لنگر.

تابع زیان سهگانه تلاش دارد فاصلهی بین لنگر و مثبت را کم و فاصلهی بین لنگر و منفی را بیشتر کند. یک پارامتر دیگر هم داریم (alpha = 0.2) که یک حاشیه اضافه کرده و بدین ترتیب آموزش را سختتر میکند و همگرایی بهتری به دست میدهد. این پارامترها (یعنی واحد متراکم 128 بُعدی و آلفا که پارامتر تابع زیان است) بر اساس تجزیهتحلیلی انتخاب میشوند که در این مقاله به نمایش گذاشته شده است.
def loss_function(x, alpha = 0.2):
# Triplet Loss function.
anchor,positive,negative = x
# distance between the anchor and the positive
pos_dist = K.sum(K.square(anchor-positive),axis=1)
# distance between the anchor and the negative
neg_dist = K.sum(K.square(anchor-negative),axis=1)
# compute loss
basic_loss = pos_dist-neg_dist+alpha
loss = K.mean(K.maximum(basic_loss,0.0))
return loss
# Note K in the above function is defined as follows K = tf.keras.backend
پیادهسازی تابع زیان سهگانه
اجازه دهید تا اینجای مقاله را جمعبندی کنیم. شبکهی VGG-16 به ما ویژگیهای 128-D (128 بُعدی) با عناوین لنگر، مثبت و منفی میدهد که بعداً به تابع زیان خورانده میشوند.
حال یک گزینه برای آموزش، فراخوانی سهبارهی همان مدل روی تصاویر لنگر، مثبت و منفی و سپس ارائهی مقدار به دست آمده به تابع زیان میباشد. با این حال اجرای پشت سر هم آنها فکر خوبی نیست؛ به همین دلیل به جای این کار، آنها را در یک رده از شبکهی Siamese قرار میدهیم که tf.keras.Model را گسترش داده و موازیسازی parallelization را به TensorFlow روش تنظیمی L2 regularization میسپارد. L2 هم به مدل اضافه میشود که روی خروجی لایهی Dense 128 بُعدی اجرا میگردد.
class SiameseNetwork(tf.keras.Model):
def __init__(self, vgg_face):
super(SiameseNetwork, self).__init__()
self.vgg_face = vgg_face
@tf.function
def call(self, inputs):
image_1, image_2, image_3 = inputs
with tf.name_scope("Anchor") as scope:
feature_1 = self.vgg_face(image_1)
feature_1 = tf.math.l2_normalize(feature_1, axis=-1)
with tf.name_scope("Positive") as scope:
feature_2 = self.vgg_face(image_2)
feature_2 = tf.math.l2_normalize(feature_2, axis=-1)
with tf.name_scope("Negative") as scope:
feature_3 = self.vgg_face(image_3)
feature_3 = tf.math.l2_normalize(feature_3, axis=-1)
return [feature_1, feature_2, feature_3]
@tf.function
def get_features(self, inputs):
return tf.math.l2_normalize(self.vgg_face(inputs), axis=-1)
model = SiameseNetwork(vggface)
ردهی شبکهی Siamese
من به ردهی شبکهی Siamese یک تابع get_features اضافه کردم که طی آزمایش شبکه به عنوان بهینهساز مفید خواهد بود.
حالا که یک مدل ساختهایم، میتوانیم وارد بحث دیتاست آموزشی بشویم.
دیتاست
دیتاست VGGFace از 2622 تصویر متمایز از شخصیتهای مشهور تشکیل شده و برای آموزش مدل VGG-16 مورد استفاده قرار میگیرد. گروه آکسفورد دیتاست VGGFace2 را نیز ارائه داده که 8631 تصویر را از افراد مشهور در برمیگیرد؛ تصاویر این دیتاست برای آموزش و 500 تصویر آن برای آزمایش کاربرد دارند. از آنجایی که حجم مجموعهی آموزشی 39GB است، من فقط مجموعهی آزمایشی (با حجم 2GB) را دانلود کردم و آخرین لایهی متراکم را با آن آموزش دادم.
استفاده از مجموعهی آزمایشی برای آموزش شاید اشتباه به نظر برسد، اما باید در نظر داشت که این قانون مربوط به مدلی است که روی همان دادههای آزمایشی، آموزش دیده است. من در کار خود از این مجموعه برای آموزش و از تصاویر خودم و اعضای خانواده و دوستانم به عنوان دادههای آزمایشی استفاده کردم.
پیشپردازش Pre-processing معمولاٌ متکی بر مدل زیربنایی است. بنابراین برای آموزش و آزمایش، تصاویر ورودی باید همان پیشپردازشی را طی کنند که مدل VGG-16 تعریف کرده است. تصاویر ورودی ابتدا از یک مدل تشخیص چهره (که در این مقاله معرفی شده) عبور کرده و سپس به تابع preprocess_input (که اینجا آوردهام) فرستاده میشوند. من در کار خودم از مدل تشخیص چهره که کتابخانهی dlib ارائه کرده استفاده نمودم و سپس تصاویر را به تابع preprocess_input فرستادم.
نکته: تابع preprocess_input (توضیح آن را در این قسمت میبینید) با تابعی که مدل VGG-16 (که روی ImageNet آموزش دیده) استفاده میکند، تفاوت دارد. بنابراین کد مربوط به پیشپردازش که در منبع کد پروژهی من ذکر شده ، از کتابخانهی VGGFace گرفته شده است.
حال ساختار دایرکتوری دیتاستها را توضیح خواهم داد که راهی برای بهینهسازی حافظه طی آموزش محسوب میشوند. اجازه بدهید ابتدا ساختار دایرکتوری دیتاست دانلودشده را بررسی کنیم. در ساختار دایرکتوری که پایین مشاهده مینمایید، هر دایرکتوری (n000001, n000009 و غیره) به همهی تصاویر یک شخصیت مشهور اختصاص داده شده است.
.
└── vggface2_test
└── test
├── n000001
│ ├── 0001_01.jpg
│ ├── 0002_01.jpg
│ ├── 0003_01.jpg ...
├── n000009
│ ├── 0001_01.jpg
│ ├── 0002_01.jpg
│ ├── 0003_01.jpg ...
(so on and so forth)
همانطور که پیشتر اشاره کردیم به منظور تشخیص چهره ها و ذخیرهسازی آنها در پوشهای متفاوت به نام دیتاست از مدل تشخیص چهره dlib استفاده میکنیم. اینجا درخت دایرکتوری تصاویر شناساییشده را مشاهده میکنید. این نوتبوک نیز همین شیوهی پیادهسازی را نشان میدهد.
.
└── dataset
└── list.txt
└── images
├── n000001
│ ├── 0001_01.jpg
│ ├── 0002_01.jpg
│ ├── 0003_01.jpg ...
├── n000009
│ ├── 0001_01.jpg
│ ├── 0002_01.jpg
│ ├── 0003_01.jpg ...
(so on and so forth)
ساختار دایرکتوری vggface_test و دیتاست تقریباً مشابه بکدیگر هستند. اما دایرکتوری دیتاست ممکن است تصاویر کمتری از برخی چهرهها داشته باشد، زیرا توسط مدل تشخیص چهره dlib شناسایی نشدهاند. تفاوت دیگر این است که در دایرکتوری دیتاست یک فایل list.txt وجود دارد که دربرگیرندهی دادههای directory-name/image-name برای هر تصویر میباشد. از list.txt به منظور بهینهسازی حافظه طی آموزش استفاده میشود.
نسل سهگانه
همانطورکه گفتیم یک مدل برای آموزش به سه تصویر نیاز دارد (لنگر، مثبت و منفی). اولین ایدهای که به ذهن میرسد تولید همهی جفتهای ممکن از این سهگانه است. شاید به نظر بیاید این روش دادههای زیادی در اختیار میگذارد اما پیشینهی پژوهش حاکی از ناکافی بودن آن است. بنابراین برای انتخاب لنگر، مثبت و منفی از یک مولد اعداد تصادفی Random number generator استفاده کردم. همچنین مولد دادهای را به کار بردم که طی چرخهی آموزشی داده تولید میکند.
نکتهی جانبی: مقدار زمانی که من برای نوشتن ردهی DataGenerator لازم داشتم از مدت زمان لازم برای آموزش مدل بیشتر بود.
class DataGenerator(tf.keras.utils.Sequence):
def __init__(self, dataset_path, batch_size=32, shuffle=True):
self.dataset = self.curate_dataset(dataset_path)
self.dataset_path = dataset_path
self.shuffle = shuffle
self.batch_size =batch_size
self.no_of_people = len(list(self.dataset.keys()))
self.on_epoch_end()
def __getitem__(self, index):
people = list(self.dataset.keys())[index * self.batch_size: (index + 1) * self.batch_size]
P = []
A = []
N = []
for person in people:
anchor_index = random.randint(0, len(self.dataset[person])-1)
a = self.get_image(person, anchor_index)
positive_index = random.randint(0, len(self.dataset[person])-1)
while positive_index == anchor_index:
positive_index = random.randint(0, len(self.dataset[person])-1)
p = self.get_image(person, positive_index)
negative_person_index = random.randint(0, self.no_of_people - 1)
negative_person = list(self.dataset.keys())[negative_person_index]
while negative_person == person:
negative_person_index = random.randint(0, self.no_of_people - 1)
negative_person = list(self.dataset.keys())[negative_person_index]
negative_index = random.randint(0, len(self.dataset[negative_person])-1)
n = self.get_image(negative_person, negative_index)
P.append(p)
A.append(a)
N.append(n)
A = np.asarray(A)
N = np.asarray(N)
P = np.asarray(P)
return [A, P, N]
def __len__(self):
return self.no_of_people // self.batch_size
def curate_dataset(self, dataset_path):
with open(os.path.join(dataset_path, 'list.txt'), 'r') as f:
dataset = {}
image_list = f.read().split()
for image in image_list:
folder_name, file_name = image.split('/')
if folder_name in dataset.keys():
dataset[folder_name].append(file_name)
else:
dataset[folder_name] = [file_name]
return dataset
def on_epoch_end(self):
if self.shuffle:
keys = list(self.dataset.keys())
random.shuffle(keys)
dataset_ = {}
for key in keys:
dataset_[key] = self.dataset[key]
self.dataset = dataset_
def get_image(self, person, index):
# print(os.path.join(self.dataset_path, os.path.join('images/' + person, self.dataset[person][index])))
img = cv2.imread(os.path.join(self.dataset_path, os.path.join('images/' + person, self.dataset[person][index])))
img = cv2.resize(img, (224, 224))
img = np.asarray(img, dtype=np.float64)
img = preprocess_input(img)
return img
data_generator = DataGenerator(dataset_path='./dataset/')
مولد دادهی سهگانه
__getitem__ مهمترین تابع میباشد. برای اینکه این نتیجه را به چشم خود ببینیم اجازه بدهید سازنده constructor و سایر مدلها را نیز بررسی کنیم.
• __init__: سازنده مسیر رسیدن به دایرکتوری دیتاستی که در قسمت قبل توضیح دادیم را طی میکند. سازنده از تابع list.txt به منظور ساخت یک دیکشنری استفاده میکند. این دیکشنری از اسم دایرکتوری به عنوان کلید و از لیست تصاویر آن به عنوان ارزش استفاده میکند. تابع list.txt درمرحلهی بههم زدن راهی آسان برای مرور دیتاست در اختیار ما قرار میدهد و بدین ترتیب میتوانیم از بارگزاری تصاویر برای بههم زدن shuffling جلوگیری کنیم.
• __getitem__: نام افراد را از کلیدهای دیکشنری بالا میگیریم. برای بستهی دادهای اول، 32 تصویر اول از افراد به عنوان لنگر استفاده میشود و یک تصویر دیگر از همان افراد به عنوان مثبت در نظر گرفته میشود. برای همهای اجزای این سهگانه (لنگر، مثبت و منفی) تصاویر به صورت تصادفی انتخاب میشوند. 32 تصویر از افراد بعدی، لنگر بستهی دیگری محسوب میگردند.
• curate_dataset : دیکشنری توضیحداده شده در تابع __init__ را میسازد.
• on_epoch_end : در انتهای هر دوره ترتیب افراد به هم میریزد؛ به نحوی که 32 تصویر اول در بستهی بعدی از آنچه در بستهی قبلی وجود داشته متفاوت باشد.
• get_image : این تابع بعد از تغییر اندازهی تصاویر به ابعاد (224×224) از preprocess_input استفاده میکند.
• __len__: خروجی این تابع تعداد بستههای دادهای است که یک دوره را تعریف میکنند.
انجام شد!!!
آموزش و آزمایش
من از یک چرخهی آموزشی سفارشی با کتابخانهی tqdm استفاده کردم (you still get Keras to feel) و مدل را برای 50 دوره آموزش دادهام. در کولب colab زمان مورد نیاز برای هر دورهی آموزشی 24 ثانیه است (که سرعت بالایی برای آموزش محسوب میشود).
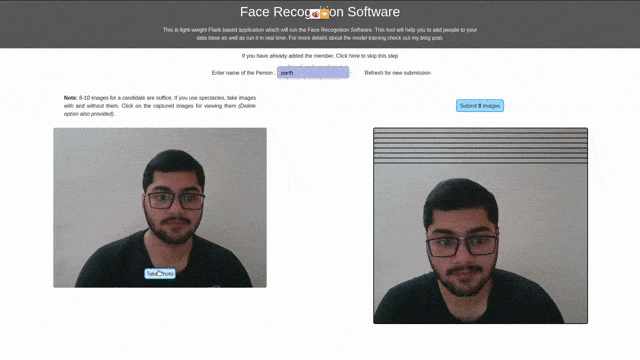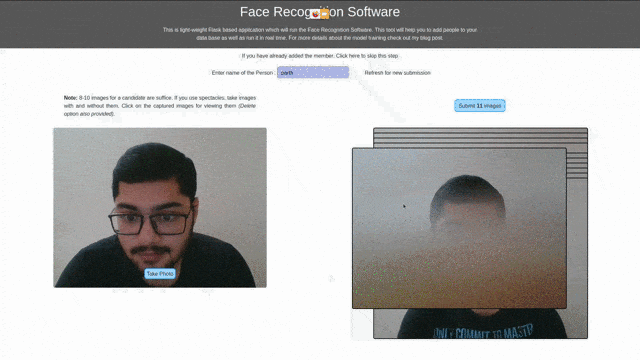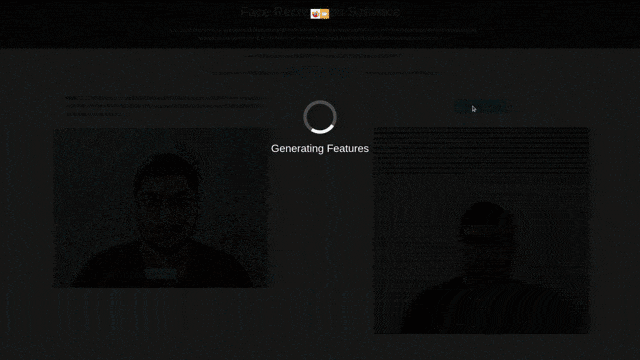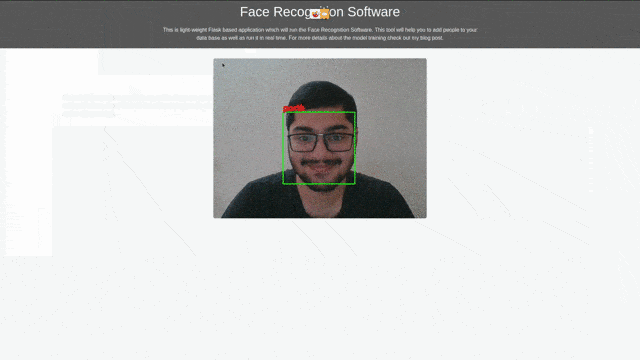
برای آزمایش میتوانید از تصاویر خود، خانواده، دوستانتان و دایرکتری خود استفاده کنید و ویژگیهای 128 بُعدی که برای هر فرد توسط لایهی متراکم تولید شده را ذخیره کنید. میتوانید از تابع (get_features) استفاده کنید که در ردهی شبکهی Siamese توضیح داده شد. همچنین برای صرفهجویی در زمان میتوانید به نوتبوک Real-time-prediction.ipynb که در پروژهی خود درست کردهام مراجعه کنید. در این نوتبوک وزنها checkpoint بارگزاری شده و دستورالعملهایی ارائه میگردد که برای جمعآوری تصاویر به منظور آزمایش آنی و پیشبینی روی تصویر وبکم کاربرد خواهند داشت.
جزئیات متفرقه
سرعت آموزش را در کولب افزایش دهید
در مولد داده به جای همهی تصاویر، شاخصهای آنها برای دستکاری روی حافظه بارگزاری شدهاند. اگر GPU دارید، شاید جزئیاتی که در این قسمت بیان میکنیم برایتان چندان مفید نباشد.
ابتدا فکر میکردم خواندن و نوشتن عملیاتها از کولب به روی درایو drive باید سریع باشد، اما بعد متوجه شدم سرعت آنها از سرعت سیستم محلی من که GPU ندارد هم کمتر است. به منظور حل این مشکل دیتاست را به dataset.7z فشردهسازی و سپس آنرا روی درایو خودم بارگزاری کردم. در قدم بعدی فایل زیپشده را از google drive برروی فضای کولب که بر اساس هر جلسه مرتب شده کپی و بعد برای آموزش از آن استفاده میکنم. استفاده از فضای کولب سرعت فرآیند آموزش را به حد معناداری افزایش داد.
با اینحال خلاصههای من از tensorboard و وزنهای مدل روی درایو ذخیره شدند، زیرا در هر دوره در دسترس هستند و عملکرد را خیلی کاهش نمیدهند.
ابزار مبتنی بر رابط کاربری
قصد داشتم به یادگیری برخی از تکنولوژیهای شبکهای همچون HTML، CSS و Javascript بپردازم. بهترین راه برای یادگیری، طراحی یک پروژهی کوچک بود. بنابراین سعی کردم یک ابزار مبتنی بر رابط کاربری برای جمعآوری داده برای آزمایش و پیشبینی بسازم. در این قسمت گامهایی که در این مسیر برداشتم را توضیح دادهام؛ میتوانید از آنها برای اجرای کار خود استفاده کنید.
نتیجهگیری
در این بلاگ جزئیات کلیدی در مورد تنظیم دقیق یک شبکهی موجود و ساخت یک شبکهی Siamese برروی آنها صحبت کردیم. یافتههای مدل کنونی از آنچه انتظار میرفت بسیار بهتر بود اما با ساخت سهگانههای خوب به صورت دستی، هنوز هم میتوان آنها را ارتقا بخشید. همچنین میتوانید همهی دیتاست آموزشی را برای آموزش مدل خود دانلود کنید. پیشینهی پژوهش نشان میدهد که انتخاب دستی یک مجموعه از سهگانههای سخت در نهایت مقدار زمان آموزش را به طرز چشمگیری کاهش و نرخ همگرایی مدل را افزایش خواهد داد.
برای امتحان ابزار جستجومحور Browser-based میتوانید سری به نوتبوکها بزنید. این ابزار قادر به تشخیص چهره چندین فرد میباشد.





