مقایسه پکیجهای EDA دیتافریم: Pandas Profiling ،Sweetviz و PandasGUI
تیم تحریریه
- ۱۳ بهمن ۱۴۰۰
بخشی از حرفه متخصصین علوم داده را تحلیل کاوشگرانه داده (EDA) تشکیل میدهد. هدف از تحلیل دادهها، درک و شناخت بیشتر آنها است.
تا چندی پیش، تحلیل دادهها با استفاده از دیتافریمهای pandas کار دشواری بود، چرا که مجبور بودیم تک تک تحلیلها را از ابتدا کدنویسی کنیم. کدنویسی تک تک تحلیلها فرایند زمانبری بود و علاوه بر آن میبایست تمامی توجه و تمرکز خود را به آن معطوف کنیم.
دیتاست mpg مقابل را در نظر بگیرد.
import pandas as pd
import seaborn as sns
mpg = sns.load_dataset('mpg')
mpg.head()

دادههای فوق ظاهراً ساده هستند اما تحلیل آنها زمان زیادی میبرد.
خوشبختانه، پکیجهای فوقالعاده زیادی توسعه داده شده که فرایند EDA را تسهیل میکنند. برای نمونه میتوان به Pandas Profiling، Sweetviz و PandasGUI اشاره کرد.
در این مقاله تصمیم دارم پکیجهای EDA را با یکدیگر مقایسه کنم و ببینم هر کدام برای چه کاری مناسب هستند.
در ادامه به معرفی این پکیجها خواهیم پرداخت و اصلیترین ویژگیهای هر کدام را با یکدیگر بررسی میکنیم.
Pandas Profiling
در این مقاله، Pandas Profiling به طور کامل معرفی شده است، اما برای مقایسه آن با پکیجهای دیگر، در این مقاله نیز توضیح مختصری از آن ارائه میدهیم.
به عقیده من Pandas Profiling سادهترین این پکیجها است. این پکیج گزارش سریعی و خوبی از دیتاست ایجاد میکند. در ادامه عملکرد آن را با یکدیگر بررسی میکنیم. ابتدا باید این پکیج را نصب کنیم.
#Installing via pip pip install -U pandas-profiling[notebook] #Enable the widget extension in Jupyter jupyter nbextension enable --py widgetsnbextension #or if you prefer via Conda conda env create -n pandas-profiling conda activate pandas-profiling conda install -c conda-forge pandas-profiling #if you prefer installing directly from the source pip install https://github.com/pandas-profiling/pandas-profiling/archive/master.zip #in any case, if the code raise an error, it probably need permission from user. To do that, add --user in the end of the line.
پس از اتمام فرایند نصب، میتوانیم از آن برای ایجاد گزارش استفاده کنیم.
from pandas_profiling import ProfileReport profile = ProfileReport(mpg, title='MPG Pandas Profiling Report', explorative = True) profile

همانگونه که در تصویر بالا مشاهده میکنید، Pandas Profiling به سرعت گزارشی از دیتاست ایجاد میکند و نمودارهای مربوط به دادهها را هم ترسیم میکند (مصورسازی). Pandas Profiling به جای ترسیم نمودارهای مربوط به دیتاست در یک فایل جداگانه، مستقیماً آن را در نوتبوک ما ترسیم میکند. در ادامه بخشهای مختلف این پکیج را با یکدیگر بررسی میکنیم.
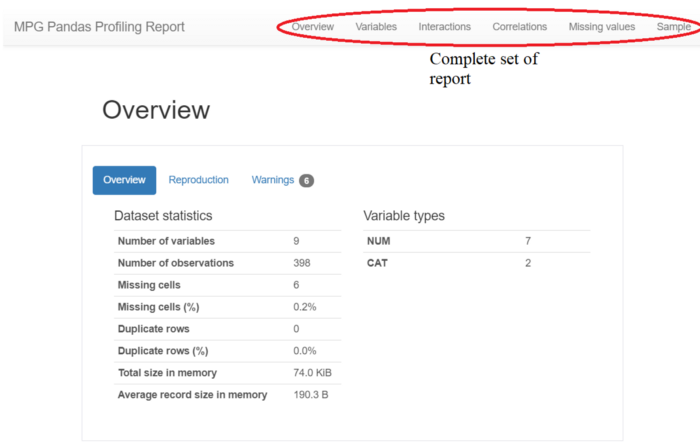
Pandas Profiling از 6 بخش Overview (مرور کلی)، Variables (متغیرها)، Interactions (تعاملات)، Correlations (همبستگیها)، Missing values (مقادیر گمشده) و Sample (نمونه) تشکیل شده است.
کاملترین بخش Pandas Profiling بخش متغیر (Variable) است، چرا که گزارش جامعی از هر کدام از متغیرها ایجاد میکند.

همانگونه که در تصویر فوق مشاهده میکنید، اطلاعات زیادی در مورد همان یک متغیر ارائه شده است. میتوانید اطلاعات توصیفی و اطلاعات چارک را به همین ترتیب به دست آورید.
با استفاده از Pandas Profiling میتوانیم اطلاعات دیگری راجع به دیتاست به دست آوریم. نمونهای از این اطلاعات، Interaction است.

در بخش Interaction میتوان نمودار پراکنش میان دو متغیر عددی را ترسیم کرد.
بخش بعدی Correlation است. در این بخش میتوانیم اطلاعات مربوط به همبستگی میان دو متغیر را به دست آوریم. در حال حاضر Pandas Profiling فقط چهار نمونه تحلیل همبستگی دارد.
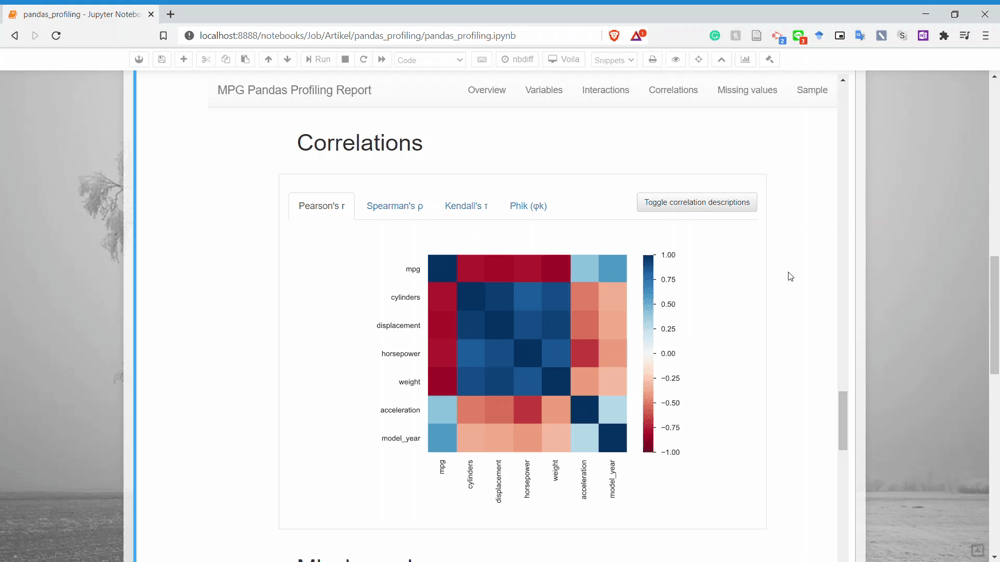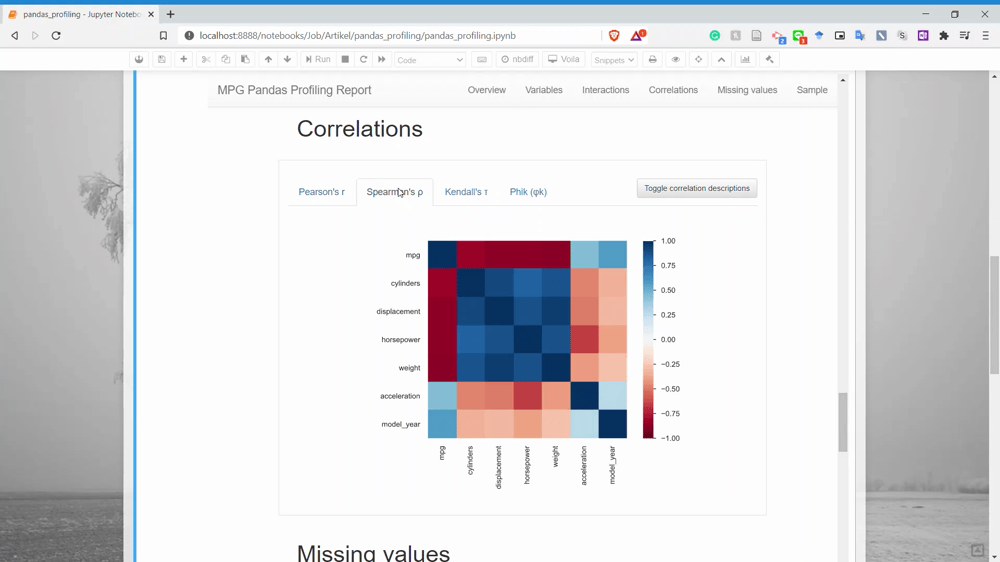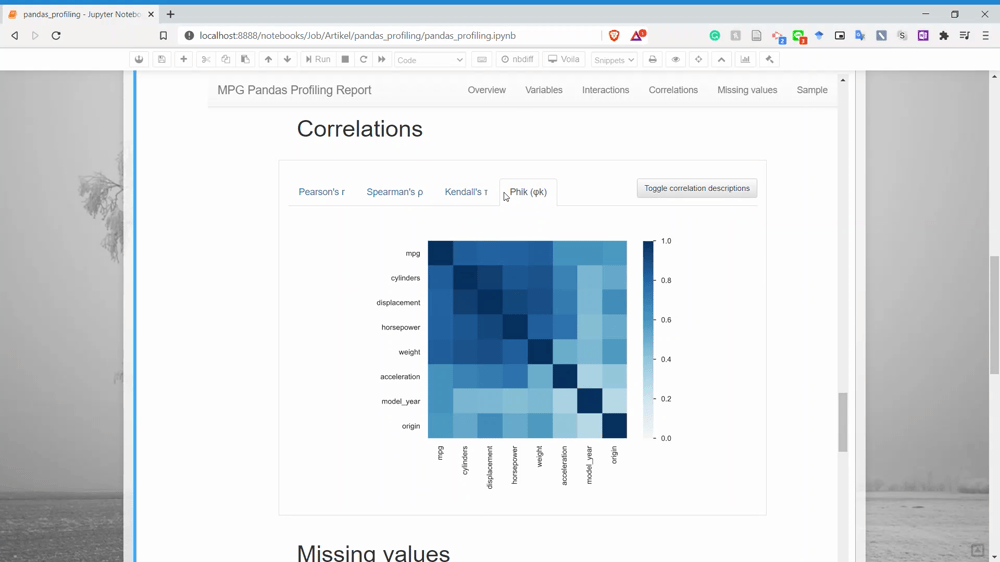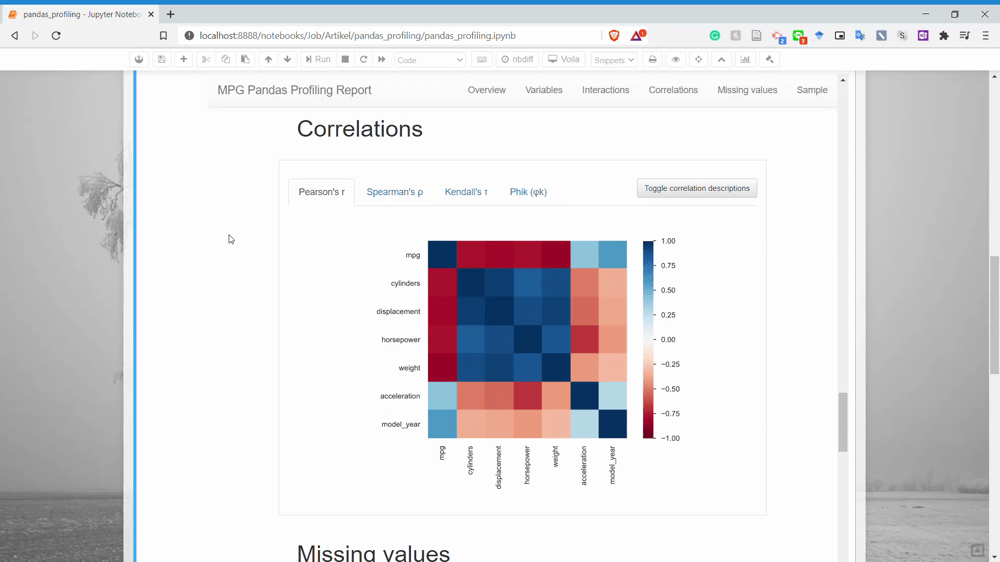
بخش بعدی Missing Values است. در این بخش میتوانید اطلاعات مربوط به تعداد مقادیر گمشده هر یک از متغیرها را به دست آورید.

آخرین بخش Sample نام دارد. این بخش فقط ردیفهای نمونه دیتاست را به ما نشان میدهد.

اطلاعات مربوط به ردیفهای نمونه ممکن است ساده به نظر برسند اما اطلاعات مهمی در اختیار ما میگذارند.
به عقیده من، نقاط قوت Pandas Profiling عبارتند از:
- ایجاد سریع گزارش
- اطلاعات دقیق مربوط به هر یک از متغیرها
و نقاط ضعف آن عبارتند از:
- فضای زیادی از حافظه را اشغال میکند
- به غیر از همبستگی و نمودار پراکنش، اطلاعات دقیق دیگری در مورد روابط میان متغیرها در اختیار ما نمیگذارد.
- وجود بخش sample ضروری نیست.
برای من، ارزش Pandas Profiling در این است که اطلاعات دقیقی در مورد دیتاست در اختیار ما میگذارد. این پکیج مناسب افرادی است که میخواهند بدانند با چه نوع دادهای سر و کار دارند. اما اگر به اطلاعات بیشتری نیاز دارید، باید به سراغ پکیجهای دیگر بروید.
Sweetviz
Sweetviz یکی دیگر از پکیجهای متنباز پایتون است؛ با استفاده از این ابزار و تنها با یک خط کد میتوان گزارش EDA مناسبی ایجاد کرد. تفاوت این پکیج با Pandas Profiling در این است که خروجی Sweetviz به طور ذاتی حاوی یک برنامه مبتنی بر HTML کاملاً است.
در مرحله اول باید این پکیج را نصب کنیم:
#Installing the sweetviz package via pip pip install sweetviz
پس از اتمام فرایند نصب، میتوانیم با استفاده از Sweetviz ، گزارش خود را ایجاد کنیم. برای ایجاد این گزارش میتوانیم از کد مقابل استفاده کنیم:
import sweetviz as sv #You could specify which variable in your dataset is the target for your model creation. We can specify it using the target_feat parameter. my_report = sv.analyze(mpg, target_feat ='mpg') my_report.show_html()

همانگونه که در تصویر فوق مشاهده میکنید، گزارشی که Sweetviz ایجاد کرده مشابه گزارش ایجادشده توسط Pandas Profiling است، اما تفاوتی که این دو گزارش دارند در این است که گزارش Sweetviz با یک UI متفاوت ایجاد شده است. در gif مقابل میتوانید گزارش ایجادشده توسط Sweetviz را مشاهده کنید.

اگر بر روی هر یک از متغیرهایی که در gif بالا نشان داده شده است، کلیک کنید، متوجه میشوید که این متغیرهای به خوبی توصیف شدهاند و اطلاعات کاملی راجع به هر کدام از آنها ارائه شده است. البته این اطلاعات را با استفاده از Pandas Profiling هم میتوانید به دست آورید.
اگر به خاطر داشته باشید، قبلاً در کد ویژگی هدف را “mpg” تعیین کردیم. یکی از مزایای Sweetviz همین است که میتوانیم اطلاعات دقیقتری درباره ویژگی هدف به دست آوریم. برای مثال، متغیر Displacement را در نظر بگیرید و به گزارش مفصلی که در سمت راست قرار گرفته است، نگاه کنید.

در تصویر بالا رابطه میان ویژگی هدف (‘mpg’) و متغیر displacment نشان داده شده است. نمودار میلهای نشاندهنده توزیع displacement است و نمودار خطی میانگین ویژگی هدف است که به دنبال متغیر displacement قرار میگیرد. اگر بخواهیم روابط میان دو متغیر را بررسی کنیم، این گزارش میتواند کمک زیادی به ما بکند.
در گوشه سمت راست گزارش، اطلاعات مربوط به همبستگی پیوند عددی و پیوند رستهای تمامی متغیرهای موجود نشان داده شده است. برای اینکه بدانید تحلیل همبستگی چه اطلاعات دیگری میتواند در اختیار ما قرار میدهد، به صفحه اصلی Sweetviz مراجعه کنید.
درست است که Sweetviz میتواند گزارشی حول EDA یک دیتاست خاص ارائه دهد اما مزیت این ابزار در این است که به کاربر اجازه میدهد دیتاست را مقایسه کند. در صفحه اصلی Sweetviz گفته شده که سیستم Sweetviz با هدف مصورسازی سریع مقادیر هدف و مقایسه دیتاست ساخته شده است.
به دو روش میتوانیم دیتاست را مقایسه کنیم: در روش اول میتوانیم دیتاست را تقسیم کنیم، برای مثال به دو دیتاست آموزشی و آزمایشی، در روش دوم میتوانیم با استفاده از تعدادی فیلتر، زیرمجموعهای برای جامعه آماری تعریف کنیم. در ادامه، روش تعریف زیرمجموعه برای دادهها (روش دوم) را امتحان میکنیم.
من میخوام بدانم دیتاستی که از دادههای مربوط به خودروهای آمریکایی تشکیل شده با دیتاستی که از دادههای مربوط به خودروهای غیرآمریکایی تشکیل شده چه تفاوتی دارد. با اجرای کد مقابل میتوانیم گزارش مربوط به این دیتاست را ایجاد کنیم.
#Subsetting are happen by using the compare_intra. We input the condition in the parameter and the name as well. my_report = sv.compare_intra(mpg, mpg["origin"] == "usa", ["USA", "NOT-USA"], target_feat ='mpg') my_report.show_html()

همانگونه که در gif بالا مشاهده کنید، میتوانیم زیرمجموعه خودروهای آمریکایی را با زیرمجموعه خودروهای غیرآمریکایی مقایسه کنیم. گزارش مربوط به مقایسه این دیتاست برای من بسیار ارزشمند است، چراکه بدون کدنویسی زیاد میتوانیم اطلاعاتی در مورد جامعه آماری به دست آوریم.
بیایید این متغیر را با دقت بیشتری بررسی کنیم.
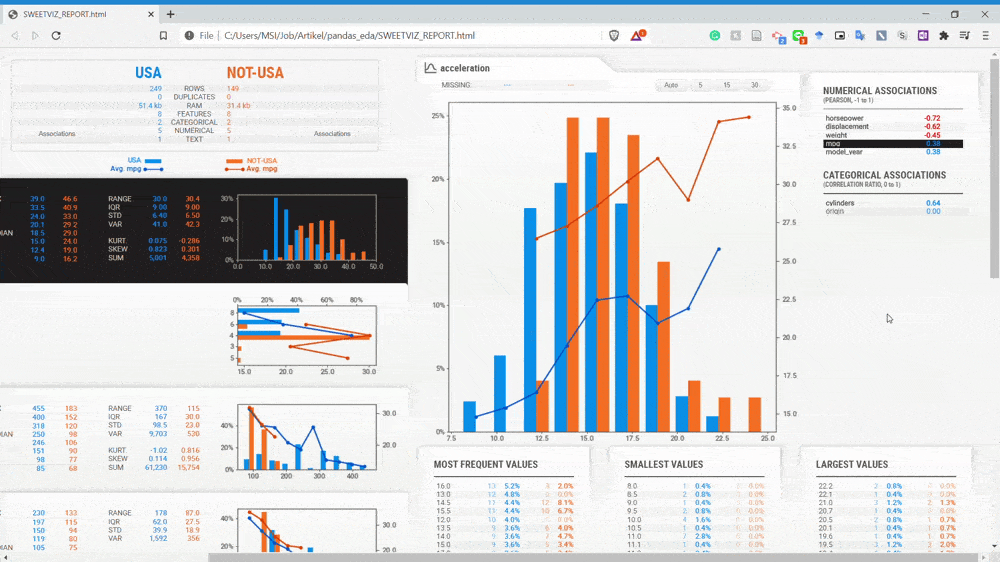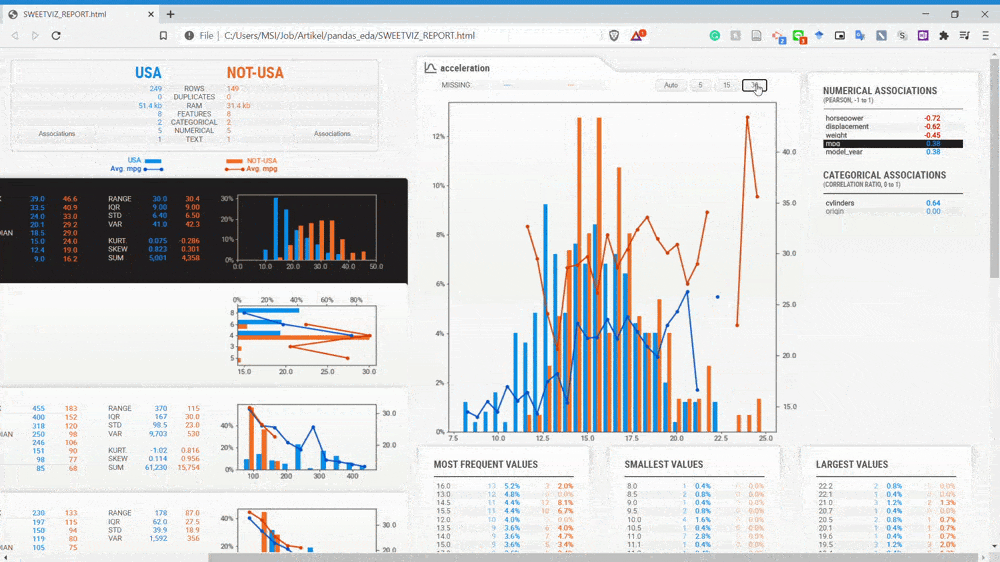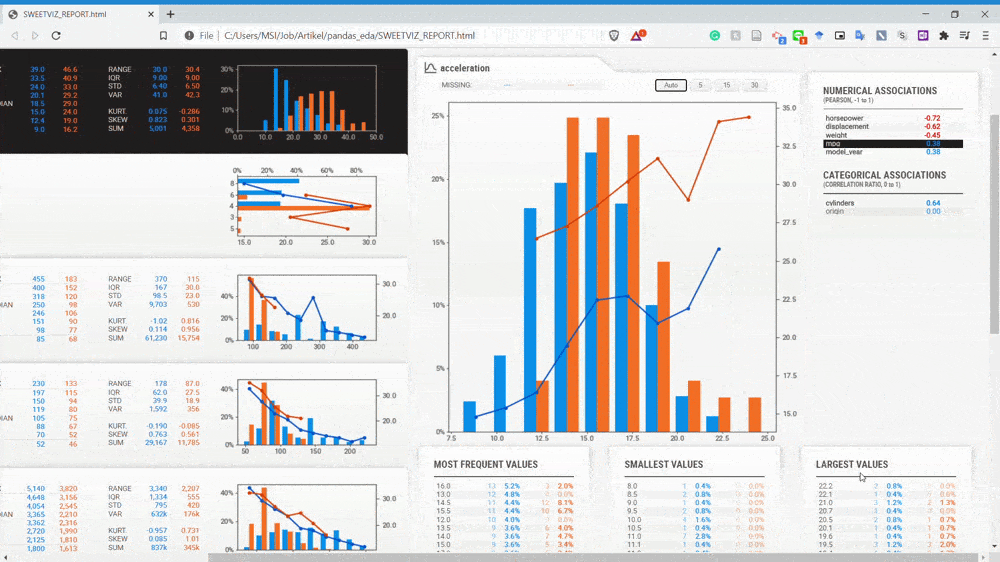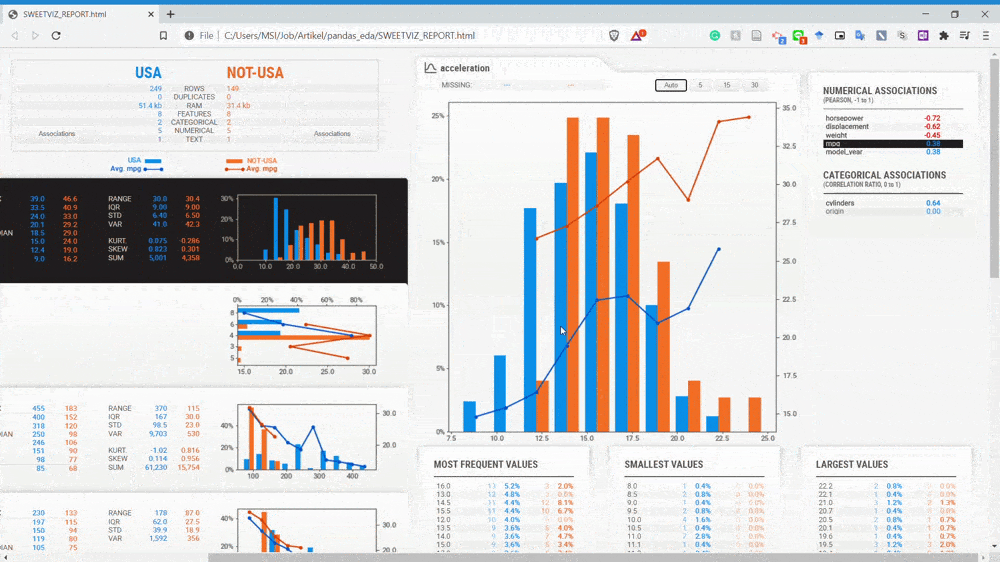
با توجه به gif بالا متوجه میشویم متغیرها به دو زیرمجموعه تقسیم شدهاند و با دو رنگ متفاوت نشان داده شدهاند ( آبی و نارنجی). حالا یک بار دیگر به سراغ متغیر displacement میرویم.
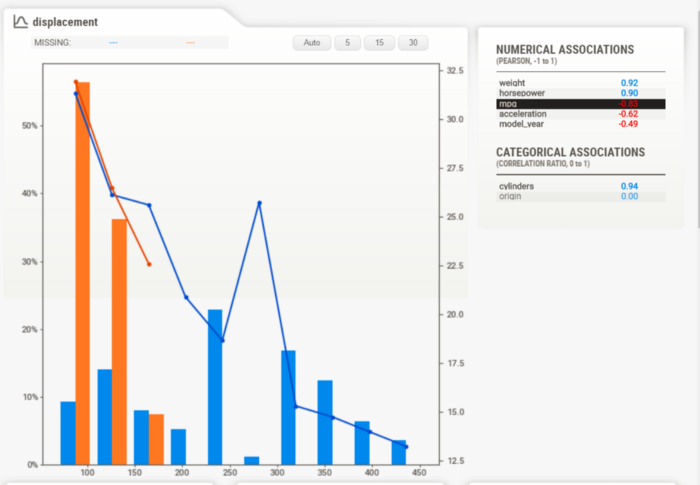
همانگونه که در تصویر فوق نشان داده شده است، متغیر displacement خودروهای غیرآمریکایی (نارنجی) خیلی کمتر از متغیر displacement خودروهای آمریکایی است. با مقایسه این دو دیتاست سریعاً میتوانیم به این اطلاعات پی ببریم.
پیوندها چطور؟ با کلیک کردن بر روی گزینه association در نام دیتاست میتوانیم به دقت پیوندها را بررسی کنیم.

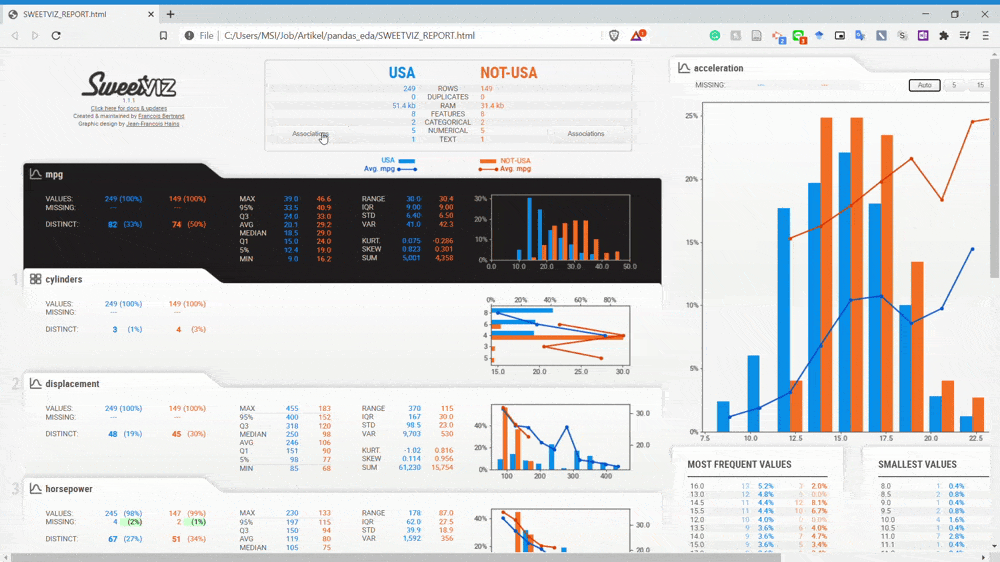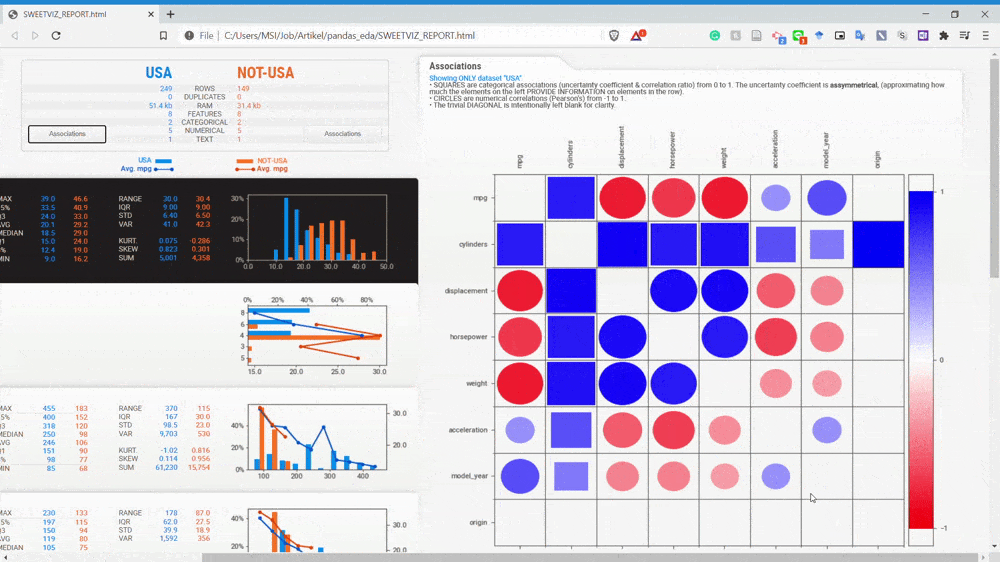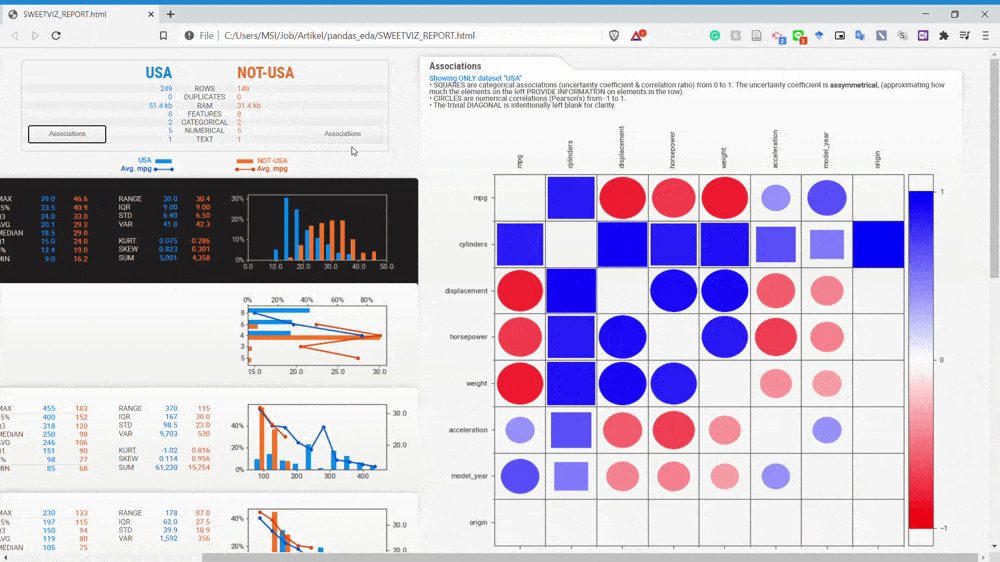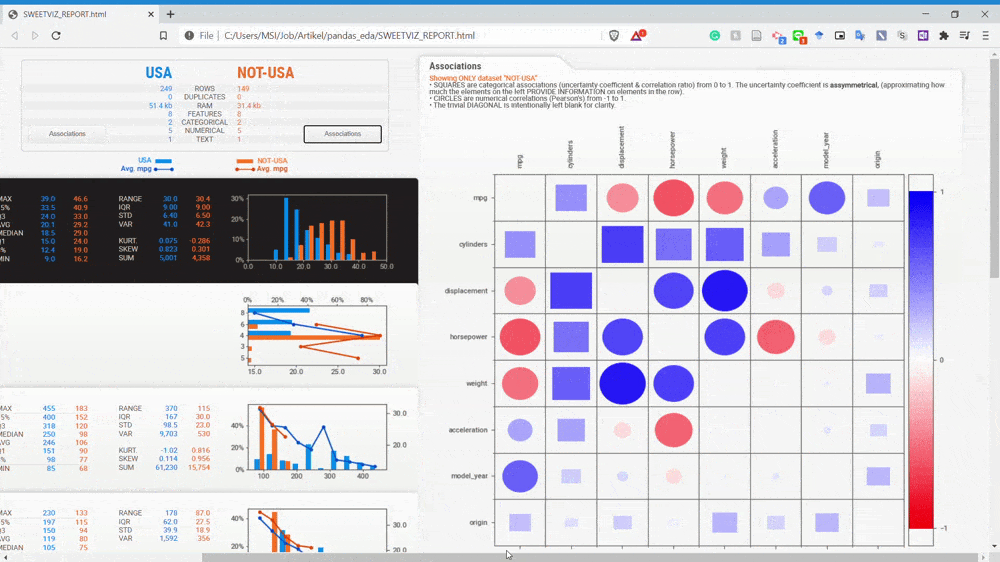
با نگاه کردن به gif فوق میتوانیم به اطلاعات مربوط به روابط میان دو متغیر پی ببریم. برای کسب اطلاعات بیشتر راجع به تحلیل پیوند به صفحه اصلی Sweetviz مراجعه کنید.
به عقیده من، نقاط قوت Swetviz عبارتند از:
- مصورسازی خوب
- درک آسان اطلاعات آماری
- امکان تحلیل دیتاست مقدار هدف
- امکان مقایسه دو دیتاست
Sweetviz امکان مقایسه دیتاست و متغیر را برای کاربر فراهم میکند و به همین دلیل به نظر من، ابزار پیشرفتهتری نسبت به Profiling Pandas است. اما برخی از نقاط ضعف آن عبارتند از:
- عدم رسم نمودارهای میان متغیرها، برای مثال نمودار پراکنش
- گزارش در tab جداگانهای باز میشود
به عقیده من اگر میخواهید دیتاست را با هدف ساخت مدلهای پیشبینیکننده تحلیل و مقایسه کنید، Sweetviz ابزار فوقالعادهای است.
PandaGUI
PandaGUI با پکیجهایی که پیش از این معرفی کردم، تفاوت دارد. در واقع PandaGUI به جای ایجاد و ارائه گزارش، یک دیتافریم GUI ( رابط کاربری گرافیکی) ایجاد میکند و با استفاده از آن میتوانیم دیتافریم Pandas را با دقت بیشتری تحلیل کنیم.
برای شروع باید پکیج PandasGUI را نصب کنیم:
#Installing via pip pip install pandasgui #or if you prefer directly from the source pip install git+https://github.com/adamerose/pandasgui.git
برای ایجاد دیتافریم GUI باید کد مقابل را اجرا کنیم:
from pandasgui import show #Deploy the GUI of the mpg dataset gui = show(mpg)
GUI باید به صورت مجزا به ما نشان داده شود.

در این GUI میتوانید عملیاتهایی انجام دهید. برای نمونه میتوان به فیلتر کردن، اطلاعات آماری، ایجاد نمودار میان متغیرها و تغییر شکل دادهها اشاره کرد.
و میتوانید تَب (tab) را drag کنید تا متناسب با نیازهایتان باشد. به GIF مقابل نگاه کنید:

حالا بیایید ویژگیهای این ابزار را با دقت بیشتری بررسی کنیم. ابتدا ویژگی فیلتر کردن دادهها را بررسی میکنیم.

برای فیلتر کردن دادهها با استفاده از PandasGUI لازم است همزمان با اینکه آن را در دیتافریم Pandas مینویسم، آن را query کنیم.
به مثال فوق نگاه کنید: من query، model_year > 72 را نوشتهام. نتیجه آن یک query است که کادر مقابل آن تیک خورده است. اگر نمیخواهید دادهها را فیلتر کنید، فقط کافی است تیک مقابل کادر آن را بردارید.
اگر هنگام نوشتن query اشتباه کنید، چه؟ خیلی ساده است، فقط باید بر روی query دو بار کلیک کنید و مجدداً آن را بنویسید.
حالا تَب Statistics را بررسی میکنیم.

اگر اطلاعات آماری به دست آمده از این GUI را با اطلاعات آماری به دست آمده از پکیج قبلی مقایسه کنیم، متوجه میشویم که اطلاعات این GUI بسیار کمتر از دو پکیج قبلی است. با این حال، این tab اطلاعات پایهای از دیتاست در اختیار ما میگذارد.
البته به یاد داشته باشید، هر فیلتری که قبلاً انجام دادهاید، بر روی فعالیت بعدی که در tab دیگری انجام میدهید نیز اعمال میشود، پس تیک تمامی فیلترهایی که به آنها نیاز ندارید را بردارید.
Tab بعدی Grapher یا ترسیم GUI است. به عقیده من نقطه قوت PandasGUI این tab است. به GIF مقابل نگاه کنید:

همانگونه که در GIF بالا مشاهده میکنید، برای رسم یک نمودار فقط باید متغیرهای مورد نیاز را drag و drop کنید. به دلیل اینکه منابع ترسیم نمودار به پکیج plotly وابسته هستند، برای پیدا کردن منودار باید مکاننما را به سمت نمودار ببریم.
و آخرین تَب، تب reshaper است. در این تب میتوانیم با ایجاد یک pivot table جدید و یا melt کردن دیتاست، عملیات reshape را انجام دهیم.
همانگونه که در تصویر مقابل مشاهده میکنید، توابع pivot و melt منجر به ایجاد یک جدول جدید میشوند.

علاوه بر این میتوانید دادههایی که فیلتر کردید را بارگذاری کنید و یا آنها به یک فایل CSV تبدیل کنید. برای انجام این کار باید بر روی گزینه Import در بخش Edit کلیک کنید.
اگر میخواهید یک فایل CSV جدید به PandasGUI صادر کنید، باید بر روی گزینه Export کلیک کنید.

به عقیده من نقاط قوت PandasGUI عبارتند از:
- امکان drag و drop
- فیلتر آسان query
- رسم سریع نمودار
و نقاط ضعف آن هم عبارتند از:
- اطلاعات آماری کمی در اختیار ما میگذارد
- هیچ گزارشی به صورت خودکار ایجاد نمیشود
به عقیده من PnadasGUI، پکیج فوقالعادهای است، به ویژه برای افرادی که قصد دارند به روش خودشان دادهها را تحلیل کنند. این پکیج به شما کمک میکند به طور دقیق و کامل دادهها را تحلیل کنید.
به عقیده من، هدف PandasGUI ایجاد گزارش به صورت خودکار نیست؛ هدف این ابزار این است که ما به روش خودمان دادهها را تحلیل کنیم.
نتیجهگیری
Pandas Profiling، Sweetviz و PandasGUI پکیجهای فوقالعادهای هستند که با هدف تسهیل EDA توسعه داده شدهاند. هر کدام از این پکیجهای نقاط ضعف و قوتی دارند و در موقعیتهای متفاوتی کاربرد دارند. به عقیده من:
- Pandas Profiling برای تحلیل سریع یک متغیر مناسب است،
- Sweetviz برای مقایسه دیتاست و مقایسه آن با ویژگی هدف مناسب است،
- PandasGUI برای تحلیل جامع و کامل با قابلیت drag و drop کردن به صورت دستی مناسب است.