
مقدمه ای بر هدوپ راه حلی برای مسئله کلان داده
 تیم تحریریه
تیم تحریریه- ۲۵ آبان ۱۴۰۰
به مقدمه «کلان داده هدوپ» خوش آمدید. میخواهیم در مقاله حاضر درباره آپاچی هدوپ و مسائلی را که کلان داده با خود به همراه میآورد، بحث کنیم. نقش آپاچی هدوپ در حل این مسائل، چارچوب آپاچی هدوپ و کارکرد آن نیز بررسی خواهد شد.

نکاتی درباره کلان داده
بر اساس تخمینها، حدود 90 درصد دادههای جهان تنها در دو سال اخیر ایجاد شده است. علاوه بر این، 80 درصد دادهها سازماندهی نشده و یا در ساختارهای گوناگون قابل دسترس هستند. این عامل باعث دشوار شدنِ فرایند تحلیل شده است. اکنون، از میزان دادههای تولید شده مطلع هستید. این حجم بزرگ از داده چالشهای بزرگی را به همراه دارد. چالشهای بزرگتر زمانی به وجود میآیند که این دادهها بدون ساختار باشند. دادهها میتوانند حاوی تصویر، ویدئو، موارد ضبط شدۀ از حسگرها و جزئیات مسیریابی GPS باشند.
این دادهها نیاز به ساختاربندی دارند. سیستمهای سنتی قابلیت کار با دادههای ساختاریافته را دارند، اما توان مدیریت چنین حجم بزرگی از دادههای بدون ساختار را ندارند. شاید این پرسش به ذهنتان خطور کند که چرا باید این دادهها را ذخیره و پردازش کرد؟ چه هدفی پشت این کار قرار دارد؟
[irp posts=”19713″]پاسخ این است که این دادهها برای اتخاذ تصمیمهای هوشمندانهتر ضروری هستند. پیشبینیِ کسبوکار چیز تازهای نیست. این کار پیشتر نیز انجام شده است، اما با دادههای کمتر. کسبوکارها باید از این دادهها استفاده کرده و تصمیمهای هوشمندانهتری بگیرند. از جمله این تصمیمها میتوان به پیشبینیِ اولویتهای مشتریان برای پیشگیری از کلاهبرداری اشاره کرد. متخصصان در هر حوزهای دلایل خاص خود را برای تجزیه و تحلیل این دادهها دارند.
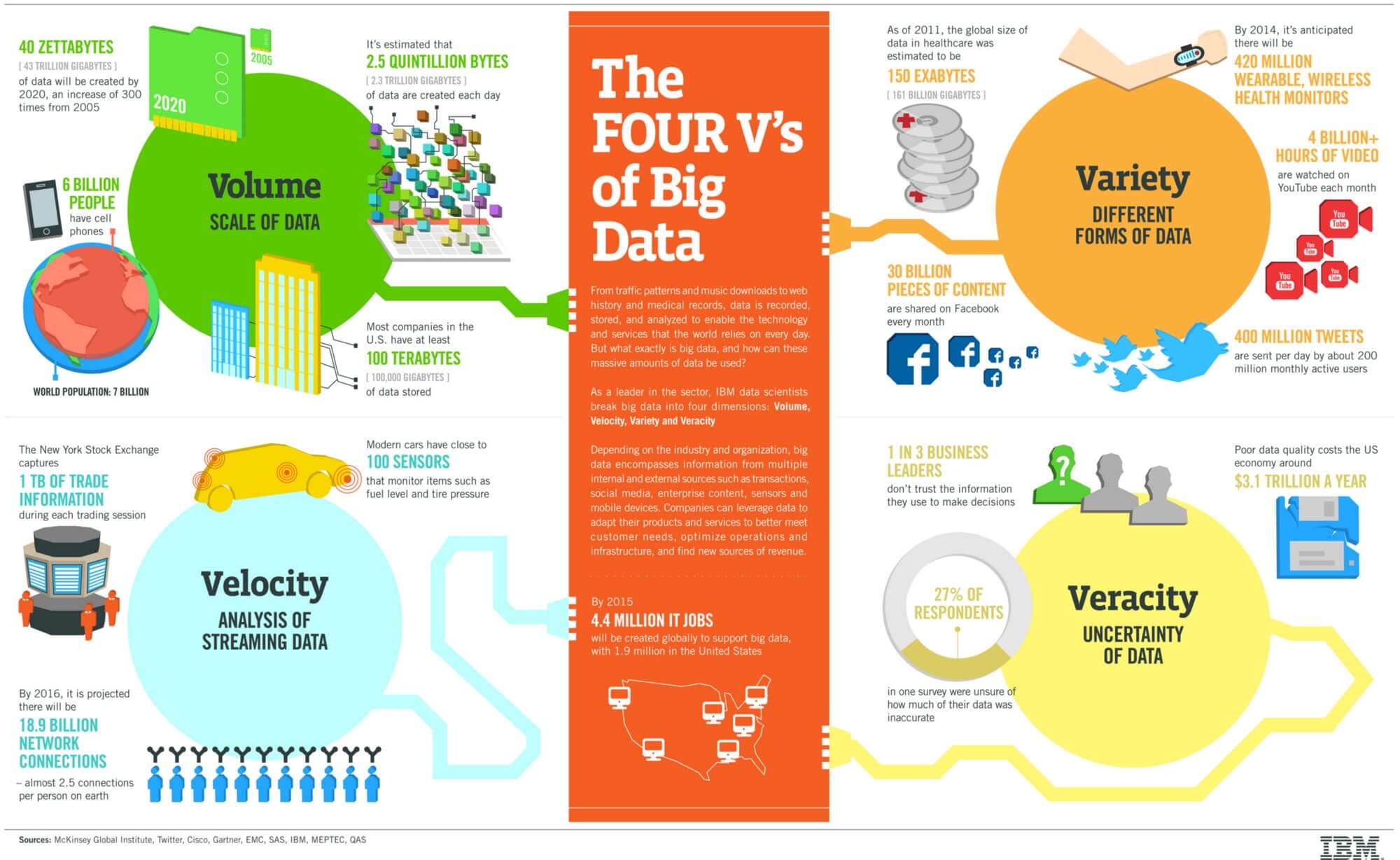
خصوصیات سیستمهای کلان داده
وقتی به این نتیجه رسیدید که پروژهتان به سیستم کلان داده نیاز دارد، دادههای خود را بررسی کرده و خصوصیات آن را در نظر بگیرید. این نکتهها در صنعت داده بزرگ «4 V» نامیده میشوند.
حجم Volume
دادههایی نظیر دادههای روزانه شبکههای اجتماعی, طغیان دادههای کاربران فروشگاههای الکترونیکی و همچنین دادههای حسگرهای الکترونیکی (که به صورت میکروثانیه ثبت میشود) از جمله مواردی هستند که نشان میدهند این صنعت با حجم عظیمی از داده روبروست. اگر نحوه کار با آنها را بلد باشید، مزیت بزرگی خواهید داشت.
تنوع Variety
در گذشته (از آنجا که دادهها مانند امروز خیلی حجیم نبودند) امکان آن وجود داشت که دادهها به صورت ساختاریافته در جداول SQL جمعآوری شوند. اما امروزه، 90 درصد دادههای تولید شده بدون ساختار هستند. این دادهها اَشکال و انواع گوناگونی دارند؛ از دادههای زمینشناسی منطقه گرفته تا توئیتها و دادههای مجازی مثل تصاویر و فیلمها. آیا این دادهها همواره به صورت ساختاریافته قابل دسترس هستند یا بدون ساختاراند یا نیمه ساختیافتهاند؟
[irp posts=”7776″]سرعت Velocity
کاربران سراسر جهان هر دقیقه از روز حدود 200 ساعت فیلم در یوتیوب بارگذاری میکنند، 300.000 توئیت ارسال میکنند و بیش از 200 میلیون ایمیل میفرستند. این آمار به دلیل افزایش سرعت اینترنت روند صعودی به خود گرفته است. پس چه آیندهای در انتظار دادهها و سرعت انتشار دادهها است؟
صحت Veracity
این مورد به نامعلوم بودنِ دادههایی که بازاریابها به آنها دسترسی دارند، مربوط میشود. «صحت» همچنین میتواند به تغییرپذیریِ جریانهای دادهای که قابلیت تغییر دارند اشاره کند. در این صورت، شاید سازمانها برای ارائه واکنشِ سریع و مناسب به مشکل بخورند.
شرکت گوگل چگونه مسئله کلان داده را حل کرد؟
در پی انقلاب صنعت اینترنت، شرکت گوگل نخستین بار به دلیل دادههای موتور جستجوی خود به این مسئله برخورد کرد. متخصصان گوگل این مسئله را به طور هوشمندانه با استفاده از نظریه پردازش موازی حل کردند. آنها الگوریتمی به نام MapReduce طراحی کردند. این الگوریتم کار را به بخشهای کوچک توزیع کرده و آنها را به رایانههای زیادی که در شبکه به هم ملحق شدهاند، اختصاص میدهد. سپس همه رویدادها را ادغام میکند تا آخرین دیتاست را به وجود آورد.

این کار زمانی منطقی به نظر میرسد که بدانید عملیات بارگذاری و ذخیرهسازی I/O پرهزینهترین عملیات در فرایند پردازش داده است. سیستمهای پایگاه دادهای از قدیم دادهها را در یک ماشین ذخیره میکردند. اگر به داده نیاز داشته باشید، به آن سیستمها در قالب SQL فرمان میدهید. این سیستمها داده را از مراکز ذخیرهسازی دریافت کرده و آن را در بخش حافظه محلی قرار میدهند؛ سپس دادهها را پردازش کرده و آن را به کاربران ارسال میکنند.
[irp posts=”10886″]میتوانید این کار را با دادههای محدود و ظرفیت پردازش محدود انجام دهید. اما وقتی با کلان داده مواجه میشوید، نمیتوانید همه دادهها را در یک ماشین جمع کنید. باید دادهها را در چند رایانه ذخیره کنید (شاید هزاران دستگاه). وقتی میخواهید جستجو کنید یا استعلام بگیرید، به دلیل هزینۀ بالای عملیات بارگذاری و ذخیرهسازی I/O نمیتوانید دادهها را در یک جا جمع کنید. بنابراین، الگوریتم MapReduce در همه گرهها جستجوی کاربر را بررسی کرده و سپس نتیجه نهایی را ارائه میکند. این روش دو مزیت به همراه دارد؛ اولی هزینه پایین (به دلیل پایین بودن نوسان داده) و دومی زمان کمتر.

مقدمهای درباره هدوپ
هدوپ از فرصتهایی که کلان داده به همراه داشته به نفع خود استفاده کرده و در پی غلبه بر چالشها است.
هدوپ چیست؟
در واقع هدوپ به یک چارچوب برنامهنویسی منبع بازِ مبتنی بر جاوا گفته میشود که مجموعهدادههای بزرگ را در یک محیط رایانش توزیعشده پردازش میکند. این چارچوب بر پایه سیستم فایل گوگل (GFS) قرار دارد.
چرا هدوپ ؟
هدوپ نرمافزارهای کمی در سیستمهای توزیع شده اجرا کرده و قابلیت کار با هزاران گره که حاوی چندین پِتا بایت اطلاعات هستند را دارد. این چارچوب دارای یک سیستم فایل توزیعشده به نام «HDFS» است که امکانِ انتقال سریع داده را در گرهها فراهم میکند.
چارچوب هدوپ
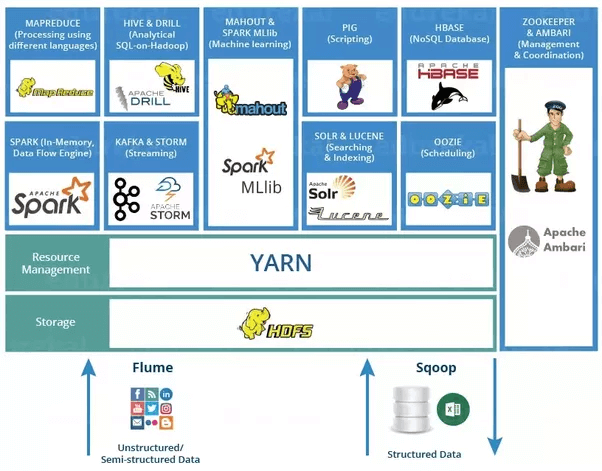
سیستم فایل توزیعشدۀ هدوپ(HDFS)
این سیستم یک لایه ذخیرهسازی برای هدوپ فراهم کرده و ابزار خوبی برای پردازش و ذخیرهسازی توزیعشده به حساب میآید. این سیستم در حین ذخیره شدن دادهها، توزیع شده و سپس به کارش ادامه میدهد. HDFS یک رابط خط فرمان برای برهمکنش با هدوپ دارد و به دادههای سیستم فایل دسترسی میدهد. بنابراین، صحت و دسترسی فایل را تضمین میسازد.
Hbase
این ابزار به ذخیرهسازی داده در HDFS کمک میکند و یک پایگاه داده NoSQL یا پایگاه داده غیرارتباطی به شمار میرود. HBase عمدتاً زمانی مورد استفاده قرار میگیرد که نیاز به دسترسی تصادفی (خواندن/نوشتن) به کلان داده داشته باشید. افزون بر این، از حجم بالای داده و خروجیِ بالا پشتیبانی میکند. در HBase، یک جدول میتواند هزاران ستون داشته باشد. تا به اینجای کار، درباره چگونگی توزیع و ذخیرهسازی داده، چگونگی استفاده مناسب از این دادهها و انتقال آن به HDFS بحث کردیم. ابزاری به نام Sqoop مسئولیتِ انجام این کار را بر عهده دارد.
[irp posts=”3782″]Sqoop
Sqoop ابزاری برای انتقال داده میان هدوپ و NoSQL است و میتواند دادهها را از پایگاههای دادهای مثل Oracle و MySQL به HDFS وارد کرده و از HDFS به پایگاه داده ارتباطی منتقل کند. اگر میخواهید از دادههایی مثل دادههای جمعآوری شده از حسگرها یا لاگهای سیستمی استفاده کنید، میتوانید Flume را انتخاب کنید.
Flume
این ابزار برای جمعآوری داده و انتقال آن به HDFS مورد استفاده قرار میگیرد. پس از اینکه دادهها به HDFS انتقال یافت، پردازش میشود. چارچوبی که به پردازش دادهها میپردازد، SPARK نام دارد.
SPARK
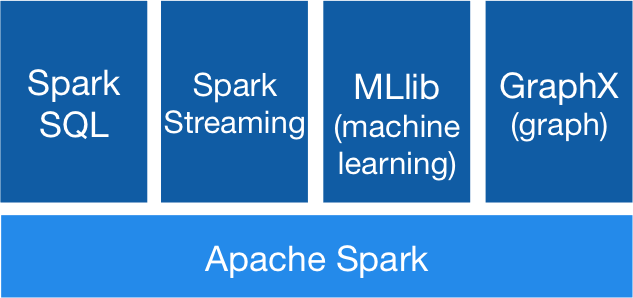
spark یک چارچوب رایانش خوشهای منبع باز می باشد. عملکرد این چارچوب 100 برابر سریعتر از MapReduce است. SPARK در خوشه هدوپ به اجرا درآمده و دادهها را در HDFS پردازش میکند و توان پشتیبانی از طیف وسیعی از ججم کار را دارد. اجزای اصلی Spark در زیر توضیح داده شده است:
Hadoop MapReduce
چارچوب دیگری برای پردازش دادهها است. موتور پردازش اصلی همان هدوپ است که عمدتا بر اساس جاوا عمل میکند. همچنین مانند Hive و Pig از مدل کاری MapReduce استفاده میکند زیرا این معماری از متداولترین و پرکاربردترین چارچوبها به شمار میآید. پس از اتمام پردازش داده، از سیستم جریان داده منبع باز Pig برای کارهای تحلیلی استفاده میکند.
Pig
یک سیستم جریان داده منبع باز که عمدتاً برای کارهای دادهکاوی تحلیلی استفاده میشود. Pig به برنامه نویس کمک میکند تا در نوشتن کد MapReduce صرفهجویی کند. در دستورات واکشی اطلاعات شبکه های بیسیم ad-hoc مانند filter و join نوشتن نگاشتها و کاهشها، گردآوری و بستهبندی کد که فرایندی بسیار زمان بری است می توان از Pig استفاده کرد که یکی از ابزارهای جایگزین برای نوشتن کد Map-Reduce است. امکان استفاده از Impala برای تجزیه و تحلیل دادهها نیز وجود دارد.
Impala
Impala یک موتور SQL قوی است که در خوشه هدوپ اجرا میشود. این سیستم برای تحلیل با رابط بسیار مناسب است. تاخیر آن در حد چند میلیثانیه اندازهگیری شده است. Impala از sequel پشتیبانی میکند. بنابراین، دادهها در HDFS به صورت جدول پایگاه داده مدلسازی میشوند. شما میتوانید تحلیل داده را با استفاده از Hive نیز انجام دهید.
Hive
Hive یک پوشش جداساز در بالای هدوپ است و شباهت زیادی به Impala دارد. با این حال، در پردازش داده و عملیات ETL مورد استفاده قرار میگیرد. Impala برای جستجوی ad-hoc مناسب است، در حالیکه hive جستجو را با Map-Reduce انجام میدهد. البته کاربران مجبور نیستند هیچ کدی را در Map-Reduce بنویسند. Hive عملکرد خوبی در دادههای ساختاریافته بر جای میگذارد. پس از اینکه دادههای بررسی شده در دسترس کاربر قرار میگیرد و از جستجوی داده پشتیبانی میشود، ادامه کار با استفاده از Cloudera Search انجام میشود.
Cloudera Search
این ابزار به کاربران غیرمتخصص این امکان را میدهد تا به جستجو و بررسی دادههای ذخیره شده در هدوپ یا HBase بپردازند. در Cloudera، کاربران به مهارت برنامهنویسی یا SQL نیاز ندارند تا از جستجوی Cloudera استفاده کنند زیرا یک رابط تمام متنیِ ساده برای جستجو فراهم میکند و یک پلتفرم پردازش داده ترکیبی به حساب میآید.
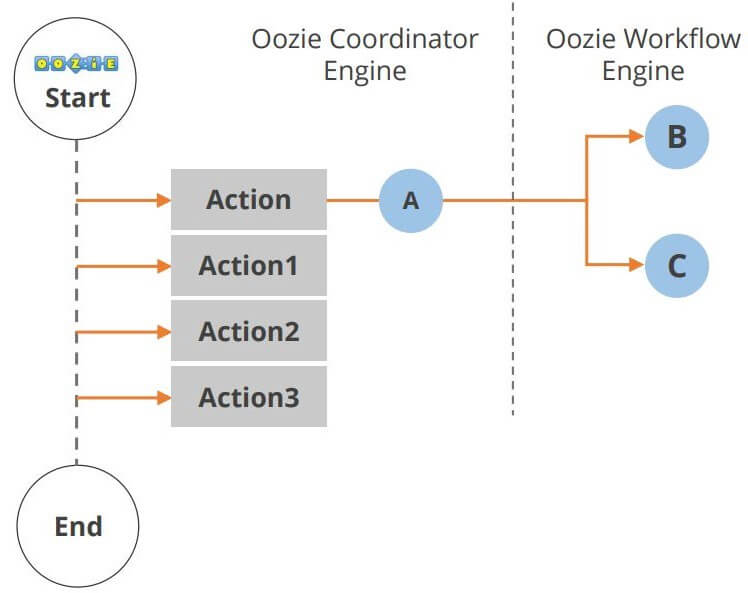
Oozie
Oozie یک گردشکار یا روش هماهنگی برای مدیریت کارهای هدوپ است. چرخه عمر Oozie در نمودار زیر نشان داده شده است.
Hue
Hue مخفف «تجربه کاربری هدوپ» است و یک رابط وب منبع باز برای تحلیل دادهها با هدوپ است. شما میتوانید کارهای زیر را با استفاده از Hue انجام دهید.
• 1. بارگذاری و بررسی داده
• 2. جستجو و واکشی جدول در Hive و Impala
• 3. انجام کارهای Spark و Pig
• 4. دادههای جستجوی گردش کار
Hue استفاده از هدوپ را ممکن کرده و آن را در دسترس کاربران قرار میدهد. همچنین، یک ویراستار برای Hive، Impala، MySQL، Oracle، Postgre SQL، Spark SQL و Solar SQL عرضه میکند.
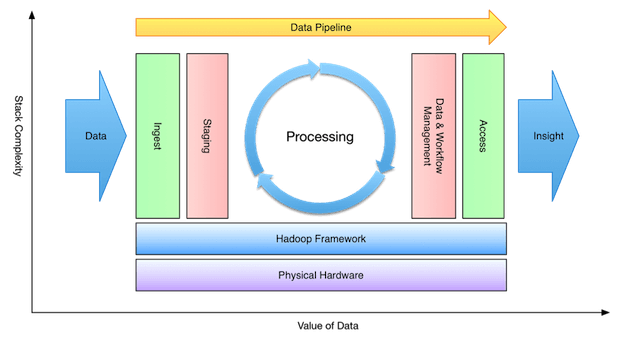
مرحله اول روال کاری تغذیه دادن دادهها نام دارد و در آن دادهها از منابع گوناگونی مثل سیستمهای پایگاه دادهای ارتباطی یا فایلهای محلی به هدوپ منتقل میشوند. همانطور که پیشتر ذکر شد، sqoop دادهها را از RDMS به HDFS انتقال میدهد.
مرحله دوم پردازش نام دارد. در این مرحله، دادهها ذخیره و پردازش میشوند. در بخشهای پیشینِ مقاله به این مورد اشاره شد که اطلاعاتِ ذخیرهشده در سیستم فایل توزیعشدۀ HDFS و داده توزیعشده HBase حائز اهمیت هستند. Spark و MapReduce مسئولیت پردازش داده را بر عهده دارند.
مرحله سوم مرحله تجزیه و تحلیل نام دارد. چارچوبهای پردازش از قبیل Pig، Hive و Impala برای تفسیر دادهها به کار برده میشوند. مرحله چهارم به ارزیابی اختصاص دارد و با ابزاری مثل Hue و Cloudera Search انجام میشود. در این مرحله، دادههای تحلیل شده در اختیار کاربران قرار میگیرد. اکنون شما اطلاعات پایه خوبی در خصوص چارچوب هدوپ به دست آوردهاید و میتوانید روی مهارتهایتان بیشتر کار کنید تا به کارشناس در حوزه مهندسی داده تبدیل شوید.





