هوش مصنوعی Meta، سیستم ترجمه جهانی را دگرگون کرد
 تیم تحریریه
تیم تحریریه- ۹ آذر ۱۴۰۰
فلش زیرِ لوگوی شرکت آمازون، معنای سادهای دارد؛ بهطوری که شما میتوانید به راحتی محصولاتتان، از A تا Z را از یک سامانه واحد، تهیه کنید. قبول دارید اینگونه کار شما ساده میشود؟ همین امر درباره سیستم ترجمه هم صدق میکند (تولید متن از یک زبان به زبانی دیگر). برای رسیدن به این هدف، هوش مصنوعی Meta دستاورد جدیدی را رونمایی کرده است. یک مدل چندزبانه جدید که بر روی 10 جفت از 14 جفت زبانی، بهتر از مدلهای دوزبانه بسیار پیشرفته موجود، عمل میکند. موفقیت این مدل به حدی بود که توانست جایزه همایش ترجمه ماشینی (WMT) را که رقابتی معتبر در زمینه ترجمه ماشینی است، از آن خود کند. به این ترتیب، میتوان به جرئت گفت این مدل، راهی به سوی ساخت سیستم ترجمه جهانی را به همگان معرفی کرده است.
محدودیتها
هدف نهایی رشته ترجمه ماشینی (MT)، ایجاد سیستم ترجمه جهانی است که به تمام افراد اجازه میدهد، به اطلاعات دسترسی داشته باشند و به طرز کارآمدتری، ارتباط برقرار کنند. با اینحال، برای اینکه این رؤیا در آینده به حقیقت بپیوندد، باید برخی از محدودیتهای اساسی که فعلاً وجود دارند، حل شوند.
[irp posts=”20237″]درحالحاضر، بسیاری از سیستمهای ترجمه ماشینی مدرن، متکی بر مدلهای دوزبانه هستند. این مدلها به تعداد زیادی نمونه برچسبخورده برای هر جفت زبانی و هر تکلیفی نیاز دارند. متأسفانه زبانهای زیادی در جهان وجود دارند که اطلاعات لازم در خصوص آموزش آنها کم است، مثل زبانهای ایسلندی و هوسا. این کمبودها، جهتگیریهای خاص به سمتوسوی هدف را بیفایده میکنند. همچنین، پیچیدگی زیاد آن زبانها، افزودن حالتهای موجود به نرمافزارهای کاربردی برای سامانهها را دشوار میسازد؛ مثلاً سامانهای مانند فیسبوک که روزانه میلیاردها کاربر به صدها زبان در آن مطلب منتشر میکنند.
هوش مصنوعی Meta؛ ابزار نجاتبخش
به گفته گروه هوش مصنوعی Meta، رشته ترجمه ماشینی، نیازمند است که از مدلهای دوزبانه به سمت ترجمه چندزبانه تغییر جهت بدهد؛ به عبارت دقیقتر، چیزی که یک مدل واحد میتواند چندین زبان را همزمان ترجمه کند. به علاوه، رفتن به سمت مدل چندزبانه بهتر، هم به نفع زبانهایی است که دارای منابع زیاد هستند و هم به نفع زبانهایی است که منابع کمی دارند؛ زیرا این مدلها ساده، مقیاسپذیر و کارآمدند. در واقع، هدف نهایی، ایجاد سیستم ترجمه جهانی است که امکان دسترسی همگان به اطلاعات و برقراری کارآمدتر ارتباط را فراهم میکند.
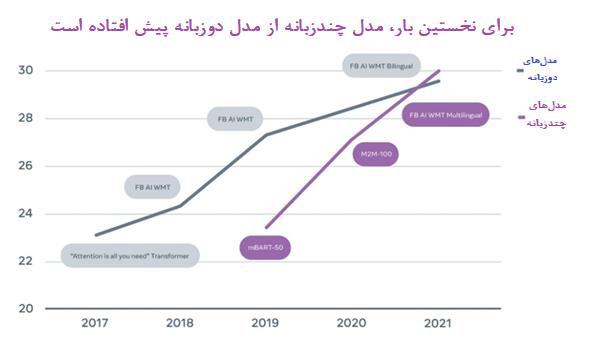
سال گذشته، هوش مصنوعی فیسبوک (که اکنون Meta نام دارد) مدلM2M-100 را به عنوان اولین مدل چندزبانه به بازار معرفی کرد که بدون اتکا به دادههای انگلیسیمحور، هر جفت زبانی را از میان 100 زبان، ترجمه میکرد. این گروه، راهبردهای دادهکاوی متفاوتی را به کار بردند، تا مجموعهدادهای با 5/7 میلیارد جمله از 100 زبان را به عنوان داده ترجمه، آماده سازند.
پژوهشگران انواع راهبردهای مقیاسبندی را به کار بردند، تا مدلی جهانی، با 15 میلیارد پارامتر ایجاد کنند. این مدل، شامل دادههایی از زبانهای مرتبط است و زبانهایی با خط و صرف متنوع را در بر میگیرد و برای زبانهایی با منابع کم نیز کارآمد است؛ اما عملکرد بالای خود را درباره زبانهایی که منابع زیادی دارند، از دست میدهد.
بر اساس مدل قبلی، گروه پژوهشی توانست سه پیشرفت جدید را در زمینههای زیر ارائه دهد:
– دادهکاوی در مقیاس کلان
– مقیاسبندی گنجایش مدل
– زیرساخت کارآمدتر
دو سیستم چندزبانه
در واقع، گروه پژوهشی، دو سیستم چندزبانه ساخت، تا ترجمه هر زبانی به انگلیسی و برعکس را به مدل WMT 2021 آموزش دهد. آنها از روشهای دادهکاوی موازی مانند CCMatrix استفاده کردند که شرکت آن ادعا میکند، بزرگترین مجموعهداده مبتنی بر وب و پیکره دومتنی با کیفیت بالا، برای مدلهای آموزش ترجمه است. مجموعهداده CCMatrix 50 بار بزرگتر از پیکرهWikiMatrix است که فیسبوک قبلاً ایجاد کرده و شامل 5/4 میلیاد عبارت موازی در 576 جفت زبانی است که از اطلاعات موجود در مجموعهداده عمومی CommonCrawlاستخراج شده است.
به علاوه، گنجایش مدل از 15 میلیون پارامتر به 52 میلیون، افزایش یافته است. نکته جالب اینجاست که با اضافه کردن یک ابزار ذخیرهسازی حافظه GPU به نام Fully Sharded Data-Parallel که ساخته خود هوش مصنوعی Meta بود، آموزش در مقیاس کلان در این مدل، 5 برابر سریعتر از مدلهای قبلی است.
[irp posts=”19860″]همچنین باید توجه داشت که اندازه مدل مقیاسبندی، اغلب هزینههای محاسباتی را بالا میبرد. گروه پژوهشی ادعا میکند که برای غلبه بر این مشکل، از معماری ترنسفرمری استفاده کردهاند که در آن، به صورت یکیدرمیان در لایههای ترنسفرمر، یک بلوک Feedforward قرار گرفته است. این لایهها در رمزگذار و رمزگشا با لایه Sparsely Mixture-of-Experts که دریچه top-2 دارد، جایگزین میشوند. در نتیجه این امر، به ازای هر توالی ورودی، فقط امکان به کار رفتن زیرمجموعهای از تمام پارامترهای این مدل وجود دارد.
ترجمه ماشینی، در رفع موانع، توانسته است پیشرفت قابلملاحظهای داشته باشد که البته باید گفت بیشتر بر تعداد کمی از زبانهای رایج، متمرکز شده است. در مجموع، آخرین مانع بزرگ ترجمه ماشینی و بزرگترین چالش حلنشده این رشته، ترجمه زبانهایی است که دارای منابع کمی هستند.
جدیدترین اخبار هوش مصنوعی ایران و جهان را با هوشیو دنبال کنید