کنترل نسخه ابزاری قدرتمند در داده کاوی برای کنترل تغییرات دیتاست ها و مدل های یادگیری ماشین
 تیم تحریریه
تیم تحریریه- ۲۱ اردیبهشت ۱۴۰۱
بیتردید، GIT هدف غاییِ سیستمهای کنترل نسخه است. GIT عملکرد بسیار خوبی در تهیه نسخههای مختلف از کدهای منبع دارد. اما برخلاف مهندسی نرمافزار، پروژههای «علم داده» دارای فایلهای بسیار حجیمی مثل دیتاست، فایلهای مدل آموزش دیده، رمزگشایی برچسب و غیره هستند. اندازه این دست از فایلها میتواند تا چند گیگابایت هم افزایش یابد. بنابراین، امکان ردیابی آنها با استفاده از GIT وجود ندارد.
راهحل چیست؟
متخصصان ابزاری تحت عنوان DVC ساختهاند که نقش مهمی در تهیه نسخههای مختلف از فایلهای دادهای بزرگ ایفا میکند. این کار تا حد زیادی به نحوه تهیه نسخههای مختلف از فایلهای کد منبع با استفاده از GIT شباهت دارد. همچنین، DVC عملکرد بسیار خوبی در کنار GIT از خود نشان میدهد.

اکثر مواقع از ردیابی دیتاستها و مدلها در روند کار «علم داده» چشمپوشی میشود. اکنون DVC به یاریمان شتافته تا همه موارد را ردیابی کنیم. این کار میتواند بهرهوریِ هر چه بیشتر دانشمندان داده را به ارمغان آورد زیرا آنها را از ردیابی دستی برای حصول اهدافشان بینیاز میکند. افزون بر این، زمان زیادی در پردازش دادهها و ساخت مدلها صرفهجویی میشود.
مزایای DVC
- کنترل نسخه آسان فایلهای بزرگ- تسهیل روند استفاده مجدد و قابلیت تکثیر
- سازگار با GIT
- پشتیبانی از GCS/S3/Azure و بسیاری دیگر از شبکهها برای ذخیره کردن داده
اکنون زمانِ آغاز به کار فرا رسیده است.
نصب
فرایند نصب با فرمان زیر خیلی آسان است:
pip install dvc
برای انجام فرایند نصب، باید dvc را در پایانه تایپ کنید. ممکن است چند گزینه فرمان DVC مشاهده کنید، که نشان میدهد در مسیر درستی قرار گرفته اید. در همین راستا، منبع dvc-sample به همراه ساختار پروژه زیر مورد استفاده قرار میگیرد تا شما خوانندگان بینش دقیقتری به این موضوع پیدا کنید:
dvc-sample ├── artifacts │ ├── dataset.csv │ └── model.model └── src ├── preprocessor.py └── trainer.py
منبع ساختار سادهای دارد؛ اسکریپتهای پایتون در پوشهای به نام src ذخیره شده و پوشه artifacts حاوی کلیه دیتاستها، فایلهای مدل و بقیه موارد میباشد. این فایلها به دلیل اندازه بزرگی که دارند، باید با dvc کنترل شوند.
راهاندازی dvc
اولین کاری که باید انجام دهیم، اجرای dvc در پوشه اصلی پروژه است. این کار با فرمان زیر انجام میشود.
dvc init
این کار شباهت زیادی به git init دارد؛ با این تفاوت که باید آن را فقط یکبار در حین اجرای پروژه انجام دهیم. حال، dvc به پروژه افزوده شده است. اما کماکان به تصریح دقیق پوشهها نیاز داریم. بدین منظور، از dvc برای کنترل نسخه استفاده میکنیم. در این مثال، میخواهیم نسخههای مختلفی از پوشه artifacts تهیه کنیم. این کار با استفاده از فرمان زیر اجرا میشود:
dvc add artifacts
با اجرای فرمان فوق، دو کار انجام شد:
1. تصریح پوشه مورد نظر برای ردیابی، با استفاده از dvc (ایجاد فایلartifacts.dvc )
2. افزودن همان فایل به .gitignore (ردیابی پوشه با git، دیگر در دستور کارمان نیست.)
پس از اجرای این فرمان dvc به ما میگوید که دو فایل بالا را به git اضافه کنیم.

حالا به کمک فرمان زیر، این فایلها را به git اضافه میکنیم:
git add . git commit -m 'Added dvc files'
توجه: در این بخش باید به یک نکته مهم توجه داشته باشید: مِتافایلهای پوشه artifacts با git و فایلهای artifacts با dvc کنترل نسخه میشوند. در این مورد، artifacts.dvc با git و محتوای درون پوشه artifacts با dvc ردیابی میشود. شاید این موضوع در حال حاضر برایتان چندان شفاف نباشد، اما نگران نباشید. در بخشهای بعد، نگاه دقیقتری به آن خواهیم انداخت.
حال، پوشه مورد نظرمان را به منظور ردیابی با dvc اضافه کردهایم. همچنین، dvc نیز به پروژه افزوده شده است.
حالا بیایید نگاهی به روند کاری یادگیری ماشین بیندازیم:
1. یک دیتاست داریم.
2. عملیات پردازش در دیتاست فوق با استفاده از اسکریپتهای پایتون انجام میشود.
3. مدل را با استفاده از اسکریپتهای پایتون آموزش میدهیم.
4. حال یک فایل مدل داریم که خروجیِ مرحله سوم است.
مورد فوق یک فرایند تکراری است زیرا چند دیتاست برای ساخت و آموزشِ مدلهای گوناگون یادگیری ماشین در اختیار داریم. مجموعه متفاوتی از گردش کار پیشپردازش نیز وجود دارد. این همان چیزی است که میخواهیم کنترل نسخه در آن پیادهسازی شود؛ با این کار، زمینه برای تکثیر آسانِ نسخههای قبلی فراهم میشود. در سناریوی فوق، مراحل 2 و 3 با استفاده از git ردیابی میشوند زیرا اینها فایلهای کد کوچکتری هستند. مراحل 1 و 4 نیز با dvc ردیابی میشوند زیرا این مراحل اندازه بسیار بزرگتری دارند.
برای اینکه دید شفافتری به موضوع داشته باشید، یک بار دیگر به این ساختار نگاه کنید:
dvc-sample ├── artifacts │├── dataset.csv #1 │ └── model.model #4 └── src ├── preprocessor.py #2 └── trainer.py #3
برای سهولت در کار، محتوای هر کدام از چهار فایل بالا، همان نسخهای خواهد بود که به آن تعلق دارند.
فرض کنید نسخه اول اسکریپتهای پیشپردازنده و آموزشی را نوشتهایم. چهار فایل مذکور به شکل زیر خواهند بود:
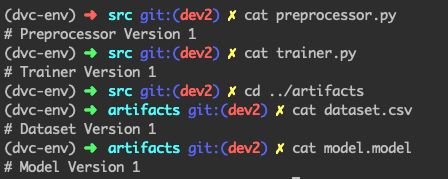
کنترل نسخه فایلهای بزرگ
اکنون باید کدها، فایلهای مدل و دیتاست را اجرا کنیم. این کار در سه مرحله قابل انجام است:
1. تغییرات inartifacts با استفاده از dvc دنبال میشود:
dvc add artifacts/
2. تغییرات موجود در اسکریپت کدها و فایلِ بهروزرسانی شده (artifacts.dvc) با git ردیابی میشود.
git add . git commit -m 'Version 1: scripts and dvc files'
3. این مرحله از پروژه با استفاده از git ، به experiment01 برچسب زده میشود.
git tag -a experiment01 -m 'experiment01'
پس تا اینجای کار موفق شدیم نسخه اول اسکریپتها را به کمک git و dvc ذخیره کنیم. حال، فرض کنید میخواهیم آزمایش جدیدی را ترتیب دهیم. در همین راستا، یک دیتاست متفاوت و چند اسکریپت اصلاح شدۀ دیگر داریم. چهار فایل فوق به این شکل خواهند بود:
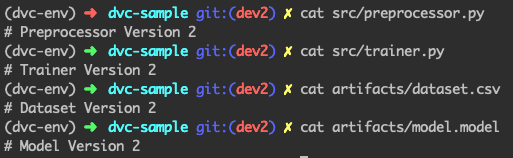
اکنون سه مرحله پیشین را تکرار میکنیم تا نسخه 2 ردیابی شود.
1. تغییرات inartifacts با استفاده از dvc ردیابی میشود:
dvc add artifacts/
2. تغییرات موجود در اسکریپت کدها و فایلِ بهروزرسانی شده (artifacts.dvc) با git ردیابی میشود.
git add . git commit -m 'Version 2: scripts and dvc files'
3. این مرحله از پروژه با استفاده از git ، به experiment02 برچسب زده میشود.
git tag -a experiment02 -m 'experiment02'
تغییر نسخه؛ تکثیر کد و artifacts
اکنون زمان آزمایش واقعی فرا رسیده است. باید ببینیم آیا ممکن است به آسانی سراغ هر نسخهای از دو پوشه رفت یا خیر. برای شروع کار، بگذارید ببینیم وضعیت فعلی پروژه چگونه است:
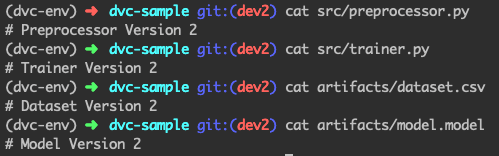
همانطور که از محتوای فایل پیداست، اکنون با نسخه 2 سر و کار داریم. فرض را بر این میگذاریم که نسخه 1 بهتر بود و میخواهیم سراغ نسخه 1 برویم. با چند فرمان ساده این کار قابل انجام است:
باید برچسب experiment01 را بررسی کنیم:
git checkout experiment01
پس از اجرای فرمان زیر، وضعیت پروژه به شکل زیر در میآید:

چیزی متوجه شدید؟
پس میبینید که اسکریپتها به نسخه 1 تغییر یافته است. بسیار عالی! اما artifacts هنوز در نسخه دو است. حال، چون مِتافایل به همان نسخهای برگشته است که میخواستیم، باید کارِ بررسی را با استفاده از dvc انجام دهیم:
dvc checkout
در این شرایط، فایلهایی که تحت پوشه artifacts هستند، تغییر خواهند یافت. پس دوباره به فایلها نگاه کنید:
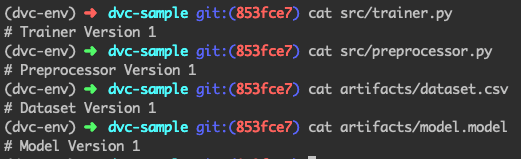
بسیار عالی! موفق شدیم از نسخه 2 به نسخه 1 بازگردیم.
نتیجهگیری
به طور خلاصه میتوان گفت که کار با دو نسخه در این مقاله بررسی شد. حتی اگر چند صد آزمایش انجام دهید، فرایند فوق دقیقاً به همان شکل عمل خواهد کرد. لذا این قابلیت را داریم تا با سرعت بالایی به تکرار فرایندها بپردازیم. DVC ابزار بسیار خوبی برای ارائه نسخههای مختلف از فایلهای بزرگی مثل دیتاستها و فایلهای مدل آموزشدیده است؛ دقیقاً به همان شکل که سورس کد را با استفاده از GIT نسخهبندی میکنیم. این کار باعث صرفهجویی در زمانِ لازم برای پردازش داده و ساخت مدل میشود.