

یادگیری تقویتی چیست؟ هر آنچه باید در مورد این رویکرد بدانید
 تیم تحریریه
تیم تحریریه- ۱۰ بهمن ۱۴۰۰
یادگیری تقویتی یکی از رویکردهای کارآمد و نوینی از یادگیری ماشین است که امروزه توانسته جایگاه خود را در زمینههای مختلفی از زندگی بشر گسترش دهد. بطور کلی، یادگیری تکنیکی است که به عامل تصمیمگیرنده اجازه میدهد تا با نشان دادن عکسالعمل به محیط و تعامل با آن، پاداش کل خود را حداکثر سازد.
یادگیری تقویتی چیست؟
یادگیری تقویتی یکی از روشهای یادگیری ماشین است که در آن، عامل یادگیری پس از ارزیابی هر اقدام، باز خوردی به صورت پاداش و یا جریمه دریافت میکند. درگذشته، این روش اغلب در بازیها (از جمله بازیهای آتاری و ماریو) بهکار گرفته میشد و عملکرد آن در سطح انسان و حتی گاهی فراتر از توانایی ما بود. اما در سالهای اخیر، این الگوریتمهای یادگیری تقویتی درنتیجه ادغام با شبکههای عصبی تکامل پیدا کرده و حال قادر است اعمال پیچیدهتری از جمله حل کردن مسائل را نیز انجام دهد.
امروزه، یادگیری تقویتی با عملکردهای فرابشری، بویژه در دنیای بازیهای کامپیوتری، که از خود نشان دادهاست، تبدیل به یکی از موضوعات به روز و برجسته هوش مصنوعی شده است. در همین راستا در این مقاله، به سازوکار و مفاهیم اصلی یادگیری تقویتی در هوش مصنوعی، الگوریتمها و مواردی جهت آموزش و پیادهسازی آن اشاره میگردد. همچنین یادگیری تقویتی عمیق که تلفیقی از یادگیری تقویتی و شبکههای عصبی عمیق میباشد، نیز مورد بررسی قرار خواهد گرفت.
خواندن مقاله کاربردهای یادگیری تقویتی را با گفته کورای کاواکاغلو که رئیس بخش تحقیقات شرکت دیپمایند است آغاز میکنیم:
«اگر یکی از اهداف ما هوش مصنوعی باشد، این مدل در مرکز آن قرار دارد. یادگیری تقویتی یک چارچوب کلی برای یادگیری مسائلی است که نیاز به تصمیمگیریهای پیدرپی و متوالی دارند. یادگیری عمیق نیز مجموعهای از بهترین الگوریتمها برای یادگیری بازنمایی است. بنایراین، ترکیب این دو مدل بهترین راه موجود برای یادگیری بازنمایی وضعیت بهمنظور حل مسائل چالشبرانگیز در دنیای واقعی است.»
شبکههای عصبی پیچشی (CNN) Convolution Neural Network و شبکههای عصبی بازگشتی (RNN) Recurrent Neural Network بهدلیل کاربردهایی که در بینایی رایانهای Computer Vision (CV) و پردازش زبان طبیعی (NLP) Natural Language Processing دارند، روزبهروز در حوزه کسبوکار محبوبیت بیشتری به دست میآورند.
اما در این میان، اهمیت یادگیری تقویتی (RL) Reinforcement Learning به عنوان چارچوبی برای علم اعصاب محاسباتی و مدلسازی فرآیندهای تصمیمگیری نادیده گرفته شده است و درخصوص نحوه بهکارگیری الگوریتمهای یادگیری تقویتی در صنایع مختلف اطلاعات چندانی دردسترس نیست. علیرغم تمامی انتقاداتی که از الگوریتمهای یادگیری تقویتی میشود، این الگوریتمها میتوانند در حوزه تصمیمگیری کمک زیادی به ما بکنند و به همین دلیل نباید نادیده گرفته شوند.
در بخش اول این مقاله یادگیری تقویتی بهطور کلی معرفی میشود و در بخش دوم، با ذکر مثالهایی از بهکارگیری یادگیری تقویتی، به بررسی کاربردهای آن در حوزههای مختلف میپردازیم. در بخش سوم نیز به مسائلی میپردازیم که باید پیش از بهکارگیری یادگیری تقویتی از آنها آگاه باشید.
در بخش چهارم به آموزههای سایر علوم پرداختهایم. در بخش پنجم درخصوص کاربردها و منافع یادگیری تقویتی در آینده صحبت خواهیم کرد و بخش ششم نیز بخش آخر و نتیجهگیری خواهد بود.
مقدمهای بر یادگیری تقویتی
برای بررسی کاربردهای یادگیری تقویتی لازم است تعریف مشترکی از یادگیری تقویتی داشته باشیم . یادگیری تکنیکی است که به عامل تصمیمگیرنده اجازه میدهد تا با نشان دادن عکسالعمل به محیط و تعامل با آن، پاداش کل خود را حداکثر سازد.
این نوع یادگیری در دنیای یادگیری ماشینی به عنوان یک مدل یادگیری نیمه نظارتی شناخته میشود. یادگیری تقویتی معمولاً در قالب فرآیند تصمیمگیری مارکوف Markov Decision Process (MDP) مدلسازی میشود.
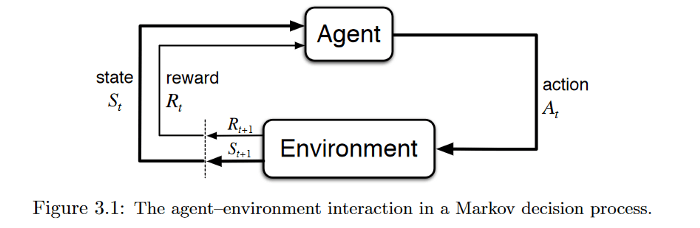
منبع: Reinforcement Learning:An Introduction
فرض کنید که در خانه (محیط) کنترل تلویزیون را به دست فرزند خود سپردهاید. کودک(عامل تصمیمگیرنده) ابتدا محیط را مشاهده میکند و یک بازنمایی یا تصور از محیط برای خود ایجاد میکند (وضعیت). پس از آن کودک کنجکاو روی کنترل ضربه میزند (اقدام) و واکنش تلویزیون (وضعیت بعدی) را مشاهده میکند.
اگر تلویزیون پاسخی به این اقدام ندهد، جذابیتی برای کودک نخواهد داشت (کودک پاداش منفی دریافت میکند) و از این پس، اقداماتی که منجر به چنین نتیجهای شوند را کمتر انجام خواهد داد (بهروزرسانی سیاست) و برعکس. کودک این فرآیند را آنقدر تکرار میکند تا سیاستی (کاری که باید تحت شرایط مختلف انجام دهد) را پیدا کند که برایش جذاب باشد (حداکثرسازی پاداش (تنزیلشده) کل).

هدف یادگیری تقویتی ساخت یک چارچوب ریاضیاتی mathematical framework برای حل مسائل است. برای مثال، برای پیدا کردن یک سیاست خوب میتوان از روشهای مبتنی بر ارزش همچون یادگیری کیفی استفاده کرد تا هماهنگی یک اقدام با یک وضعیت معین را سنجید. از طرف دیگر نیز میتوان با اعمال روشهای مبتنی بر سیاست، مستقیماً و بدون توجه به میزان هماهنگی اقدام و وضعیت، اقداماتی که میتوان در وضعیتهای مختلف انجام داد را شناسایی کرد.
اما مشکلات و مسائلی که در دنیای واقعی با آنها مواجه میشویم گاه آنقدر پیچیدهاند که الگوریتمهای رایج یادگیری تقویتی نمیتوانند هیچ راهی برای حل آنها پیدا کنند. برای مثال، فضای وضعیت (وضعیتهای محتمل) در بازی «گو» بسیار بزرگ است، یا در بازی پوکر الگوریتم قادر نیست محیط را بهطور کامل مشاهده و بررسی کند و در دنیای واقعی نیز عوامل تصمیمگیرنده با یکدیگر تعامل دارند و به اقدامات یکدیگر واکنش نشان میدهند.
پژوهشگران برای حل برخی از این مسائل روشهایی ابداع کردهاند که در آنها از شبکههای عصبی عمیق برای مدلسازی سیاستهای مطلوب، توابع ارزش و حتی مدلهای انتقال استفاده میشود. این روشها یادگیری تقویتی عمیق نام گرفتهاند. البته ما در ادامه این مقاله، تمایزی بین یادگیری تقویتی و یادگیری تقویتی عمیق قائل نشدهایم. در ادامه بخش دوم را تحت عنوان کاربردهای یادگیری تقویتی مطالعه بفرمایید.
سازوکار و اصطلاحات کلیدی یادگیری تقویتی
عامل تصمیمگیرنده و محیط
یادگیری تقویتی متشکل از دو عنصر اصلی؛ عامل تصمیمگیرنده و محیط است.

منظور از محیط، شیءای است که عامل تصمیمگیرنده عملی بر روی آن انجام میدهد (برای مثال، خود بازی در بازی آتاری یک محیط است). عامل تصمیمگیرنده نیز معرف الگوریتم یادگیری تقویتی و یا هر تابع دیگری که اقدامی را بر روی محیط انجام میدهد، میباشد. در ابتدا محیط دارای یک وضعیت است که عامل آنرا پردازش کرده و براساس دانش خود نسبت به آن عکسالعمل نشان میدهد. سپس با توجه به اقدام عامل، وضعیت محیط تغییر میکند و اطلاعات مربوط به وضعیت جدید و پاداش اقدام قبلی با هم برای عامل فرستاده میشود. عامل تصمیمگیرنده نیز دانش خود را بر پایه بازخوردی که در ازای اقدام پیشین خود دریافت کرده، بهروزرسانی میکند.
بنابراین، یکی از تفاوتهای اصلی روش یادگیری تقویتی نسبت به سایر روشهای یادگیری ماشین، این است که شبکه عصبی از طریق تعامل با یک محیط پویا به جای مجموعه داده ایستا آموزش داده میشود. معمولاً شما در روشهای یادگیری ماشین یک مجموعه داده متشکل از تصاویر/جملات/فایل های صوتی دارید و بارها آنرا مورد استفاده قرار میدهید تا در کاری که برای آن آموزش میدهید بهتر شود. اما در یادگیری تقویتی قضیه اندکی متفاوت است. بطور مفصل در این زمینه در بخشهای آتی صحبت خواهد شد.
وضعیت و فرایند تصمیمگیری مارکوف
وضعیت و یا (State|S) شرایطی از محیط است که عامل در هرلحظه با آن مواجه میشود و با انجام اقداماتی بر محیط، این پارامتر را تغییر میدهد. به بیانی دیگر، وضعیت هرگونه اطلاعاتی از محیط است که در هر مرحله زمانی به عامل داده میشود تا به کمک آن بتواند اقدام مناسبی را انجام دهد.
اگر اطلاعات ارائه شده توسط وضعیت به گونهای باشد که بتوان به کمک آن وضعیتهای آینده محیط را با توجه به اقدامات عامل، تعیین نمود، در آن صورت گفته میشود که وضعیت دارای ویژگی مارکوفی است. به عنوان مثال، بازی آجرشکن (Breakout) آتاری را در نظر بگیرید. اگر یک اسکرین شات از بازی را در هر نقطه ای به عنوان وضعیت در نظر بگیریم، آیا دارای خاصیت مارکوفی است؟
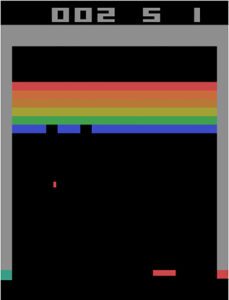
پاسخ منفی است، زیرا فقط با توجه به اسکرین شات فوق، هیچ راهی برای تعیین جهت حرکت توپ وجود ندارد و توپ میتواند بر هر طرف حرکت کند. حال تصویر زیر که چهار فریم متوالی از حرکت توپ را نشان میدهد، در نظر بگیرید.
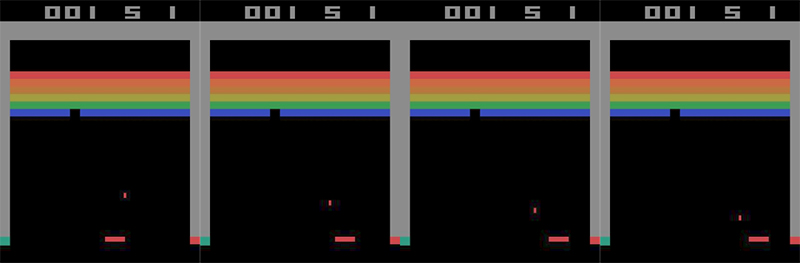
با کمک این 4 فریم به عنوان وضعیت، میتوانیم سرعت و جهت توپ را برای پیشبینی 4 فریم آینده محاسبه کنیم. بنابراین این وضعیت خاصیت مارکوفی دارد و میتواند در مدلسازی بواسطه فرایند تصمیمگیری مارکوف مورد استفاده قرار گیرد. اکثر محیطهایی که در یادگیری تقویتی با آنها سر و کار داریم به عنوان فرآیندهای تصمیم گیری مارکوف مدل سازی می شوند.
لازم به ذکر است که در برخی از موارد یافتن وضعیتهایی از محیط که خاصیت مارکوفی داشته باشد، کار دشواری است. خبر خوب این است، الگوریتمهای یادگیری تقویتی بر روی تقریبهایی با ویژگیهایی نزدیک به مارکوف هم توانسته عملکرد خوبی از خود نشان دهد. در چنین مواقعی، فرض میشود که وضعیتی از محیط با ویژگی مارکوفی وجود دارد که ما نمیتوانیم آن را مشاهده کنیم. آنچه ما مشاهده میکنیم تنها بخشی از این وضعیت است که به آن مشاهده جزئی می گویند و به فرایند حل آن فرآیند تصمیمگیری مارکوف با مشاهدهپذیری جزئی POMDP Partially Observable Markov Decision Process میگویند.
اقدام و اپیزودیک episodic و یا مستمر بودن آن
اقدام (Action|A): شامل تمامی واکنشهای محتملی میباشد که عامل تصمیمگیرنده ممکن است در مواجهه با وضعیت ایجاد شده، از خود نشان دهد. اقدامها با توجه به متناهی بودن و یا نامتناهی بودنشان به دو نوع اپیزودیک و یا مستر (غیر اپیزودیک) تقسیمبندی میشوند. منظور از اقدامات اپیزودیک، وجود یک نقطه آغاز و یا پایان برای آنهاست. یک بازی را در نظر بگیرید که در آن بازیکننده کامپیوتری ممکن است بمیرد و یا به پایان مرحله برسد. در چنین حالتی میتوان یک لیستی از وضعیتها، اقدامات و یا پاداشها داشت.
ولی در وظایف مستمر یا غیر اپیوزدیک نقطه پایانی برای اقدامات وجود ندارد. در این زمینه میتوان به تجارت سهام برای عامل اشاره کرد که عامل تا زمانی که که توسط نیروی خارجی (مثل کاربر انسانی) متوقف نشود، همواره به یادگیری و انجام اقدام مناسب به تعامل با محیط میپردازد.
سایر اصطلاحات کلیدی:

پاداش(Reward|R): بازخوردی که پس از ارزیابی هر اقدام عامل، توسط محیط برای آن ارسال میشود، را پاداش میگویند.
سیاست(Policy|π): عامل تصمیمگیرنده برای انجام هر عملی بر روی محیط و پاسخ به وضعیت فعلی، استراتژیای در پیش میگیرد که به آن در اصطلاح سیاست گفته میشود.
ارزش(Value|V): ارزش عبارتست از سود موردانتظار در بلندمدت که ناشی از وضعیت کنونی s تحت سیاست π است. به بیانی دیگر، ارزش، پاداش بلند مدت موردانتظار تنزیلشدهای است که برای بلندمدت اعمال میشود.
تابع انتقال: تابع انتقال، مقدار توزیع احتمال رفتن به وضعیت جدید با توجه به حالت اولیه محیط و عملکرد اعمال شده بر آن را، مشخص میکند.
مراحل اصلی در یادگیری تقویتی
همانطور که پیش از این هم اشاره شد، در یادگیری تقویتی برعکس روشهای یادگیری با برچسبگذاری دادهها، عامل از طریق آزمون و خطا آموزش میبیند. به بیانی دیگر، عامل با انجام یکسری اقدامات در محیط مشاهده میکند کدام از اقدامات دارای بازده خوب و کدامیک دارای بازده بد است. در نهایت با استفاده از تکنیکهای مختلف، عامل بر مبنای سیاست خود اقداماتی را اجرا میکند که حداکثر یا نزدیک به حداکثر پاداش و یا ارزش را به همراه دارد.
الگوریتمهای متنوعی برای RL در شکلها و اندازههای مختلف وجود دارند، اما بیشتر آنها از یک الگو پیروی میکنند. به طور کلی، هر الگوریتم RL فرآیند یادگیری را به سه مرحله تقسیم میکند که این مراحل برای دستیابی به عملکردی قابل قبول ممکن است بارها تکرار شوند.
- جمعآوری داده: برخلاف روشهای استاندارد یادگیری ماشین، هیچ مجموعه داده ایستا در تنظیمات RL وجود ندارد که بتوانیم برای بهبود خط مشی خود به طور مکرر از آن استفاده کنیم. در عوض، در یادگیری تقویتی، دادهها از طریق تعامل با محیط جمع آوری میگردند. سپس اقدام مربوطه با توجه به سیاست موردنظر اجرا شده و دادهها ذخیره می شوند. دادهها معمولاً به صورت مقادیر 4 تایی ]وضعیت فعلی ( )، اقدام ( )، پاداشی که در نتیجه اقدام در وضعیت فعلی به عامل داده میشود ( )، وضعیت آینده ( )[ ذخیره می شوند.
- تخمین میزان پاداش و یا ارزش: مرحله بعدی در حلقه یادگیری الگوریتمهای RL محاسبه پاداش و یا ارزش است. هدف اصلی یادگیری تقویتی به حداکثر رساندن پاداش تجمعی مورد انتظار است. دلیل استفاده از کلمه “مورد انتظار” اساساً در ماهیت احتمالی سیاستها و یا محیط نهفته است.
- بهبود سیاست: در مرحله سوم، سیاست بهروزرسانی میشود تا عامل بتواند اقداماتی انجام دهد که پاداش مورد انتظار را به حداکثر برساند. به عنوان نمونه برای یادگیری تقویتی عمیق، جهت یادگیری سیاستهای بهینه رویکردهای مختلفی وجود دارد که دارای اهدافی برای بهینهسازی هستند.
لازم است به این نکته توجه کنید که در طراحی یادگیری تقویتی باید حواسمون به توازن استخراج Exploitation و اکتشاف Exploration باشد. برای اکثر ما اتفاق افتاده، زمانیکه به دنبال انجام کاری نظیر نوشتن برنامهای و یا تهیه گزارشی هستیم و متناسب با آن اطلاعاتی را جمعآوری میکنیم، از یک جا به بعد احساس میکنیم بهتر است جمعآوری اطلاعات را متوقف کنیم و تمرکز خود را بر روی اطلاعات جمعآوری شده بگذاریم. به بیان فنیتر، دست از اکتشاف اطلاعات جدید برداریم و به استخراج دانش از اطلاعات موجود بپردازیم. توازن بین استخراج و اکتشاف یکی از چالشهای مطرح در الگوریتمهای یادگیری تقویتی نیز هست. با توجه به اینکه هدف در یادگیری تقویتی بیشینهسازی پاداش و یا ارزش دریافتی است، گاهی ممکن است در تله عدم توازن استخراج و اکتشاف بیفتیم. برای این منظور، طراحان و توسعهدهندگان باید قوانینی را تعبیه کنند که به این توازن کمک میکند.

یادگیری تقویتی و ارتباط آن با سایر روشهای یادگیری ماشین
یادگیری تقویتی شاخهای از یادگیری ماشین به حساب میآید که در بین یادگیری تحت نظارت و یادگیری بدون نظارت قرار میگیرد. تعریف و مقایسه هر یک از انواع یادگیری در زیر اشاره گردیده است:
یادگیری تحت نظارت (Supervised Learning): در یادگیری تحت نظارت، الگوریتمها بر روی مجموعهای از دادههای برچسب دار آموزش میبینند. الگوریتمهای یادگیری تحت نظارت فقط میتوانند ویژگیهایی را یاد بگیرند که در مجموعه دادهها مشخص شدهاند. کاربردهای رایج یادگیری تحت نظارت، مدلهای پردازش تصویر هستند. این مدلها مجموعهای از تصاویر برچسبگذاری شده را دریافت میکنند و یاد میگیرند که ویژگیهای رایج نظیر تشخیص اجسام و مکانیابی آنها را استخراج نمایند.
یادگیری بدون نظارت (Unsupervised learning): در یادگیری بدون نظارت، توسعهدهندگان الگوریتمها را روی دادههای کاملاً بدون برچسب به اصطلاح رها میکنند. الگوریتمهای مذکور با تقسیمبندی مشاهدات با توجه به ویژگیهای داده، بدون اینکه به آنها گفته شود به دنبال چه چیزی بگردید، یاد میگیرند. به بیانی دیگر، در یادگیری بدون نظارت دادهها بررسی شده تا ساختار و یا روابط پنهان بین آنها کشف شود. تشخیص ناهنجاری که میتواند وجود یک محصول معیوب، تراکنش مشکوک به تقلب و غیره باشد، نمونهای از کاربرد این نوع از یادگیری است.

یادگیری تقویتی (Reinforcement learning): به طور کلی رویکرد این نوع از یادگیری متفاوت است. یادگیری تقویتی از سیستمی مبتنی بر پاداش و جریمه استفاده میکند تا کامپیوتر را وادار کند تا یک مشکل را به تنهایی حل کند. دخالت انسان به تغییر محیط و اصلاح سیستم پاداش و مجازات محدود می شود. از برخی جهات یادگیری تقویتی را مشابه با یادگیری تحت نظارت میدانند که توسعه دهندگان لازم است برای الگوریتمها اهداف مشخص شده و پاداشها و مجازاتهایی را تعریف کنند. این بدان معناست که سطح برنامه نویسی مورد نیاز در یادگیری تقویتی بیشتر از یادگیری بدون نظارت است. اما، زمانی که این پارامترها تنظیم شوند، الگوریتم به تنهایی عمل میکند و آن را بسیار خودگردانتر از الگوریتمهای یادگیری تحت نظارت میکند. در جدول زیر، یادگیری تقویتی و یادگیری تحت نظارت با یکدیگر مقایسه شدهاند:
|
یادگیر تقویتی |
یادگیری تحت نظارت |
| یادگیری تقویتی جهت تصمیمگیری متوالی استفاده میشود. به عبارت ساده می توان گفت که خروجی هر مرحله به وضعیت ورودی آن و ورودی مرحله بعد به خروجی مرحله قبل بستگی دارد. | در یادگیری تحت نظارت، تصمیمگیری براساس ورودی اولیه یا ورودی داده شده در شروع انجام میشود. |
| یادگیری تقویتی مبتنی بر تصمیمگیری وابسته است، بنابراین به دنبالهای از تصمیمات وابسته، برچسب میزنیم. | در یادگیری تحت نظارت ، تصمیمات مستقل از یکدیگر هستند، بنابراین به هر تصمیم بطور مجزا برچسب زده میشود. |
| مثال موردی: بازی شطرنج |
مثال موردی: شناسایی اجسام در پردازش تصویر |
اهداف یادگیری تقویتی
هدف یادگیری تقویتی ساخت یک چارچوب ریاضیاتی برای حل مسائل است. برای مثال، برای پیدا کردن یک سیاست خوب میتوان از روشهای مبتنی بر ارزش همچون یادگیری کیفی استفاده کرد تا هماهنگی یک اقدام با یک وضعیت معین را سنجید. از طرف دیگر نیز میتوان با اعمال روشهای مبتنی بر سیاست، مستقیماً و بدون توجه به میزان هماهنگی اقدام و وضعیت، اقداماتی که میتوان در وضعیتهای مختلف انجام داد را شناسایی کرد.
انواع یادگیری تقویتی
با توجه به رویکردهای متفاوتی که الگوریتمهای یادگیری عمیق در سه مرحله جمعآوری داده، تخمین تابع ارزش و بهینهسازی سیاست در پیش میگیرند، میتوان آنها را از مناظر مختلف دستهبندی کرد که در ذیل به دستهبندیها رایج در این حوزه اشاره میگردد:

الگوریتمهای RL بین دو فعالیت جمعآوری داده و بهبود سیاست دائما در تناوب هستند. سیاستی که برای جمعآوری داده استفاده میشود ممکن است با سیاست عامل در حین آموزش متفاوت باشد. به این رویکرد Off-policy میگویند. در رویکرد Off-policy سیاست بهینه بدون در نظر گرفتن اقدامات عامل و یا انگیزه او برای اقدام بعدی تعیین میشود.
در مقابل رویکرد On-policy، از همان سیاستی که در آموزش استفاده شده برای جمعآوری داده نیز استفاده میگردد. به بیانی دیگر، این رویکرد به سیاستهایی که عامل قبلاً در تصمیمگیریها استفاده کرده، توجه کرده و سعی در ارزیابی و بهبود آنها میکند.
الگوریتمهای بدون مدل دربرابر الگوریتمهای مبتی بر مدل
در خیلی از اوقات وضعیتهای مسأله دارای ابعاد بالایی است. در چنین شرایطی، تابع انتقال نیاز به برآورد توزیع احتمال روی هر یک از این حالتها است. همچنین به یاد داشته باشید که احتمالات انتقال باید در هر مرحله محاسبه شوند. در حال حاضر، انجام این کار با قابلیتهای سختافزاری فعلی تقریبا غیرقابل حل است. برای رویارویی با این چالش یک دستهبندی از مسائل یادگیری تقویتی ارائه شده است:
در شرایطی که تلاش طراح صرف یادگیری مدلی از شرایط و محیط اطراف میشود، میتوانیم بگوییم رویکرد مبتنی بر مدل را در پیش گرفته است. به عنوان نمونه، مجددا بازی آجرشکن آتاری را در نظر بگیرید. طراح از یادگیری عمیق برای یادگیری تابع انتقال و تابع پاداش بهره میگیرد. وقتی روی یادگیری این مسائل تمرکز میشود. به اصطلاح در حال یادگیری مدلی از محیط هستیم که ما از این مدل برای دستیابی به تابعی به نام سیاست ( ) استفاده میکنیم. تابع سیاست، مشخص مینماید که وقتی محیط در وضعیت است، عامل با چه احتمالی اقدام را برمیگزیند. اما با افزایش تعداد وضعیتها و اقدامها، الگوریتمهای مبتنی بر مدل کارآمدی خود را از دست میدهند.
از سوی دیگر، الگوریتمهای بدون مدل درواقع مبتنی بر روش آزمون و خطا هستند و براساس نتیجه آن، دانش خود را بهروزرسانی میکنند. این نوع از الگوریتمها برای مواقعی مناسب هستند که مدلسازی محیط بسیار سخت باشد و طراح ترجیح میدهد الگوریتمی را مورد استفاده قرار دهد که بهجای تلاش برای یادگیری مدل محیط، مستقیماً از تجربیات یاد بگیرد. این رویکرد بسیار شبیه روشی است که انسانها اکثر وظایف خود را مبتنی بر آن یاد میگیرند. به عنوان نمونه، راننده ماشین برای انجام رانندگی، قوانین فیزیک حاکم بر ماشین را نمیآموزد، اما یاد میگیرد که بر اساس تجربه خود از نحوه واکنش ماشین به اقدامات مختلف، تصمیم بگیرد. از مزیتهای این رویکرد، عدم نیاز به فضایی برای ذخیره ترکیبات احتمالی وضعیتها و اقدامها خواهد بود.
رویکر مبتنی بر ارزش و یا مبتنی بر سیاست
اکثر مدلهای بدون مدل از دو رویکرد ارزش محور و یا سیاست محور استفاده میکنند. در رویکرد سیاست محور، هدف بهینهسازی تابع سیاست است بدون اینکه به تابع ارزش کار داشته باشیم. به بیانی دیگر عامل یک تابع سیاست را میآموزد، آنرا در حین یادگیری در حافظه نگه میدارد و سعی میکند هر وضعیت را به بهترین اقدام ممکن نگاشت کند. لازم به ذکر است سیاستها ممکن است قطعی (برای یک وضعیت، همیشه اقدام مشابهی را باز میگرداند) و یا تصادفی (برای هر اقدام یک توزیع احتمالی در نظر میگیرد) باشند.
در رویکرد ارزش محور، برخلاف رویکرد سیاستمحور که به تابع ارزش کاری ندارد، هدف بهینهسازی تابع ارزش خواهد بود. به عبارت دیگر، عامل اقدامی را انتخاب مینماید که برآورد میکند بیشترین پاداش را در آینده دریافت خواهد کرد.
چرا به یادگیری تقویتی نیاز داریم؟
یکی از قابلیتهای برجسته یادگیری تقویتی انعطافپذیری بالای آن در مقابله با محیط پویا است و همین امر سبب گردیده که در خیلی از موارد توسعهدهندگان و طراحان تمایل به استفاده از یادگیری تقویتی در توسعه سیستمهای هوشمند داشتهباشند. سیستمهای هوشمندی که بر پایه یادگیری تقویتی بنا شدهاند حتی توانایی عملکردی فراتر از عملکرد انسان را از خود نشان دادهاند. به احتمال زیاد، شکست قویترین بازیکن جهانی تخته چینی Go را در مقابل بازیکن کامپیوتری خود شنیدهاید. این تکنیک قدرتمند بدون نیاز به پایگاه دادهای ایستا، دیگر محدودیت دانش انسانی را ندارد و هزاران سال دانش بشری را در طی مدت چند روز میتواند جمع نماید و عملکردی وصفنشدنی از خود نشان دهد.
الگوریتمهای یادگیری تقویتی و مقدمهای بر انواع آن
الگوریتمهای یادگیری تقویتی بسیار متنوع هستند، اما این الگوریتمها هیچگاه بهطور جامع بررسی و مقایسه نشدهاند. در صورتی که بخواهیم از الگوریتمهای یادگیری تقویتی در پروژه خود استفاده کنیم، لازم است بدانیم کدام الگوریتم را باید برای چه فرآیندی بهکار بگیرم. در این بخش سعی بر این است که تعدادی از محبوبترین الگوریتمهای این حوزه را معرفی نماییم.
روشهای حل جدولی در مقابل روشهای تقریبی
بطور کلی ایده اصلی بسیاری از الگوریتمهای یادگیری تقویتی در سادهترین حالت ممکن، نمایش تابع ارزش به صورت جدولی و یا آرایهای است که اصطلاحا به آنها روشهای حل جدولی Tabular Solution Methods میگویند. این روشها برای مواردی مناسب هستند که اندازه فضای وضعیت و اقدام چندان بزرگ نباشد، در غیراینصورت با افزایش ابعاد مقیاسپذیر نخواهند بود و زمان یادگیری آنها به صورت نمایی افزایش مییابد. روشهای حل جدولی اغلب به راهکارهای دقیق دست مییابند و میتوان براساس آنها مقدار بهینه تابع ارزش و سیاست را پیدا نمود.
روشهای حل جدولی که مسائل را به صورت مدلهای تصمیمگیری مارکوف مدلسازی میکنند میتوانند از سه روش کلی حل شوند:
برنامهریزی پویا (Dynamic Programming): روش برنامهریزی پویا که رویکردی برای حل مسائل بسیار زیادی است، یک مسأله کلی را به مسایل جز تقسیمبندی کرده و راهحل بهینه را برای هر یک از مسائل جز بدست آورده و در نهایت با ترکیب آنها پاسخ بهینه مساله کل را محاسبه مینماید. روشهایی که معمولا از برنامهریزی پویا استفاده میکنند به نامهای ارزیابی سیاستPolicy Evaluation، تکرار سیاستPolicy Iteration و تکرار ارزش Value Iteration نیز شناخته میشوند که در موارد مختلفی مورد استفاده قرار گرفتهاند. این روشها از نظر ریاضی به خوبی توسعه یافته اند، اما نیاز به یک مدل کامل و دقیق از محیط از چالشهای استفاده از آنها محسوب میشود.
مونت کارلو (Monte Carlo Approach): روش مونت کارلو برخلاف روش برنامهریزی پویا که نیازمند اطلاعات کامل در مورد توزیع احتمالات همه انتقالهای ممکن بود؛ تنها به نمونهای از توزیعهای احتمال بسنده میکند. به بیانی دیگر، در روش مونت کارلو شناخت کامل محیط لازم نیست و با برقراری تعامل واقعی یا شبیهسازی شده با یک محیط میتوان به توالی نمونهای از حالتها، اقدامات و پاداشهای دست یافت. به همین دلیل است که در این روش، پاداشها در انتهای دوره حساب میشود تا بتوان از دانش کسب شده برای دوره جدید استفاده نمود.
یادگیری تفاوت زمانی (Temporal Difference Learning): یادگیری تفاوت زمانی (TD) یک نوع روش پیشبینی است که از ایدههای مونت کارلو و برنامه نویسی پویا برای حل مسائل تقویتی استفاده میکند. روشهای TD مانند روشهای مونت کارلو، مستقیماً از تجربه خام بدون نیاز به مدلی پویا از محیط، میآموزند و مانند برنامهریزی پویا، تخمینها را تا حدی بر اساس سایر تخمین های آموخته شده به روز می کنند، بدون اینکه منتظر نتیجه نهایی باشند. امروزه الگوریتمهای این دسته بسیار رایج و پرکاربرد هستند که برخی از آنها عبراتند از:
- الگوریتم Q-Learning و یا یادگیری Q
- شبکه عمیق Q یا DQNDeep-Q Networks
- الگوریتم SARSA و یا «وضعیت-اقدام-پاداش-وضعیت-اقدام»
به دلیل اهمیت این الگوریتمها؛ در ادامه، چند نمونه از برجستهترین الگوریتمهای یادگیری تفاوت زمانی شرح داده خواهد شد.
روشهای تقریبی
در مقابل روشهای حل جدولی، روشهای تقریبی مطرح میشوند که تنها راهحلهای تقریبی را پیدا میکنند، اما میتوان از آنها در مسائل بزرگتری استفاده نمود. روشهای گرادیان سیاستPolicy Gradient از جمله روشهای رایج در این زمینه هستند که در انتهای این بخش به یکی از جدیدترین انواع این روشها، گرادیان سیاست قطعی عمیق، اشاره میگردد:
- الگوریتم گرادیان سیاست قطعی عمیق و یا DDPGDeep Deterministic Policy Gradient
الگوریتم Q-Learning و یا یادگیری Q
الگوریتم Q-Learning یا یادگیری Q یک الگوریتم یادگیری تقویتی از نوع بدون مدل و Off-policy است که بر پایه معادله معروف بِلمَن تعریف میشود:

که در معادله بالا،E نماد مقدار مورد انتظار و λ ضریب تنزیلDiscount Factor است. ضریب تنزیل که مقداری بین 0 و 1 به خود میگیرد، به دلیل تفاوت قائل شدن اهمیت پاداشها در کوتاهمدت و بلندمدت اعمال میگردد. به بیان دیگر هر چه مقدار این ضریب بیشتر باشد، تنزیل کمتر خواهد بود و عامل یادگیرنده به پاداشهای بلندمدت اهمیت بیشتری میدهد. در مقابل اگر مقدار این ضریب کوچکتر باشد، تنزیل بیشتر خواهد بود و عامل توجه بیشتری به پاداشهای کوتاهمدت خواهد کرد. میتوانیم معادله بالا را در فرم تابعی Q-Value به صورت زیر نیز بنویسیم:

مقدار بهینه Q-value که با نماد نمایش داده میشود را میتوان از فرمول زیر به دست آورد:

هدف این معادله حداکثرسازی مقدار Q-value است. البته، پیش از پرداختن به روشهای بهینهسازی مقدار Q-value، قصد دارم ۲ روش بهروزرسانی ارزش را که رابطه نزدیکی با الگوریتم یادگیری Q دارند، معرفی کنم.
- تکرار سیاست
در روش تکرار سیاست، یک حلقه بین ارزیابی سیاست و بهبود آن شکل میگیرد.

در ارزیابی سیاست، مقدار تابع V را برحسب سیاست حریصانهای که درنتیجهی بهبود سیاست قبلی به دست آمده، تخمین میزنیم. به عبارت دیگر، عامل یادگیرنده براساس تخمینی که از ارزش اقدامات در وضعیتهای محیط پیرامونی داشته، صرفا بهترین اقدام را در همه و یا اکثر شرایط انتخاب میکند،کمتر به اقدامات غیربهینه توجه میکند و به اصطلاح حریصانه عمل مینماید.
از سوی دیگر، در بهبود سیاست، سیاست فعلی را برحسب اقدامی که مقدار V را در هر وضعیت حداکثر کند، بهروزرسانی میکنیم. بهروزرسانی معادلات برپایه معادله بلمن انجام میگیرد و تکرار حلقه تا زمانی که این معادلات همگرا شوند، ادامه مییابد.

- تکرار ارزش

روش تکرار ارزش تنها یک بخش دارد. در این روش، تابع ارزش براساس مقدار بهینه معادله بلمن بهروزرسانی میشود.

وقتی تکرار به همگرایی برسد، یک سیاست بهینه برای همه وضعیتها مستقیماً توسط تابع argument-max ارائه داده میشود.
بهخاطر داشته باشید که برای استفاده از این دو روش باید احتمال انتقال p را بشناسید. بنابراین، میتوان گفت که این روشها، الگوریتمهای مبتنی بر مدل هستند. اما همانطور که پیشتر نیز ذکر کردیم، الگوریتمهای مبتنی بر مدل با مشکل مقیاسپذیری مواجه هستند. سوالی که در اینجا پیش میآید این است که الگوریتم یادگیری Q چطور این مشکل را حل کرده است؟

در این معادله،α نماد نرخ یادگیری Learning Rate (یعنی سرعت ما در حرکت به سوی هدف اصلی) است. ایده اصلی یادگیری Q بهشدت به روش تکرار ارزش متکی است. اما معادله بهروزشده با فرمول بالا جایگزین میشود و درنتیجه، دیگر نیاز نیست نگران احتمال انتقال باشیم.

بخاطر داشته باشید که اقدام بعدی یعنی، با هدف حداکثر کردن وضعیت بعدی Q-value انتخاب شده است، نه براساس سیاست مربوطه. درنتیجه یادگیری Q در دسته روشهای Off-policy قرار میگیرد.
شبکه عمیق Q یا DQNDeep-Q Networks
الگوریتم یادگیری Q الگوریتم قدرتمندی است، اما قابلیت تعمیمپذیریGeneralization ندارد و همین مسئله را میتوان بزرگترین نقطهضعف آن دانست. اگر الگوریتم یادگیری Q را بهروزرسانی اعداد موجود در یک آرایه دو بعدی (شامل: فضای اقدام×فضای وضعیت) درنظر بگیرید، متوجه شباهت آن با برنامهنویسی پویا خواهید شد. این موضوع برای ما روشن میسازد که وقتی عامل تصمیمگیرنده در الگوریتم یادگیری Q با وضعیتی کاملاً جدید روبهرو شود، هیچ راهی برای شناسایی و انتخاب اقدام مناسب نخواهد داشت. به عبارت دیگر، عامل تصمیمگیرنده الگوریتم یادگیری Q توانایی تخمین ارزش وضعیتهای ناشناخته را ندارد. برای حل این مشکل، شبکه DQN آرایه دو بعدی را حذف و شبکه عصبی را جایگزین آن میکند.
شبکه DQN به کمک یک شبکه عصبی، تابع Q-value را تخمین میزند. وضعیت فعلی به عنوان ورودی به این شبکه داده میشود، سپس مقدار Q-value متناظر با هر اقدام به عنوان خروجی از شبکه دریافت خواهد شد.

شرکت دیپ مایند DeepMind در سال ۲۰۱۳، شبکه DQN را همانطور که در تصویر بالا ملاحظه میکنید، در بازی آتاری بهکار گرفت. ورودی که به این شبکه داده میشد یک تصویر خام از وضعیت جاری بازی بود. این ورودی از چندین لایه مختلف از جمله لایههای پیچشی و تماماً متصل عبور میکند و خروجی نهایی شامل مقادیر Q-valueهای مربوط به تمام اقدامات احتمالی عامل تصمیمگیرنده است.
حال سؤال اصلی این است که: چطور میتوان این شبکه را آموزش داد؟
پاسخ این است که ما شبکه را براساس معادله بهروزرسانی الگوریتم یادگیری Q آموزش میدهیم. اگر بخاطر داشته باشید، مقدار Q-value هدف برای الگوریتم یادگیری Q از فرمول زیر به دست میآمد:

نماد ϕ معادل وضعیت s است. نماد نیز بیانگر تعدادی از پارامترهای شبکه عصبی است که خارج از بحث ما هستند. بنابراین، تابع زیان شبکه به صورت مربعات خطای Q-value هدف و Q-value ای که شبکه به عنوان خروجی به ما میدهد، تعریف میشود.

دو تکنیک دیگر نیز برای آموزش شبکه DNQ ضروری است:
- تکرار تجریهExperience Replay: در سازوکار متداول یادگیری تقویتی، نمونههای آموزشی همبستگی بالایی دارند و ازنظر مقدار داده موردنیاز نیز کارآمد نیستند. به همین دلیل، سخت است که مدل به مرحله همگرایی برسد. یک راه برای حل مسئله توزیع نمونه، بهکارگیری تکنیک تکرار تجربه است. در این روش، تابع انتقال نمونهها ذخیره میشود و سپس الگوریتم این تجربیات را از محلی به نام «مجموعه انتقال» به طور تصادفی انتخاب میکند تا دانش خود را براساس آن بهروزرسانی نماید.
- شبکه هدف مجزاSeparate Target Network: ساختار شبکه هدف Q مشابه ساختار شبکهای است که ارزش را تخمین میزند. همانطور در نمونه کد بالا ملاحظه کردید، بعد از C مرحله، در شبکه هدف جدیدی تعریف میشود تا از شدت نوسانات کاسته شود و فرایند آموزش ثبات بیشتری داشته باشد.
الگوریتم SARSA و یا «وضعیت-اقدام-پاداش-وضعیت-اقدام»
الگوریتم SARSA که سرواژه عبارت (State-Action-Reward-State-Action) است، شباهت زیادی با الگوریتم یادگیری Q دارد. تفاوت کلیدی این دو الگوریتم در این است که SARSA برخلاف الگوریتم یادگیری Q، در دسته الگوریتمهای On-Policy قرار میگیرد. بنابراین، الگوریتم SARSA مقدار Q-value را با توجه به اقدامی که ناشی از سیاست فعلی است محاسبه میکند نه اقدام ناشی از سیاست حریصانه.

اقدام  اقدامی است که در وضعیت بعدی یعنی تحت سیاست فعلی انجام خواهد گرفت.
اقدامی است که در وضعیت بعدی یعنی تحت سیاست فعلی انجام خواهد گرفت.

ممکن است در نمونه کد بالا متوجه شده باشید که هر دو اقدام اجرا شده از سیاست فعلی پیروی میکنند. اما در الگوریتم یادگیری Q، تا زمانی که اقدام بعدی بتواند مقدار Q-value برای وضعیت بعدی را حداکثر سازد، هیچ قیدی برای آن تعریف نمیشود. بنابراین همانطور که گفته شد، الگوریتم SARSA از نوع الگوریتمهای On-policy است.
الگوریتم گرادیان سیاست قطعی عمیق و یا DDPGDeep Deterministic Policy Gradient
اگرچه شبکه DQN در مسائلی که ابعاد زیادی دارند (همچون بازی آتاری)، بسیار موفق عمل کرده است، اما فضای اقدام در این شبکه گسستهDiscrete میباشد و از آنجا که بسیاری از مسائل موردعلاقه و حائز اهمیت برای ما از جمله مسائل مربوط به کنترل فیزیکی، دارای فضای اقدام پیوسته هستند، گسسته بودن فضا در شبکه DQN یک نقطهضعف بهشمار میآید.
با تبدیل یک فضای اقدام پیوسته به یک فضای گسسته به صورت دقیق و جزئی، یک فضای اقدام بسیار گسترده به دست میآید. برای مثال، فرض کنید درجه آزادی سیستم تصادفی ۱۰ باشد. بهازای هر درجه، باید فضا را به ۴ قسمت تقسیم کنیم. به این ترتیب، در آخر ۱۰۴۸۵۷۶=۴¹⁰ عدد اقدام خواهیم داشت. سخت است که در چنین فضای اقدام بزرگی به همگرایی برسید.
الگوریتم DDPG مبتنی بر معماری عملگر منتقدActor-critic architecture عمل میکند. این معماری دو عنصر اصلی دارد: عملگر و منتقد. عنصر عملگر، تنظیم پارامتر با تابع سیاست را برعهده دارد، به این ترتیب، عملگر تصمیم میگیرد که بهترین اقدام ممکن برای هر وضعیت چیست.
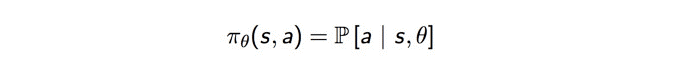
وظیفه منتقد نیز ارزیابی تابع سیاستی است که عملگر براساس تابع خطای تفاوت موقتیTemporal Difference (TD) error تخمین زده است.

در این تابع حرف v کوچک نمایانگر سیاستی است که عملگر برمیگزیند. این فرمول کمی آشنا بهنظر نمیرسد؟ بله، درست است. این فرمول دقیقاً مشابه معادله بهروزرسانی الگوریتم یادگیری Q است. یادگیری تفاوت زمانی روشی است که الگوریتم به کمک آن میتواند نحوه پیشبینی یک تابع ارزش را بر پایه ارزشهای آتی یک وضعیت معین بیاموزد. الگوریتم یادگیری Q نوعی خاصی از یادگیری تفاوت زمانی در حوزه یادگیری Q-value است.

الگوریتم DDPG تکنیکهای تکرار تجربه و شبکه هدف مجزا در شبکه DQN را نیز بهکارمیگیرد. اما یکی از مشکلات DDPG این است که به ندرت اقدامات را جستوجو میکند. یک راهحل برای این مشکل، ایجاد اختلالAdding noise در فضای پارامترها یا فضای اقدام میباشد.

البته محققین OpenAI در مقاله خود ادعا کردهاند که ایجاد اختلال در فضای پارامترها بهتر از ایجاد اختلال در فضای اقدام است. یکی از رایجترین و پرکاربردترین اختلالات در این زمینه فرایند تصادفی اورنستین-یولنبکThe Ornstein-Yolnbeck process نام دارد.

محصولات مبتنی بر یادگیری تقویتی
به تبع جایگاه یادگیری تقویتی در زمینههای مختلف زندگی بشر، محصولات زیادی براساس این رویکرد طراحی و توسعه داده شدند. بارزترین مشخصات این محصولات، دریافت بازخورد از مخاطب است که میتواند از فرم امتیاز تا دریافت عکسالعمل از مخاطب، متغیر باشد. در ادامه به چند نمونه رایج در این زمینه اشاره میکنیم:
- بازیکنهای کامپیوتری در دنیای بازیها؛ این بازیکنها با مشاهده نتیجه اعمال خود و عکسالعملهای مخاطب، بازخوردی در قالب جریمه یا پاداش دریافت میکنند و براساس آن اقدامات بعدی را بر میگزینند.
- رباتها، در حال حاضر بسیاری از انواع رباتها از صنعتی گرفته تا خانگی توسط الگوریتمهای یادگیری تقویتی توسعه داده شدند.
3.چتباتها؛ برخی از چتباتها با دریافت امتیاز از کاربران در مورد کیفیت پاسخهای خود، به سمت بهبود عملکرد خود پیش میروند.
- سیستمهای پیشنهاددهنده؛ مشابه چتباتها، سیستمهای پیشنهاددهنده نیز با دریافت بازخورد از کاربر، از عملکرد خود آگاهی یافته و در راستای بهبود آن قدم بر میدارند.
یادگیری تقویتی در متلب
نرمافزار متلب با فراهم نمودن جعبه ابزار مخصوص یادگیری تقویتی طراحی و آزمایش الگوریتمهای تقویتی را میسر ساخته است. Reinforcement Learning Toolbox برنامه، توابع و یک بلوک Simulink را برای سیاستهای آموزشی با استفاده از الگوریتمهای یادگیری تقویتی نظیر DQN و DDPG ارائه میکند. از این سیاستها میتوان جهت پیادهسازی کنترلکنندهها و الگوریتمهای تصمیمگیری برای برنامههای پیچیده مانند تخصیص منابع، روباتیک و سیستمهای مستقل استفاده کرد.
این جعبه ابزار به شما این امکان را می دهد سیاستها و توابع ارزش را با استفاده از شبکه های عصبی عمیق یا جداول جستجو نمایش دهید و آنها را از طریق تعامل با محیط های مدل سازی شده در MATLAB یا Simulink آموزش دهید. می توانید الگوریتم های یادگیری تقویتی تک یا چند عامله ارائه شده در جعبه ابزار را ارزیابی کنید یا الگوریتم های خود را توسعه دهید. میتوانید تنظیمات فراپارامتر را آزمایش کنید، پیشرفت آموزش را نظارت کنید و عوامل آموزش دیده را به صورت تعاملی از طریق برنامه یا برنامهای شبیهسازی کنید. برای بهبود عملکرد آموزشی، شبیهسازیها را میتوان بهطور موازی بر روی چندین CPU، GPU، خوشههای رایانه و فضای ابری (با جعبه ابزار محاسبات موازی و سرور موازی MATLAB) اجرا نمایید.
یادگیری تقویتی عمیق
یکی از چالشهای موجود در پیادهسازی روشهای یادگیری تقویتی در دنیای واقعی نیاز به حجم زیادی از داده جهت دستیابی به نتایج مطلوب میباشد. در روشهای کلاسیک یادگیری تقویتی، این دادهها که بواسطه تعامل با محیط و انجام آزمایشهای سعی و خطا تولید میگردند، قابلیت تعمیمدهی کمی دارند. به بیان دیگر برای مسئله جدید مجددا باید فرایند جمعآوری داده طی شود که میتواند بسیار دشوار و زمانبر باشد، بویژه در مواردی که تعداد ترکیبی از اقدامات و وضعیتها بسیار زیاد است و یا جایی که محیط غیر قطعی بوده و میتواند حالتهای تقریباً نامحدودی داشته باشد.
بدین منظور مسائل یادگیری تقویتی عمیق که استفاده از یادگیری عمیق در بستر یادگیری تقویتی را فراهم کرده، مطرح شده است تا بتواند بسیاری از چالشهای موجود در این زمینه را رفع نماید. با توجه به ساختار و تابع بهینهسازی مناسب، یک شبکه عصبی عمیق میتواند یک خط مشی بهینه را بدون گذر از تمام حالتهای ممکن یک سیستم، یاد بگیرد. هرچند عوامل یادگیری تقویتی عمیق همچنان به حجم عظیمی از دادهها نیاز دارند، اما میتوانند مشکلاتی را که حل آنها با سیستمهای کلاسیک یادگیری تقویتی غیرممکن بود، حل کنند.
کاربردهای یادگیری تقویتی
مباحث این بخش عمومی و غیرفنی است، اما خوانندگانی که با کاربردهای یادگیری تقویتی آشنایی دارند نیز میتوانند از این مطالب سود ببرند.
مدیریت منابع در محاسبات خوشهای
طراحی یک الگوریتم برای تخصیص منابع محدود به کارهای مختلف، کاری چالشبرانگیز و نیازمند الگوریتم مکاشفهای مانند ابتکار انسان است. در مقاله «Resource Management with Deep Reinforcement Learning» میخوانیم که سیستم چگونه میتواند با استفاده از الگوریتمهای یادگیری تقویتی، تخصیص و برنامهریزی منابع محاسباتی را بهطور خودکار بیاموزد و این منابع را به نحوی به پروژههای دردست اجرا تخصیص دهد که زمان تلفشده را به حداقل برسد.
در این مطالعه، فضای حالت State space را در قالب تخصیص کنونی منابع و مشخصات منابع موردنیاز هر پروژه تعیین کردند. برای فضای حرکت Action space نیز از تکنیک ویژهای استفاده نمودند که به عامل تصمیمگیرنده امکان میداد تا در هر مرحله زمانی بیش از یک اقدام انجام دهد و پاداش را هم از فرمول (∑▒〖[(-1)/(کار هر انجام زمان مدت)]〗)/(سیستم در موجود کارهای تمام) به دست آوردند.
سپس با ترکیب الگوریتم تقویتی REINFORCE Algorithm و ارزش پایه Baseline Value، گرادیان سیاست Policy Gradient را محاسبه کرده و بهترین پارامتر سیاست را که توزیع احتمال اقدامات برای حداقلسازی هدف به دست میدهد را شناسایی کردند.
کنترل چراغهای راهنمایی
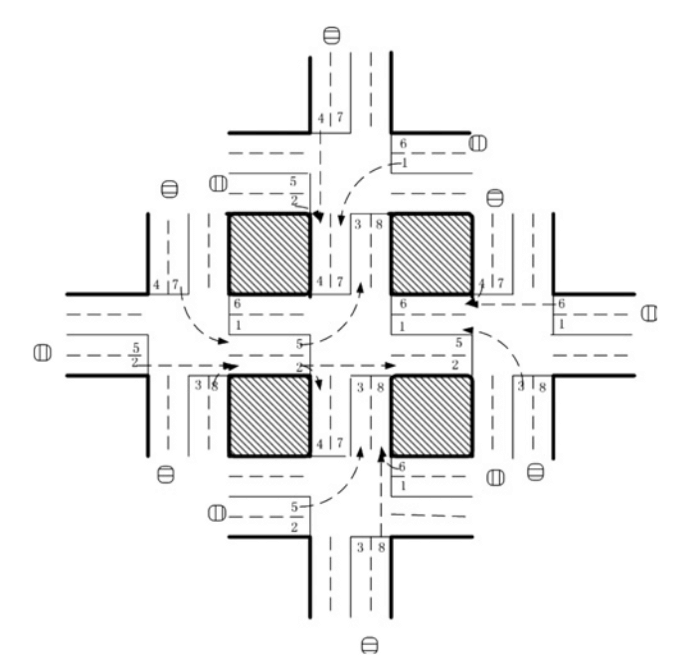
نویسندگان مقاله «Reinforcement learning-based multi-agent system for network traffic signal control» تلاش کردند تا سیستمی برای کنترل چراغهای راهنمایی طراحی نمایند که مسئله ترافیک سنگین خیابانها را حل کند. این الگوریتم تنها در محیط شبیهسازیشده و غیرواقعی آزمایش شد، اما نتایج آن بسیار بهتر از روش سنتی کنترل ترافیک بود و بدین ترتیب، کاربردهای بالقوه الگوریتمهای چند عاملی یادگیری تقویتی در حوزه طراحی سیستمهای کنترل ترافیک را برای همه آشکار کرد.
در این شبکه ترافیکی که دارای 5 چهاراره است، یک الگوریتم یادگیری تقویتی 5 عاملی بهکارگرفته شده که یک عامل آن در چهارراه مرکزی مستقر است تا سیگنالهای ترافیک را کنترل و هدایت کند. در اینجا، وضعیت (State) یک بردار 8 بعدی است که هر عنصر آن نمایانگر جریان نسبی ترافیک در یکی از لاین هاست.

بنابراین، عامل 8 گزینه پیش رو دارد که هر یک از آنها نماد یک ترکیب فازی و تابع پاداش هستند. در اینجا پاداش تابعی از کاهش زمان تأخیر نسبت به مرحله زمانی قبلی است. نویسندگان در این پژوهش، بهمنظور تعیین مقدار کیفی value هر جفت {وضعیت، اقدام} از شبکه عمیق Q Q Deep Q Netork (DQN) استفاده کردند.
رباتیک
برای بهکار گرفتن الگوریتمهای یادگیری تقویتی در علم رباتیک تلاشهای زیادی شده است. برای یادگیری بیشتر شما را به مقاله «Reinforcement Learning in Robotics:A Survey» ارجاع میدهم. در پژوهشی دیگر تحت عنوان «End-to-End Training of Deep Visuomotor Policies» یک ربات تعلیم دید تا سیاستهای لازم جهت مقایسه و تطبیق تصاویر ویدیویی خام با فعالیتهای رباتی را بیاموزد.
در این پژوهش، تصاویری با رنگهای RGB به شبکه عصبی پیچشی داده شدند تا الگوریتم نیروی گشتاور مورد نیاز موتور ربات را محاسبه کند و به عنوان خروجی تحویل دهد. در اینجا الگوریتم “جستجوی سیاست هدایت شده”Guided Policy Search که به عنوان مولفه یادگیری تقویتی در نظر گرفته شده است تا دادههای آموزشی موردنیاز براساس توزیع وضعیت خود الگوریتم تولید شوند.
پیکربندی سیستم وب
در هر سیستم وب بیش از 100 پارامتر قابل پیکربندی وجود دارد. هماهنگ کردن این پارامترها نیازمند یک اپراتور ماهر و بهکارگیری روش آزمون و خطا است. مقاله Reinforcement Learning Approach to Online Web System Auto-configuration» یکی از اولین تلاشها در این زمینه است که نحوه پیکربندی مجدد پارامترها در سیستمهای وب چند لایه در محیطها پویای مبتنی بر ماشین مجازی را بررسی میکند.
فرآیند پیکربندی مجدد میتواند در قالب یک فرآیند تصمیمگیری مارکوف (MDP) محدود ارائه شود. در این پژوهش، فضای وضعیت همان پیکربندی سیستم و فضای اقدام به ازای هر پارامتر شامل {افزایش، کاهش، حفظ} بود. همچنین پاداش الگوریتم به صورت اختلاف میان زمان هدف مفروض برای پاسخگویی و زمان تخمینزده شده محاسبه میشد. پژوهشگران برای حل این مسئله از الگوریتم یادگیری کیفی فارغ از مدل model-free Q-learning استفاده کردند.
پژوهشگران در این پژوهش بهجای ترکیب یادگیری تقویتی با شبکههای عصبی از تکنیکهای دیگری همچون مقداردهی ابتدایی به سیاستها استفاده کردند تا بتوانند مشکلات ناشی از فضای وضعیت بزرگ و پیچیدگیهای محاسباتی این مسئله را حل کنند. اما درهرحال، این پژوهش قدمی بزرگ بود که راه را برای پیشرفتهای آتی در این حوزه هموار کرد.
کاربردهای یادگیری تقویتی در حوزه شیمی
از الگوریتمهای یادگیری تقویتی میتوان در بهینهسازی واکنشهای شیمیایی نیز استفاده کرد. مدل ارائهشده در مقاله «Optimizing Chemical Reactions with Deep Reinforcement Learning» عملکرد بهتری از پیشرفتهترین الگوریتمهای موجود داشت و به ساختارهای اساسی و متفاوتی تعمیم داده شده است.
در این پژوهش، بهمنظور ارائه مدلی برای تابع سیاست Policy function شبکه LSTM و الگوریتم یادگیری تقویتی با یکدیگر ادغام شدند تا عامل تصمیمگیرنده بتواند بهینهسازی واکنش شیمیایی را براساس فرآیند تصمیمگیری مارکوف (MDP) انجام دهد. MDP در اینجا به صورت {S,A,P,R} توصیف میشود که در آن S مجموعه شرایط آزمایش (از قبیل: دما، Ph و غیره) و A مجموعه تمام اقدامات محتملی است که میتوانند شرایط آزمایش را تغییر دهند،P احتمال انتقال از شرایط فعلی آزمایش به شرایط بعدی و R نماد پاداش میباشد که به صورت تابعی از وضعیت تعریف شده است.
این پژوهش به همه ثابت کرد که یادگیری تقویتی میتواند در محیطی نسبتاً باثبات، به خوبی از پس کارهای زمانبر و نیازمند آزمون و خطا برآید.
پیشنهادات شخصیسازیشده
کارهای پیشین در زمینه پیشنهاد اخبار با چالشهایی از جمله سرعت بالای تغییرات در پویایی اخبار، نارضایتی کاربران و نامناسب بودن معیارها مواجه شدند. فردی به نام گوانجی برای غلبه بر این مشکلات، در سیستم پیشنهاد اخبار خود از یادگیری تقویتی استفاده کرد و نتایج این کار را در مقالهای با عنوان «DRN: A Deep Reinforcement Learning Framework for News Recommendation» منتشر کرد.
پژوهشگران حاضر دراین پژوهش 4 دسته ویژگی ایجاد کردند که عبارت بودند از:
- الف) ویژگیهای کاربر
- ب) ویژگیهای متن که همان ویژگیهای وضعیت ایجادشده در محیط بودند
- ج) ویژگیهای کاربر-خبر
- د) ویژگیهای خبر به عنوان ویژگیهای پارامتر اقدام
این 4 ویژگی به عنوان ورودی به شبکه عمیق Q داده شدند تا مقدار کیفی مربوطه محاسبه شود. سپس براساس مقدار کیفی، فهرستی از اخبار پیشنهادی تهیه شد. در این الگوریتم یادگیری تقویتی، کلیک کاربران بر روی اخبار بخشی از پاداش عامل تصمیمگیرنده بود.
پژوهشگران برای غلبه بر سایر مشکلات از تکنیکهایی چون Memory Replay تکرار حافظه Memory Replay، مدلهای تحلیل بقا survival models ، Dueling Bandit Gradient Descent و غیره استفاده کردند.
مزایده و تبلیغات
محققین گروه Alibaba مقالهای با عنوان «Real-Time Bidding with Multi-Agent Reinforcement Learningin Display Advertising» منتشر کردند و ادعا کردند که راهکار آنها با عنوان مزایده چند عاملی توزیعی distributed cluster-based multi-agent bidding و مبتنی بر خوشهبندی (DCMAB) نتایج امیدوارکنندهای به دنبال داشته است و به همین دلیل، قصد دارند آن را بهصورت زنده بر روی سامانه TaoBao محک بزنند.
بررسی جزئیات نتایج این آزمایش به کاربران بستگی دارد. سامانه تبلیغاتی تائوبائو محلی است که پس از آغاز یک مزایده توسط فروشندگان، آگهی مربوط به آن به مشتریان نمایش داده میشود. این مسئله را میتوان یک مسئله چندعاملی درنظر گرفت، زیرا مزایده مربوط به هر فروشنده علیه فروشنده دیگر است و اقدامات هر عامل به اقدام سایرین بستگی دارد.
در این پژوهش، فروشندگان و مشتریان در چند گروه خوشهبندی شده بودند تا از پیچیدگیهای محاسباتی کاسته شود. همچنین، فضای وضعیت هر عامل نمایانگر هزینه-فایده آن، فضای اقدام همان مزایده (پیوسته) و پاداش نیز درآمد ناشی از فرستادن تبلیغ به خوشه مشتری مناسب بود.
سوالاتی از قبیل اثر انواع مختلف پاداش (برای مثال، پاداش مبتنی بر نفع شخصی و نفع جمعی) بر درآمد عامل نیز در این مقاله پاسخ داده شدهاند.
بازیها
شناخته شدن الگوریتمهای یادگیری تقویتی عمدتاً به دلیل کاربردهای گسترده آن در بازیها و گاه عملکرد فرابشری این الگوریتمها بوده است.
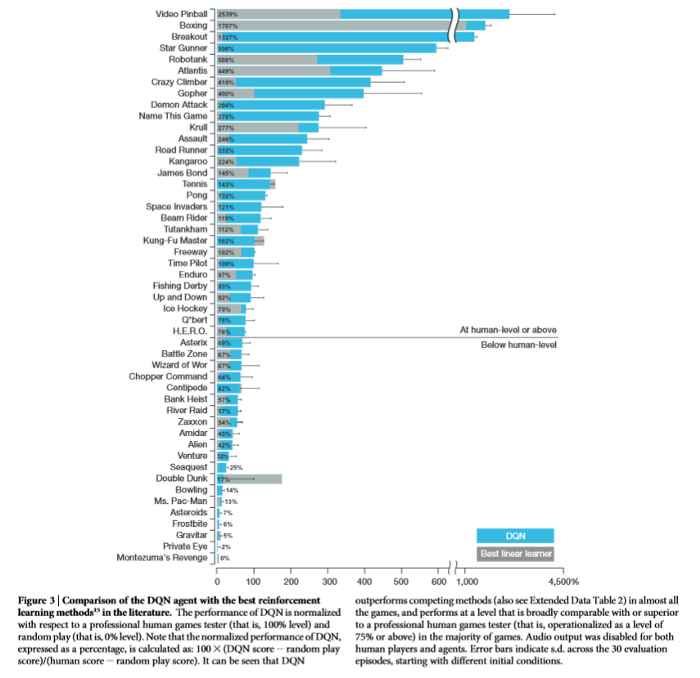
منبع: https://web.stanford.edu/class/psych209/Readings/MnihEtAlHassibis15NatureControlDeepRL.pdf
نامآشناترین الگوریتمها در این حوزه AlphaGo و AlphaGo Zero هستند. برای آموزش الگوریتم آلفاگو دادههای بیشماری از روند بازیهای انسانی جمعآوری و به آن داده شد. این الگوریتم با بهرهگیری از تکنیک جستوجوی درختی مونت کارلو (MCTS) و شبکه ارزش تعبیه شده در شبکه سیاست خود توانست عملکردی فرابشری داشته باشد.
اما کمی بعد از آن، توسعهدهندگان این الگوریتم قدمی به عقب برداشته و تلاش کردند تا با رویکردی بهبودیافته یعنی آموزش الگوریتم از صفر، دوباره این کار را انجام دهد. بدین ترتیب، پژوهشگران عامل جدید خود یعنی AlphaGo Zero را در بازی، رقیب خودش قرار دادند. این الگوریتم جدید درنهایت توانست 100-0 آلفاگو را شکست دهد.
ترکیب یادگیری عمیق
امروزه شاهد تلاشهای روزافزون برای ترکیب یادگیری تقویتی با سایر معماریهای یادگیری عمیق هستیم. برخی از این تلاشها نتایج شگفتانگیزی داشتهاند.
یکی از تأثیرگذارترین پروژهها در این حوزه، ترکیب شبکههای عصبی پیچشی (CNN) با یادگیری تقویتی بود که توسط شرکت DeepMind انجام گرفت. با ترکیب این دو، عامل تصمیمگیرنده به کمک حواس چند بُعدی خود توانایی دیدن محیط را خواهد داشت و نحوه تعامل با محیط را میآموزد.
یکی دیگر از ترکیباتی که برای آزمایش ایدههای جدید از آن استفاده میشود، ترکیب یادگیری تقویتی و شبکههای عصبی بازگشتی (RNN) است. شبکه عصبی بازگشتی یا RNN میتواند اتفاقات را به خاطر بسپارد. وقتی این شبکه عصبی با الگوریتمهای یادگیری تقویتی ترکیب شود، عامل تصمیمگیرنده نیز قادر به یادآوری و به خاطر سپردن اتفاقات خواهد بود. برای مثال، از ترکیب شبکه LSTM (حافظه طولانی کوتاهمدت) با یادگیری تقویتی، شبکه بازگشتی و عمیق Q (DRQN) به دست آمد
که میتواند بازیهای آتاری 2600 را انجام دهد. علاوه براین، ترکیب یادیگری تقویتی و شبکه عصبی بازگشتی در بهینهسازی واکنشهای شیمیایی نیز کاربرد دارد.

منبع: https://www.youtube.com/watch?v=N5oZIO8pE40
DeepMind به ما نشان داد که چگونه برای ساخت برنامههای خود از مدلهای مولد و یادگیری تقویتی بهره ببریم. در این مدل همانند فرآیند آموزش در شبکههای مولد تخاصمی (GAN)، عامل درنتیجه تقابل با سایر عوامل آموزش میبیند و با کمک سیگنالهایی که به عنوان پاداش دریافت میکند، به جای پخش کردن گرادیانها در فضای ورودی، اقدامات خود را بهبود میبخشد.
آنچه باید پیش از استفاده از یادگیری تقویتی بدانید
در ادامه موارد و نکاتی ذکر شدهاند که پیشنیاز بهکارگیری یادگیری تقویتی در حل مسائل مختلف میباشند:
شناخت مسئله مدنظر
هیچ الزامی برای استفاده از یادگیری تقویتی برای حل یک مسئله وجود ندارد و حتی گاه این روش برای حل مسئلهای که با آن مواجهیم، مناسب نیست. بهتر است پیش از بهکارگیری یادگیری تقویتی بررسی کنید که آیا مسئله موردنظر شما ویژگیهای لازم را دارد یا خیر. برخی از این ویژگیها عبارتند از:
- 1. آزمون و خطا (بهبود کیفیت یادگیری در اثر دریافت بازخورد از محیط)
- 2. پاداش متأخر
- 3. امکان مدلسازی در قالب MDP
- 4. موضوع کنترل مطرح باشد
محیط شبیهسازی شده
پیش از شروع به کار یک الگوریتم یادگیری تقویتی، روش حل مسئله آن باید بارها تکرار شود. مطمئناً ما نمیخواهیم عامل یادگیری تقویتی که پشت یک اتومبیل خودران قرار گرفته، در وسط بزرگراه، روشهای مختلف حل مسئله را امتحان کند. بنابراین، به یک محیط شبیهسازی شده که بازتاب دقیقی از دنیای واقعی باشد، نیاز داریم.
فرآیند تصمیمگیری مارکوف (MDP)
شما باید بتوانید مسئله مدنظر خود را در قالب یک MDP مدلسازی کنید. بدین منظور باید فضای وضعیت، فضای اقدام، تابع پاداش و سایر موارد موردنیاز را طراحی کنید. عامل تصمیمگیرنده شما نیز تحت قیود تعریف شده و براساس پاداشی که دریافت کرده، اقداماتی را در پیش میگیرد. اگر طراحی این موارد دقیق و متناسب با هدف نباشد، ممکن است به نتایج دلخواهتان دست پیدا نکنید.
الگوریتمها
در دنیای یادگیری تقویتی الگوریتمهای زیادی وجود دارد. اما برای انتخاب الگوریتم مناسب باید از خود بپرسید که آیا میخواهید الگوریتم مستقیماً سیاست را پیدا کند یا میخواهید براساس تابع ارزش آموزش ببیند؟ میخواهید الگوریتم شما مبتنی بر مدل باشد یا بدون مدل؟ آیا میخواهید برای حل این مسئله، علاوه بر یادگیری تقویتی از سایر شبکههای عصبی یا روشها نیز کمک بگیرید یا خیر؟
بهمنظور تصمیمگیری درست و واقعبینانه، باید از کاستیهای یادگیری تقویتی نیز آگاه باشید. با مراجعه به این لینک میتوانید نقاط ضعف این الگوریتمها را نیز بشناسید.
بخش چهارم: آموزه هایی از سایر علوم
یادگیری تقویتی رابطه نزدیکی با علوم روانشناسی، زیستشناسی و عصبشناسی دارد. اگر کمی دقیقتر بنگرید، تنها کاری که یک عامل تصمیمگیرنده در الگوریتم یادگیری تقویتی انجام میدهد، آزمون و خطاست. این عامل بر اساس پاداشی که از محیط دریافت میکند، میآموزد که اقداماتش درست بودهاند یا اشتباه. این دقیقاً همان مسیری است که یک انسان برای یادگیری یک مسئله بارها و بارها طی میکند. علاوه براین، ما هر روز با مسائلی چون اکتشاف و انتفاع و تخصیص اعتبار مواجه میشویم و سعی در ارائه یک مدل از محیط اطراف خود داریم.
برخی نظریات اقتصادی نیز گاه وارد دنیای یادگیری تقویتی میشوند. برای مثال، در حوزه تحلیل یادگیری تقویتی چندعاملی (MARL) از نظریه بازیها کمک میگیریم. نظریه بازیها که توسط جان نَش ارائه شده است، در درک تعاملات عوامل حاضر در یک سیستم به ما کمک میکند. علاوه بر کاربرد نظریه بازیها در MARL، فرآیندهای تصمیمگیری مارکوف با مشاهدهپذیری جزئی (POMDP) نیز در فهم موضوعات اقتصادی از جمله ساختار بازارها (انحصار یک جانبه، انحصار چند جانبه و غیره)، اثرات خارجی و اطلاعات نامتقارن به کمک اقتصاددانان میروند.
یادگیری تقویتی را از کجا شروع کنیم؟
آموزش یادگیری تقویتی با توجه به اینکه حوزه وسیعی است و روش و تکنیکهای مختلفی دارد ممکن است در ابتدا بسیار گیجکننده و پیچیده باشد. به خصوص اگر شروع به خواندن تحقیقات جدید با ترفندها و جزئیات آنها برای به نتیجه رساندن کارها بکنید که همه چیز پیچیدهتر هم خواهد شد. توصیه میگردد خود را گیج نکنید و به مرور و براساس دستورالعمل زیر یادگیری تقویتی را فرا بگیرید.
- مشاهده دوره آموزشی زیر در سایت Coursera
Practical Reinforcement Learning course from Coursera
این دوره فهم مفاهیم اصلی یادگیری تقویتی را در ذهن شما به چالش میکشد و از روش ساده Cross Entropy شروع شده و به تدریج به سمت روشهای تکرار سیاست، تکرار ارزش، یادگیری Q و SARSA میرود. نیمه دوم دوره نیز اختصاص به فراگیری Deep Q Networks و Actor-Critic Algorithms مییابد.
- مطالعه کتاب مرجع Reinforcement Learning-An Introduction از R Sutton و AG Barto. این کتاب به عنوان یکی از کتابهای مرجع در زمینه یادگیری تقویتی معرفی شده است که در حال حاضر مرجع بسیاری از دانشگاهها برای تدریس دروس مرتبط با یادگیری تقویتی نیز میباشد.

- تمام مفاهیم مربوط به یادگیری تقویتی تا وارد اجرا نشوید و آنها را کدگذاری ننماید شاید بدرستی برایتان قابل درک نباشد. بنابراین توصیه اکید میگردد در حین مشاهده فیلم آموزشی و یا مطالعه کتابهای مرجع، توابع یادگیری تقویتی با پایتون و یا متلب را اجرا و اشکالزدایی نمایید و مدام این فرایند را تکرار کنید. برای این زمینه بسترهایی نظیر DeepMind Lab و OpenAI gym برای طراحی و پیادهسازی انواع الگوریتمهای یادگیری عمیق فراهم شده است.
البته لازم به ذکر است کتابها، فیلمهای آموزشی و مقالههای یادگیری تقویتی بسیار زیاد است که ما در این جا تنها مواردی را به طور نمونه معرفی کردیم که تاکنون دانشآموختگان زیادی از آنها استفاده کرده و نتیجه گرفتند. در صورتیکه شما هم منابعی را میشناسید که توانسته به شما در این زمینه کمک نماید، ممنون میشویم در قسمت نظرات با ما به اشتراک گذارید.
دستآوردهای احتمالی یادگیری تقویتی در آینده
یادگیری تقویتی هنوز مشکلات و نقصهای زیادی دارد و استفاده از آن آسان نیست. اما با توجه به تلاشهای روزافزونی که بهمنظور رفع این نقصها صورت میگیرد، یادگیری تقویتی میتواند در آنیده در حوزههای زیر تأثیرگذار باشد:
همکاری با انسانها
شاید گفتن اینکه یادگیری تقویتی در آینده میتواند بخشی از دنیای هوش مصنوعی عمومی باشد، زیادهروی بهنظر برسد، اما یادگیری تقویتی توانایی همکاری و همراهی با انسان را دارد. برای مثال فرض کنید ربات یا دستیار مجازی که با شما کار میکند، برای اقدام و یا تصمیم بعدی خود، اقدامات پیشین شما را مدنظر قرار دهد. واقعاً شگفتانگیز نیست؟
برآورد عواقب استراتژیها مختلف
در دنیای ما زمان به عقب برنمیگردد و هر اتفاق تنها یکبار رخ میدهد و همین است که زندگی را اعجاببرانگیز میسازد. اما گاهی میخواهیم بدانیم اگر در گذشته تصمیمی متفاوت گرفته بودیم، شرایط کنونی چگونه بود؟ یا اگر مربی تیم ملی کرواسی استراتژی متفاوتی را در پیش میگرفت، شانس این تیم برای پیروزی در جامجهانی 2018 بیشتر میشد؟ البته برای انجام چنین برآوردهایی باید تابع انتقال و محیط را بسیار دقیق مدلسازی کنیم و تعاملات میان محیط و عامل را تجزیه و تحلیل کنیم. کاری که درحالحاضر غیرممکن بهنظر میرسد.
نتیجهگیری
در این مقاله تنها چند مثال از کاربرد یادگیری تقویتی در صنایع مختلف را ذکر کردیم، اما شما نباید ذهن خود را به این مثالها محدود کنید و مثل همیشه، ابتدا باید بهطور کاملاً اصولی و دقیق طبیعت و ذات الگوریتمهای یادگیری تقویتی و مسئله خود را بشناسید.
اگر تصمیمگیری یکی از وظایف شغلی شماست، امیداوارم این مقاله شما را به سوی بررسی شرایط و پیدا کردن راهی برای استفاده از یادگیری تقویتی سوق داده باشد. و اگر پژوهشگر هستید، امیدوارم پذیرفته باشید که یادگیری تقویتی علیرغم تمام کاستیهایش، پتانسیل زیادی برای بهبود یافتن دارد و فرصتهای زیادی برای تحقیق و پژوهش در این زمینه فراهم است.
اگر شما کاربردی از یادگیری تقویتی میشناسید که در مطلب به آن اشاره نشده، در قسمت کامنتها به ما معرفی کنید.





