
یادگیری نیمه نظارتی چیست؟ هر آنچه باید درباره این رویکرد بدانید
 تیم تحریریه
تیم تحریریه- ۲۱ فروردین ۱۴۰۱
در دهههای اخیر، یادگیری نیمه نظارتی به عنوان یک مسیر جدید و اثرگذار در حوزه یادگیری ماشین ظاهر شده است. این نوع یادگیری با بهرهگیری از قابلیتهای دادههای برچسب خورده در کنار حجم زیادی از دادههای برچسب نخورده، فرایند آموزش مدلهای یادگیری ماشین را به میزان قابل توجهی بهبود بخشیده است. لزوم استفاده از یادگیری نیمه نظارتی به دلیل محدودیت دسترسی به حجم بالای دادههای برچسب خورده در عمل بسیار حس میشود. بدین منظور، این بخش به معرفی یادگیری نیمه نظارتی، نحوه کارکرد و روشهای آن و کاربرد این نوع از یادگیری در زمینههای مختلف اختصاص مییابد.
یادگیری نیمه نظارتی چیست؟
در یادگیری ماشین، برچسبگذاری دادهها، به فرایند شناسایی دادههای خام (تصاویر، فایلهای ویدئویی و غیره) و افزودن یک یا چند برچسب معنادار و یا آموزنده جهت ارائه اطلاعات در مورد آن اطلاق میشود. برچسبها ممکن است حاوی اطلاعاتی نظیر وجود پرنده یا ماشین در یک عکس، تلفظ یک کلمه در یک فایل صوتی و یا وجود تومور در یک عکس اشعه ایکس باشند.

اطلاعاتی که در قالب برچسب دادهها ارائه میشود، نقش بسزایی در آموزش مدلهای یادگیری ماشین در حوزههای مختلف هوش مصنوعی نظیر بینایی ماشین، پردازش زبان طبیعی و پردازش گفتار ایفا مینماید. بسیاری از موفقیتهای اخیر در آموزش شبکههای یادگیری عمیق، وجود دادههای برچسبگذاری شده است. با این حال جمعآوری این مجموعه داده بسیار زمانبر، نیازمند نیروی متخصص و یا به طور کلی گران میباشد. علاوه بر این، در خیلی از اوقات، برچسب دادهها حاوی اطلاعات خصوصی است که تأمین امنیت فرآیندهای گردآوری و نگهداری آنها بسیار پرچالش است.
روش یادگیری نیمه نظارتی به عنوان یکی از مدلهای یادگیری ماشین، راهکاری مؤثر جهت رفع چالشهای مربوط به دادههای برچسبدار میباشد. در یادگیری نیمه نظارتی به طور همزمان از دادههای برچسب خورده و از دادههای برچسب نخورده استفاده میشود تا بتوان دقت یادگیری را بهبود بخشید. این نوع از مدل یادگیری به عنوان روشی که میتواند از دادههای بدون برچسب بیشترین استفاده را بکند، از منظر کاربرد عملی از ارزش فوقالعادهای برخوردار است.
چه زمانی یادگیری نیمه نظارتی میتواند کار کند؟
یک سوال طبیعی مطرح میشود: آیا یادگیری نیمه نظارتی معنادار است؟ بهطور دقیقتر: در مقایسه با یک الگوریتم نظارتشده که فقط از دادههای برچسب دار استفاده میکند، آیا میتوان امیدوار بود که با در نظر گرفتن نقاط بدون برچسب، پیشبینی دقیقتری داشت؟ پاسخ این سال همانطور که حدس میزنید، بله است. بااینحال، یک پیشنیاز مهم وجود دارد: توزیع مثالها، که دادههای بدون برچسب به روشن شدن آنها کمک میکند و برای مشکل طبقهبندی مرتبط باشد.
در یک فرمول ریاضیتر، میتوان گفت که دانش مربوط به p(x) که فرد از طریق دادههای بدون برچسب به دست میآورد باید حاوی اطلاعاتی باشد که در استنتاج p(y|x) مفید باشد. اگر اینطور نباشد، یادگیری نیمه نظارتی باعث بهبودی نسبت به یادگیری تحت نظارت نخواهد شد. حتی ممکن است این اتفاق بیفتد که استفاده از دادههای بدون برچسب، دقت پیشبینی را با گمراه کردن استنتاج کاهش دهد.
بنابراین نباید خیلی تعجب کرد که برای اینکه کسی با یادگیری نیمه نظارتی کار کند، فرضیات خاصی را در نظر بگیرد. در این زمینه، توجه داشته باشید که یادگیری با نظارت ساده نیز باید بر مفروضات تکیه کند. و رسمی کردن مفروضات در چارچوب سبک PAC، یکی از رایجترین فرضیات است که میتوان آن را بهصورت زیر فرموله کرد.
فرض یکنواختی یادگیری تحت نظارت: اگر دونقطه x1، x2 نزدیک هستند، خروجیهای مربوطه y1، y2 نیز باید نزدیک باشند.
مفروضات موردنیاز برای یادگیری نیمه نظارتی چیست؟
برای استفاده از دادههای بدون برچسب، باید برخی از رابطهها با توزیع اساسی دادهها وجود داشته باشد. الگوریتمهای یادگیری نیمه نظارتشده حداقل از یکی از مفروضات زیر استفاده میکنند:
- فرض تداوم
نقاطی که به یکدیگر نزدیک هستند بهاحتمالزیاد دارای یک برچسب مشترک هستند. این نیز بهطورکلی در یادگیری نظارتشده فرض میشود و ترجیحی برای مرزهای تصمیمگیری هندسی ساده ایجاد میکند. در مورد یادگیری نیمه نظارتی، فرض یکنواختی علاوه بر این، ترجیحی برای مرزهای تصمیمگیری در مناطق کم تراکم ایجاد میکند، بنابراین نقاط کمی به هم نزدیک هستند اما در کلاسهای مختلف.
- فرض خوشهای
در این فرض دادهها تمایل به تشکیل خوشههای مجزا دارند، و نقاط در همان خوشه بیشتر احتمال دارد یک برچسب را به اشتراک بگذارند (اگرچه دادههایی که یک برچسب را به اشتراک میگذارند ممکن است در چندین خوشه پخش شوند). اینیک مورد خاص از فرض همواری است و باعث یادگیری ویژگی با الگوریتمهای خوشهبندی میشود.

- فرض چندگانه
دادهها تقریباً روی یک مسیر چندگانه با ابعاد بسیار کمتر از فضای ورودی قرار دارند. در این مورد، یادگیری چندگانه با استفاده از دادههای برچسبگذاری و بدون برچسب میتواند از چالشهای فرض خوشهای جلوگیری کند. سپس یادگیری میتواند با استفاده از فواصل و چگالیهای تعریفشده در فرض چندگانه ادامه یابد.
مقایسه یادگیری نیمه نظارتی با یادگیریهای با نظارت و بدون نظارت
از منظر مفهومی، یادگیری نیمه نظارتی در بین یادگیری با نظارت و یادگیری بدون نظارت قرار میگیرد و روشهایی مبتنی بر ترکیب مزیتهای هر دو روش ارائه داده است. بنابراین جهت درک بهتر یادگیری نیمه نظارتی بهتر است به تفاوت آن با سایر یادگیریها و بررسی جایگاهش در بین یادگیری با نظارت و بدون نظارت پرداخته شود.
[irp posts=”16210″]
یادگیری با نظارت (Supervised Learning): یادگیری با نظارت فرایندی است که براساس دادههای برچسبدار عمل مینماید. بدین معنی که ما در این نوع روش، متغیرهای ورودی (X) و متغیر خروجی متناظرشان (Y) را داریم و از الگوریتمهای یادگیری با نظارت برای دستیابی به تابع نگاشت متغیرهای ورودی به خروجی استفاده میکنیم؛ Y=f(x). هدف از این تابع نگاشت، پیشبینی متغیر خروجی Y برای داده جدید X میباشد.
با افزایش متغیرهای ورودی و خروجی (دادههای برچسبدار)، فرایند یادگیری الگوریتم برای دستیابی به نگاشت بهینه و یا نزدیک به بهینه، تسریع مییابد. دلیل اینکه این روش یادگیری “با نظارت” نامگذاری شده، وجه شباهت فرایند یادگیری به معلمی است که دائما بر این فرایند نظارت مینماید. در طول آموزش، زمانیکه الگوریتم خروجی Y را پیشبینی میکند، مدل یادگیری مانند یک معلم و با توجه به آگاهی از جواب درست، خروجی را در صورت لزوم اصلاح مینماید.
[irp posts=”25664″]
یادگیری بدون نظارت (Unsupervised Learning): در این نوع از یادگیری، برخلاف یادگیری با نظارت دادههای مشخصی از قبل وجود ندارد. در عوض، باید به مدل اجازه دهید تا برای کشف اطلاعات به تنهایی کار کند. به عبارت دیگر، هدف در این نوع یادگیری، دستیابی به تابع نگاشت و ایجاد ارتباط بین روردی و خروجی نیست، بلکه تنها دستهبندی دادهها مهم است. بنابراین این نوع از یادگیری به دنبال ساختار مشخص بین دادهها میگردد.
[irp posts=”25600″]به عنوان نمونه، یک تحلیلگر بازار را در نظر بگیرید که سعی میکند مصرفکنندگان خود را بخشبندی کند، روشهای خوشهبندی بدون نظارت میتواند نقطه شروع خوبی برای تحلیل آنها باشد. در موقعیتهایی که پیشنهاد دادن روندها در دادهها برای انسان غیرممکن یا غیرعملی است، یادگیری بدون نظارت میتواند بینشهای اولیهای را ارائه دهد که جهت آزمایش فرضیههای فردی مورد استفاده قرار میگیرد.

یادگیری نیمه نظارتی (Semi-supervised Learning): بزرگترین تفاوت بین یادگیری ماشینی با نظارت و بدون نظارت در این است که الگوریتمهای یادگیری با نظارت بر روی مجموعه دادههایی آموزش میبینند که شامل برچسبهایی میباشد که توسط مهندس یادگیری ماشین یا دانشمند داده اضافه شده است. این یک فرآیند بسیار پرهزینه است، به خصوص زمانی که با حجم زیادی از داده ها سروکار داریم. از سوی دیگر، الگوریتم های یادگیری ماشینی بدون نظارت، بر روی داده های بدون برچسب آموزش می بینند و باید اهمیت ویژگی را به تنهایی بر اساس الگوهای ذاتی در دادهها تعیین کنند. عیب الگوریتمهای یادگیری بدون نظارت، طیف کاربردی محدود آنها است.
برای مقابله با این معایب، مفهوم یادگیری نیمه نظارتی معرفی شد. در این نوع یادگیری، الگوریتم بر اساس ترکیبی از دادههای برچسبدار و بدون برچسب آموزش داده می شود. به طور معمول، این ترکیب حاوی مقدار بسیار کمی از دادههای برچسبدار و مقدار بسیار زیادی از دادههای بدون برچسب خواهد بود. در این نوع از یادگیری، میتوان از تکنیکهای یادگیری بدون نظارت برای کشف و یادگیری ساختار در متغیرهای ورودی استفاده کرد. همچنین میتوان از تکنیکهای یادگیری با نظارت برای انجام بهترین پیشبینیها برای دادههای بدون برچسب استفاده نمود، بطوریکه آن دادهها را به الگوریتم یادگیری نظارتشده به عنوان دادههای آموزشی برگردانید و از مدل برای پیشبینی دادههای جدید استفاده کنید.
یادگیری نیمه نظارتی چگونه کار میکند؟
همانطور که در قسمتهای پیشین نیز بارها اشاره شد، مجموعه داده برای آموزش مدلهای یادگیری نیمه نظارتی متشکل از دادههای برچسب خورده و دادههای برچسب نخورده است که معمولا بیشترین مقدار را دادههای برچسب نخورده تشکیل میدهد. بطور کلی فرایند یادگیری نیمه نظارتی را میتوان در مراحل زیر خلاصه نمود.
- مدل توسط دادههای برچسب خورده مشابه با یادگیری با نظارت آموزش میبیند و این روند تا زمانی ادامه پیدا خواهد کرد که به نتایج مطلوبی دست پیدا نماید.
- سپس مدلِ تا حدودی آموزش دیده، بر روی دادههای برچسب نخورده اجرا میشود تا بتوان برچسب آنها را پیشبینی نمود. به این فرایند اصطلاحاً فرایند شبه برچسب زدن (Pseudo labelling) میگویند.
- سپس دادههای برچسب دار اولیه و دادههای شبه برچسب زده شده مرحله پیشین با هم تجمیع شده و جهت آموزش مدل مورد استفاده قرار میگیرند.
- به همان ترتیبی که در مجموعهدادهی کاملاً برچسبدار عمل شد، مدل آموزش داده میشود.

لازم به ذکر است که مراحل ذکر شده مربوط به روش خود یادگیرنده Self-training در یادگیری نیمه نظارتی است. روشهای متفاوت دیگری نیز وجود دارد که مراحل کاری آنها متفات میباشد که به طور مفصل در بخش «روشهای یادگیری نیمه نظارتی» شرح داده میشوند.
اهمیت یادگیری نیمه نظارتی
در بسیاری از کاربردها، جمعآوری دادههای برچسبدار یا برچسب زدن به دادهها کاری زمانبر است. در حالیکه دادههای بدون برچسب به آسانی در دسترس هستند. بنابراین پیدا کردن روشی که بتوان از دادههای بدون برچسب بیشترین استفاده را کرد، در کاربردهای عملی ارزش فوقالعادهای دارد. به عنوان مثال، در کاربردهای متنی، تشخیص هرزنامه از نامههای عادی، دستهبندی اسناد و صفحات وب، ردهبندی و توصیه صفحات بر مبنای علاقه کاربر، از این نمونه کاربردها است.
بنابریان نیاز به یک روش نیمهنظارتی که بتواند با استفاده از دادههای بدون برچسب (که معمولا تعدا زیادی هم در دسترس است) کمبود تعداد دادههای برچسبدار را جبران کند، کاملا احساس میشود. اما اهمیت یادگیری نیمه نظارتی کمی فراتر از کاربرد در موارد بالا است. به نحوی میتوان گفت که بیشتر یادگیری طبیعی در انسان و حیوان به صورت نیمه نظارتی صورت میگیرد. ما در جهانی زندگی میکنیم که به طور پیوسته در معرض سیگنالهایی از محیط است. این سیگنالها در نقش دادههای بدون برچسب عمل میکنند که به مقدار زیاد در دسترس هستند. از طرف دیگر توانایی انسان در مسائل غیرنظارتی مثل خوشهبندی نشان میدهد که دادههای بدون برچسب حاوی اطلاعات مفیدی هستند.
همچنین از دیگر فواید ارزشمند یادگیری نیمه نظارتی در کنار کاهش نیاز به دادههای برچسب خورده، استفاده از قابلیتهای یادگیری با نظارت برای بهبود فرایند یادگیری میباشد که میتوان از آن در برچسبگذاری دادههای بدون برچسب استفاده نمود و بطور همزمان استفاده از قابلیتهای یادگیری بدون نظارت و کشف ساختارهای موجود در دادهها است.
یادگیری نیمه نظارتی در داده کاوی
ادغام تکنیکهای خوشهبندی Clustering و طبقهبندی Classification، دو تا از تکنیکهای محبوب دادهکاوی، از رویکردهای مورد توجه در یادگیری نیمه نظارتی به شمار میآید. خوشهبندی براساس یادگیری بدون نظارت، دادهها را براساس شباهتهایشان گروهبندی میکند. به بیان دیگر، خوشهبندی مرتبطترین دادهها با یکدیگر را در یک گروه قرار میدهد، بدون اینکه بدانیم هر گروه به چه چیزی دلالت میکند. از طرف دیگر، طبقهبندی مشابه خوشهبندی دادهها را در دستههای مختلف قرار میدهد، با این تفاوت که هر کدام از دستهها دارای برچسب مشخصی است. به عبارت دیگر، طبقهبندی مبتنی بر یادگیری با نظارت است که دادهها را در دستههای مشخص (دارای لیبل) قرار میدهد. در یادگیری نیمه نظارتی میتوان از طریق خوشهبندی، دادهها را دستهبندی نمود. سپس آنها را برچسبگذاری کرد و برای آموزش مدل یادگیری ماشینی با نظارت جهت طبقهبندی مورد استفاده قرار داد.
همچنین هر یک میتوانند به طور جداگانه از رویکرد یادگیری نیمه نظارتی بهره ببرند. در مسائل طبقهبندی مبتنی بر یادگیری نیمه نظارتی، مدل براساس هر دو مجموعه داده با برچسب و بدون برچسب آموزش میبیند و در اکثر اوقات کارایی آن از مدلی که تنها با دادههای برچسبدار آموزش داده باشد، بهتر است. اما در مسائل خوشهبندی نیمه نظارتی نیز میتوان از دادههای برچسبدار برای انتخاب مناسبتر شاخصهای هر خوشه استفاده نمود. در اینصورت به طور معمول، خوشه بندی بهتری نسبت به زمانی که خوشهبندی فقط با دادههای بدون برچسب انجام می شود، حاصل میگیرد.

یادگیری نیمه نظارتی در هوش مصنوعی
امروزه، در هر زمینهای که صحبت از هوش مصنوعی میشود، عبارت یادگیری ماشین نیز به چشم میخورد. هوش مصنوعی به کمک یادگیری ماشین توانسته رشد چشمگیری در عملکرد خود ایجاد نماید. با توجه به اینکه یادگیری نیمه نظارتی نیز یکی از روشهای یادگیری ماشین است بنابراین الگوریتم یادگیری نیمه نظارتی در حوزههای مختلف هوش مصنوعی نظیر بینایی ماشین، پردازش زبان طبیعی و پردازش گفتار استفادههای فراوانی شده است. در ادامه، به چند مورد برجسته از کاربردهای یادگیری نیمه نظارتی در هوش مصنوعی اشاره میشود:
تجزیه و تحلیل گفتار: برچسب زدن فایلهای صوتی، کاری بس فشرده، زمانبر و خستهکننده است. یادگیری نیمه نظارتی یک رویکرد بسیار مناسب برای حل چالشهای موجود در این زمینه است.
طبقهبندی محتوای اینترنتی: برچسبگذاری هر صفحه وب فرآیندی غیرعملی و غیرقابل اجرا است. بنابراین الگوریتم یادگیری نیمه نظارتی در این زمینه کاربرد فراوانی دارد. در حال حاضر، الگوریتم جستجوی گوگل از یک نوع یادگیری نیمه نظارتی برای رتبهبندی ارتباط یک صفحه وب برای یک جستار معین استفاده میکند.
طبقهبندی توالی پروتئین: با توجه به این که رشته های DNA معمولاً از نظر اندازه بسیار بزرگ هستند، یادگیری نیمه نظارتی در این زمینه میتواند بسیار مثمر ثمر واقع شود.
تشخیص تقلب: با توجه به اینکه اغلب دادههای برچسب خورده در این زمینه بسیار کم است، بنابراین میتوان به خوبی از یادگیری نیمه نظارتی جهت آموزش مدلهای تشخیصدهنده کلاهبرداری استفاده نمود.
فرضیات اساسی در یادگیری نیمهنظارتی
جهت مفید واقع شدن یادگیری نیمه نظارتی در عمل، لازم است فرضهایی برقرار باشد، در غیر اینصورت دادههای بدون برچسب آنطور که باید بکار نمیآیند و موجب بهبود نخواهند شد. برخی از رایجترین فرضها به شرح زیر میباشند:
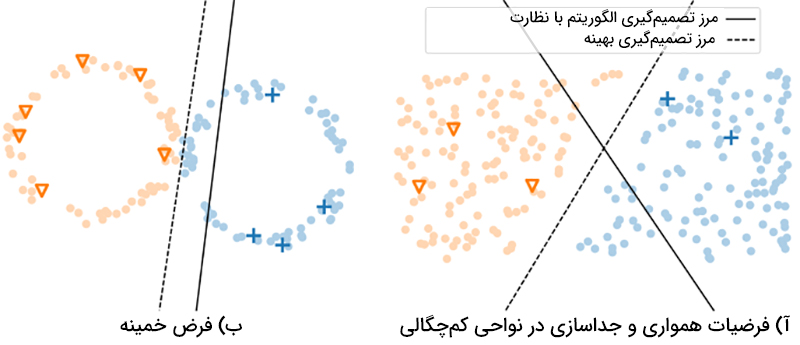
فرض همواری نیمهنظارتی: اگر دو نقطه در یک ناحیه چگال نزدیک هم باشند، خروجی متناظر آن دو نیز نزدیک به هم است.
اگر دو نقطه در ناحیه چگال توسط یک مسیر به هم متصل باشند، آنگاه برچسبهای آن دو نیز نزدیک به هم است. به بیان دیگر این دو داده در یک خوشه قرار گرفتهاند. ولی اگر دو نقطه به وسیله یک ناحیه کمچگال از هم جدا باشند، لزومی ندارد برچسبهای آن دو یکی باشد.
فرض جداسازی در نواحی کمچگالی: مرز تصمیمگیری معمولا در نواحی کم چگال قرار دارد.
فرض خمینه: دادهها که معمولا دارای ابعاد زیادی هستند، تقریبا در یک خمینه با بعد کم قرار میگیرند. منظور از خمینه، سطحی از فضا است که دادههای مساله این سطح را میسازند. در روشهای مبتنی بر گراف که در بخش آتی به آن پرداخته میشود، با استفاده از دادهها، گرافی ساخته میشود که گراف تخمینی از خمینه میباشد. برای درک بهتر این فرض، اطلس جغرافیایی را در نظر بگیرید. کره زمین یک کره است که در فضای سه بعدی قرار میگیرد. اما اگر در مقیاس کوچک به یک نقطه از سطح این کره و همسایگیهای کوچک اطراف آن بنگریم آن را به صورت صاف و به صورت یک صفحه میبینیم. یعنی در مقیاس کوچک دو بعدی است. اطلسهای جغرافیایی با استفاده از همین ایده به وجود آمدهاند. در اصطلاح میگوییم که سطح کره زمین یک خمینه دو بعدی است.
روشهای یادگیری نیمه نظارتی
انواع یادگیری نیمه نظارتی بواسطه روشها و الگوریتمهای متعددی تعریف میشود که در این بخش به طور اجمالی در مورد آنها شرح داده میشود:
یادگیری نیمه نظارتی خود یادگیرنده
یکی از روشهایی که عموما برای یادگیری نیمه نظارتی استفاده میشود، روش مرسوم به خود یادگیرنده است. در این روش ابتدا یک طبقهبند، با تعداد کم نمونههای آموزشی آموزش دیده و سپس طبقهبند برای طبقهبندی دادههای بدون برچسب استفاده میشود. دادههای برچسب زده شده جدید که قابلیت اطمینان بالایی دارند به همراه برچسبشان به مجموعه آموزشی افزوده شده و طبقهبند با این مجموعه آموزشی دوباره آموزش داده میشود و این روند تکرار میشود. در واقع طبقهبند از پیشبینیهای خودش برای آموزش خود استفاده میکند.
یادگیری نیمه نظارتی آموزش همکارانه
در روش آموزش همکارانه سه فرض اولیه به شرح زیر وجود دارد که لازم است در ابتدا این سه فرض بیان شوند:
- ویژگیها بتوانند به دو زیر مجموعه افراز شوند.
- هر کدام از این دو زیر مجموعه برای آموزش یک طبقهبند خوب مناسب باشند
- هر کدام از این دو زیرمجموعه با توجه به کلاسها، باید استقلال کافی داشته باشند.
در ابتدا دو طبقهبند مجزا، به ترتیب روی دو مجموعه زیر ویژگی آموزش میبینند. سپس هر طبقهبند دادههای بدون برچسب را طبقهبندی میکند و طبقهبند دیگری با نمونههای اندک تازه برچسبخوردهای که قابلیت اطمینان بالایی دارند، آموزش میبیند. هر کدام از طبقهبندها با نمونههای آموزشی اضافه شده که به وسیله طبقهبند دیگر، ارائه میشود دوباره آموزش میبیند و این روند تکرار شده و ادامه مییابد.
در روش آموزش همکارانه، دادههای بدون برچسب با کاهش اندازه فضا، به عمل طبقهبندی کمک میکنند. بنابراین، دو طبقهبند باید بر روی دادههای زیاد بدون برچسب به خوبی دادههای برچسبدار توافق داشته باشند.

مدلهای مولد نیمه نظارتی
یک دسته از الگوریتمهای یادگیری نیمه نظارتی با بسط مدلهای مولد طراحی میشوند تا از دو مجموعه برچسبدار و بدون برچسب استفاده کنند. مدلهای مولد فرض میکنند که نمونهها از یک توزیع تصادفی نمونهبرداری شدهاند. بنابراین پارامترهای مدل به گونهای انتخاب میشوند که احتمال تولید نمونههای آموزشی بیشینه شود. به بیان دیگر، مدلهای مولد میتوانند با خلاصهسازی توزیع دادههای ورودی، متغیرهای جدید و قابل قبولی تولید کنند که در برازش (Fit) قابل استفاده باشد و بتواند دقت یادگیری را به بهبود بخشد.
از نقطه نظر احتمالی، نمونههای بدون برچسب، توزیع کلی تمام دستهها در کنار یکدیگر را نشان میدهد، اگر بتوان به جواب این سوال دست پیدا کرد که توزیع نمونههای هر یک از دستهها چگونه است، میتوان مدل مخلوط را به اجزای تشکیلدهنده آن تجزیه کرد. در حوزه یادگیری نظارتی، روشهای مولد بر حسب کاربردهای مختلف، گونههای مختلفی پیدا کردهاند که میتوان به مدلهای مخلوط گاوسیGaussian Mixture Model ، مدلهای بیز سادهNaïve Bayes و مدلهای پنهان مارکوفHidden Markov Model اشاره کرد که به ترتیب در جداسازی تصاویر، طبقهبندی متون و بازشناسی گفتار استفاده عام دارند. بیشینهسازی امید (EMExpectation-Maximization ) رایجترین الگوریتم مورد استفاده برای حل این مدل میباشد.
ماشین بردار پشتیبان نیمه نظارتی
ماشین بردار پشتیبان نیمه نظارتی، حالت گسترش یافته ماشین بردار پشتیبانSupport-vector machine استاندارد است که دادههای بدون برچسب را به کار میگیرد. در ماشین بردار پشتیبان استاندارد فقط از دادههای برچسبدار استفاده میشود که هدف یافتن مرکز خطی حاشیهای بیشینه میباشد. در ماشین بردار پشتیبان نیمه نظارتی، دادههای بدون برچسب نیز استفاده میشود. این ماشین بردار پشتیبان را TSVMTransductive Support Vector machine نیز مینامند.
در این روش ابتدا یک ماشین بردار پشتیبان، با دادههای کم آموزش دیده و مرز تصمیم اولیه مشخص میشود. سپس یک یا چند نمونه داده بدون برچسب در نظر گرفته میشود. هدف یافتن یک برچسب برای دادههای بدون برچسب است به طوری که مرز تصمیم، بیشترین فاصله را از هر دو طرف دادههای برچسبدار اولیه و دادههای بدون برچسبی که تازه بروی آنها برچسب زده شده، داشته باشد. این روش جز روشهای مبتنی بر فرض جداسازی کم چگالی است.

روشهای مبتنی بر گراف
روشهای نیمه نظارتی مبتنی بر گراف، از یک گراف استفاده میکنند که گرهها نشاندهنده نمونههای برچسبدار یا بدون برچسب مجموعه دادهها میباشند و یالها که ممکن است وزندار باشند، نشاندهنده شباهت نمونهها میباشد. هنگامی که گراف ساخته میشود، یادگیری شروع به اختصاص دادن مقادیر به گرههای گراف میکند. معمولا یالهای گراف بدون جهت هستند. اگر مقدار وزن یال بین دو گره بزرگ باشد نشاندهنده یکسان بودن برچسب دو گره میباشد. بنابراین وزنها یالها از اهمیت فراوانی برخوردار است. این روش در صورتی مؤثر میباشد که فرض همواری نیمهنظارتی و فرض خمینه در حالت ضعیف، همزمان برقرار باشد.

برخی از کتابهای یادگیری نیمه نظارتی
مراجع و منابع مختلفی در مورد یادگیری نیمهنظارتی وجود دارد که در این بخش به دو تا از رایجترین منابع در این زمینه اشاره میشود.
نام کتاب: Semi-Supervised Learning
نویسندگان: Olivier Chapelle،Bernhard Scholkopf و Alexander Zien
سال انتشار: 2006

این کتاب از جمله کتابهای مرجع در زمینه یادگیری نیمه نظارتی به شمار میرود که خواننده را اصطلاحا به یک تور در زمینه تحقیقات یادگیری نیمهنظارتی از جمله شهود، تکنیکهای برتر و مشکلات در عمل میبرد. این کتاب با معرفی انواع روشهای یادگیری نیمه نظارتی و بررسی این نوع از یادگیری در عمل خواننده را به خوبی با این رویکرد آشنا مینماید.
نام کتاب: Introduction to Semi-Supervised Learning
نویسندگان: Xiaojin Zhu و Andrew Goldberg
سال انتشار: 2009

این کتاب یک راهنمای مناسب برای افراد تازهکار در این زمینه است. مخاطبین این کتاب دانشجویان مقطع کارشناسی ارشد و محققان در زمینه های مختلفی مانند علوم کامپیوتر، مهندسی برق، آمار و روانشناسی میباشد. برای افرادی که قصد دارند به سرعت با مفاهیم کلیدی این رویکرد آشنا شوند، این کتاب توصیه میشود.
سخن آخر
یادگیری ماشین، چه با نظارت، چه بدون نظارت و یا نیمه نظارت، برای به دست آوردن بینشهای مهم از دادههای بزرگ یا ایجاد فناوریهای نوآورانه جدید بسیار ارزشمند است. یادگیری نیمه نظارتی به دلیل برخورداری از قابلیتهای همزمان یادگیری با نظارت و بدون نظارت و همچنین کاهش نیاز به نیروی انسانی و دقت بالا هم در تئوری و هم در عمل بسیار مورد توجه قرار گرفته است. هر چند محدودیتهای نیز به همراه دارد که از جمله آن عدم کارائی مناسب در تمامی مسایلی که در یادگیری با نظارت انجام میشود به ویژه زمانیکه فرضیههای هموارسازی، جداسازی در نواحی کمچگالی و خمینه صادق نباشد و یا دادههای برچسبگذاری شده نماینده کل توزیع نباشند. با این وجود یادگیری نیمهنظارتی در زمینههایی مختلفی نظیر طبقهبندی ساده تصاویر و وظایف طبقهبندی اسناد که در آن خودکار کردن فرآیند برچسبگذاری دادهها امکانپذیر است، کاربردهای فراوان دارد.





