
12 مورد از چالش های هوش مصنوعی که با آنها مواجه خواهید شد
 تیم تحریریه
تیم تحریریه- ۲۴ فروردین ۱۴۰۰
پاسخ ترس است و این ترس از بهکارگیری هوش مصنوعی دلایل زیادی دارد. شرکت O’Reilly در سال 2019، کتاب الکترونیکی منتشر کرد که در آن یافتههای پژوهش خود درخصوص بهکارگیری و چالش های هوش مصنوعی را در سازمانها بهطور خلاصه آورده بود. علاوه براین، در این کتاب فهرستی از رایجترین عواملی که مانع از بهکارگیری فناوری هوش مصنوعی در سازمانها میشوند نیز ارائه شده است. 23% از شرکتکنندگان در این پژوهش اظهار داشتند که دلیل اصلی آنها برای عدم پیشروی در زمینه هوش مصنوعی این است که هوش مصنوعی و استفاده از آن در فرهنگ و سنتهای شرکتشان تعریف نشده است. سایر دلایل ذکرشده عبارت بودند از کمبود اطلاعات و داده، کمبود افراد متخصص و عدم تشخیص کاربردهای هوش مصنوعی در زمینه کسبوکار.
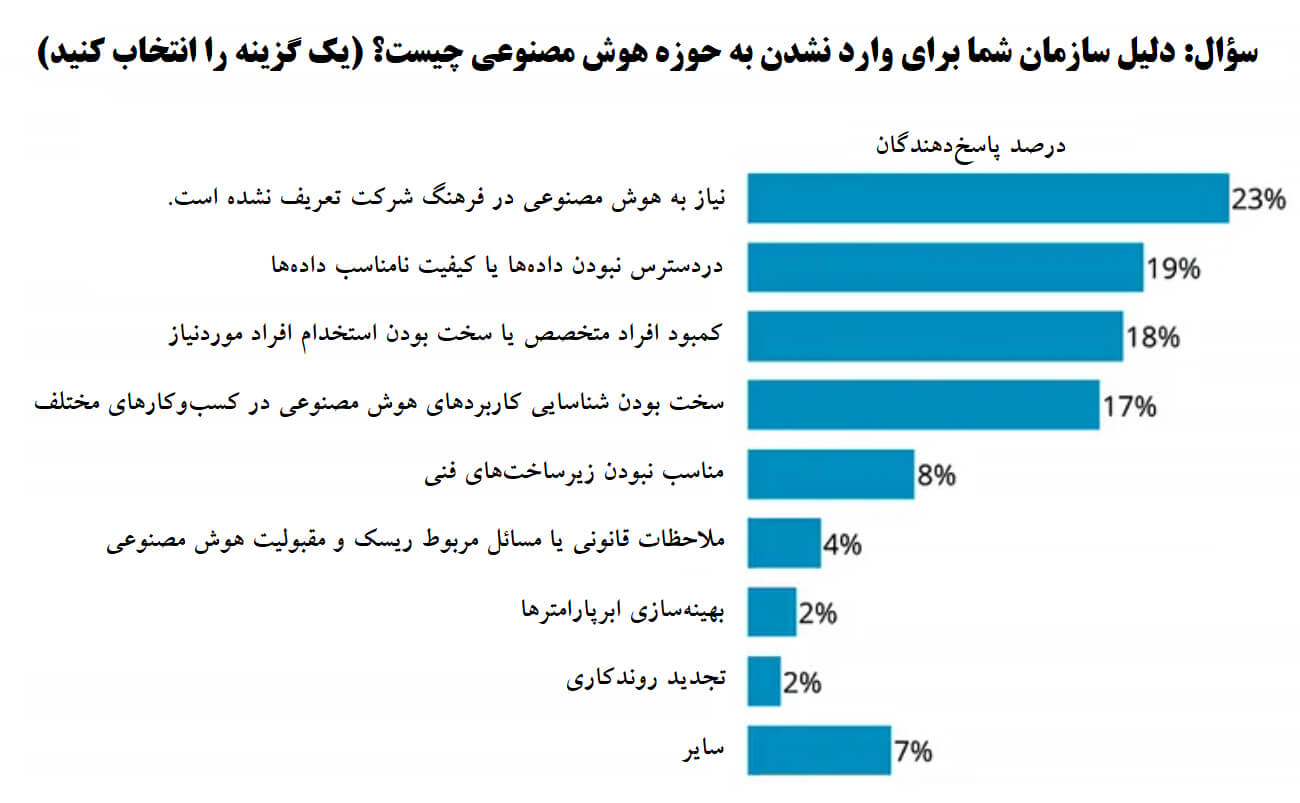
شرکتها برای ورود به دنیای هوش مصنوعی با چه چالشهایی روبهرو میشوند؟
همانطور که در بالا گفته شد، مشکلات اصلی در این زمینه بهطور معمول مربوط به افراد، دادهها و تطابق پیدا کردن کسبوکارها است. شرکتها با یکدیگر متفاوتند و درنتیجه تجربهای که از بهکارگیری هوش مصنوعی خواهند داشت نیز متفاوت با دیگری است، اما موانعی هستند که بر سر راه همه قرار میگیرند و باید از آنها آگاه بود. در این مقاله، ما تعدادی از متداولترین چالشهایی که شرکتها در مسیر بهکارگیری هوش مصنوعی با آنها مواجه خواهند شد را معرفی خواهیم کرد و راههایی برای مقابله با این چالشها نیز به شما پیشنهاد خواهیم کرد. مواردی که در این مقاله مطرح خواهند شد، عبارتند از:
• دادهها
1. کیفیت و کمیت دادهها
2. تخصیص برچسب به دادهها
3. قابلیت توضیح و تفسیر نتایج
4. یادگیری موضوعی
5. سوگیری
6. مقابله با خطاهای مدل
• افراد
7. اطلاعات محدود کارمندان غیر فنی در حوزه هوش مصنوعی
8. کمبود متخصص در حوزه هوش مصنوعی
• کسبوکار
9. عدم تطابق کسبوکارها
10. ارزیابی ارائهدهندگان
11. چالشهای یکپارچهسازی
12. مسائل قانونی
دادهها
اغلب شرکتها انتظار دارند که در زمینه دادهها با مشکل موجه شوند. همه میدانیم که عملکرد یک سیستم به دادههایی که به آن میدهیم، بستگی دارد. پیشتر در مقالهای دیگر به مواردی که باید پیش از بهکارگیری هوش مصنوعی درنظر گرفت، اشاره کردیم، اما از آنجا که دادهها عنصر کلیدی راهحلهای مبتنی بر هوش مصنوعی هستند، در ادامه برخی از مشکلات مربوط به این حوزه را مرور خواهیم کرد.
- کیفیت و کمیت دادهها
کیفیت و عملکرد سیستمهای هوش مصنوعی به شدت به دادههای ورودی وابسته است. این سیستمها برای یادگیری به دیتاستهای بزرگ و باکیفیت نیاز دارند، چون مانند انسانها از تجربه (دادهها) برای یادگیری استفاده میکنند، با این تفاوت که سرعت پردازش آنها بسیار بالاست. برای غلبه بر چالشهای مرتبط با دادهها، ابتدا باید دادههای موجود و نیازهای مدل را بشناسید.
سپس، فهرستی از دادههای موردنیاز تهیه کرده و بررسی کنید که دادهها ساختاریافتهاند یا نه، و آیا درباره مشتریان، تاریخچه خرید یا تعاملات آنلاین هستند. گاهی دادههای موردنیاز در دسترس عموم هستند یا میتوان آنها را خریداری کرد، ولی برخی مانند دادههای پزشکی بهسختی بهدست میآیند. در این موارد، استفاده از دادههای مصنوعی، دادههای رایگان، یا ابزارهایی مانند موتور جستوجوی دیتاست گوگل و رباتهای جمعآوری اطلاعات از منابعی مانند ویکیپدیا پیشنهاد میشود. شناخت دقیق دادههای موجود و موردنیاز، مسیر دستیابی به دیتاست مناسب را هموار میکند.
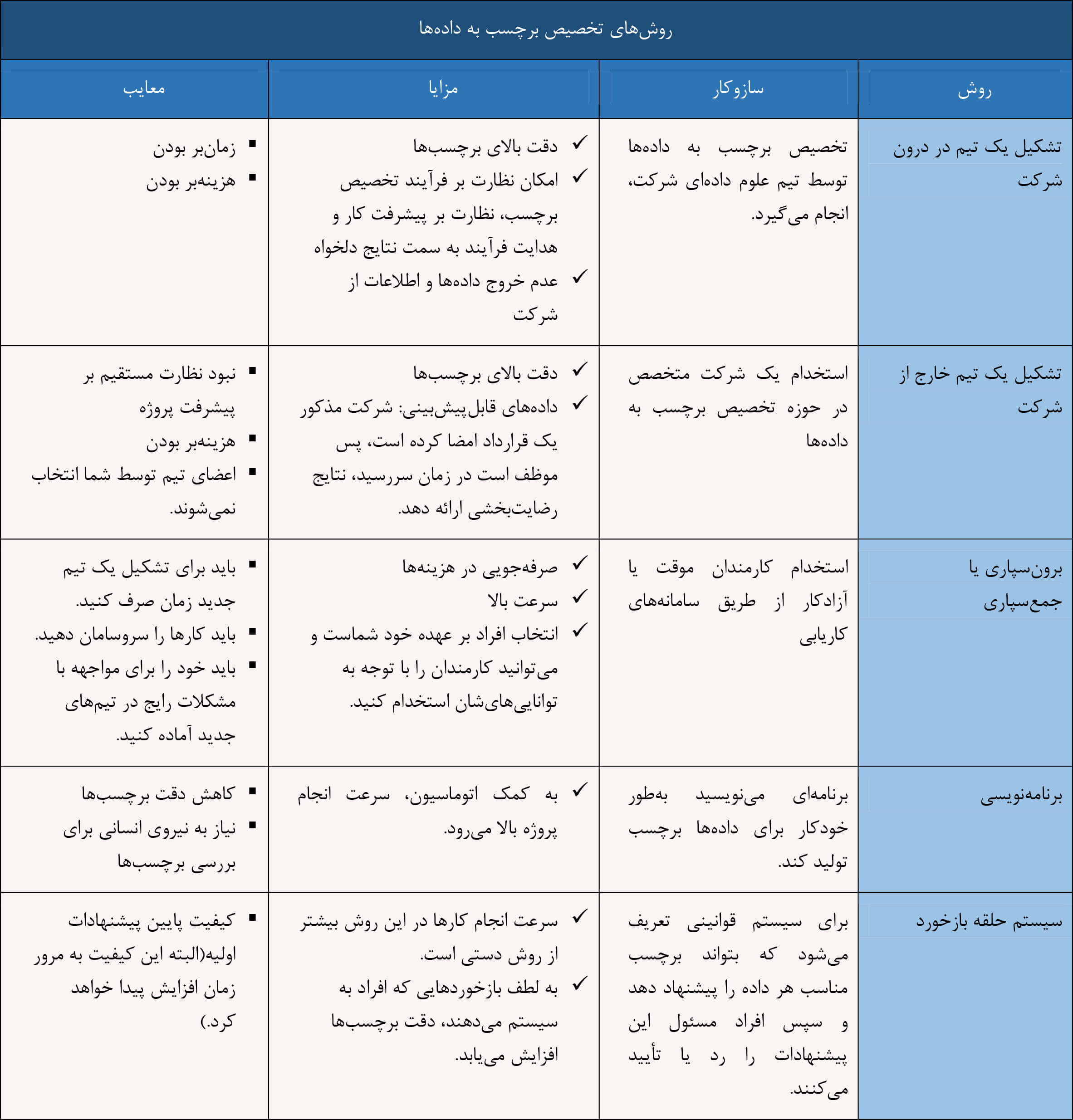
2. تخصیص برچسب به دادهها
تا چند سال پیش، دادههای ما عمدتا ساختار یافته و متنی بودند، اما با پیشرفت فناوری اینترنت اشیاء (IoT)، دادهها بیشتر به شکل تصاویر و ویدیوها در دسترس قرار گرفتهاند. این دادهها مشکل خاصی ندارند، اما برای آموزش سیستمهای یادگیری ماشینی یا عمیق نیاز به دادههای برچسبدار دارند. با حجم بالای دادههای تولیدی، نیروی انسانی کافی برای برچسب زدن به این دادهها وجود ندارد. پایگاههایی مانند ImageNet بیش از 14 میلیون تصویر برچسبدار فراهم میکنند، که بهطور دستی تفسیر شدهاند. روشهای مختلفی برای تخصیص برچسب به دادهها وجود دارد که میتوان آنها را به صورت داخلی، برونسپاری یا دستی انجام داد، که هرکدام مزایا و معایب خاص خود را دارند.
3. قابلیت توضیح و تفسیر نتایج
اغلب در مدلهای «جعبه سیاه»، سیستم هیچ توضیح اضافهای، یک نتیجه نهایی به شما ارائه میدهد. اگر نتیجهای که سیستم ارائه میدهد با دانستههای پیشین شما و نتیجه موردانتظار شما همپوشانی داشته باشد، سؤالی برای شما پیش نمیآید. اما اگر نتیجه نهایی متفاوت از دیدگاه شما باشد، چطور؟ در این حالت، قطعاً میخواهید بدانید که چرا چنین تصمیم و نتیجهای گرفته شده است. از طرفی، در بسیاری از موارد، تصمیم سیستم به تنهایی کافی نیست. برای مثال، پزشکان نمیتوانند در زمینهای سلامتی بیماران خود، تنها به پیشنهادی که سیستم به آنها میدهد، اکتفا کنند.
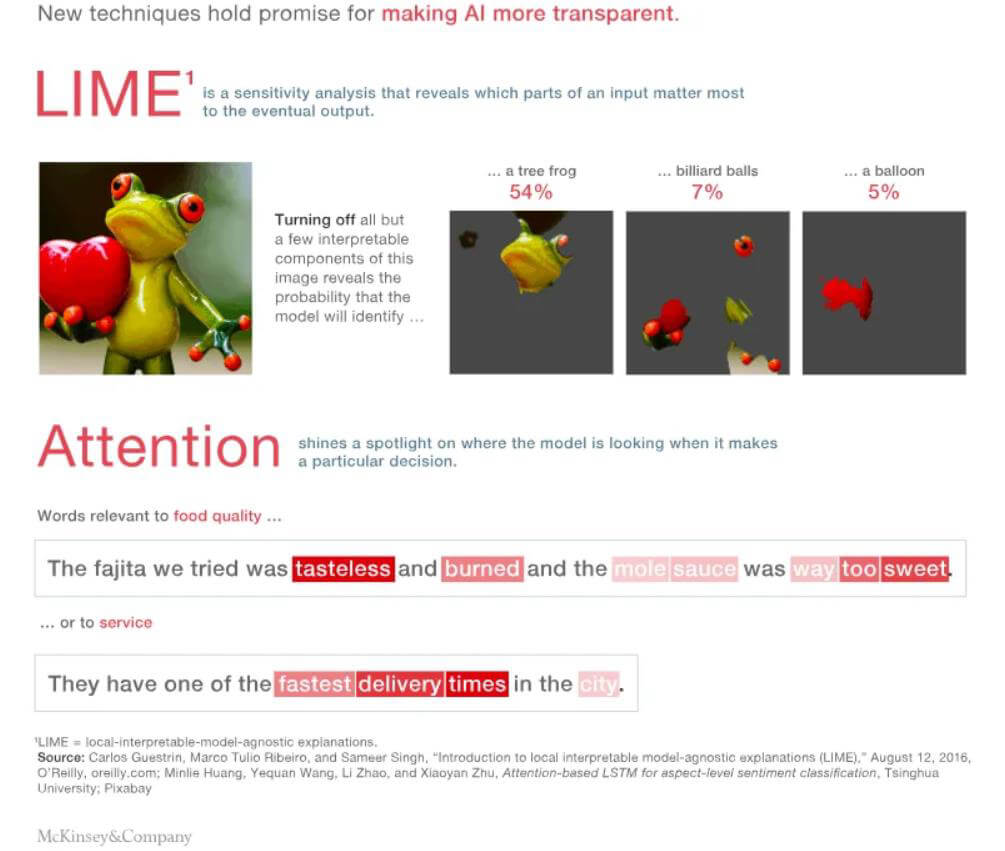
هدف پکیج LIME (local interpretable model-agnostic explanations) روشنسازی و توضیح نتایج مدل است. بدین ترتیب، اگر سیستم هوش مصنوعی بیماری فرد را آنفولانزا تشخیص دهد، این مدل دادههایی که منجر به ارائه این تشخیص شدهاند را نیز به ما خواهد داد. برای مثال، این مدل میگوید نشانههایی چون سردرد و آبریزش بینی منجر به چنین تشخیصی شده نه وزن و سن بیمار. هنگامی که ما از منطق پشت تصمیمات مدل اطلاع پیدا کنیم، میتوانیم تصمیم بگیریم که تا چه حد به آن اعتماد کنیم.
4. یادگیری موضوعی
انسانها میتوانند تجربیات خود را از یک حوزه به حوزهای دیگر منتقل کنند، اما هوش مصنوعی هنوز در این زمینه با محدودیتهایی روبروست. چون اغلب مدلهای هوش مصنوعی برای یک وظیفه خاص طراحی شدهاند، نمیتوانند بهراحتی در شرایط متفاوت عملکرد خوبی داشته باشند.
با این حال، ممکن است آموختههای یک مدل در یک وظیفه، برای وظیفهای دیگر نیز مفید باشد. این ایده اساس انتقال آموختهها است؛ یعنی استفاده از تجربیات یک مدل آموزشدیده برای آموزش مدل دیگری در یک فعالیت مشابه. این روش باعث صرفهجویی در زمان و منابع میشود و بهرهوری مدلها را افزایش میدهد.
5. سوگیری
سوگیری در هوش مصنوعی موضوعی است که اخیراً توجه زیادی جلب کرده است. این سوگیری از دادههایی نشأت میگیرد که به هوش مصنوعی داده میشود. هوش مصنوعی خود هیچ قصد یا ارادهای ندارد، بلکه تصمیمات آن بر اساس دادهها و اطلاعات وارد شده است. سوگیری میتواند به دلایل مختلفی ایجاد شود، اما عمدتاً به نحوه جمعآوری و تحلیل دادهها مربوط میشود. به عنوان مثال، اگر دادهها از یک گروه خاص جمعآوری شوند، نمیتوانند نماینده کل جامعه باشند. همچنین، نحوه استفاده از دادهها و ویژگیهای خاص افراد نیز میتواند منجر به سوگیری شود. یکی دیگر از دلایل سوگیری، تأثیر انسانها بر دادهها است، چرا که افراد میتوانند اطلاعات نادرست یا تبعیضآمیز را وارد سیستم کنند، همانطور که در مورد سیستم استخدامی آمازون مشاهده شد که سوگیری جنسیتی از خود نشان داد.
6. مقابله با خطاهای مدل
هوش مصنوعی از خطا مصون نیست و ممکن است تحت تأثیر تعصبات انسانی و دادههای نادرست قرار گیرد که منجر به سوگیری در نتایج میشود. این سوگیریها میتوانند دقت نتایج را کاهش دهند. «استدلال اشتباه» نیز یکی از مشکلات است که به دلیل پیچیدگی فرآیندهای درون شبکههای عصبی شناسایی خطاها دشوار میشود. در مواقعی که سیستمهای هوش مصنوعی خطا میکنند، مثل اتومبیلهای خودران، خطر آنها میتواند جدی باشد. با این حال، برخی اشتباهات سیستمها در موارد غیر حساس، مانند انتخاب بین یک مرد و زن با تواناییهای مشابه، به مسائل اخلاقی تبدیل میشود.
همچنین، برخی خطاها سادهلوحانه هستند، مانند اشتباه یک سیستم در شناسایی یک تصویر. برای کاهش خطرات، کیفیت ورودیها و انجام آزمونهای مناسب اهمیت دارند.
افراد
7. اطلاعات محدود کارمندان غیر فنی در حوزه هوش مصنوعی
برای بهکارگیری هوش مصنوعی، مدیران سازمانها باید درک عمیقی از تواناییها و محدودیتهای آن داشته باشند. متأسفانه، افسانهها و تصورات نادرست، مانند رقابت با غولهای فناوری یا ترس از رباتها، مانع از استفاده مؤثر از این فناوری میشوند.
نداشتن دانش کافی میتواند منجر به تعیین اهداف غیرواقعی شود. برای حل مسائل کسبوکار با هوش مصنوعی، لازم نیست به دانشمند داده تبدیل شوید؛ کافی است با صنعت خود آشنا شوید، بازیگران اصلی را زیرنظر بگیرید و کاربردهای هوش مصنوعی را بررسی کنید تا مدیریت انتظارات آسانتر شود.
8. کمبود متخصص در حوزه هوش مصنوعی
بهمنظور موفقیت در طراحی یک راهحل مبتنی بر هوش مصنوعی، شما باید علاوه بر دانش فنی، درک کافی از حوزه کسبوکار نیز داشته باشید. متأسفانه، اغلب افراد تنها در یکی از این حوزهها دانش کافی دارند. بهطورمعمول، مدیرعامل و سایر مدیران یک سازمان دانش فنی لازم برای بهکارگیری هوش مصنوعی را ندارند و اکثر دانشمندان و متخصصین داده نیز علاقهای به شناخت و بررسی کاربردهای مدل خود در دنیای واقعی ندارند. شمار متخصصان هوش مصنوعی که میدانند چگونه میتوان یک فنآوری را در یک کسبوکار خاص بهکار گفت، بسیار اندک است.
شرکتهایی که عضوی از گروه FAMGA (که متشکل از شرکتهای فیسبوک، اپل، مایکروسافت، گوگل و آمازون است) نباشند، برای استخدام افراد با استعداد در این حوزه با مشکلات زیادی مواجهند و حتی اگر بتوانند یک تیم هوش مصنوعی در داخل سازمان خود تشکیل دهند، نمیتوانند با اطمینان بگویند که افراد درستی را برای این تیم استخدام کردهاند. شما بدون داشتن دانش فنی کافی از هوش مصنوعی، نمیتوانید کیفیت راهحلهایی که تیم هوش مصنوعی ارائه میدهند را ارزیابی کنید. شرکتهای متوسط یا کوچک ممکن است بهدلیل محدودیت منابع مالی، نتوانند راهی برای استفاده از هوش مصنوعی در سازمان خود پیدا کنند. البته، درحالحاضر برونسپاری و سپردن پروژههای هوش مصنوعی به تیمهای متخصص داده در خارج از شرکت، گزینه مناسبی است.
کسبوکار
9. عدم تطابق کسبوکارها
همانطور که در نمودار ابتدای این مقاله ملاحظه کردید، در فرهنگ شرکتها چیزی به عنوان هوش مصنوعی تعریف نشده و شناسایی کاربردهای هوش مصنوعی در کسبوکارهای مختلف، یکی از بزرگترین موانع بر سر راه بهکارگیری هوش مصنوعی است. مدیران کسبوکار برای شناسایی کاربردهای هوش مصنوعی در سازمان خود باید درک عمیقی از فنآوریهای مبتنی بر هوش مصنوعی و تواناییها و محدودیتهای آن داشته باشند. نداشتن دانش و اطلاعات کافی درخصوص هوش مصنوعی مانع از بهکارگیری این فنآوری در بسیاری از سازمانها شده است.
اما مسئله دیگری نیز در این میان وجود دارد. برخی از شرکتها با خوشبینی زیاد و بدون داشتن استراتژی روشن و دقیق، وارد عرصه هوش مصنوعی میشوند. استفاده و بهرهبرداری از هوش مصنوعی نیازمند داشتن رویکردی راهبردی، هدفگذاری دقیق، شناسایی شاخصهای کلیدی عملکرد و تحت نظر گرفتن میزان بازگشت سرمایه است. در صورت نادیده گرفتن هر یک از این موارد، نمیتوانید نتایج حاصل از پروژه هوش مصنوعی خود را ارزیابی کنید، یا آنها را با فروض ابتدایی خود مقایسه کنید و میزان موفقیت یا شکست خود در این سرمایهگذاری را بسنجید.
10. ارزیابی ارائهدهندگان
همانطور که پیشتر و در موضوع استخدام متخصصین داده نیز گفتیم، اگر دانش فنی کافی درباره هوش مصنوعی نداشته باشید، بهسادگی فریب میخورید. بهکارگیری هوش مصنوعی در کسبوکار، یک عرصه نوظهور است که احتمال آسیبپذیری در آن بالاست، زیرا بسیاری از شرکتها در بیان تجربیات و دستآوردهای خود غلو میکنند، درحالیکه در واقعیت ممکن است اصلاً ندانند که چطور میتوان از هوش مصنوعی در حل مسائل حوزه کسبوکار استفاده کرد. به این ترتیب، یکی از راههایی که برای شناسایی رهبران دنیای هوش مصنوعی پیش روی شما این است که به وبسایتهای همچون Clutch مراجعه کنید تا بتوانید دستآوردهای شرکتهای مختلف را مشاهده و بررسی نمایید. یک راه دیگر، برداشتن قدمهای کوچک به سمت دنیای هوش مصنوعی است. برای مثال، میتوانید از یکی از ارائهدهندگان خوشآتیه خود در حوزه هوش مصنوعی بخواهید که برای شما یک کارگاه برگزار کند. بدین ترتیب، قابلیتها و تواناییهای آنها برای شما روشن خواهد شد و متوجه خواهید شد که آیا شرکت مذکور درک درستی از کسبوکار شما دارد؟، آیا مهارتهای لازم برای کمک به شما را دارد؟ و آیا میداند که چطور مشکلات شما را حل کند؟
11. چالشهای یکپارچهسازی
یکپارچهسازی سیستم هوش مصنوعی در شرکتها فراتر از نصب افزونه است و نیاز به بررسی عوامل مختلفی دارد، از جمله زیرساختهای داده، نحوه ذخیرهسازی، برچسبزنی و آموزش مدل. پس از آموزش، باید مدل را آزمایش و با ایجاد حلقه بازخورد بهبود بخشید.
برای اطمینان از موفقیت پروژه، همکاری با شرکتهای ارائهدهنده خدمات ضروری است تا فرآیند بهدرستی درک و پیادهسازی شود. این سیستم باید بهطور گام به گام و استراتژیک وارد سازمان شود. پس از پیادهسازی، آموزش نحوه استفاده و تفسیر نتایج مدل برای کارکنان ضروری است.
12. مسائل قانونی
قوانین فعلی توان همگامی با رشد سریع هوش مصنوعی را ندارند و همین باعث ایجاد ابهامات حقوقی در پیادهسازی این فناوری در شرکتها شده است. در مواردی که هوش مصنوعی به کسی آسیب بزند، مشخص نیست چه کسی مسئول است: طراح مدل یا استفادهکننده؟ همچنین، قوانین GDPR اتحادیه اروپا، دادهها را نوعی دارایی میدانند و محدودیتهایی برای جمعآوری و استفاده از آنها تعیین کردهاند. علاوه بر چالشهای قانونی، برخی دادهها ممکن است حساس نباشند، اما در صورت افشا، به شرکت آسیب برسانند. بنابراین، شرکتها باید با دقت دادههای خود را مدیریت و محافظت کنند.
غلبه بر موانع پذیرش موفق هوش مصنوعی
پذیرش موفق هوش مصنوعی تنها به معنای استفاده از جدیدترین فناوری نیست. این فرآیند نیازمند یک استراتژی دقیق است که شامل مدیریت مناسب، یکپارچگی دادهها، تحلیل مالی و همکاری با تأمینکنندگان باشد. با پیشبینی و حل مشکلات احتمالی، سازمانها میتوانند پذیرش هوش مصنوعی را سرعت ببخشند و اثرات آن را به حداکثر برسانند.
اولویت دادن به مدیریت، شفافیت و اخلاق
ایجاد چارچوبهای مدیریتی قوی برای استفاده مسئولانه و اخلاقی از هوش مصنوعی بسیار حیاتی است. سیستمهای هوش مصنوعی شفاف نه تنها اعتماد ایجاد میکنند، بلکه به سازمانها در رعایت قوانین در حال تغییر کمک میکنند. به همین دلیل، ۶۱٪ از رهبران کسبوکار به استفاده مسئولانه از هوش مصنوعی علاقهمند هستند که این رقم نسبت به شش ماه پیش افزایش یافته است. کسبوکارها باید دستورالعملهای دقیقی برای پاسخگویی هوش مصنوعی و تعیین مسئولیتها و فرآیندهای اعتبارسنجی تدوین کنند.
علاوه بر این، تمرکز بر توضیحپذیری هوش مصنوعی نیز اهمیت دارد؛ یعنی اطمینان حاصل کنید که مدلهای هوش مصنوعی نتایج قابل درک و توجیه ارائه میدهند. مدلهای “جعبه سیاه” که در آنها تصمیمات بدون شفافیت منطقی گرفته میشود، میتوانند به بیاعتمادی و بررسیهای دقیق نظارتی منجر شوند. شرکتها میتوانند با ادغام اصول اخلاقی در هوش مصنوعی و تقویت نظارت انسانی، اعتماد به راهحلهای خود را افزایش دهند و خطرات را کاهش دهند.
بهبود مدیریت دادهها
کیفیت و امنیت دادهها برای موفقیت هوش مصنوعی حیاتی است. قبل از وارد کردن دادهها به مدلها، کسبوکارها باید روشهای پیشرفته مدیریت دادهها مانند ناشناسسازی، حریم خصوصی تفاضلی و رمزگذاری را پیادهسازی کنند. این روشها از دادههای حساس محافظت کرده و همزمان امکان استفاده مؤثر از آنها را برای تحلیلهای هوش مصنوعی فراهم میکنند. به عنوان مثال:
- ناشناسسازی: حذف اطلاعات شخصی قابل شناسایی (PII) از دادهها، که هم رعایت حریم خصوصی را تضمین میکند و هم تجزیه و تحلیلهای مفید را امکانپذیر میسازد.
- حریم خصوصی تفاضلی: وارد کردن نویز آماری به دادهها بهطوری که مدلها بدون افشای دادههای خاص، از الگوهای کلی یاد بگیرند.
- رمزگذاری: حفاظت از دادهها در زمان استراحت و انتقال، جلوگیری از دسترسی غیرمجاز و کاهش خطر نقض اطلاعات
انتخاب ترکیب مناسب از راهحلها
یک استراتژی موفق برای هوش مصنوعی به معنای انتخاب ترکیب صحیح از ابزارها، پلتفرمها و مدلهای استقرار است. سازمانها باید نیازها و آمادگی زیرساختهای خود را ارزیابی کرده و به جای یک رویکرد عمومی، راهحلهای متناسب با شرایط خود را پیدا کنند. در برخی موارد، استفاده از زیرساختهای موجود یا انتخاب راهحلهای ابری ترکیبی ممکن است از ساخت سیستمهای جدید بهطور کامل مقرون به صرفهتر باشد.
علاوه بر این، کسبوکارها باید تصمیم بگیرند که از مدلهای آماده استفاده کنند، راهحلهای متنباز را سفارشیسازی کنند یا مدلهای اختصاصی خود را توسعه دهند. در بسیاری از موارد، ترکیب چندین راهحل مختلف مانند مدلهای پیشآموزشدیده برای وظایف عمومی و مدلهای سفارشی برای نیازهای خاص، بهترین نتیجه را به همراه دارد. سازمانها با بررسی دقیق ساختار هوش مصنوعی خود میتوانند عملکرد، هزینه و مقیاسپذیری را بهینه کنند.
ارائه دلیل قانعکننده برای سرمایهگذاری
برای جلب حمایت مدیران ارشد در زمینه ابتکارات هوش مصنوعی، ضروری است که یک طرح تجاری مستحکم ارائه شود که تأثیر مالی آن را بهوضوح نشان دهد. با معرفی هوش مصنوعی به عنوان یک ضرورت استراتژیک برای کسبوکار و نه فقط یک بهروزرسانی فناوری، سازمانها میتوانند بودجه و حمایت لازم برای پیادهسازی موفق آن را جلب کنند.
برای ارائه یک استدلال قوی، سازمانها باید:
- هماهنگی با اهداف تجاری: توضیح دهند که چگونه پروژههای هوش مصنوعی میتوانند به افزایش درآمد، کاهش هزینهها یا بهبود بهرهوری کمک کنند.
- تخمین بازگشت سرمایه: از پروژههای آزمایشی و دادههای واقعی برای تخمین صرفهجوییها، بهرهوری بالاتر و کاهش ریسک استفاده کنند.
- برجسته کردن مزایای رقابتی: نشان دهند که هوش مصنوعی چگونه میتواند شرکت را از رقبا متمایز کند، تجربه مشتری را بهبود بخشد و فرآیند تصمیمگیری را تسهیل کند.
- پرداختن به خطرات بالقوه: استراتژیهایی برای کاهش خطرات مرتبط با مسائل امنیتی، رعایت مقررات و آمادگی نیروی کار ارائه دهند.
چگونه با چالشهای بهکارگیری هوش مصنوعی مواجه شویم؟
باید این نکته را بهخاطر داشته باشید که شما نمیتوانید به تنهایی از پس همه این مشکلات بر بیایید. اما اولین قدم شما برای مقابله با آنها، آشنایی بیشتر با هوش مصنوعی است تا بتوانید فرآیندهای مختلف را بهتر درک کنید. پس از این که یک استراتژی مبتنی بر هوش مصنوعی طراحی کردید، باید مسائل و مشکلاتی که بر سر راهتان قرار دارند را شناسایی کنید.
با داشتن یک استراتژی و رویکرد دقیق و جزئی، فرآیند پیادهسازی هوش مصنوعی در سازمان شما بسیار آسانتر خواهد شد. آیا طی کردن این مسیر بدون برخورد با موانع ممکن است؟ پاسخ منفی است. هیچچیز 100% عالی و بی نقص نیست. اما کسب آمادگی برای مواجهه با مشکلاتی که ممکن است با آنها مواجه شوید، مزیت بزرگی برای شما بهحساب میآید.
سوالات متداول
- چگونه میتوانیم از دادههای حساس در هوش مصنوعی محافظت کنیم؟
استفاده از تکنیکهایی مانند ناشناسسازی، رمزگذاری و حریم خصوصی تفاضلی میتواند به محافظت از دادههای حساس کمک کند. این روشها به شما امکان میدهند که دادهها را در حالی که از حریم خصوصی محافظت میکنید، برای آموزش مدلهای هوش مصنوعی استفاده کنید.
- چگونه میتوان از هوش مصنوعی بهطور اخلاقی استفاده کرد؟
برای استفاده اخلاقی از هوش مصنوعی، باید اصول شفافیت، پاسخگویی و رعایت حقوق افراد را رعایت کنید. ایجاد چارچوبهای حاکمیتی و نظارتی به شما کمک میکند تا از کاربردهای مسئولانه و بیطرفانه هوش مصنوعی اطمینان حاصل کنید.
- چگونه میتوان به خطرات امنیتی در هوش مصنوعی پاسخ داد؟
برای مقابله با تهدیدات امنیتی، باید از فناوریهای رمزگذاری و محافظت از دادهها استفاده کنید و نظارت مستمر بر سیستمها داشته باشید. همچنین، امنیت سایبری باید بخشی از استراتژی کلان هوش مصنوعی باشد.





