
5 روش انتخاب ویژگی در کتابخانه Scikit-Learn
 تیم تحریریه
تیم تحریریه- ۲۹ آبان ۱۴۰۰
عملکرد خود را با انواع مهمترین روش انتخاب ویژگی بهبود ببخشید. انتخاب ویژگی Feature selection روشی است برای کاهش تعداد متغیرها. در این روش کاراترین متغیرها برای پیشبینی متغیر هدف در مدل، بر اساس یک سری معیار مشخص انتخاب میشوند.
هر چه تعداد ویژگیها افزایش یابد، توان مدل در پیشبینی بیشتر خواهد شد، اما فقط تا سطحی معین! از این سطح خاص به بعد، مدل دچار مشکلی میشود که به آن نفرین ابعاد Curse of Dimensionality گفته میشود. از این نقطه به بعد، با افزایش تعداد ویژگیها، عملکرد مدل بد و بدتر میشود. به همین دلیل نیز باید تنها ویژگیهایی را برگزینیم که به صورت کارآمد، توانایی پیشبینی متغیر مدنظر را داشته باشند.
روش انتخاب ویژگی مشابه تکنیک تقلیل ابعاد Dimensionality reduction technique است. هدف تکنیک تقلیل ابعاد نیز کاهش تعداد ویژگیهاست، اما این دو از پایه با هم متفاوت هستند. تفاوت انتخاب ویژگی و تقلیل ابعاد این است که در روش انتخاب ویژگی، ویژگیهایی که میخواهیم حذف شوند یا در دیتاست باقی بمانند را انتخاب میکنیم. اما در تکنیک کاهش ابعاد یک نگاشت از دادهها ایجاد میشود که منجر به ایجاد ویژگیهای ورودی کاملاً جدید خواهد شد.
روشهای مختلفی برای انتخاب ویژگی وجود دارد. اما در این مقاله تنها به 5 روشی که در کتابخانه Scikit-Learn وجود دارند، اشاره خواهم کرد. من تنها به روشهای موجود در این کتابخانه اکتفا میکنم، چرا که علیرغم آسانی، بسیار کارآمد هستند.
انتخاب ویژگی به روش آستانه واریانس
وقتی واریانس یک ویژگی بالا باشد، یعنی مقادیر آن ویژگی تنوع زیاد یا کاردینالیتی Cardinality دارند. درحالیکه وقتی واریانس یک ویژگی کم باشد، به این معناست که مقادیر آن شباهت بیشتری به هم دارند و وقتی که واریانس صفر باشد، یعنی تمامی مقادیر آن ویژگی با هم برابرند.
ما عموماً میخواهیم که مقادیر ویژگیمان متفاوت از هم باشند تا پیشبینی مدل سوگیری نداشته باشد. به همین دلیل نیز میتوانیم ویژگیها را بر اساس واریانسشان انتخاب کنیم.
آستانه واریانس Variance Threshold روشی است ساده برای حذف ویژگیها بر اساس واریانس موردانتظار ما برای هر ویژگی. البته این روش نقاط ضعفی نیز دارد. روش آستانه واریانس تنها ویژگیهای ورودی (X) را در نظر میگیرد و هیچ اطلاعاتی از متغیر وابسته (y) را در تصمیم خود لحاظ نمیکند. این روش تنها برای حذف ویژگیها در مدلسازیهای بدوننظارت مناسب است و در در مدلسازی نظارتشده کاربردی ندارد.
بیایید این روش را روی یک دیتاست نمونه اجرا کنیم.

در این مثال، به منظور سادهسازی تنها از ویژگیهای عددی استفاده کردم. البته پیش از استفاده از روش آستانه واریانس باید ویژگیهای عددی را استانداردسازی کنیم تا اثر مقیاس آنها را در محاسبه واریانس خنثی سازیم.
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() mpg = pd.DataFrame(scaler.fit_transform(mpg), columns = mpg.columns) mpg.head()

حال که همه ویژگیها در مقیاس یکسانی قرار گرفتند، مجدداً با روش آستانه واریانس ویژگیهای مدنظر را انتخاب میکنیم. برای مثال، در اینجا واریانس را به 1 محدود میکنم.

from sklearn.feature_selection import VarianceThreshold selector = VarianceThreshold(1) selector.fit(mpg) mpg.columns[selector.get_support()]
به نظر میرسد تنها ویژگی weight بر اساس آستانه واریانسی که تعیین کردیم، انتخاب شده است.
همانطور که پیشتر گفتم، روش آستانه واریانس تنها در مدلهای یادگیری بدون نظارت کاربرد دارد، اما در کل، اغلب روشهای انتخاب ویژگی Scikit-Learn در مدلهای یادگیری نظارتشده کاربرد دارند که در ادامه به آنها خواهیم پرداخت.
انتخاب ویژگی تک متغیره توسط SelectKBest
انتخاب ویژگی تک متغیره Univariate Feature Selection یک روش انتخاب ویژگی است که مبتنی بر آزمونهای آماری تکمتغیره
Univariate statistical test مثل آزمون chi2، همبستگی پیرسون Pearson-correlation و غیره است.
SelectKBest بهطور پیشفرض آزمون آماری تک متغیره را با انتخاب تعداد K ویژگی بر اساس نتیجه آماری بین X و y ترکیب میکند.
بیایید کاربرد آن را روی همان دادههای قبلی ببینیم.
mpg = sns.load_dataset('mpg')
mpg = mpg.select_dtypes('number').dropna()
#Divide the features into Independent and Dependent Variable
X = mpg.drop('mpg' , axis =1)
y = mpg['mpg']
از آنجا که روش انتخاب ویژگی تک متغیره برای یادگیری نظارتشده در نظر گرفته شده است، ما ویژگیها را به متغیرهای مستقل و وابسته تقسیم میکنیم و سپس آنها را با استفاده از SelectKBest براساس رگرسیون اطلاعات متقابل Mutual info regression انتخاب میکنیم. فرض کنید در اینجا تنها دو ویژگی برتر را میخواهیم.
from sklearn.feature_selection import SelectKBest, mutual_info_regression #Select top 2 features based on mutual info regression selector = SelectKBest(mutual_info_regression, k =2) selector.fit(X, y) X.columns[selector.get_support()]

بر اساس رگرسیون اطلاعات متقابل، فقط ویژگی های displacement و weight انتخاب شدند.
حذف ویژگیها به صورت بازگشتی (RFE)
حذف ویژگیها به صورت بازگشتی یا RFE Recursive Feature Elimination (RFE) یک روش انتخاب ویژگی است که عمل انتخاب ویژگی را با استفاده از یک مدل یادگیری ماشین که هدفش حذف کماهمیتترین ویژگیها پس از آموزش بازگشتی است، انجام میدهد.
در Scikit-Learn ،RFE روشی است برای انتخاب ویژگیها که به طور بازگشتی هر بار مجموعه کوچکتری از ویژگیها را در نظر میگیرد. در ابتدا، برآوردگر روی مجموعه ویژگیهای اولیه آموزش میبیند و اهمیت هر ویژگی از خصیصههای coef_ یا feature_importances_ به دست میآید. سپس، کماهمیتترین ویژگیها از مجموعه ویژگیهای فعلی هرس Prune میشوند. این رویه به صورت بازگشتی روی مجموعه هرسشده تکرار میشود تا در نهایت تعداد ویژگیها به تعداد تعیینشده برسد.
در روش حذف ویژگیها به صورت بازگشتی، k ویژگی برتر براساس مدل یادگیری ماشینی که خصیصههای coef_ یا feature_importances_ را دارد، انتخاب میشوند. RFE کماهمیتترین ویژگیها را حذف میکند و سپس مدل را مجدداً آموزش میدهد تا زمانی که فقط k ویژگی مورد نظر شما را انتخاب کند.
این روش تنها در صورتی کار میکند که مدل دارای خصیصههایcoef_ یا feature_importances_ باشد. بنابراین، اگر مدل شما دارای یکی از این دو خصیصهها باشد، میتوانید از RFE استفاده کنید.
بیایید از یک دیتاست نمونه استفاده کنیم. در این مثال، میخواهم از دیتاست titanic برای یک مسئله دستهبندی استفاده کنم تا پیشبینی کنم چه کسی زنده خواهد ماند.
#Load the dataset and only selecting the numerical features for example purposes
titanic = sns.load_dataset('titanic')[['survived', 'pclass', 'age', 'parch', 'sibsp', 'fare']].dropna()
X = titanic.drop('survived', axis = 1)
y = titanic['survived']
حال میخواهم با استفاده از RFE ببینم کدام ویژگیها برای پیشبینی بازماندگان حادثه کشتی تایتانیک مفیدتر هستند. برای به دست آوردن بهترین ویژگیها از مدل LogisticRegression استفاده میکنیم.
from sklearn.feature_selection import RFE from sklearn.linear_model import LogisticRegression# #Selecting the Best important features according to Logistic Regressionrfe_selector = RFE(estimator=LogisticRegression(),n_features_to_select = 2, step = 1) rfe_selector.fit(X, y) X.columns[rfe_selector.get_support()]
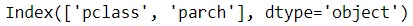
به طور پیشفرض، تعداد ویژگیهای انتخابشده برای RFE میانه کل ویژگیها است و مقدار پارامتر step که تعداد ویژگیهای حذفشده در هر تکرار را نشان میدهد برابر یک است. میتوانید براساس دانش خود یا سایر معیارهایی که در نظر دارید، مقدار آن را تغییر دهید.
انتخاب ویژگی به کمک SelectFromModel
روش انتخاب ویژگی با SelectFromModel نیز مثل روش RFE مبتنی بر یک مدل یادگیری ماشین است. تفاوت این دو روش در این است که انتخاب ویژگی با کمک SelectFromModel بر اساس آستانه اهمیت یک خصیصه که غالباً coef_ یا feature_importances_ در نظر گرفته میشود، عمل میکند. این آستانه به طور پیشفرض مقدار میانگین در نظر گرفته میشود.
برای درک بهتر مفهوم این روش، آن را روی یک دیتاست نمونه اعمال کنیم. من از همان دادههای قبلی استفاده میکنم.
from sklearn.feature_selection import SelectFromModel# #Selecting the Best important features according to Logistic Regression using SelectFromModelsfm_selector = SelectFromModel(estimator=LogisticRegression()) sfm_selector.fit(X, y) X.columns[sfm_selector.get_support()]

با استفاده از SelectFromModel، متوجه شدیم که فقط یک ویژگی یعنی «pclass» از آستانه عبور کرده است.
در اینجا نیز مانند روش RFE، میتوانید از هر مدل یادگیری ماشین برای انتخاب ویژگی استفاده کنید، به شرطی که قابلیت تخمین اهمیت خصیصه را داشته باشد. میتوانید مثال بالا را با مدل Random Forest یا XGBoost نیز امتحان کنید.
انتخاب ویژگی زنجیرهای
در نسخه 0.24 Scikit-Learn الگوریتمی حریصانه Greedy به نام انتخاب ویژگی ترتیبی Sequential Feature Selection (SFS) یا SFS اضافه شده که میتواند بهترین ویژگیها را با رفتن به جلو یا عقب و بر اساس امتیاز اعتبارسنجی متقاطع Cross-validation score برآوردگر پیدا کند.
SFS-Forward کار خود را با صفر ویژگی شروع میکند و هدفش پیدا کردن ویژگی است که وقتی مدل یادگیری ماشینی تنها بر روی آن آموزش داده میشود، امتیاز اعتبارسنجی متقاطع آن بالاتر از سایر ویژگیها باشد. هنگامی که اولین ویژگی انتخاب شد، این فرایند با اضافه کردن یک ویژگی جدید به ویژگیهای منتخب قبلی، تکرار میشود. این فرایند وقتی تعداد ویژگیها به تعداد تعیینشده برسد، متوقف میشود.
SFS-Backward نیز از همین ایده کلی پیروی میکند، اما در جهت عکس آن عمل میکند. به این معنا که در ابتدا همه ویژگیهای موجود را درنظر میگیرد و سپس به صورت حریصانه ویژگیها را حذف میکند تا زمانی که به تعداد ویژگی تعیینشده برسد.
SFS با RFE و SelectFromModel متفاوت است زیرا مدل یادگیری ماشین آن نیازی به خصیصههایcoef یا feature_importances_ ندارد. اما چون برای ارزیابی نتایج مدل را چندین بار برازش میدهد، سرعت آن بسیار کندتر از دو روش قبلی است.
بیایید این روش را در یک مثال ببینیم. من در این مثال SFS-Backward را امتحان کنم.
from sklearn.feature_selection import SequentialFeatureSelector #Selecting the Best important features according to Logistic Regression sfs_selector = SequentialFeatureSelector(estimator=LogisticRegression(), n_features_to_select = 3, cv =10, direction ='backward') sfs_selector.fit(X, y) X.columns[sfs_selector.get_support()]
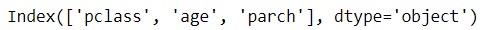
در این مثال SFS-Backward و سه ویژگی برای انتخاب و ده اعتبار سنجی متقاطع داشتیم که نتیجه آن در نهایت شد ویژگیهای pclass ، age و parch .
میتوانید این روش انتخاب ویژگی را روی دیتاست خود اعمال کنید و ببینید عملکرد مدل شما چگونه است، اما به یاد داشته باشید که اگر تعداد ویژگیها و حجم دادهها بیشتر باشد، زمان اجرای این روش نیز طولانیتر میشود.
نتیجهگیری
انتخاب ویژگی از جنبههای مهم در فرایند آموزش مدلهای یادگیری ماشین است، زیرا ما نمیخواهیم ویژگیهایی که اصلاً بر مدلهای پیشبینی ما تأثیری ندارند را در آموزش دخیل کنیم.
در این مقاله، من 5 روش انتخاب ویژگی موجود در کتابخانه Scikit-Learn را به شما معرفی کردم:
- آستانه واریانس
- انتخاب تک متغیره با استفاده از SelectKBest
- حذف ویژگی به صورت بازگشتی یا RFE
- روش SelectFromModel
- روش انتخاب ویژگی زنجیرهای یا SFS





